Recognition: 2 theorem links
· Lean TheoremLossless Prompt Compression via Dictionary-Encoding and In-Context Learning: Enabling Cost-Effective LLM Analysis of Repetitive Data
Pith reviewed 2026-05-15 07:53 UTC · model grok-4.3
The pith
LLMs learn encoding keys from a system prompt dictionary and analyze compressed repetitive data directly, matching uncompressed results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
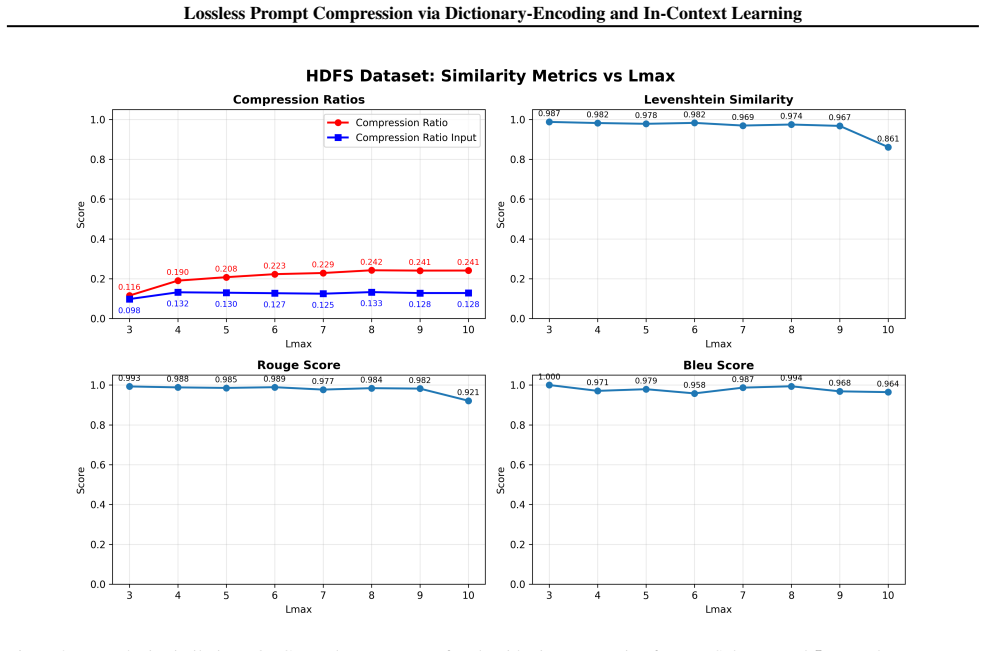
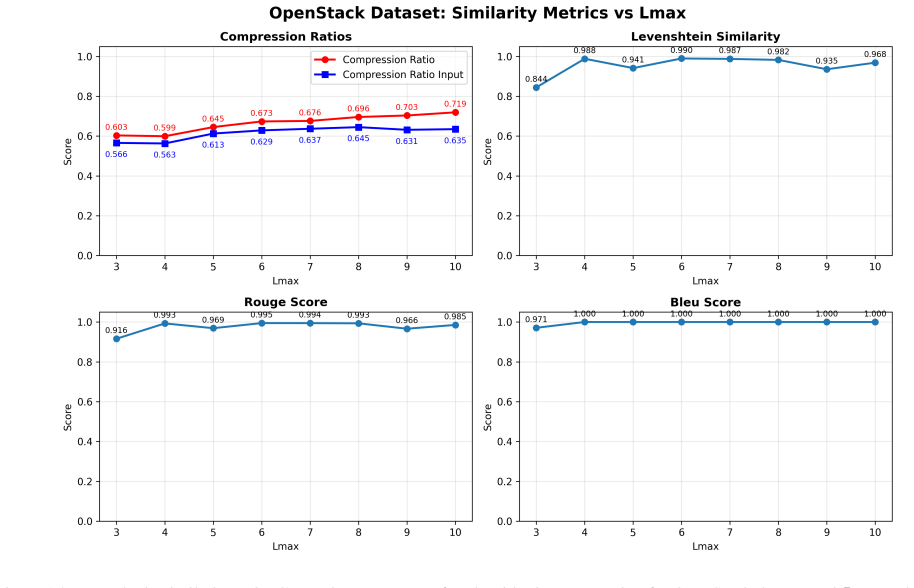
The paper establishes that LLMs, when supplied with a compression dictionary in the system prompt, correctly interpret meta-tokens and perform analysis on the encoded representation, producing outputs equivalent to those obtained from the original uncompressed inputs. This holds for a multi-scale dictionary-encoding algorithm that identifies repetitive subsequences and substitutes them with compact meta-tokens under a token-savings optimization rule. Experiments on LogHub 2.0 using Claude 3.7 Sonnet confirm equivalence via a decompression proxy task, with exact matches exceeding 0.99 for template compression and average similarity above 0.91 for algorithmic compression at 60-80 percent rates
What carries the argument
Dictionary encoding that replaces frequent subsequences with meta-tokens, with the mapping provided in the system prompt so the LLM learns the encoding in-context and operates directly on the compressed sequence.
If this is right
- Token counts and API costs drop substantially for repetitive data while output equivalence is retained.
- No fine-tuning or training is required, allowing immediate use with existing API-based LLMs.
- Datasets exceeding normal token limits become analyzable without truncation or summarization.
- Compression quality remains stable across varying ratios, depending instead on inherent data repetition.
- The method adapts automatically as repetitive patterns shift in evolving datasets.
Where Pith is reading between the lines
- The approach may extend to structured text domains such as code or configuration files that contain repeated blocks.
- Combining dictionary encoding with other token-reduction techniques could produce additive efficiency gains.
- Real-time streaming applications like log monitoring could apply ongoing dictionary updates for sustained savings.
- Dictionary size limits imposed by context windows may require separate optimization for very large vocabularies.
Load-bearing premise
Supplying the compression dictionary in the system prompt is sufficient for the LLM to interpret meta-tokens correctly during analysis without misreading or hallucinating the mapping.
What would settle it
An instance where analysis output on the dictionary-provided compressed prompt differs from output on the matching uncompressed prompt.
Figures

















read the original abstract
In-context learning has established itself as an important learning paradigm for Large Language Models (LLMs). In this paper, we demonstrate that LLMs can learn encoding keys in-context and perform analysis directly on encoded representations. This finding enables lossless prompt compression via dictionary encoding without model fine-tuning: frequently occurring subsequences are replaced with compact meta-tokens, and when provided with the compression dictionary in the system prompt, LLMs correctly interpret these meta-tokens during analysis, producing outputs equivalent to those from uncompressed inputs. We present a compression algorithm that identifies repetitive patterns at multiple length scales, incorporating a token-savings optimization criterion that ensures compression reduces costs by preventing dictionary overhead from exceeding savings. The algorithm achieves compression ratios up to 80$\%$ depending on dataset characteristics. To validate that LLM analytical accuracy is preserved under compression, we use decompression as a proxy task with unambiguous ground truth. Evaluation on the LogHub 2.0 benchmark using Claude 3.7 Sonnet demonstrates exact match rates exceeding 0.99 for template-based compression and average Levenshtein similarity scores above 0.91 for algorithmic compression, even at compression ratios of 60$\%$-80$\%$. Additionally, compression ratio explains less than 2$\%$ of variance in similarity metrics, indicating that decompression quality depends on dataset characteristics rather than compression intensity. This training-free approach works with API-based LLMs, directly addressing fundamental deployment constraints -- token limits and API costs -- and enabling cost-effective analysis of large-scale repetitive datasets, even as data patterns evolve over time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that LLMs can learn encoding keys in-context from a system prompt containing a compression dictionary and perform analysis directly on dictionary-encoded meta-token representations, producing outputs equivalent to those from uncompressed inputs. It introduces a multi-scale dictionary compression algorithm with a token-savings optimization criterion that achieves up to 80% compression on repetitive data. Validation uses a decompression proxy task on LogHub 2.0 with Claude 3.7 Sonnet, reporting exact match >0.99 for template-based compression and Levenshtein similarity >0.91 for algorithmic compression, with compression ratio explaining <2% of variance in similarity metrics.
Significance. If the central claim holds, the work would provide a training-free method for substantial token and cost reduction in LLM analysis of repetitive datasets such as logs, directly addressing API limits and expenses while allowing patterns to evolve. The proxy metrics are quantitatively strong and the validation is non-circular, but the significance is limited by the gap between the claimed direct analytical use of encoded representations and the decompression-based evidence provided.
major comments (2)
- [Evaluation] The validation relies exclusively on a decompression proxy task (exact match and Levenshtein metrics) rather than direct analytical tasks performed on the encoded meta-token inputs. This tests token-to-text reconstruction but does not establish whether the LLM executes the intended reasoning steps over the compressed representation itself, which is required to support the claim of cost-effective analysis on encoded data. See abstract paragraph on validation and the evaluation description.
- [Methods] The compression algorithm is described at a high level (multi-scale pattern identification and token-savings optimization to avoid dictionary overhead exceeding savings) but lacks the precise pseudocode, decision criteria for subsequence selection, and handling of edge cases needed for reproducibility. Without these details it is difficult to verify that the reported 60-80% ratios are achieved under the stated constraints.
minor comments (2)
- [Abstract] Clarify the exact model version (Claude 3.7 Sonnet appears to be a typographical error for Claude 3.5 Sonnet or the current release).
- [Results] Ensure all figures showing compression ratios versus similarity metrics include error bars or statistical controls and are referenced in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the empirical support and reproducibility of our work. We address each major comment below and will incorporate revisions to enhance the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation] The validation relies exclusively on a decompression proxy task (exact match and Levenshtein metrics) rather than direct analytical tasks performed on the encoded meta-token inputs. This tests token-to-text reconstruction but does not establish whether the LLM executes the intended reasoning steps over the compressed representation itself, which is required to support the claim of cost-effective analysis on encoded data. See abstract paragraph on validation and the evaluation description.
Authors: We appreciate this distinction. The decompression proxy was selected to provide unambiguous ground truth while testing whether the LLM correctly interprets meta-tokens from the in-context dictionary; the reported exact match rates exceeding 0.99 and Levenshtein similarities above 0.91 indicate faithful reconstruction, which is a necessary precondition for any downstream reasoning on the compressed form. Nevertheless, to more directly demonstrate analytical capabilities, we will revise the evaluation section to include direct analytical tasks (such as anomaly detection and summarization) performed on encoded inputs, with outputs compared against uncompressed baselines. These additions will be detailed in the revised manuscript. revision: yes
-
Referee: [Methods] The compression algorithm is described at a high level (multi-scale pattern identification and token-savings optimization to avoid dictionary overhead exceeding savings) but lacks the precise pseudocode, decision criteria for subsequence selection, and handling of edge cases needed for reproducibility. Without these details it is difficult to verify that the reported 60-80% ratios are achieved under the stated constraints.
Authors: We agree that greater specificity is required for reproducibility. In the revised manuscript, we will augment the Methods section with full pseudocode for the multi-scale algorithm, explicit decision criteria for subsequence selection (including frequency thresholds, length scales, and the token-savings optimization formula), and discussion of edge-case handling such as overlapping patterns, minimum occurrence requirements, and dictionary size constraints. This will enable verification of the reported compression ratios. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central demonstration relies on an empirical compression algorithm that identifies repetitive patterns and a separate validation using decompression as an independent proxy task with unambiguous ground truth (exact match and Levenshtein metrics). No equations, fitted parameters, or results reduce by construction to the inputs or to self-citations; the token-savings criterion and in-context interpretation are defined externally to the analytical equivalence claim. The derivation remains self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can learn and apply encoding keys provided in the system prompt during analysis tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
lossless prompt compression via dictionary encoding... meta-tokens... token-savings optimization criterion
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LLMs can learn encoding keys in-context and perform analysis directly on encoded representations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2403. 18119. Zhu, X. et al. Loghub: A large collection of system log datasets towards automated log analytics. EMSE, 28:54,
-
[2]
URL https: //doi.org/10.1186/s40411-023-00194-9
doi: 10.1186/s40411-023-00194-9. URL https: //doi.org/10.1186/s40411-023-00194-9 . A D ATASET TOKEN STATISTICS Table 3 presents the original token counts for each dataset in the LogHub-2k experiments, computed using the Claude tokenizer. B T EMPLATE -BASED DECOMPRESSION DETAILED METRICS Table 4 presents per-dataset metrics for template-based de- compressi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.