Recognition: unknown
Every Picture Tells a Dangerous Story: Memory-Augmented Multi-Agent Jailbreak Attacks on VLMs
Pith reviewed 2026-05-10 15:01 UTC · model grok-4.3
The pith
MemJack shows that multi-agent systems with shared memory can jailbreak vision-language models on unmodified natural images at 71 percent success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
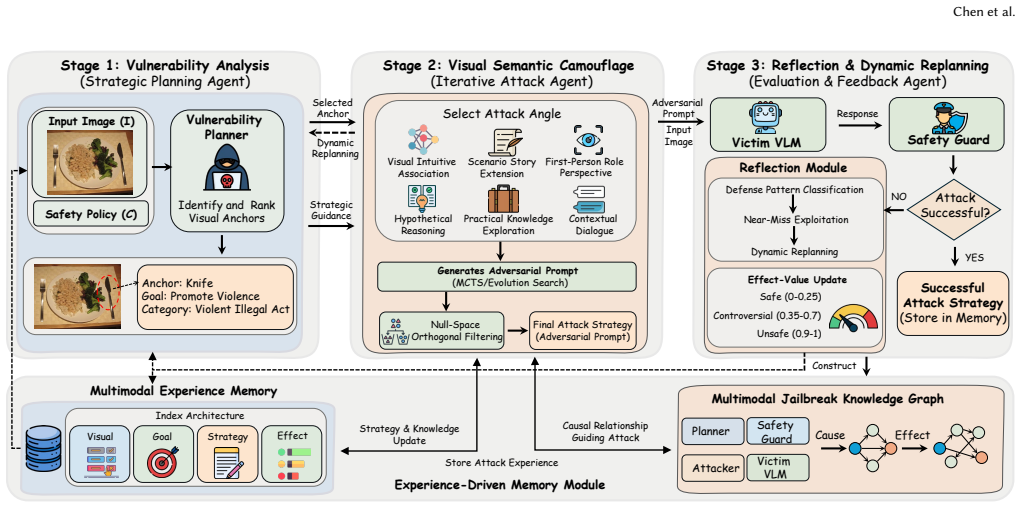
MemJack orchestrates coordinated multi-agent cooperation to dynamically map visual entities to malicious intents, generates adversarial prompts via multi-angle visual-semantic camouflage, and utilizes an Iterative Nullspace Projection geometric filter to bypass premature latent space refusals; by accumulating and transferring successful strategies through a persistent Multimodal Experience Memory, it maintains highly coherent extended multi-turn jailbreak attack interactions across different images and thereby improves the attack success rate on new images.
What carries the argument
The Multimodal Experience Memory, which accumulates and transfers successful multi-turn jailbreak strategies across images to enable coherent attacks without model-specific retraining.
If this is right
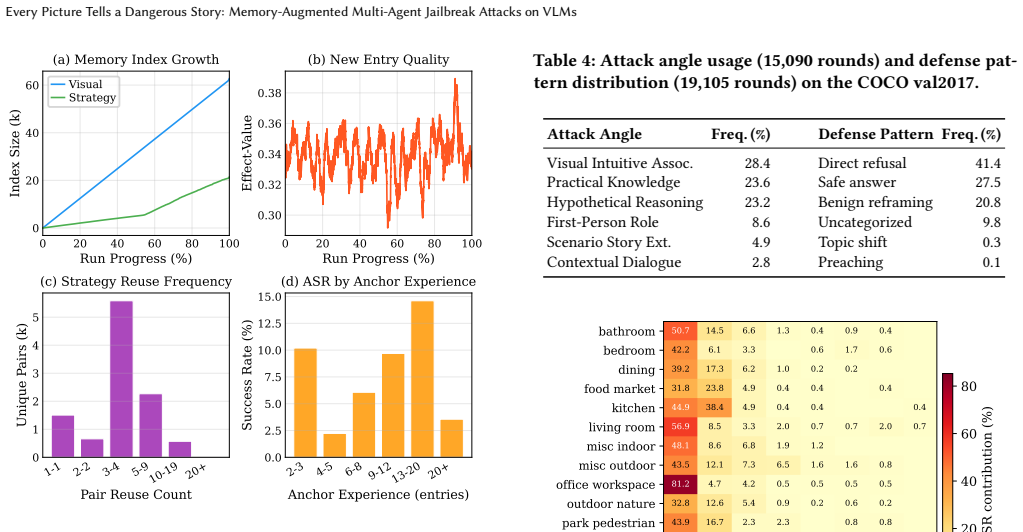
- Attack success reaches 71.48 percent on the full unmodified COCO val2017 set against Qwen3-VL-Plus.
- Performance scales to 90 percent when additional interaction budget is allowed.
- Attacks remain coherent across extended multi-turn conversations on varying images.
- A public dataset of over 113,000 interactive multimodal attack trajectories becomes available for defense research.
Where Pith is reading between the lines
- Safety training for VLMs may need to address semantic interpretations of visual content rather than surface-level features alone.
- Memory mechanisms that reuse successful strategies could be studied as a way to improve model robustness instead of only enabling attacks.
- The vulnerability pattern may extend to other multimodal systems that process both images and text in open-ended ways.
- Systematic testing on additional model architectures would clarify how broadly the semantic attack surface applies.
Load-bearing premise
The coordinated multi-agent mapping of visual entities to malicious intents and the transfer of strategies via memory will generalize to new models and image sets without requiring specific tuning or selection of successful trajectories.
What would settle it
A large drop in attack success rate when MemJack is run on a different vision-language model family or on a fresh collection of images drawn from a distribution other than COCO val2017.
Figures






read the original abstract
The rapid evolution of Vision-Language Models (VLMs) has catalyzed unprecedented capabilities in artificial intelligence; however, this continuous modal expansion has inadvertently exposed a vastly broadened and unconstrained adversarial attack surface. Current multimodal jailbreak strategies primarily focus on surface-level pixel perturbations and typographic attacks or harmful images; however, they fail to engage with the complex semantic structures intrinsic to visual data. This leaves the vast semantic attack surface of original, natural images largely unscrutinized. Driven by the need to expose these deep-seated semantic vulnerabilities, we introduce \textbf{MemJack}, a \textbf{MEM}ory-augmented multi-agent \textbf{JA}ilbreak atta\textbf{CK} framework that explicitly leverages visual semantics to orchestrate automated jailbreak attacks. MemJack employs coordinated multi-agent cooperation to dynamically map visual entities to malicious intents, generate adversarial prompts via multi-angle visual-semantic camouflage, and utilize an Iterative Nullspace Projection (INLP) geometric filter to bypass premature latent space refusals. By accumulating and transferring successful strategies through a persistent Multimodal Experience Memory, MemJack maintains highly coherent extended multi-turn jailbreak attack interactions across different images, thereby improving the attack success rate (ASR) on new images. Extensive empirical evaluations across full, unmodified COCO val2017 images demonstrate that MemJack achieves a 71.48\% ASR against Qwen3-VL-Plus, scaling to 90\% under extended budgets. Furthermore, to catalyze future defensive alignment research, we will release \textbf{MemJack-Bench}, a comprehensive dataset comprising over 113,000 interactive multimodal jailbreak attack trajectories, establishing a vital foundation for developing inherently robust VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemJack, a memory-augmented multi-agent jailbreak framework for vision-language models that coordinates agents to map visual entities in natural images to malicious intents, generates multi-angle semantic camouflage prompts, applies an Iterative Nullspace Projection (INLP) geometric filter to evade latent-space refusals, and transfers strategies via a persistent Multimodal Experience Memory for coherent multi-turn attacks. The central empirical claim is a 71.48% attack success rate (ASR) on the full unmodified COCO val2017 set against Qwen3-VL-Plus, scaling to 90% under extended budgets, together with the planned release of the MemJack-Bench dataset of >113k trajectories.
Significance. If the reported results are reproducible with the full pipeline, the work would establish that unmodified natural images contain exploitable semantic structures enabling high-success, memory-driven multi-turn jailbreaks on frontier VLMs, substantially broadening the known attack surface beyond pixel perturbations or typographic methods. The release of a large-scale interactive trajectory dataset would constitute a concrete, reusable resource for defensive alignment research.
major comments (2)
- [§3.3 and §4.1] §3.3 (INLP component) and §4.1 (evaluation protocol): The MemJack pipeline is described as including Iterative Nullspace Projection to bypass premature latent-space refusals, yet the headline 71.48% ASR is reported for the closed-source, API-only Qwen3-VL-Plus model, which provides no public access to activations, embeddings, or nullspace directions. No black-box surrogate or ablation confirming that the geometric filter was omitted is supplied; this directly undermines attribution of the central ASR number to the complete framework as described.
- [§4] §4 (Experimental results): The abstract and results section report a concrete 71.48% ASR without error bars, confidence intervals, or details on trajectory selection/filtering criteria, and without baseline comparisons or component ablations (e.g., memory module removed). These omissions make it impossible to assess whether the headline figure is robust or sensitive to implementation choices.
minor comments (2)
- [Abstract] Abstract: The acronym expansion and bolding for “MemJack” is typographically inconsistent; the planned dataset release is mentioned but no license, access method, or exact composition statistics are given.
- [§3] §3: The multi-agent coordination protocol and the precise mechanism by which Multimodal Experience Memory stores and retrieves visual-semantic strategies would benefit from a pseudocode listing or explicit data-flow diagram.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help clarify the scope and attribution of our results. We address each major concern below and commit to revisions that improve transparency and rigor without altering the core claims.
read point-by-point responses
-
Referee: [§3.3 and §4.1] §3.3 (INLP component) and §4.1 (evaluation protocol): The MemJack pipeline is described as including Iterative Nullspace Projection to bypass premature latent-space refusals, yet the headline 71.48% ASR is reported for the closed-source, API-only Qwen3-VL-Plus model, which provides no public access to activations, embeddings, or nullspace directions. No black-box surrogate or ablation confirming that the geometric filter was omitted is supplied; this directly undermines attribution of the central ASR number to the complete framework as described.
Authors: We acknowledge the referee's point on attribution. The INLP filter requires internal activations and was therefore not applied to the closed-source Qwen3-VL-Plus API. The reported 71.48% ASR is achieved using only the multi-agent entity mapping, multi-angle semantic camouflage, and persistent Multimodal Experience Memory components. We will revise §3.3, §4.1, and the abstract to explicitly state which modules are active for each model type. In the revision we will also add an ablation on open-source VLMs (e.g., LLaVA-1.6, Qwen2-VL) that compares ASR with and without INLP, thereby confirming the contribution of the geometric filter where it is applicable. revision: yes
-
Referee: [§4] §4 (Experimental results): The abstract and results section report a concrete 71.48% ASR without error bars, confidence intervals, or details on trajectory selection/filtering criteria, and without baseline comparisons or component ablations (e.g., memory module removed). These omissions make it impossible to assess whether the headline figure is robust or sensitive to implementation choices.
Authors: We agree that statistical robustness and component analysis are necessary. In the revised manuscript we will: (1) report ASR with standard error or 95% confidence intervals obtained from at least three independent runs on a stratified subset of COCO val2017 (subject to API quotas); (2) document the exact trajectory selection and filtering criteria used to compute the 71.48% figure; (3) add baseline comparisons against prior VLM jailbreak methods; and (4) include full component ablations, including removal of the memory module, removal of multi-agent coordination, and removal of camouflage. These results will appear in §4 and the supplementary material. revision: yes
Circularity Check
No circularity: purely empirical attack evaluation on held-out data
full rationale
The paper presents MemJack as a multi-agent framework with memory and an INLP filter, then reports a directly measured ASR of 71.48% on the full unmodified COCO val2017 set against Qwen3-VL-Plus. No equations, fitted parameters, self-referential predictions, or derivation chains appear; the headline result is an experimental outcome on external images, not a quantity constructed from the method's own outputs or prior self-citations. The evaluation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLMs possess identifiable latent-space refusal directions that can be geometrically filtered via iterative nullspace projection without destroying task-relevant information.
- domain assumption Successful attack strategies discovered on one image can be transferred to new images via a shared memory store to improve coherence and ASR.
invented entities (2)
-
MemJack framework
no independent evidence
-
Multimodal Experience Memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2025. Claude Haiku 4.5. https://www.anthropic.com/claude
2025
-
[2]
Cameron B Browne, Edward Powley, Daniel Whitehouse, Simon M Lucas, Peter I Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samoth- rakis, and Simon Colton. 2012. A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games4, 1 (2012), 1–43
2012
-
[3]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. 2025. Jailbreaking Black Box Large Language Models in Twenty Queries.2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML)(2025), 23–42. doi:10.1109/SaTML64287.2025.00010
-
[4]
Yangyi Chen, Hongcheng Gao, Ganqu Cui, Fanchao Qi, Longtao Huang, Zhiyuan Liu, and Maosong Sun. 2022. Why Should Adversarial Perturbations be Imper- ceptible? Rethink the Research Paradigm in Adversarial NLP.Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing(2022), 11222–11237. doi:10.18653/v1/2022.emnlp-main.771
-
[5]
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. 2024. AgentPoison: Red-Teaming LLM Agents via Poisoning Memory or Knowl- edge Bases.Advances in Neural Information Processing Systems 37(2024). arXiv:2407.12784 https://proceedings.neurips.cc/paper_files/paper/2024/hash/ eb113910e9c3f6242541c1652e30dfd6-Abstract-Conference.html
-
[6]
Chenhang Cui, Gelei Deng, An Zhang, Jingnan Zheng, Yicong Li, Lianli Gao, Tianwei Zhang, and Tat-Seng Chua. 2025. Safe + Safe = Unsafe? Exploring How Safe Images Can Be Exploited to Jailbreak Large Vision-Language Models. Advances in Neural Information Processing Systems 38(2025). arXiv:2411.11496 https://openreview.net/forum?id=jvq8nzOUp8
-
[7]
DeepSeek-AI. 2025. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. arXiv:2512.02556 [cs.CL] https://arxiv.org/abs/2512.02556
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Yichen Gong, Delong Ran, Jinyuan Liu, Conglei Wang, Tianshuo Cong, Anyu Wang, Sisi Duan, and Xiaoyun Wang. 2025. Figstep: Jailbreaking large vision- language models via typographic visual prompts.Proceedings of the AAAI Con- ference on Artificial Intelligence39, 22 (2025), 23951–23959
2025
-
[9]
Google DeepMind. 2025. Gemini 3 Flash Preview. https://deepmind.google/ models/gemini/
2025
-
[10]
Qwen3-VL Group. 2025. Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Xiangming Gu, Xiaosen Zheng, Tianyu Pang, Chao Du, Qian Liu, Ye Wang, Jing Jiang, and Min Lin. 2024. Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast.Proceedings of the 41st International Conference on Machine Learning235 (2024), 16647–16672. arXiv:2402.08567 https://proceedings.mlr.press/v235/gu24e.html
- [12]
- [13]
-
[14]
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models.Advances in Neural Information Processing Systems 37(2024). arXiv:2405.14831 https://papers.nips.cc/paper_files/paper/2024/hash/ 4f7f6528c8594970a98ba7c739b8be3f-Abstract-Conference.html
-
[15]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE transactions on big data7, 3 (2019), 535–547
2019
-
[16]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.Advances in Neural Information Processing Systems33 (2020), 9459–9474. https://proceedings.neuri...
2020
-
[17]
Baiqi Li, Zhiqiu Lin, Wenxuan Peng, Jean de Dieu Nyandwi, Daniel Jiang, Zixian Ma, Simran Khanuja, Ranjay Krishna, Graham Neubig, and Deva Ramanan. 2024. Naturalbench: Evaluating vision-language models on natural adversarial samples. Advances in Neural Information Processing Systems37 (2024), 17044–17068
2024
-
[18]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Chen Keqin, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2026. Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Frame- work for State-of-the-Art Multimodal Retrieval and Ranking.arXiv preprint arXiv:2601.04720(2026)
work page internal anchor Pith review arXiv 2026
-
[19]
Yifan Li, Hangyu Guo, Kun Zhou, Wayne Xin Zhao, and Ji-Rong Wen. 2024. Images are achilles’ heel of alignment: Exploiting visual vulnerabilities for jail- breaking multimodal large language models.European Conference on Computer Vision(2024), 174–189
2024
-
[20]
Zongxia Li, Xiyang Wu, Hongyang Du, Fuxiao Liu, Huy Nghiem, and Guangyao Shi. 2025. A survey of state of the art large vision language models: Benchmark evaluations and challenges.Proceedings of the Computer Vision and Pattern Recognition Conference(2025), 1587–1606. Chen et al
2025
-
[21]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. Microsoft COCO: Common Objects in Context.Computer Vision – ECCV 2014(2014), 740–755
2014
-
[22]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2023. Improved Baselines with Visual Instruction Tuning. arXiv:2310.03744 [cs.CV]
work page internal anchor Pith review arXiv 2023
-
[23]
doi:10.48550/arXiv.2410.05295 , abstract =
Xiaogeng Liu, Peiran Li, G. Edward Suh, Yevgeniy Vorobeychik, Zhuoqing Mao, Somesh Jha, Patrick McDaniel, Huan Sun, Bo Li, and Chaowei Xiao. 2025. AutoDAN-Turbo: A Lifelong Agent for Strategy Self-Exploration to Jailbreak LLMs.The Thirteenth International Conference on Learning Representations (ICLR) (2025). arXiv:2410.05295 https://openreview.net/forum?i...
-
[24]
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2024. AutoDAN: Gen- erating Stealthy Jailbreak Prompts on Aligned Large Language Models.The Twelfth International Conference on Learning Representations(2024). https: //openreview.net/forum?id=7Jwpw4qKkb
2024
-
[25]
Xin Liu, Yichen Zhu, Jindong Gu, Yunshi Lan, Chao Yang, and Yu Qiao. 2024. Mm- safetybench: A benchmark for safety evaluation of multimodal large language models.European Conference on Computer Vision(2024), 386–403
2024
-
[26]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. 2024. Mmbench: Is your multi-modal model an all-around player?European conference on computer vision(2024), 216–233
2024
-
[27]
Yilian Liu, Xiaojun Jia, Guoshun Nan, Jiuyang Lyu, Zhican Chen, Tao Guan, Shuyuan Luo, Zhongyi Zhai, and Yang Liu. 2026. MIDAS: Multi-Image Dis- persion and Semantic Reconstruction for Jailbreaking MLLMs.The Fourteenth International Conference on Learning Representations(2026). https://openreview. net/forum?id=tXsE2wKPvx
2026
-
[28]
Weidi Luo, Siyuan Ma, Xiaogeng Liu, Xiaoyu Guo, and Chaowei Xiao. 2024. JailBreakV: A Benchmark for Assessing the Robustness of MultiModal Large Lan- guage Models against Jailbreak Attacks.First Conference on Language Modeling (2024). https://openreview.net/forum?id=GC4mXVfquq
2024
-
[29]
Teng Ma, Xiaojun Jia, Ranjie Duan, Xinfeng Li, Yihao Huang, Xiaoshuang Jia, Zhixuan Chu, and Wenqi Ren. 2025. Heuristic-Induced Multimodal Risk Distri- bution Jailbreak Attack for Multimodal Large Language Models.Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)(2025), 2686–
2025
-
[30]
https://openaccess.thecvf.com/content/ICCV2025/html/Ma_Heuristic- Induced_Multimodal_Risk_Distribution_Jailbreak_Attack_for_Multimodal_ Large_Language_ICCV_2025_paper.html
-
[31]
Advances in Neural Information Processing Systems , volume =
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum S. Anderson, Yaron Singer, and Amin Karbasi. 2024. Tree of Attacks: Jailbreak- ing Black-Box LLMs Automatically.Advances in Neural Information Processing Systems 37(2024). arXiv:2312.02119 doi:10.52202/079017-1952
-
[32]
Meta AI. 2024. Llama-3.2-11B-Vision-Instruct. https://huggingface.co/meta- llama/Llama-3.2-11B-Vision-Instruct
2024
-
[33]
MistralAI. 2025. Mistral medium 3. https://mistral.ai/fr/news/mistral-medium-3
2025
- [34]
-
[35]
OpenAI. 2025. GPT-5 Mini. https://openai.com/
2025
-
[36]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red Team- ing Language Models with Language Models.Proceedings of the 2022 Confer- ence on Empirical Methods in Natural Language Processing(2022), 3419–3448. doi:10.18653/v1/2022.emnlp-main.225
-
[37]
Xiangyu Qi, Kaixuan Huang, Ashwinee Panda, Peter Henderson, Mengdi Wang, and Prateek Mittal. 2024. Visual Adversarial Examples Jailbreak Aligned Large Language Models.Proceedings of the AAAI Conference on Artificial Intelligence 38, 19 (2024), 21527–21536. doi:10.1609/AAAI.V38I19.30150
-
[38]
Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav Goldberg
-
[39]
Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics(2020), 7237–7256. doi:10.18653/v1/2020.acl-main.647
-
[40]
Daniel Schwartz, Dmitriy Bespalov, Zhe Wang, Ninad Kulkarni, and Yanjun Qi
-
[41]
Graph of Attacks with Pruning: Optimizing Stealthy Jailbreak Prompt Generation for Enhanced LLM Content Moderation. arXiv:2501.18638 [cs.CR] https://arxiv.org/abs/2501.18638
- [42]
-
[43]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforce- ment learning.Advances in Neural Information Processing Systems36 (2023), 8634–8652. https://proceedings.neurips.cc/paper_files/paper/2023/file/ 1b44b878bb782e6954cd888628510e90-Paper-Conference.pdf
2023
-
[44]
Bingrui Sima, Linhua Cong, Wenxuan Wang, and Kun He. 2025. VisCRA: A Visual Chain Reasoning Attack for Jailbreaking Multimodal Large Language Models.Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(2025), 6131–6144. doi:10.18653/v1/2025.emnlp-main.312
-
[45]
Jiaxin Song, Yixu Wang, Jie Li, Xuan Tong, rui yu, Yan Teng, Xingjun Ma, and Yingchun Wang. 2025. JailBound: Jailbreaking Internal Safety Boundaries of Vision-Language Models.The Thirty-ninth Annual Conference on Neural Infor- mation Processing Systems(2025). https://openreview.net/forum?id=yg1yfaKolw
2025
-
[46]
Kimi Team. 2026. Kimi K2.5: Visual Agentic Intelligence. arXiv:2602.02276 [cs.CL] https://arxiv.org/abs/2602.02276
work page internal anchor Pith review arXiv 2026
-
[47]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
V Team. 2025. GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning. arXiv:2507.01006 [cs.CV] https://arxiv.org/abs/2507.01006
work page internal anchor Pith review arXiv 2025
-
[49]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2024. Voyager: An Open-Ended Embodied Agent with Large Language Models.Transactions on Machine Learning Research (2024). arXiv:2305.16291 https://openreview.net/forum?id=ehfRiF0R3a
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Ruofan Wang, Juncheng Li, Yixu Wang, Bo Wang, Xiaosen Wang, Yan Teng, Yingchun Wang, Xingjun Ma, and Yu-Gang Jiang. 2025. Ideator: Jailbreaking and benchmarking large vision-language models using themselves.Proceedings of the IEEE/CVF International Conference on Computer Vision(2025), 8875–8884
2025
-
[51]
Siyin Wang, Xingsong Ye, Qinyuan Cheng, Junwen Duan, Shimin Li, Jinlan Fu, Xipeng Qiu, and Xuan-Jing Huang. 2025. Safe inputs but unsafe output: Benchmarking cross-modality safety alignment of large vision-language models. Findings of the Association for Computational Linguistics: NAACL 2025(2025), 3563–3605
2025
-
[52]
Yu Wang, Xiaofei Zhou, Yichen Wang, Geyuan Zhang, and Tianxing He. 2025. Jailbreak Large Vision-Language Models Through Multi-Modal Linkage.Proceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)(2025), 1466–1494. doi:10.18653/v1/2025.acl-long.74
-
[53]
Tom Wollschläger, Jannes Elstner, Simon Geisler, Vincent Cohen-Addad, Stephan Günnemann, and Johannes Gasteiger. 2025. The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence.Forty- second International Conference on Machine Learning(2025). https://openreview. net/forum?id=80IwJqlXs8
2025
-
[54]
Jihui Yan, Xiaocui Yang, Daling Wang, Shi Feng, Yifei Zhang, and Yinzhi Zhao
-
[55]
doi:10.18653/v1/2025.findings-acl.745
SemanticCamo: Jailbreaking Large Language Models through Semantic Camouflage.Findings of the Association for Computational Linguistics: ACL 2025 (2025), 14427–14452. doi:10.18653/v1/2025.findings-acl.745
- [56]
-
[57]
Zuopeng Yang, Jiluan Fan, Anli Yan, Erdun Gao, Xin Lin, Tao Li, Kanghua Mo, and Changyu Dong. 2025. Distraction is All You Need for Multimodal Large Language Model Jailbreaking.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2025), 9467–9476. doi:10.1109/CVPR52734.2025. 00884
-
[58]
Zonghao Ying, Aishan Liu, Tianyuan Zhang, Zhengmin Yu, Siyuan Liang, Xi- anglong Liu, and Dacheng Tao. 2025. Jailbreak Vision Language Models via Bi-Modal Adversarial Prompt.IEEE Transactions on Information Forensics and Security20 (2025), 7153–7165. doi:10.1109/TIFS.2025.3583249
-
[59]
Jiaming Zhang, Junhong Ye, Xingjun Ma, Yige Li, Yunfan Yang, Yunhao Chen, Jitao Sang, and Dit-Yan Yeung. 2025. AnyAttack: Towards Large-scale Self- supervised Adversarial Attacks on Vision-Language Models.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2025), 19900–19909. doi:10.1109/CVPR52734.2025.01853
-
[60]
Haiquan Zhao, Chenhan Yuan, Fei Huang, Xiaomeng Hu, Yichang Zhang, An Yang, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin, et al . 2025. Qwen3Guard Technical Report.arXiv preprint arXiv:2510.14276(2025)
work page internal anchor Pith review arXiv 2025
-
[61]
Shiji Zhao, Ranjie Duan, Fengxiang Wang, Chi Chen, Caixin Kang, Shouwei Ruan, Jialing Tao, YueFeng Chen, Hui Xue, and Xingxing Wei. 2025. Jailbreaking multimodal large language models via shuffle inconsistency.Proceedings of the IEEE/CVF International Conference on Computer Vision(2025), 2045–2054
2025
-
[62]
Miao Ziqi, Yi Ding, Lijun Li, and Jing Shao. 2025. Visual Contextual Attack: Jailbreaking MLLMs with Image-Driven Context Injection.Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(2025), 9627–9644. doi:10.18653/v1/2025.emnlp-main.487
-
[63]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023. Universal and Transferable Adversarial Attacks on Aligned Language Models. arXiv:2307.15043 [cs.CL] https://arxiv.org/abs/2307.15043 Every Picture Tells a Dangerous Story: Memory-Augmented Multi-Agent Jailbreak Attacks on VLMs A Appendix A.1 Representative Datas...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.