Recognition: no theorem link
FF3R: Feedforward Feature 3D Reconstruction from Unconstrained views
Pith reviewed 2026-05-10 17:43 UTC · model grok-4.3
The pith
FF3R reconstructs both 3D geometry and semantics from unconstrained multi-view images using only rendering supervision and no camera poses, depth, or labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FF3R is a fully annotation-free feed-forward framework that unifies geometric and semantic reasoning from unconstrained multi-view image sequences, relying solely on rendering supervision for RGB and feature maps, while addressing global semantic inconsistency and local structural inconsistency via Token-wise Fusion and Semantic-Geometry Mutual Boosting.
What carries the argument
Token-wise Fusion Module that enriches geometry tokens with semantic context via cross-attention, together with Semantic-Geometry Mutual Boosting that combines geometry-guided feature warping for global consistency and semantic-aware voxelization for local coherence.
If this is right
- Novel-view synthesis becomes possible directly from image sequences without pose estimation.
- Open-vocabulary semantic segmentation works in 3D space from the unified features.
- Depth estimation improves through the combined semantic and geometric signals.
- The framework generalizes to in-the-wild multi-view captures without retraining.
Where Pith is reading between the lines
- Training on raw video footage alone could become a practical route to large-scale 3D scene datasets.
- The same unification pattern might extend to video inputs for tracking both structure and meaning over time.
- Embodied agents could use the output for navigation tasks that require both layout and object understanding.
Load-bearing premise
Rendering supervision on RGB and feature maps alone, plus the cross-attention fusion and mutual boosting steps, is sufficient to produce globally consistent semantics and locally coherent geometry without camera poses, depth supervision, or semantic labels.
What would settle it
A clear drop in performance or visible semantic inconsistencies on a new multi-view dataset when the mutual boosting is removed, or when the method is compared against pose-supervised baselines on the same scenes.
Figures






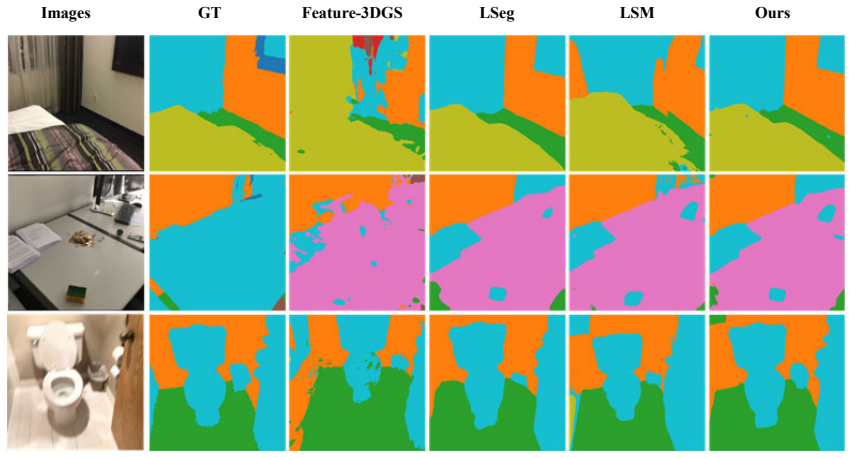


read the original abstract
Recent advances in vision foundation models have revolutionized geometry reconstruction and semantic understanding. Yet, most of the existing approaches treat these capabilities in isolation, leading to redundant pipelines and compounded errors. This paper introduces FF3R, a fully annotation-free feed-forward framework that unifies geometric and semantic reasoning from unconstrained multi-view image sequences. Unlike previous methods, FF3R does not require camera poses, depth maps, or semantic labels, relying solely on rendering supervision for RGB and feature maps, establishing a scalable paradigm for unified 3D reasoning. In addition, we address two critical challenges in feedforward feature reconstruction pipelines, namely global semantic inconsistency and local structural inconsistency, through two key innovations: (i) a Token-wise Fusion Module that enriches geometry tokens with semantic context via cross-attention, and (ii) a Semantic-Geometry Mutual Boosting mechanism combining geometry-guided feature warping for global consistency with semantic-aware voxelization for local coherence. Extensive experiments on ScanNet and DL3DV-10K demonstrate FF3R's superior performance in novel-view synthesis, open-vocabulary semantic segmentation, and depth estimation, with strong generalization to in-the-wild scenarios, paving the way for embodied intelligence systems that demand both spatial and semantic understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce FF3R, a fully annotation-free feed-forward framework that unifies geometric and semantic reasoning from unconstrained multi-view image sequences. It does not require camera poses, depth maps, or semantic labels, relying solely on rendering supervision for RGB and feature maps. Two key innovations are proposed: the Token-wise Fusion Module, which enriches geometry tokens with semantic context via cross-attention, and the Semantic-Geometry Mutual Boosting mechanism, which combines geometry-guided feature warping for global consistency with semantic-aware voxelization for local coherence. Extensive experiments on ScanNet and DL3DV-10K are said to demonstrate superior performance in novel-view synthesis, open-vocabulary semantic segmentation, and depth estimation, along with strong generalization to in-the-wild scenarios.
Significance. If the results hold, this work is significant as it offers a scalable paradigm for unified 3D reasoning without annotations, potentially reducing redundant pipelines and errors in separate geometry and semantic models. The Token-wise Fusion and Mutual Boosting address critical inconsistencies in feedforward feature reconstruction, which could benefit applications in embodied AI requiring both spatial and semantic understanding. The approach builds on vision foundation models in a novel way by integrating them through rendering supervision.
major comments (1)
- The abstract states that FF3R demonstrates superior performance on ScanNet and DL3DV-10K for novel-view synthesis, open-vocabulary segmentation, and depth estimation, but does not include any quantitative numbers, ablation details, or error analysis. This makes it hard to evaluate whether the data supports the central unification claim without the full experimental section.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of FF3R and for the constructive comment. We agree that enhancing the abstract will improve clarity and better support evaluation of the unification claim.
read point-by-point responses
-
Referee: The abstract states that FF3R demonstrates superior performance on ScanNet and DL3DV-10K for novel-view synthesis, open-vocabulary segmentation, and depth estimation, but does not include any quantitative numbers, ablation details, or error analysis. This makes it hard to evaluate whether the data supports the central unification claim without the full experimental section.
Authors: We acknowledge that the abstract provides only a high-level summary. The full manuscript contains the requested details in Section 4 (Experiments), including quantitative tables for all three tasks on both datasets, ablation studies on the Token-wise Fusion Module and Mutual Boosting mechanism, and error analyses. To directly address the concern and make the central claim more immediately verifiable, we will revise the abstract to include key quantitative results (e.g., PSNR/SSIM gains for novel-view synthesis, mIoU for open-vocabulary segmentation, and Abs Rel for depth estimation) while remaining concise. This is a minor change that strengthens the paper without altering its core contributions. revision: yes
Circularity Check
No significant circularity; derivation relies on external rendering supervision
full rationale
The paper describes FF3R as a feed-forward network trained end-to-end using only RGB and feature-map rendering losses on unconstrained multi-view sequences, without camera poses, depth, or semantic labels. The Token-wise Fusion Module (cross-attention enrichment) and Semantic-Geometry Mutual Boosting (geometry-guided warping plus semantic-aware voxelization) are presented as architectural components that mitigate inconsistencies, but no equations, parameter fits, or derivations are shown that reduce the claimed geometry or semantics to self-referential definitions or fitted inputs by construction. Supervision is external (rendering-based), the central claims remain independent of any self-citation chain, and the approach follows standard self-supervised reconstruction patterns without renaming known results or smuggling ansatzes. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the International Conference on Computer Vi- sion (ICCV), 2021. 2, 3, 5
2021
-
[2]
Jiazhong Cen, Jiemin Fang, Chen Yang, Lingxi Xie, Xi- aopeng Zhang, Wei Shen, and Qi Tian. Segment any 3d gaussians.arXiv preprint arXiv:2312.00860, 2023. 3
-
[3]
Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017. 3, 7, 8, 11
2017
-
[4]
Large spatial model: End- to-end unposed images to semantic 3d.arXiv preprint arXiv:2410.18956, 2024
Zhiwen Fan, Jian Zhang, Wenyan Cong, Peihao Wang, Renjie Li, Kairun Wen, Shijie Zhou, Achuta Kadambi, Zhangyang Wang, Danfei Xu, Boris Ivanovic, Marco Pavone, and Yue Wang. Large spatial model: End- to-end unposed images to semantic 3d.arXiv preprint arXiv:2410.18956, 2024. 2, 3, 5, 6, 7, 8, 11
-
[5]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Run- jin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, Hongyu Xu, Justin Theiss, Tianlong Chen, Jiachen Li, Zhengzhong Tu, Zhangyang Wang, and Rakesh Ranjan. Vlm-3r: Vision-language models aug- mented with instruction-aligned 3d reconstruction.arXiv preprint arXiv:2505.20279, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Fernando A. Fardo, Victor H. Conforto, Francisco C. de Oliveira, and Paulo S. Rodrigues. A formal evaluation of psnr as quality measurement parameter for image segmen- tation algorithms.arXiv preprint arXiv:1605.07116, 2016. 6
-
[7]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.arXiv preprint arXiv:2505.23716,
-
[8]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023. 1, 4, 11
2023
-
[9]
Lerf: Language embedded radiance fields
Justin* Kerr, Chung Min* Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. InInternational Conference on Computer Vision (ICCV), 2023. 3
2023
-
[10]
3d gaussian splat- ting as markov chain monte carlo
Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Wei- wei Sun, Yang-Che Tseng, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. 3d gaussian splat- ting as markov chain monte carlo. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. Spotlight Presentation. 3
2024
-
[11]
Garfield: Group anything with radiance fields.arXiv preprint arXiv:2401.09419, 2024
Chung Min* Kim, Mingxuan* Wu, Justin* Kerr, Matthew Tancik, Ken Goldberg, and Angjoo Kanazawa. Garfield: Group anything with radiance fields.arXiv preprint arXiv:2401.09419, 2024. 3
-
[12]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything.arXiv preprint arXiv:2304.02643, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[13]
Decomposing nerf for editing via feature field distilla- tion
Sosuke Kobayashi, Eiichi Matsumoto, and Vincent Sitz- mann. Decomposing nerf for editing via feature field distilla- tion. InAdvances in Neural Information Processing Systems,
-
[14]
Hyunjee Lee, Youngsik Yun, Jeongmin Bae, Seoha Kim, and Youngjung Uh. Rethinking open-vocabulary segmen- tation of radiance fields in 3d space.arXiv preprint arXiv:2408.07416, 2024. 3
-
[15]
Language-driven semantic seg- mentation
Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and Rene Ranftl. Language-driven semantic seg- mentation. InInternational Conference on Learning Rep- resentations, 2022. 2, 3, 4, 6, 7, 8, 11
2022
-
[16]
Hao Li, Zhengyu Zou, Fangfu Liu, Xuanyang Zhang, Fangzhou Hong, Yukang Cao, Yushi Lan, Manyuan Zhang, Gang Yu, Dingwen Zhang, and Ziwei Liu. Iggt: Instance- grounded geometry transformer for semantic 3d reconstruc- tion.arXiv preprint arXiv:2510.22706, 2024. 2, 3
-
[17]
Semanticsplat: Feed-forward 3d scene understanding with language-aware gaussian fields
Qijing Li, Jingxiang Sun, Liang An, Zhaoqi Su, Hongwen Zhang, and Yebin Liu. Semanticsplat: Feed-forward 3d scene understanding with language-aware gaussian fields. arXiv preprint arXiv:2506.09565, 2025. 3
-
[18]
Langsplatv2: High- dimensional 3d language gaussian splatting with 450+ fps
Wanhua Li, Yujie Zhao, Minghan Qin, Yang Liu, Yuanhao Cai, Chuang Gan, and Hanspeter Pfister. Langsplatv2: High- dimensional 3d language gaussian splatting with 450+ fps. Advances in Neural Information Processing Systems, 2025. 3
2025
-
[19]
Scenesplat: Gaussian splatting-based scene understanding with vision-language pretraining
Yue Li, Qi Ma, Runyi Yang, Huapeng Li, Mengjiao Ma, Bin Ren, Nikola Popovic, Nicu Sebe, Ender Konukoglu, Theo Gevers, et al. Scenesplat: Gaussian splatting-based scene understanding with vision-language pretraining. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), 2025. 2, 3
2025
-
[20]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024. 3, 7, 8, 11, 12, 14
2024
-
[21]
Xinyi Liu, Tianyi Zhang, Matthew Johnson-Roberson, and Weiming Zhi. Splatraj: Camera trajectory gener- ation with semantic gaussian splatting.arXiv preprint arXiv:2410.06014, 2024. 3
-
[22]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2019. 11
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20654–20664, 2024. 5
2024
-
[24]
Mengjiao Ma, Qi Ma, Yue Li, Jiahuan Cheng, Runyi Yang, Bin Ren, Nikola Popovic, Mingqiang Wei, Nicu Sebe, Luc Van Gool, et al. Scenesplat++: A large dataset and compre- hensive benchmark for language gaussian splatting.arXiv preprint arXiv:2506.08710, 2025. 3
-
[25]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis. InECCV, 2020. 1
2020
-
[26]
Understanding ssim.arXiv preprint arXiv:2006.13846, 2020
Jim Nilsson and Tomas Akenine-M ¨oller. Understanding ssim.arXiv preprint arXiv:2006.13846, 2020. 6
-
[27]
Maxime Oquab, Timoth ´ee Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Rus- sell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang- Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nico- las Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patri...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Langsplat: 3d language gaussian splatting,
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaussian splatting. arXiv preprint arXiv:2312.16084, 2023. 3
-
[29]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 2, 3, 5
2021
-
[30]
Vision transformers for dense prediction.arXiv preprint arXiv:2103.13413, 2021
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction.arXiv preprint arXiv:2103.13413, 2021. 4
-
[31]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Sch ¨onberger and Jan-Michael Frahm
Johannes L. Sch ¨onberger and Jan-Michael Frahm. Structure- from-motion revisited. In2016 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 4104– 4113, 2016. 1
2016
-
[33]
A Tutorial on Principal Component Analysis
Jonathon Shlens. A tutorial on principal component analysis. arXiv preprint arXiv:1404.1100, 2014. 5
work page Pith review arXiv 2014
-
[34]
Xiangyu Sun, Haoyi Jiang, Liu Liu, Seungtae Nam, Gyeongjin Kang, Xinjie Wang, Wei Sui, Zhizhong Su, Wenyu Liu, Xinggang Wang, and Eunbyung Park. Uni3r: Unified 3d reconstruction and semantic understanding via generalizable gaussian splatting from unposed multi-view images.arXiv preprint arXiv:2508.03643, 2025. 2, 3, 11
-
[35]
Splattalk: 3d vqa with gaussian splatting.arXiv preprint arXiv:2503.06271, 2025
Anh Thai, Songyou Peng, Kyle Genova, Leonidas Guibas, and Thomas Funkhouser. Splattalk: 3d vqa with gaussian splatting.arXiv preprint arXiv:2503.06271, 2025
-
[36]
Qijian Tian, Xin Tan, Jingyu Gong, Yuan Xie, and Lizhuang Ma. Uniforward: Unified 3d scene and semantic field re- construction via feed-forward gaussian splatting from only sparse-view images.arXiv preprint arXiv:2506.09378, 2025. 2, 3
-
[37]
3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024. 2
-
[38]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 1, 4, 6, 11
2025
-
[39]
Continuous 3d perception model with persistent state.arXiv preprint arXiv:2501.12387, 2025
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state.arXiv preprint arXiv:2501.12387, 2025
-
[40]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InCVPR, 2024. 1, 6, 11
2024
-
[41]
Qi Xu, Dongxu Wei, Lingzhe Zhao, Wenpu Li, Zhangchi Huang, Shunping Ji, and Peidong Liu. Siu3r: Simultaneous scene understanding and 3d reconstruction beyond feature alignment.arXiv preprint arXiv:2507.02705, 2025. 2, 3
-
[42]
arXiv preprint arXiv:2410.24207 (2024)
Botao Ye, Sifei Liu, Haofei Xu, Li Xueting, Marc Pollefeys, Ming-Hsuan Yang, and Peng Songyou. No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images.arXiv preprint arXiv:2410.24207, 2024. 2, 4
-
[43]
Featuren- erf: Learning generalizable nerfs by distilling foundation models
Jianglong Ye, Naiyan Wang, and Xiaolong Wang. Featuren- erf: Learning generalizable nerfs by distilling foundation models. InInternational Conference on Computer Vision (ICCV), 2023. 3
2023
-
[44]
Gaussian grouping: Segment and edit anything in 3d scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaussian grouping: Segment and edit anything in 3d scenes. InECCV, 2024. 3
2024
-
[45]
Scannet++: A high-fidelity dataset of 3d in- door scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d in- door scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023. 7
2023
-
[46]
Improving 2D Feature Representa- tions by 3D-Aware Fine-Tuning
Yuanwen Yue, Anurag Das, Francis Engelmann, Siyu Tang, and Jan Eric Lenssen. Improving 2D Feature Representa- tions by 3D-Aware Fine-Tuning. InEuropean Conference on Computer Vision (ECCV), 2024. 3
2024
-
[47]
Sigmoid loss for language image pre-training, 2023
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. arXiv preprint arXiv:2303.15343, 2023. 2
-
[48]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. 6
2018
-
[49]
Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields
Shijie Zhou, Haoran Chang, Sicheng Jiang, Zhiwen Fan, Ze- hao Zhu, Dejia Xu, Pradyumna Chari, Suya You, Zhangyang Wang, and Achuta Kadambi. Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21676–21685, 2024. 3, 6, 7, 8, 11
2024
-
[50]
Xingxing Zuo, Pouya Samangouei, Yunwen Zhou, Yan Di, and Mingyang Li. Fmgs: Foundation model embedded 3d gaussian splatting for holistic 3d scene understanding.arXiv preprint arXiv:2401.01970, 2024. 3 Appendix In the Appendix, we provide the following: • comprehensive implementation details in Section A • additional experiments, results, and discussions i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.