Recognition: unknown
Towards Fine-grained Temporal Perception: Post-Training Large Audio-Language Models with Audio-Side Time Prompt
Pith reviewed 2026-05-10 12:34 UTC · model grok-4.3
The pith
Interleaving timestamp embeddings with RL post-training improves temporal perception in large audio-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
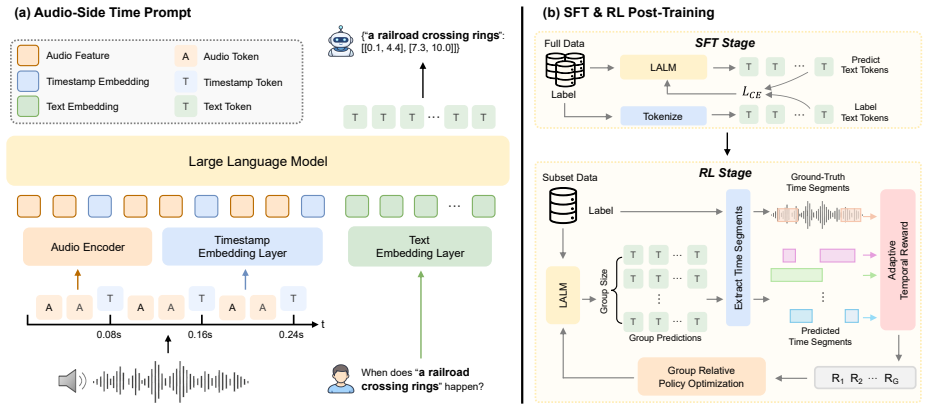
The TimePro-RL framework encodes timestamps as embeddings interleaved within the audio feature sequence as temporal coordinates to prompt the model, and uses reinforcement learning following supervised fine-tuning to directly optimize temporal alignment performance, resulting in significant gains across audio temporal tasks.
What carries the argument
Audio-Side Time Prompt, which interleaves timestamp embeddings within the audio feature sequence to provide explicit temporal coordinates to the model.
If this is right
- Significant performance gains in audio grounding tasks.
- Improved accuracy in sound event detection with precise timing.
- Better performance in dense audio captioning involving temporal details.
- The approach demonstrates robust effectiveness across multiple audio temporal tasks.
- General audio understanding capabilities remain intact after the post-training steps.
Where Pith is reading between the lines
- The prompting method could extend to video-language models to address similar timing issues in visual events.
- RL-based optimization may reduce reliance on large amounts of precisely timed labeled audio data.
- Real-time audio monitoring applications could gain from the added timing precision.
- Analogous coordinate interleaving might improve temporal tasks in speech or music analysis.
Load-bearing premise
The assumption that interleaving timestamp embeddings and applying RL after SFT will improve temporal alignment without degrading other capabilities or overfitting to the chosen evaluation sets.
What would settle it
Evaluating the fine-tuned model on a new audio dataset with temporal annotations and finding no improvement or degradation in onset and offset prediction metrics compared to the base model.
Figures

read the original abstract
Large Audio-Language Models (LALMs) enable general audio understanding and demonstrate remarkable performance across various audio tasks. However, these models still face challenges in temporal perception (e.g., inferring event onset and offset), leading to limited utility in fine-grained scenarios. To address this issue, we propose Audio-Side Time Prompt and leverage Reinforcement Learning (RL) to develop the TimePro-RL framework for fine-grained temporal perception. Specifically, we encode timestamps as embeddings and interleave them within the audio feature sequence as temporal coordinates to prompt the model. Furthermore, we introduce RL following Supervised Fine-Tuning (SFT) to directly optimize temporal alignment performance. Experiments demonstrate that TimePro-RL achieves significant performance gains across a range of audio temporal tasks, such as audio grounding, sound event detection, and dense audio captioning, validating its robust effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the TimePro-RL framework to improve fine-grained temporal perception in Large Audio-Language Models. It introduces an Audio-Side Time Prompt that encodes timestamps as embeddings and interleaves them within the audio feature sequence, then applies Reinforcement Learning after Supervised Fine-Tuning to optimize temporal alignment. Experiments are claimed to demonstrate significant performance gains on audio grounding, sound event detection, and dense audio captioning tasks.
Significance. If the empirical results hold under rigorous validation, the work could meaningfully advance post-training techniques for temporal capabilities in multimodal audio models, addressing a known limitation in current LALMs. The combination of prompt-based coordinate injection with RL optimization offers a practical, potentially generalizable approach; credit is due for focusing on a load-bearing capability gap and for the empirical framing that allows direct testing of the central claim.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The central claim of 'significant performance gains' is asserted without any quantitative metrics, baseline comparisons, ablation results, or error analysis in the provided abstract. The experiments section must supply concrete numbers (e.g., mAP or F1 improvements on audio grounding and SED) with SFT-only and other controls to substantiate that the time-prompt + RL combination drives the gains rather than other factors.
- [Method (RL stage)] Method section (RL stage): The reward formulation for the post-SFT RL step is not shown to be independent of the evaluation metrics used for audio grounding, SED, and dense captioning. If the reward directly optimizes the same temporal alignment scores on data distributionally close to the test sets, this creates a load-bearing risk of metric hacking or overfitting, undermining the claim of robust effectiveness without held-out generalization experiments.
minor comments (2)
- [Method] Clarify the precise dimensionality and initialization of the timestamp embeddings and the exact interleaving mechanism within the audio feature sequence (e.g., before or after each frame).
- [Discussion] Add a limitations paragraph discussing potential degradation on non-temporal audio tasks after the RL stage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and describe the revisions we will implement to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The central claim of 'significant performance gains' is asserted without any quantitative metrics, baseline comparisons, ablation results, or error analysis in the provided abstract. The experiments section must supply concrete numbers (e.g., mAP or F1 improvements on audio grounding and SED) with SFT-only and other controls to substantiate that the time-prompt + RL combination drives the gains rather than other factors.
Authors: We agree that the abstract should include key quantitative results for clarity. In the revised manuscript, we will update the abstract to report specific metrics, including mAP improvements on audio grounding and F1 scores on sound event detection relative to baselines. The experiments section already contains these concrete numbers along with SFT-only controls, ablations isolating the Audio-Side Time Prompt and RL stages (Tables 2–4), and error analysis in Section 4.3, which together demonstrate that the time-prompt + RL combination is responsible for the gains. revision: yes
-
Referee: [Method (RL stage)] Method section (RL stage): The reward formulation for the post-SFT RL step is not shown to be independent of the evaluation metrics used for audio grounding, SED, and dense captioning. If the reward directly optimizes the same temporal alignment scores on data distributionally close to the test sets, this creates a load-bearing risk of metric hacking or overfitting, undermining the claim of robust effectiveness without held-out generalization experiments.
Authors: The reward is computed from temporal alignment objectives (e.g., boundary IoU) on the RL training data, which is standard practice but shares surface similarity with evaluation metrics. All reported results use held-out test sets drawn from distinct distributions. We will expand the Method section with an explicit reward equation and add results on further out-of-distribution held-out sets to strengthen the generalization evidence. revision: partial
Circularity Check
No circularity: empirical method proposal with independent experimental validation
full rationale
The paper introduces Audio-Side Time Prompt via timestamp embeddings interleaved in audio features, followed by RL after SFT, and reports performance gains on audio grounding, sound event detection, and dense captioning. No derivation chain, equations, or self-citations reduce any claimed result to fitted inputs or prior author work by construction. The central claims rest on experimental outcomes rather than self-referential definitions or predictions, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Timestamp embeddings can be directly interleaved into audio feature sequences to provide usable temporal coordinates.
- domain assumption Reinforcement learning after SFT will optimize temporal alignment without introducing new biases or capability regressions.
invented entities (1)
-
Audio-Side Time Prompt
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introduction Audio conveys a wealth of information, ranging from human speech to environmental events, and serves as a fundamental modality for perceiving the world[1, 2]. Large Audio-Language Models (LALMs) have significantly advanced general audio understanding by integrating the linguistic reasoning of Large Language Models (LLMs) with audio encoders [...
-
[2]
Method In this section, we elaborate on the TimePro-RL framework, the overall schematic of which is illustrated in Figure 1. We first present the infusion of temporal cues into LALM’s audio input (Section 2.1), and then describe the RL post-training paradigm tailored for audio temporal tasks, focusing on reward design (Section 2.2). 2.1. Audio-Side Time P...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Tasks and datasets We conduct experiments across three representative audio tem- poral tasks: Audio Grounding (AG)[11]
Experimental setup 3.1. Tasks and datasets We conduct experiments across three representative audio tem- poral tasks: Audio Grounding (AG)[11]. The audio grounding task is defined as localizing a specific sound event within an audio clip based on a descriptive natural language query. For this task, we utilize the FTAR dataset [8] and require the model to ...
-
[4]
random init
Results In this section, we first evaluate TimePro-RL against baselines under zero-shot and finetuned settings. Then, we conduct ab- lation studies to analyze the contributions of components in TimePro-RL. Table 3:Ablation study of different components. ASTP denotes Audio-Side Time Prompt; “random init” refers to random initialization of Timestamp Embeddi...
-
[5]
Conclusion In this paper, we propose TimePro-RL, a framework to enhance the fine-grained temporal perception of LALMs. TimePro-RL interleaves Timestamp Embeddings into audio feature sequence to provide temporal cues, and introduces RL post-training with an adaptive temporal reward designed for temporal alignment to further strengthen temporal capabilities...
-
[6]
Audio set: An ontol- ogy and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontol- ogy and human-labeled dataset for audio events,” inIEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 776–780
2017
-
[7]
Panns: Large-scale pretrained audio neural networks for audio pattern recognition,
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumb- ley, “Panns: Large-scale pretrained audio neural networks for audio pattern recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020
2020
-
[8]
Pengi: An audio language model for audio tasks,
S. Deshmukh, B. Elizalde, R. Singh, and H. Wang, “Pengi: An audio language model for audio tasks,” inAdvances in Neural In- formation Processing Systems (NeurIPS), vol. 36. Curran Asso- ciates, Inc., 2023, pp. 18 090–18 108
2023
-
[9]
SALMONN: towards generic hearing abilities for large language models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “SALMONN: towards generic hearing abilities for large language models,” inThe Twelfth International Conference on Learning Representations (ICLR). OpenReview.net, 2024
2024
-
[10]
Listen, think, and understand,
Y . Gong, H. Luo, A. H. Liu, L. Karlinsky, and J. R. Glass, “Listen, think, and understand,” inThe Twelfth International Conference on Learning Representations (ICLR). OpenReview.net, 2024
2024
-
[11]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Y . Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou, “Qwen-audio: Advancing universal audio understand- ing via unified large-scale audio-language models,”arXiv preprint arXiv:2311.07919, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
K., Asawaroengchai, C., Nguyen, D
P. K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, A. Bapna, Z. Borsos, F. d. C. Quitry, P. Chen, D. E. Badawy, W. Han, E. Kharitonovet al., “Audiopalm: A large language model that can speak and listen,”arXiv preprint arXiv:2306.12925, 2023
-
[13]
H. Wang, Y . Li, S. Ma, H. Liu, and X. Wang, “Listening between the frames: Bridging temporal gaps in large audio-language mod- els,”arXiv preprint arXiv:2511.11039, 2025
-
[14]
Sound event detection: A tutorial,
A. Mesaros, T. Heittola, T. Virtanen, and M. D. Plumbley, “Sound event detection: A tutorial,”IEEE Signal Processing Magazine, vol. 38, no. 5, pp. 67–83, 2021
2021
-
[15]
Multi-domain audio question answering benchmark toward acoustic content reasoning, 2026
C.-H. H. Yang, S. Ghosh, Q. Wang, J. Kim, H. Hong, S. Ku- mar, G. Zhong, Z. Kong, S. Sakshi, V . Lokegaonkaret al., “Multi-domain audio question answering toward acoustic con- tent reasoning in the DCASE 2025 challenge,”arXiv preprint arXiv:2505.07365, 2025
-
[16]
Text-to-audio grounding: Building correspondence between captions and sound events,
X. Xu, H. Dinkel, M. Wu, and K. Yu, “Text-to-audio grounding: Building correspondence between captions and sound events,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 606–610
2021
-
[17]
Detection and classification of acoustic scenes and events,
D. Stowell, D. Giannoulis, E. Benetos, M. Lagrange, and M. D. Plumbley, “Detection and classification of acoustic scenes and events,”IEEE Transactions on Multimedia, vol. 17, no. 10, pp. 1733–1746, 2015
2015
-
[18]
Audiotime: A temporally-aligned audio-text benchmark dataset,
Z. Xie, X. Xu, Z. Wu, and M. Wu, “Audiotime: A temporally-aligned audio-text benchmark dataset,” inIEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[19]
Grounded-videollm: Sharpening fine- grained temporal grounding in video large language models,
H. Wang, Z. Xu, Y . Cheng, S. Diao, Y . Zhou, Y . Cao, Q. Wang, W. Ge, and L. Huang, “Grounded-videollm: Sharpening fine- grained temporal grounding in video large language models,” inFindings of the Association for Computational Linguistics (EMNLP). Association for Computational Linguistics, 2025, pp. 959–975
2025
-
[20]
arXiv preprint arXiv:2504.06958 (2025)
X. Li, Z. Yan, D. Meng, L. Dong, X. Zeng, Y . He, Y . Wang, Y . Qiao, Y . Wang, and L. Wang, “Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning,”arXiv preprint arXiv:2504.06958, 2025
-
[21]
L. Dong, H. Zhang, H. Lin, Z. Yan, X. Zeng, H. Zhang, Y . Huang, Y . Wang, Z.-H. Ling, L. Wanget al., “Videotg-r1: Boosting video temporal grounding via curriculum reinforcement learning on re- flected boundary annotations,”arXiv preprint arXiv:2510.23397, 2025
-
[22]
Roformer: Enhanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “Roformer: Enhanced transformer with rotary position embedding,”Neuro- computing, vol. 568, p. 127063, 2024
2024
-
[23]
Enhancing temporal un- derstanding in audio question answering for large audio language models,
A. K. Sridhar, Y . Guo, and E. Visser, “Enhancing temporal un- derstanding in audio question answering for large audio language models,” inConference of the Nations of the Americas Chapter of the ACL (NAACL), 2025, pp. 1026–1035
2025
-
[24]
Number it: Temporal grounding videos like flipping manga,
Y . Wu, X. Hu, Y . Sun, Y . Zhou, W. Zhu, F. Rao, B. Schiele, and X. Yang, “Number it: Temporal grounding videos like flipping manga,” inIEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2025, pp. 13 754–13 765
2025
-
[25]
Time-r1: Post-training large vision language model for temporal video grounding,
Y . Wang, Z. Wang, B. Xu, Y . Du, K. Lin, Z. Xiao, Z. Yue, J. Ju, L. Zhang, D. Yanget al., “Time-r1: Post-training large vision language model for temporal video grounding,”arXiv preprint arXiv:2503.13377, 2025
-
[26]
A deep reinforced model for abstractive summarization,
R. Paulus, C. Xiong, and R. Socher, “A deep reinforced model for abstractive summarization,” inInternational Conference on Learning Representations (ICLR). OpenReview.net, 2018
2018
-
[27]
Self- critical sequence training for image captioning,
S. J. Rennie, E. Marcheret, Y . Mroueh, J. Ross, and V . Goel, “Self- critical sequence training for image captioning,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 7008–7024
2017
-
[28]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reason- ing capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Metrics for polyphonic sound event detection,
A. Mesaros, T. Heittola, and T. Virtanen, “Metrics for polyphonic sound event detection,”Applied Sciences, vol. 6, no. 6, p. 162, 2016
2016
-
[30]
Sound event detection in domestic environments with weakly labeled data and soundscape synthesis,
N. Turpault, R. Serizel, A. P. Shah, and J. Salamon, “Sound event detection in domestic environments with weakly labeled data and soundscape synthesis,” inWorkshop on Detection and Classifica- tion of Acoustic Scenes and Events (DCASE), 2019
2019
-
[31]
Meteor: An automatic metric for mt evaluation with improved correlation with human judgments,
S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evaluation with improved correlation with human judgments,” in Proceedings of the acl workshop on intrinsic and extrinsic eval- uation measures for machine translation and/or summarization, 2005, pp. 65–72
2005
-
[32]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review arXiv 2024
-
[33]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Danget al., “Qwen2.5-omni technical report,”arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review arXiv 2025
-
[34]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational Conference on Machine Learning (ICML). PMLR, 2023, pp. 28 492–28 518
2023
-
[35]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” inInternational Conference on Learning Rep- resentations (ICLR), vol. 1, no. 2, 2022, p. 3
2022
-
[36]
Audio flamingo 2: An audio- language model with long-audio understanding and expert rea- soning abilities,
S. Ghosh, Z. Kong, S. Kumar, S. Sakshi, J. Kim, W. Ping, R. Valle, D. Manocha, and B. Catanzaro, “Audio flamingo 2: An audio- language model with long-audio understanding and expert rea- soning abilities,” inInternational Conference on Machine Learn- ing (ICML), ser. Proceedings of Machine Learning Research, vol
-
[37]
PMLR / OpenReview.net, 2025
2025
-
[38]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tanget al., “Kimi-audio technical report,” arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.