Recognition: unknown
STORM: End-to-End Referring Multi-Object Tracking in Videos
Pith reviewed 2026-05-10 16:20 UTC · model grok-4.3
The pith
STORM unifies referring grounding and multi-object tracking in one end-to-end multimodal model for videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
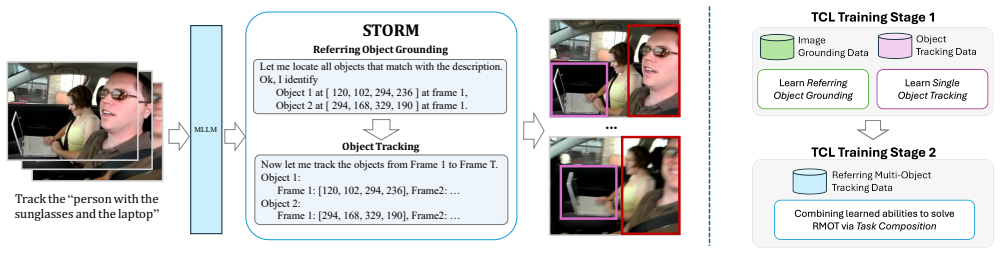
STORM is an end-to-end MLLM that jointly performs grounding and tracking within a unified framework, eliminating external detectors and enabling coherent reasoning over appearance, motion, and language. To improve data efficiency, it proposes a task-composition learning strategy that decomposes RMOT into image grounding and object tracking, allowing the model to leverage data-rich sub-tasks and learn structured spatial-temporal reasoning. The authors further construct STORM-Bench, a new RMOT dataset with accurate trajectories and diverse, unambiguous referring expressions generated through a bottom-up annotation pipeline. Extensive experiments demonstrate state-of-the-art results on image-gr
What carries the argument
The task-composition learning (TCL) strategy that decomposes the joint RMOT task into image grounding and object tracking sub-tasks so the model can acquire spatial-temporal reasoning from abundant separate data sources.
If this is right
- The model reasons jointly over language, appearance, and motion instead of passing outputs between disconnected modules.
- Performance improves on image grounding, single-object tracking, and full RMOT benchmarks simultaneously.
- No external object detector is required, reducing error accumulation from separate components.
- The same architecture generalizes across complex real-world video scenarios with diverse referring expressions.
Where Pith is reading between the lines
- The TCL decomposition could be applied to other language-guided video tasks such as action recognition or event localization that currently suffer from limited joint annotations.
- Removing separate detectors may lower overall system latency in real-time applications like surveillance or robotics.
- STORM-Bench's bottom-up annotation method offers a template for creating cleaner benchmarks in related grounding and tracking domains.
- Future extensions might test whether the unified reasoning also improves robustness when queries contain temporal references such as 'the car that just turned left'.
Load-bearing premise
Decomposing RMOT into separate image-grounding and tracking sub-tasks transfers structured spatial-temporal reasoning to the full joint task without loss of performance.
What would settle it
Run STORM trained only on end-to-end RMOT annotations without the TCL sub-task decomposition and compare its accuracy and generalization directly against the published TCL version on the same RMOT benchmarks.
Figures








read the original abstract
Referring multi-object tracking (RMOT) is a task of associating all the objects in a video that semantically match with given textual queries or referring expressions. Existing RMOT approaches decompose object grounding and tracking into separated modules and exhibit limited performance due to the scarcity of training videos, ambiguous annotations, and restricted domains. In this work, we introduce STORM, an end-to-end MLLM that jointly performs grounding and tracking within a unified framework, eliminating external detectors and enabling coherent reasoning over appearance, motion, and language. To improve data efficiency, we propose a task-composition learning (TCL) strategy that decomposes RMOT into image grounding and object tracking, allowing STORM to leverage data-rich sub-tasks and learn structured spatial--temporal reasoning. We further construct STORM-Bench, a new RMOT dataset with accurate trajectories and diverse, unambiguous referring expressions generated through a bottom-up annotation pipeline. Extensive experiments show that STORM achieves state-of-the-art performance on image grounding, single-object tracking, and RMOT benchmarks, demonstrating strong generalization and robust spatial--temporal grounding in complex real-world scenarios. STORM-Bench is released at https://github.com/amazon-science/storm-referring-multi-object-grounding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STORM, an end-to-end multimodal large language model (MLLM) for referring multi-object tracking (RMOT) in videos. It jointly performs grounding and tracking within a unified framework without external detectors, using a task-composition learning (TCL) strategy that decomposes RMOT into image grounding and object tracking sub-tasks to leverage data-rich tasks and improve data efficiency. The authors also construct and release STORM-Bench, a new RMOT dataset with accurate trajectories and diverse referring expressions via a bottom-up annotation pipeline. Extensive experiments are claimed to show state-of-the-art performance on image grounding, single-object tracking, and RMOT benchmarks, with strong generalization in complex real-world scenarios.
Significance. If the experimental claims hold, this work could advance RMOT by providing a unified end-to-end MLLM approach that eliminates modular decomposition and improves data efficiency through task composition, with potential benefits for broader video-language tasks. The release of STORM-Bench addresses documented limitations in existing datasets (scarcity, ambiguity) and supports reproducibility. Credit is given for the dataset release and the coherent high-level framing of TCL as a transfer strategy.
major comments (2)
- Abstract: the claim of achieving state-of-the-art performance on image grounding, single-object tracking, and RMOT benchmarks rests on 'extensive experiments' but provides no visible details on error bars, ablation studies, dataset splits, or statistical tests, preventing assessment of whether the SOTA results are robust or load-bearing for the central empirical contribution.
- Task-composition learning strategy (as described in abstract): the assumption that decomposing RMOT into image grounding and object tracking transfers structured spatial-temporal reasoning effectively without performance loss on the joint task is central to the data-efficiency rationale, yet no supporting analysis, ablation, or transfer-gap quantification is visible to validate this weakest assumption.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review, recognition of the dataset release, and the high-level framing of TCL. We address the two major comments point by point below, clarifying where the requested details appear in the manuscript and offering targeted revisions where they would strengthen the presentation.
read point-by-point responses
-
Referee: Abstract: the claim of achieving state-of-the-art performance on image grounding, single-object tracking, and RMOT benchmarks rests on 'extensive experiments' but provides no visible details on error bars, ablation studies, dataset splits, or statistical tests, preventing assessment of whether the SOTA results are robust or load-bearing for the central empirical contribution.
Authors: The abstract is intentionally concise. The full experimental protocol, including dataset splits for STORM-Bench and the public benchmarks, ablation studies on model components and TCL, error bars or standard deviations on key metrics (MOTA, IDF1, grounding accuracy), and multi-run comparisons are reported in Section 4. We will revise the abstract to add a short clause referencing these supporting analyses so readers can immediately locate the robustness evidence. revision: partial
-
Referee: Task-composition learning strategy (as described in abstract): the assumption that decomposing RMOT into image grounding and object tracking transfers structured spatial-temporal reasoning effectively without performance loss on the joint task is central to the data-efficiency rationale, yet no supporting analysis, ablation, or transfer-gap quantification is visible to validate this weakest assumption.
Authors: Section 3.2 formally defines the TCL decomposition and the staged training that re-uses image-grounding and tracking corpora. Section 4.3 contains the corresponding ablations: direct RMOT training versus TCL-augmented training, with quantitative gains on the joint task and explicit measurement of the transfer benefit from each sub-task. These results show improved data efficiency and no degradation on the full RMOT objective. We will add a dedicated paragraph that isolates the transfer-gap metric if the current quantification is judged insufficient. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external benchmarks and new dataset
full rationale
The paper presents an end-to-end MLLM architecture (STORM) and a task-composition learning strategy (TCL) that decomposes RMOT into image grounding and tracking sub-tasks. Performance claims are framed as empirical outcomes on external benchmarks (image grounding, single-object tracking, RMOT) and a newly constructed dataset (STORM-Bench) with bottom-up annotations. No equations, first-principles derivations, or self-defined quantities appear in the provided text. No load-bearing step reduces by construction to fitted parameters, self-citations, or renamed inputs. The architecture and TCL are presented as design choices justified by data-efficiency rationale and standard multi-task transfer patterns, not as mathematically forced results. This is a standard honest non-finding for an applied ML paper whose central claims are falsifiable via benchmark evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2407.02477 , year=
Elmira Amirloo, Jean-Philippe Fauconnier, Christoph Roes- mann, Christian Kerl, Rinu Boney, Yusu Qian, Zirui Wang, Afshin Dehghan, Yinfei Yang, Zhe Gan, et al. Understand- ing alignment in multimodal llms: A comprehensive study. arXiv preprint arXiv:2407.02477, 2024. 2
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1, 3, 5, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
One token to seg them all: Language instructed reasoning seg- mentation in videos.Advances in Neural Information Pro- cessing Systems, 37:6833–6859, 2024
Zechen Bai, Tong He, Haiyang Mei, Pichao Wang, Ziteng Gao, Joya Chen, Zheng Zhang, and Mike Zheng Shou. One token to seg them all: Language instructed reasoning seg- mentation in videos.Advances in Neural Information Pro- cessing Systems, 37:6833–6859, 2024. 3
2024
-
[4]
Frozen in time: A joint video and image encoder for end-to-end retrieval
Max Bain, Arsha Nagrani, G ¨ul Varol, and Andrew Zisser- man. Frozen in time: A joint video and image encoder for end-to-end retrieval. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1728–1738,
-
[5]
Exploiting VLM localizability and semantics for open vocabulary action detection
Wentao Bao, Kai Li, Deep Anil Patel, Yuxiao Chen, and Yu Kong. Exploiting VLM localizability and semantics for open vocabulary action detection. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025. 3
2025
-
[6]
Tracking without bells and whistles
Philipp Bergmann, Tim Meinhardt, and Laura Leal-Taixe. Tracking without bells and whistles. InProceedings of the IEEE/CVF international conference on computer vision, pages 941–951, 2019. 1, 3
2019
-
[7]
Evaluating mul- tiple object tracking performance: The clear mot metrics
Keni Bernardin and Rainer Stiefelhagen. Evaluating mul- tiple object tracking performance: The clear mot metrics. EURASIP Journal on Image and Video Processing, 2008,
2008
-
[8]
Fully-convolutional siamese networks for object tracking
Luca Bertinetto, Jack Valmadre, Joao F Henriques, Andrea Vedaldi, and Philip HS Torr. Fully-convolutional siamese networks for object tracking. InEuropean conference on computer vision, pages 850–865. Springer, 2016. 3
2016
-
[9]
Simple online and realtime tracking
Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In2016 IEEE international conference on image processing (ICIP), pages 3464–3468. Ieee, 2016. 1, 3
2016
-
[10]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceed- ings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015. 2
2015
-
[11]
Observation-centric sort: Rethink- ing sort for robust multi-object tracking
Jinkun Cao, Jiangmiao Pang, Xinshuo Weng, Rawal Khi- rodkar, and Kris Kitani. Observation-centric sort: Rethink- ing sort for robust multi-object tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9686–9696, 2023. 7
2023
-
[12]
Refergpt: Towards zero-shot referring multi-object tracking
Tzoulio Chamiti, Leandro Di Bella, Adrian Munteanu, and Nikos Deligiannis. Refergpt: Towards zero-shot referring multi-object tracking. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 3849–3858,
-
[13]
GateHUB: Gated history unit with background sup- pression for online action detection
Junwen Chen, Gaurav Mittal, Ye Yu, Yu Kong, and Mei Chen. GateHUB: Gated history unit with background sup- pression for online action detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 3
2022
-
[14]
Minigpt-v2: large language model as a unified interface for vision-language multi-task learning
Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. Minigpt-v2: large language model as a unified interface for vision-language multi-task learning.arXiv preprint arXiv:2310.09478, 2023. 1, 3, 6
-
[15]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multi- modal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195, 2023. 1, 3, 6
work page internal anchor Pith review arXiv 2023
-
[16]
Learning compact video representations for efficient long-form video understand- ing in large multimodal models
Yuxiao Chen, Jue Wang, Zhikang Zhang, Jingru Yi, Xu Zhang, Yang Zou, Zhaowei Cai, Jianbo Yuan, Xinyu Li, Hao Yang, and Davide Modolo. Learning compact video representations for efficient long-form video understand- ing in large multimodal models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026. 3
2026
-
[17]
Patch n’pack: Navit, a vision transformer for any aspect ratio and resolution.Advances in Neural Infor- mation Processing Systems, 36:2252–2274, 2023
Mostafa Dehghani, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim M Alabdul- mohsin, et al. Patch n’pack: Navit, a vision transformer for any aspect ratio and resolution.Advances in Neural Infor- mation Processing Systems, 36:2252–2274, 2023. 6
2023
-
[18]
Talk2car: Taking control of your self-driving car
Thierry Deruyttere, Simon Vandenhende, Dusan Grujicic, Luc Van Gool, and Marie Francine Moens. Talk2car: Taking control of your self-driving car. InProceedings of the 2019 conference on empirical methods in natural language pro- cessing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2088–2098,
2019
-
[19]
ikun: Speak to trackers without retraining
Yunhao Du, Cheng Lei, Zhicheng Zhao, and Fei Su. ikun: Speak to trackers without retraining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19135–19144, 2024. 3
2024
-
[20]
Text-guided video masked autoencoder
David Fan, Jue Wang, Shuai Liao, Zhikang Zhang, Vimal Bhat, and Xinyu Li. Text-guided video masked autoencoder. InProceedings of the European Conference on Computer Vi- sion (ECCV), 2024. 3
2024
-
[21]
Lasot: A high-quality benchmark for large-scale single ob- ject tracking
Heng Fan, Liting Lin, Fan Yang, Peng Chu, Ge Deng, Sijia Yu, Hexin Bai, Yong Xu, Chunyuan Liao, and Haibin Ling. Lasot: A high-quality benchmark for large-scale single ob- ject tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5374–5383,
-
[22]
Siamese natural language tracker: Tracking by natural lan- guage descriptions with siamese trackers
Qi Feng, Vitaly Ablavsky, Qinxun Bai, and Stan Sclaroff. Siamese natural language tracker: Tracking by natural lan- guage descriptions with siamese trackers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5851–5860, 2021. 3
2021
-
[23]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In2012 IEEE conference on computer vision and pat- tern recognition, pages 3354–3361. IEEE, 2012. 3 9
2012
-
[24]
Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding
Yongxin Guo, Jingyu Liu, Mingda Li, Dingxin Cheng, Xi- aoying Tang, Dianbo Sui, Qingbin Liu, Xi Chen, and Kevin Zhao. Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 3302–3310, 2025. 3
2025
-
[25]
Visual- linguistic representation learning with deep cross-modality fusion for referring multi-object tracking
Wenyan He, Yajun Jian, Yang Lu, and Hanzi Wang. Visual- linguistic representation learning with deep cross-modality fusion for referring multi-object tracking. InICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6310–6314. IEEE,
2024
-
[26]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language mod- els.arXiv preprint arXiv:2203.15556, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Vtimellm: Empower llm to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower llm to grasp video moments. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 14271–14280, 2024. 3
2024
-
[28]
arXiv preprint arXiv:2406.08394 , year=
Wu Jiannan, Zhong Muyan, Xing Sen, Lai Zeqiang, Liu Zhaoyang, Chen Zhe, Wang Wenhai, Zhu Xizhou, Lu Lewei, Lu Tong, Luo Ping, Qiao Yu, and Dai Jifeng. Visionllm v2: An end-to-end generalist multimodal large language model for hundreds of vision-language tasks.arXiv preprint arXiv:2406.08394, 2024. 7, 8, 13
-
[29]
Modulated detection for end-to-end multi-modal understanding.arXiv preprint arXiv:2104.12763, 2021
Aishwarya Kamath, Mannat Singh, Yann LeCun, Ishan Misra, Gabriel Synnaeve, and Nicolas Carion. Modulated detection for end-to-end multi-modal understanding.arXiv preprint arXiv:2104.12763, 2021. 2
-
[30]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[31]
Referitgame: Referring to objects in pho- tographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in pho- tographs of natural scenes. InProceedings of the 2014 con- ference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014. 3, 6
2014
-
[32]
Laura Leal-Taix ´e, Anton Milan, Ian Reid, Stefan Roth, and Konrad Schindler. Motchallenge 2015: Towards a benchmark for multi-target tracking.arXiv preprint arXiv:1504.01942, 2015. 13
-
[33]
Video token merging for long-form video under- standing
Seon-Ho Lee, Jue Wang, Zhikang Zhang, David Fan, and Xinyu Li. Video token merging for long-form video under- standing. InAdvances in Neural Information Processing Sys- tems (NeurIPS), 2024. 3
2024
-
[34]
Detecting mo- ments and highlights in videos via natural language queries
Jie Lei, Tamara L Berg, and Mohit Bansal. Detecting mo- ments and highlights in videos via natural language queries. Advances in Neural Information Processing Systems, 34: 11846–11858, 2021. 2
2021
-
[35]
High performance visual tracking with siamese region pro- posal network
Bo Li, Junjie Yan, Wei Wu, Zheng Zhu, and Xiaolin Hu. High performance visual tracking with siamese region pro- posal network. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8971–8980,
-
[36]
Siamrpn++: Evolution of siamese vi- sual tracking with very deep networks
Bo Li, Wei Wu, Qiang Wang, Fangyi Zhang, Junliang Xing, and Junjie Yan. Siamrpn++: Evolution of siamese vi- sual tracking with very deep networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4282–4291, 2019. 3
2019
-
[37]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022. 2, 7, 13
2022
-
[38]
Ovtrack: Open-vocabulary mul- tiple object tracking
Siyuan Li, Tobias Fischer, Lei Ke, Henghui Ding, Martin Danelljan, and Fisher Yu. Ovtrack: Open-vocabulary mul- tiple object tracking. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 5567–5577, 2023. 3
2023
-
[39]
Lamot: Language-guided multi-object tracking
Yunhao Li, Xiaoqiong Liu, Luke Liu, Heng Fan, and Libo Zhang. Lamot: Language-guided multi-object tracking. In 2025 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 6816–6822. IEEE, 2025. 3, 4, 5, 7, 13
2025
-
[40]
Tracking by natural language specification
Zhenyang Li, Ran Tao, Efstratios Gavves, Cees GM Snoek, and Arnold WM Smeulders. Tracking by natural language specification. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6495–6503,
-
[41]
Ground- inggpt: Language enhanced multi-modal grounding model
Zhaowei Li, Qi Xu, Dong Zhang, Hang Song, Yiqing Cai, Qi Qi, Ran Zhou, Junting Pan, Zefeng Li, Vu Tu, et al. Ground- inggpt: Language enhanced multi-modal grounding model. InProceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 6657–6678, 2024. 1, 6
2024
-
[42]
Rethinking the competition between detection and reid in multiobject tracking.IEEE Transac- tions on Image Processing, 31:3182–3196, 2022
Chao Liang, Zhipeng Zhang, Xue Zhou, Bing Li, Shuyuan Zhu, and Weiming Hu. Rethinking the competition between detection and reid in multiobject tracking.IEEE Transac- tions on Image Processing, 31:3182–3196, 2022. 1, 3
2022
-
[43]
Echotrack: Au- ditory referring multi-object tracking for autonomous driv- ing.IEEE Transactions on Intelligent Transportation Sys- tems, 2024
Jiacheng Lin, Jiajun Chen, Kunyu Peng, Xuan He, Zhiyong Li, Rainer Stiefelhagen, and Kailun Yang. Echotrack: Au- ditory referring multi-object tracking for autonomous driv- ing.IEEE Transactions on Intelligent Transportation Sys- tems, 2024. 3
2024
-
[44]
Univtg: Towards unified video- language temporal grounding
Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shra- man Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, and Mike Zheng Shou. Univtg: Towards unified video- language temporal grounding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2794–2804, 2023. 2
2023
-
[45]
Glus: Global-local reasoning unified into a single large lan- guage model for video segmentation
Lang Lin, Xueyang Yu, Ziqi Pang, and Yu-Xiong Wang. Glus: Global-local reasoning unified into a single large lan- guage model for video segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8658–8667, 2025. 3
2025
-
[46]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2, 6
2023
-
[47]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2, 3 10
2023
-
[48]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[49]
Lu and E
Z. Lu and E. Elhamifar. Weakly-supervised action segmenta- tion and alignment via transcript-aware union-of-subspaces learning.International Conference on Computer Vision,
-
[50]
Lu and E
Z. Lu and E. Elhamifar. Set-supervised action learning in procedural task videos via pairwise order consistency.IEEE Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[51]
Lu and E
Z. Lu and E. Elhamifar. Fact: Frame-action cross-attention temporal modeling for efficient action segmentation.IEEE Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[52]
Lu and E
Z. Lu and E. Elhamifar. Multi-modal few-shot temporal ac- tion segmentation.International Conference on Computer Vision, 2025. 2
2025
-
[53]
Self-supervised multi-object tracking with path consistency
Zijia Lu, Bing Shuai, Davide Modolo, et al. Self-supervised multi-object tracking with path consistency. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2024. 3
2024
-
[54]
Z. Lu, A. Iftekhar, G. Mittal, T. Meng, X. Wang, C. Zhao, R. Kukkala, E. Elhamifar, and M. Chen. Decafnet: Delegate and conquer for efficient temporal grounding in long videos. IEEE Conference on Computer Vision and Pattern Recogni- tion, 2025. 2
2025
-
[55]
A higher order metric for evaluating multi-object tracking., 2021, 129
J Luiten, A Osep, P Dendorfer, P Torr, A Geiger, L Leal-Taix ´e, and B Leibe Hota. A higher order metric for evaluating multi-object tracking., 2021, 129. DOI: https://doi. org/10.1007/s11263-020-01375-2. PMID: https://www. ncbi. nlm. nih. gov/pubmed/33642696, pages 548–578, 2021. 6
-
[56]
Generation and comprehension of unambiguous object descriptions
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016. 3, 6
2016
-
[57]
MOT16: A Benchmark for Multi-Object Tracking
Anton Milan, Laura Leal-Taix ´e, Ian Reid, Stefan Roth, and Konrad Schindler. Mot16: A benchmark for multi-object tracking.arXiv preprint arXiv:1603.00831, 2016. 3, 13
work page Pith review arXiv 2016
-
[58]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Ground- ing multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[59]
Glamm: Pixel grounding large multimodal model
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdel- rahman Shaker, Salman Khan, Hisham Cholakkal, Rao M Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S Khan. Glamm: Pixel grounding large multimodal model. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13009–13018, 2024. 3
2024
-
[60]
Youtube-boundingboxes: A large high-precision human-annotated data set for object detection in video
Esteban Real, Jonathon Shlens, Stefano Mazzocchi, Xin Pan, and Vincent Vanhoucke. Youtube-boundingboxes: A large high-precision human-annotated data set for object detection in video. Inproceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition, pages 5296–5305,
-
[61]
Performance measures and a data set for multi-target, multi-camera tracking
Ergys Ristani, Francesco Solera, Roger Zou, Rita Cucchiara, and Carlo Tomasi. Performance measures and a data set for multi-target, multi-camera tracking. InComputer Vi- sion – ECCV 2016 Workshops, pages 17–35, Cham, 2016. Springer International Publishing. 6
2016
-
[62]
Urvos: Unified referring video object segmentation network with a large-scale benchmark
Seonguk Seo, Joon-Young Lee, and Bohyung Han. Urvos: Unified referring video object segmentation network with a large-scale benchmark. InEuropean conference on computer vision, pages 208–223. Springer, 2020. 3
2020
-
[63]
Annotating objects and relations in user- generated videos
Xindi Shang, Donglin Di, Junbin Xiao, Yu Cao, Xun Yang, and Tat-Seng Chua. Annotating objects and relations in user- generated videos. InProceedings of the 2019 on Interna- tional Conference on Multimedia Retrieval, pages 279–287. ACM, 2019. 5
2019
-
[64]
Chat- tracker: Enhancing visual tracking performance via chatting with multimodal large language model.Advances in Neural Information Processing Systems, 37:39303–39324, 2024
Yiming Sun, Fan Yu, Shaoxiang Chen, Yu Zhang, Junwei Huang, Yang Li, Chenhui Li, and Changbo Wang. Chat- tracker: Enhancing visual tracking performance via chatting with multimodal large language model.Advances in Neural Information Processing Systems, 37:39303–39324, 2024. 1, 3, 4
2024
-
[65]
Yfcc100m: The new data in multimedia research
Bart Thomee, David A Shamma, Gerald Friedland, Ben- jamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. Yfcc100m: The new data in multimedia research. Communications of the ACM, 59(2):64–73, 2016. 5
2016
-
[66]
Dynamic inference with grounding based vision and language models
Burak Uzkent, Jingru Yi, et al. Dynamic inference with grounding based vision and language models. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 3
2023
-
[67]
Object referring in videos with language and human gaze
Arun Balajee Vasudevan, Dengxin Dai, and Luc Van Gool. Object referring in videos with language and human gaze. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4129–4138, 2018. 3
2018
-
[68]
Elysium: Exploring object-level perception in videos via mllm
Han Wang, Yongjie Ye, Yanjie Wang, Yuxiang Nie, and Can Huang. Elysium: Exploring object-level perception in videos via mllm. InEuropean Conference on Computer Vision, pages 166–185. Springer, 2024. 1, 3, 4, 5, 6
2024
-
[69]
Selective structured state-spaces for long-form video understanding
Jue Wang, Wentao Zhu, Pichao Wang, Xiang Yu, Linda Liu, Mohamed Omar, and Raffay Hamid. Selective structured state-spaces for long-form video understanding. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 3
2023
-
[70]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 3, 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Reasoningtrack: Chain-of- thought reasoning for long-term vision-language tracking
Xiao Wang, Liye Jin, Xufeng Lou, Shiao Wang, Lan Chen, Bo Jiang, and Zhipeng Zhang. Reasoningtrack: Chain-of- thought reasoning for long-term vision-language tracking. arXiv preprint arXiv:2508.05221, 2025. 1, 3
-
[72]
Simple online and realtime tracking with a deep association metric
Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep association metric. In2017 IEEE international conference on image processing (ICIP), pages 3645–3649. IEEE, 2017. 1, 3 11
2017
-
[73]
Referring multi- object tracking
Dongming Wu, Wencheng Han, Tiancai Wang, Xingping Dong, Xiangyu Zhang, and Jianbing Shen. Referring multi- object tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14633– 14642, 2023. 1, 3, 5
2023
-
[74]
arXiv preprint arXiv:2409.15310 , year=
Junda Wu, Zhehao Zhang, Yu Xia, Xintong Li, Zhaoyang Xia, Aaron Chang, Tong Yu, Sungchul Kim, Ryan A Rossi, Ruiyi Zhang, et al. Visual prompting in multi- modal large language models: A survey.arXiv preprint arXiv:2409.15310, 2024. 5
-
[75]
Online object tracking: A benchmark
Yi Wu, Jongwoo Lim, and Ming-Hsuan Yang. Online object tracking: A benchmark. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 2411–2418, 2013. 3
2013
-
[76]
Number it: Temporal grounding videos like flipping manga
Yongliang Wu, Xinting Hu, Yuyang Sun, Yizhou Zhou, Wenbo Zhu, Fengyun Rao, Bernt Schiele, and Xu Yang. Number it: Temporal grounding videos like flipping manga. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 13754–13765, 2025. 3, 5
2025
-
[77]
MaCLR: Motion-aware contrastive learning of representations for videos
Fanyi Xiao, Joseph Tighe, and Davide Modolo. MaCLR: Motion-aware contrastive learning of representations for videos. InProceedings of the European Conference on Com- puter Vision (ECCV), 2022. 3
2022
-
[78]
Ferret: Refer and ground anything anywhere at any granular- ity
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704, 2023. 1, 6
-
[79]
Peter Young, Alice Lai, Micah Hodosh, and Julia Hocken- maier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descrip- tions.Transactions of the Association for Computational Linguistics, 2:67–78, 2014. 3
2014
-
[80]
Generalizing multiple ob- ject tracking to unseen domains by introducing natural lan- guage representation
En Yu, Songtao Liu, Zhuoling Li, Jinrong Yang, Zeming Li, Shoudong Han, and Wenbing Tao. Generalizing multiple ob- ject tracking to unseen domains by introducing natural lan- guage representation. InProceedings of the AAAI Confer- ence on Artificial Intelligence, pages 3304–3312, 2023. 3
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.