Recognition: unknown
UHR-BAT: Budget-Aware Token Compression Vision-Language model for Ultra-High-Resolution Remote Sensing
Pith reviewed 2026-05-10 13:50 UTC · model grok-4.3
The pith
UHR-BAT selects visual tokens from ultra-high-resolution remote sensing images using text-guided multi-scale importance to stay inside a fixed token budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UHR-BAT is a query-guided and region-faithful token compression framework that uses text-guided multi-scale importance estimation to score visual tokens and applies region-wise preserve and merge strategies to reduce redundancy, thereby selecting a budgeted set of tokens that still supports state-of-the-art performance on ultra-high-resolution remote sensing benchmarks.
What carries the argument
Text-guided multi-scale importance estimation combined with region-wise preserve and merge strategies that decide which visual tokens to keep or combine under a fixed context budget.
If this is right
- The same compression pipeline can be applied to any vision-language task where image size produces too many tokens for the available context window.
- Region-wise merging reduces token count more efficiently than uniform global top-k selection while attempting to keep spatial relationships intact.
- Multi-scale scoring allows the model to consider both large-scale scene layout and fine local details in one pass without separate tiling steps.
- Performance gains appear across multiple remote sensing benchmarks when the token budget is held constant.
Where Pith is reading between the lines
- The same importance-plus-merge logic could be tested on other high-resolution domains such as medical whole-slide images or aerial photography of urban areas.
- If the merge operations preserve enough local structure, the approach might reduce the need for separate object detectors before feeding images to a vision-language model.
- Extending the multi-scale estimation to include explicit scale weighting based on query type could further reduce cases where tiny but decisive objects are overlooked.
Load-bearing premise
Text-guided multi-scale importance estimation can reliably locate and preserve every piece of query-critical evidence, including objects only a few pixels wide, without systematic omission caused by the region-wise merge steps.
What would settle it
A controlled test in which a model using the full uncompressed image answers a query correctly about a sub-pixel or few-pixel object, yet the same model using UHR-BAT's compressed tokens answers incorrectly because the object was dropped during importance scoring or merging.
Figures















read the original abstract
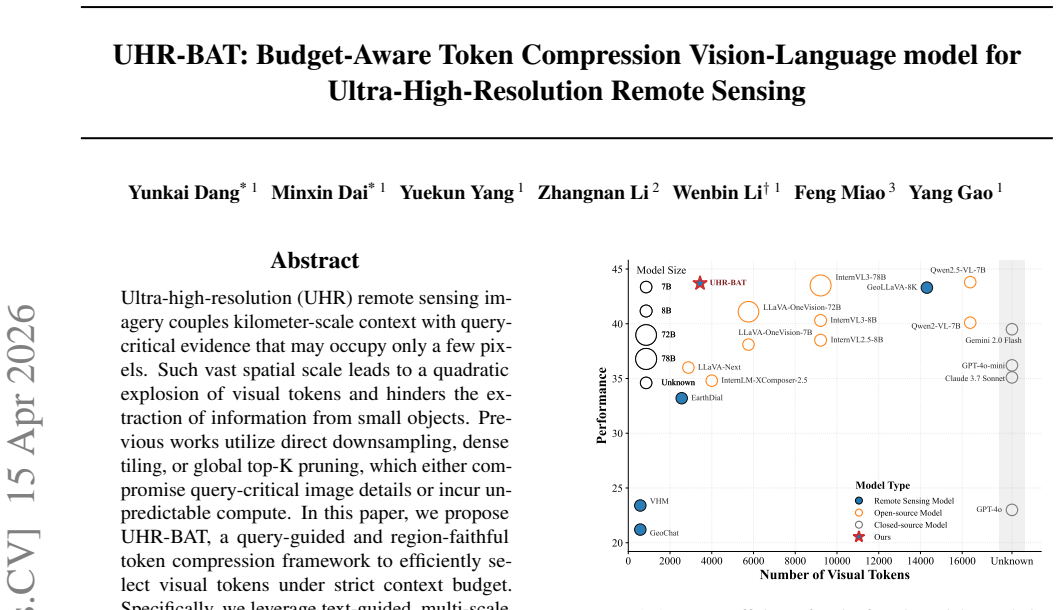
Ultra-high-resolution (UHR) remote sensing imagery couples kilometer-scale context with query-critical evidence that may occupy only a few pixels. Such vast spatial scale leads to a quadratic explosion of visual tokens and hinders the extraction of information from small objects. Previous works utilize direct downsampling, dense tiling, or global top-k pruning, which either compromise query-critical image details or incur unpredictable compute. In this paper, we propose UHR-BAT, a query-guided and region-faithful token compression framework to efficiently select visual tokens under a strict context budget. Specifically, we leverage text-guided, multi-scale importance estimation for visual tokens, effectively tackling the challenge of achieving precise yet low-cost feature extraction. Furthermore, by introducing region-wise preserve and merge strategies, we mitigate visual token redundancy, further driving down the computational budget. Experimental results show that UHR-BAT achieves state-of-the-art performance across various benchmarks. Code will be available at https://github.com/Yunkaidang/UHR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UHR-BAT, a query-guided token compression framework for vision-language models on ultra-high-resolution remote sensing imagery. It uses text-guided multi-scale importance estimation of visual tokens together with region-wise preserve (top-k per region) and merge (average/concatenate) operations to select tokens under a fixed context budget, and claims state-of-the-art performance on various benchmarks.
Significance. If the performance claims are substantiated, the work addresses a practically important scaling problem in remote-sensing VLMs where kilometer-scale context coexists with query-critical evidence that may occupy only a few pixels. A reliable budget-aware compressor that preserves small-object signals would be a useful engineering contribution.
major comments (2)
- [Abstract] Abstract: the claim of state-of-the-art performance is asserted without any quantitative metrics, baseline comparisons, ablation studies, or error analysis, making it impossible to judge whether the data support the central claim.
- [Method] Method (text-guided multi-scale importance estimation and region-wise preserve/merge): importance scores are computed on downsampled or pooled features at each scale; any object smaller than the coarsest pooling kernel therefore receives diluted scores. The subsequent per-region top-k preserve followed by merge can further discard or average away the already-weak signal. No explicit high-resolution saliency pass or pixel-level recovery mechanism is described. This directly threatens the central claim that query-critical evidence occupying only a few pixels is reliably preserved.
minor comments (1)
- [Abstract] The abstract would benefit from a concise statement of the key quantitative gains (e.g., accuracy delta and token reduction factor) to allow readers to assess the SOTA claim at a glance.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed feedback. We have carefully addressed each major comment below and revised the manuscript to strengthen the presentation of our results and clarify the method's handling of small objects.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of state-of-the-art performance is asserted without any quantitative metrics, baseline comparisons, ablation studies, or error analysis, making it impossible to judge whether the data support the central claim.
Authors: We agree that the abstract would be strengthened by including key quantitative highlights. In the revised manuscript, we have updated the abstract to briefly report specific performance gains (e.g., average improvements over strong baselines on the primary remote-sensing VLM benchmarks) while remaining within length limits. The full set of quantitative comparisons, ablation studies, and error analyses already appears in Sections 4 and 5; the abstract revision now directs readers to these results more explicitly. revision: yes
-
Referee: [Method] Method (text-guided multi-scale importance estimation and region-wise preserve/merge): importance scores are computed on downsampled or pooled features at each scale; any object smaller than the coarsest pooling kernel therefore receives diluted scores. The subsequent per-region top-k preserve followed by merge can further discard or average away the already-weak signal. No explicit high-resolution saliency pass or pixel-level recovery mechanism is described. This directly threatens the central claim that query-critical evidence occupying only a few pixels is reliably preserved.
Authors: We appreciate this careful analysis of potential signal dilution for sub-kernel objects. Our multi-scale estimation explicitly includes a finest scale whose pooling kernel is sized to retain few-pixel features; importance scores at this scale are computed directly on high-resolution patches. The text-guided cross-attention then amplifies query-relevant tokens at every scale, including the fine one, before region-wise top-k selection. The per-region preserve step further guarantees that localized high-importance tokens (even isolated small-object signals) are retained rather than globally pruned. We have added a dedicated paragraph in Section 3.2 clarifying the scale-specific kernel sizes and the role of query guidance, together with new qualitative visualizations in Section 4.3 that demonstrate preservation of few-pixel targets on UHR remote-sensing examples. While we did not introduce a separate pixel-level saliency branch (to preserve the low-cost design), the current mechanism supports the reported benchmark results on datasets containing small objects. revision: partial
Circularity Check
No significant circularity; independent engineering method validated by experiments
full rationale
The paper presents UHR-BAT as a query-guided and region-faithful token compression framework relying on text-guided multi-scale importance estimation plus region-wise preserve and merge strategies. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the text that reduce the claimed SOTA performance or token selection to inputs by construction. The contribution is described as an independent engineering approach whose validity rests on benchmark experiments rather than any self-referential loop or ansatz smuggled via prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abdin, M., Aneja, J., Behl, H., Bubeck, S., Eldan, R., Gunasekar, S., Harrison, M., Hewett, R. J., Javaheripi, M., Kauffmann, P., et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905,
work page internal anchor Pith review arXiv
-
[2]
Ac- cessed: 2025-02-25. Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Pali: A jointly-scaled mul- tilingual language-image model
Chen, L., Li, J., Dong, X., Zhang, P., He, C., Wang, J., Zhao, F., and Lin, D. Sharegpt4v: Improving large multi-modal models with better captions. InEuropean Conference on Computer Vision, pp. 370–387. Springer, 2024a. Chen, X., Wang, X., Changpinyo, S., Piergiovanni, A. J., Padlewski, P., Salz, D., Goodman, S., Grycner, A., Mustafa, B., Beyer, L., et al...
-
[4]
Chen, Z., Wang, W., Cao, Y ., Liu, Y ., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al. Expanding per- formance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024b. Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al. Intern...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Chu, X., Qiao, L., Zhang, X., Xu, S., Wei, F., Yang, Y ., Sun, X., Hu, Y ., Lin, X., Zhang, B., et al. Mobilevlm v2: Faster and stronger baseline for vision language model. arXiv preprint arXiv:2402.03766,
-
[6]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Explainable and interpretable multimodal large language models: A comprehensive survey
Dang, Y ., Huang, K., Huo, J., Yan, Y ., Huang, S., Liu, D., Gao, M., Zhang, J., Qian, C., Wang, K., et al. Explainable and interpretable multimodal large language models: A comprehensive survey.arXiv preprint arXiv:2412.02104,
-
[8]
Fuse-rsvlm: Feature fusion vision-language model for remote sensing
Dang, Y ., Gao, M., Yan, Y ., Zou, X., Gu, Y ., Li, J., Wang, J., Jiang, P., Liu, A., Liu, J., et al. Exploring response uncertainty in mllms: An empirical evaluation under mis- leading scenarios. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 18143–18184, 2025a. 9 UHR-BAT: Budget-Aware Token Compression Visi...
-
[9]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Bowen Jing, Bonnie Berger, and Tommi Jaakkola
Jaegle, A., Borgeaud, S., Alayrac, J.-B., Doersch, C., Ionescu, C., Ding, D., Koppula, S., Zoran, D., Brock, A., Shelhamer, E., et al. Perceiver io: A general archi- tecture for structured inputs & outputs.arXiv preprint arXiv:2107.14795, 2021a. Jaegle, A., Gimeno, F., Brock, A., Vinyals, O., Zisserman, A., and Carreira, J. Perceiver: General perception w...
-
[11]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y ., Liu, Z., et al. Llava- onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024a. Li, J., Li, D., Savarese, S., and Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational confe...
-
[12]
10 UHR-BAT: Budget-Aware Token Compression Vision-Language model for Ultra-High-Resolution Remote Sensing Liu, R., Fu, B., Song, J., Li, K., Li, W., Xue, L., Qiao, H., Zhang, W., Meng, D., and Cao, X. Zoomearth: Ac- tive perception for ultra-high-resolution geospatial vision- language tasks.arXiv preprint arXiv:2511.12267,
-
[13]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Lu, H., Liu, W., Zhang, B., Wang, B., Dong, K., Liu, B., Sun, J., Ren, T., Li, Z., Yang, H., et al. Deepseek-vl: towards real-world vision-language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review arXiv
-
[14]
Feast your eyes: Mixture-of- resolution adaptation for multimodal large language models
Luo, G., Zhou, Y ., Zhang, Y ., Zheng, X., Sun, X., and Ji, R. Feast your eyes: Mixture-of-resolution adaptation for multimodal large language models.arXiv preprint arXiv:2403.03003, 2024a. Luo, J., Pang, Z., Zhang, Y ., Wang, T., Wang, L., Dang, B., Lao, J., Wang, J., Chen, J., Tan, Y ., et al. Skysensegpt: A fine-grained instruction tuning dataset and m...
-
[15]
arXiv preprint arXiv:2312.06960 , year=
Mall, U., Phoo, C. P., Liu, M. K., V ondrick, C., Hariharan, B., and Bala, K. Remote sensing vision-language foun- dation models without annotations via ground remote alignment.arXiv preprint arXiv:2312.06960,
-
[16]
Pang, C., Wu, J., Li, J., Liu, Y ., Sun, J., Li, W., Weng, X., Wang, S., Feng, L., Xia, G.-S., et al
Accessed: 2025-08-10. Pang, C., Wu, J., Li, J., Liu, Y ., Sun, J., Li, W., Weng, X., Wang, S., Feng, L., Xia, G.-S., et al. H2rsvlm: Towards helpful and honest remote sensing large vision language model.CoRR,
2025
-
[17]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Sori- cut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Geollava-8k: Scaling remote-sensing multimodal large language models to 8k resolution
Wang, F., Chen, M., Li, Y ., Wang, D., Wang, H., Guo, Z., Wang, Z., Shan, B., Lan, L., Wang, Y ., et al. Geollava-8k: Scaling remote-sensing multimodal large language mod- els to 8k resolution.arXiv preprint arXiv:2505.21375, 2025a. Wang, F., Wang, H., Guo, Z., Wang, D., Wang, Y ., Chen, M., Ma, Q., Lan, L., Yang, W., Zhang, J., et al. Xlrs-bench: Could y...
-
[19]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025c. Wu, J., Gan, W., Chen, Z., Wan, S., and Yu, P. S. Multimodal large language models: A survey. In2023 IEEE Interna- tional Co...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
11 UHR-BAT: Budget-Aware Token Compression Vision-Language model for Ultra-High-Resolution Remote Sensing Yang, J., Chen, A., Dang, Y ., Fan, Q., Wang, C., Li, W., Miao, F., and Gao, Y . Annotation-free visual reasoning for high-resolution large multimodal models via rein- forcement learning.arXiv preprint arXiv:2602.23615,
-
[21]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yao, Y ., Yu, T., Zhang, A., Wang, C., Cui, J., Zhu, H., Cai, T., Li, H., Zhao, W., He, Z., et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800,
work page internal anchor Pith review arXiv
-
[22]
Yuan, Z., Li, Z., Huang, W., Ye, Y ., and Sun, L. Tinygpt- v: Efficient multimodal large language model via small backbones.arXiv preprint arXiv:2312.16862,
-
[23]
Zhang, P., Dong, X., Wang, B., Cao, Y ., Xu, C., Ouyang, L., Zhao, Z., Duan, H., Zhang, S., Ding, S., et al. Internlm-xcomposer: A vision-language large model for advanced text-image comprehension and composition. arXiv preprint arXiv:2309.15112,
-
[24]
Zhang, P., Dong, X., Zang, Y ., Cao, Y ., Qian, R., Chen, L., Guo, Q., Duan, H., Wang, B., Ouyang, L., et al. Internlm-xcomposer-2.5: A versatile large vision lan- guage model supporting long-contextual input and output. arXiv preprint arXiv:2407.03320, 2024a. Zhang, W., Cai, M., Zhang, T., Zhuang, Y ., and Mao, X. Earthgpt: A universal multimodal large l...
-
[25]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Zhu, D., Chen, J., Shen, X., Li, X., and Elhoseiny, M. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592,
work page internal anchor Pith review arXiv
-
[26]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y ., Su, W., Shao, J., et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Background
12 UHR-BAT: Budget-Aware Token Compression Vision-Language model for Ultra-High-Resolution Remote Sensing A. Background. Resource-Efficient Training and Inference for High-Resolution Remote Sensing.The rapid proliferation of high- resolution remote sensing platforms, including satellites, Unmanned Aerial Vehicles (UA Vs), and precision agriculture systems...
2025
-
[28]
Regarding our model, in the case of XLRS-Bench, the budget Bs is assigned as 180,1320,1600 , and 8000 corresponding to the four resolutions
For evaluation, baseline results are sourced from the original dataset papers. Regarding our model, in the case of XLRS-Bench, the budget Bs is assigned as 180,1320,1600 , and 8000 corresponding to the four resolutions. Similarly, in the case of MMERealWorld-RS and RSHR-Bench, we adopt budgets of80,320,1600, and4000, respectively. C. Implementation Detail...
1967
-
[29]
By integrating spatial distance, the clustering process effectively groups tokens that are both semantically similar and geographically close
with k centers iteratively partitions the input space and minimizes the objectiveJto find centroids{µ r}k r=1: J= NX i=1 ∥ui −µ ci ∥2 2, c i = arg min 1≤r≤k ∥ui −µ r∥2 2,(14) yielding clusters {Sr}k r=1 as the partition P(s). By integrating spatial distance, the clustering process effectively groups tokens that are both semantically similar and geographic...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.