Recognition: unknown
Self-Distillation as a Performance Recovery Mechanism for LLMs: Counteracting Compression and Catastrophic Forgetting
Pith reviewed 2026-05-10 09:09 UTC · model grok-4.3
The pith
Self-distillation fine-tuning restores LLM performance lost to forgetting, quantization, and pruning by realigning hidden-layer manifolds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
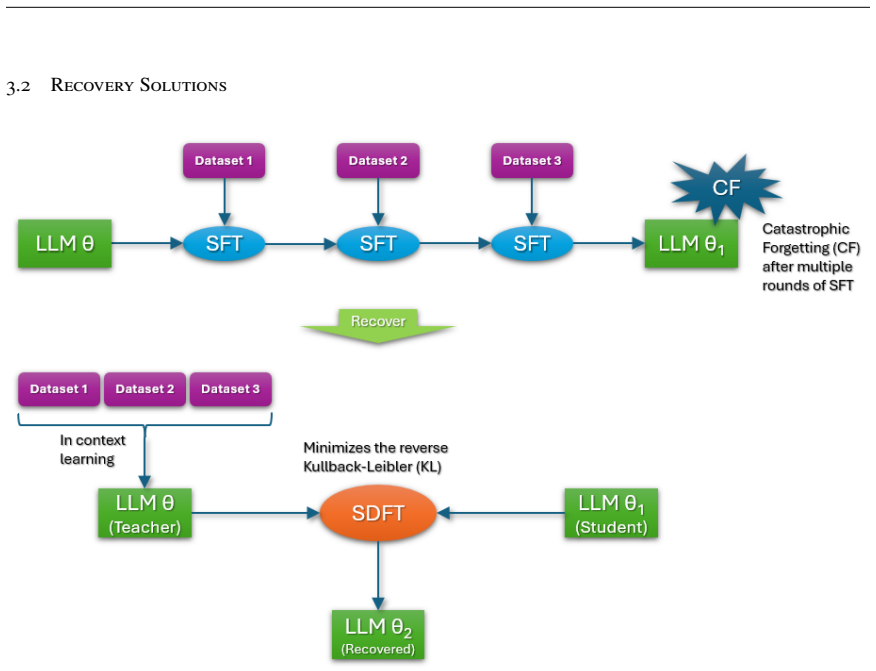
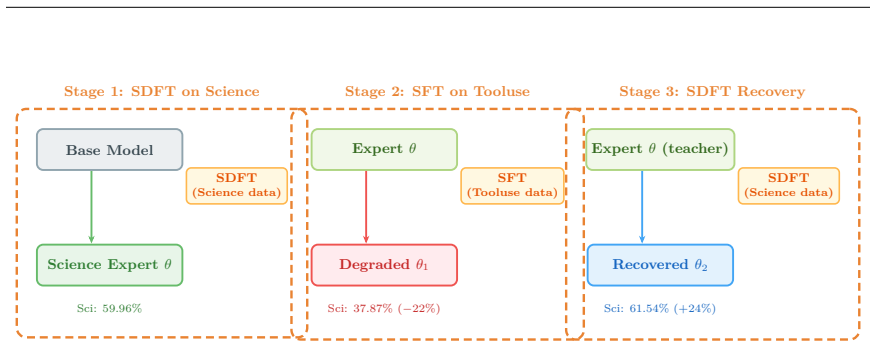
The paper claims that an LLM's generative capability depends on the high-dimensional manifold formed by its hidden-layer activations. Self-distillation fine-tuning recovers performance degraded by catastrophic forgetting, quantization, or pruning by aligning the student's manifold with the teacher's optimal structure. Centered kernel alignment quantifies this match and remains stable under orthogonal transformations and scaling. Experiments establish a strong correlation between the degree of manifold alignment and the extent of performance recovery.
What carries the argument
The high-dimensional manifold of hidden-layer activations, aligned between student and teacher models through centered kernel alignment.
Load-bearing premise
An LLM's generative capability fundamentally relies on the geometric structure of the high-dimensional manifold formed by its hidden layers, and that alignment of this manifold explains performance recovery rather than merely correlating with it.
What would settle it
Performance recovers after self-distillation while centered kernel alignment between student and teacher manifolds stays low, or alignment rises without corresponding performance improvement.
Figures






read the original abstract
Large Language Models (LLMs) have achieved remarkable success, underpinning diverse AI applications. However, they often suffer from performance degradation due to factors such as catastrophic forgetting during Supervised Fine-Tuning (SFT), quantization, and pruning. In this work, we introduce a performance recovery framework based on Self-Distillation Fine-Tuning (SDFT) that effectively restores model capabilities. Complementing this practical contribution, we provide a rigorous theoretical explanation for the underlying recovery mechanism. We posit that an LLM's generative capability fundamentally relies on the high-dimensional manifold constructed by its hidden layers. To investigate this, we employ Centered Kernel Alignment (CKA) to quantify the alignment between student and teacher activation trajectories, leveraging its invariance to orthogonal transformations and scaling. Our experiments demonstrate a strong correlation between performance recovery and manifold alignment, substantiating the claim that self-distillation effectively aligns the student's high-dimensional manifold with the optimal structure represented by the teacher. This study bridges the gap between practical recovery frameworks and geometric representation theory, offering new insights into the internal mechanisms of self-distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Self-Distillation Fine-Tuning (SDFT) as a practical framework to recover LLM performance degraded by catastrophic forgetting during supervised fine-tuning, as well as by quantization and pruning. It complements this with a theoretical account positing that generative capability depends on the high-dimensional manifold of hidden-layer activations; Centered Kernel Alignment (CKA) is used to quantify alignment between student and teacher trajectories, with experiments showing a correlation between increased CKA scores and recovered downstream performance, interpreted as evidence that self-distillation realigns the student manifold to the teacher's optimal structure.
Significance. If the causal link between manifold alignment and performance recovery can be established, the work would supply both an efficient recovery technique for compressed or fine-tuned LLMs and a geometric lens on self-distillation that could inform future representation-aware training methods. The explicit use of CKA's invariance properties for measuring alignment is a methodological strength that distinguishes the analysis from purely empirical distillation studies.
major comments (3)
- [Abstract] Abstract: The central claim that self-distillation 'effectively aligns the student's high-dimensional manifold with the optimal structure represented by the teacher' rests on post-hoc correlation between CKA scores and performance metrics; no ablation or intervention that isolates geometric alignment from other distillation effects (e.g., softened targets or logit matching) is described, leaving the causal status of the manifold mechanism untested.
- [Theoretical explanation] Theoretical explanation: The assertion that 'an LLM's generative capability fundamentally relies on the high-dimensional manifold constructed by its hidden layers' is introduced without a formal derivation or reference establishing manifold geometry as the primary determinant of generation rather than a correlate, rendering the explanatory account vulnerable to circularity with the CKA observations.
- [Experiments] Experiments: The reported 'strong correlation' between manifold alignment and recovery does not rule out joint causation by non-geometric factors; without control conditions that hold alignment fixed while varying other distillation components, the geometric interpretation cannot be distinguished from simpler regularization accounts.
minor comments (2)
- [Notation] The phrase 'activation trajectories' is used without an explicit definition of how hidden-layer activations are aggregated or sampled across tokens or layers; a brief formalization or pseudocode would improve reproducibility.
- [References] Prior literature on CKA applications to representation similarity in transformers and on manifold hypotheses in language models should be cited to better situate the geometric claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important distinctions between correlation and causation as well as the need for precise theoretical framing. We address each point below and indicate planned revisions to strengthen the manuscript without overstating the current evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that self-distillation 'effectively aligns the student's high-dimensional manifold with the optimal structure represented by the teacher' rests on post-hoc correlation between CKA scores and performance metrics; no ablation or intervention that isolates geometric alignment from other distillation effects (e.g., softened targets or logit matching) is described, leaving the causal status of the manifold mechanism untested.
Authors: We agree that the manuscript relies on observed correlations between CKA alignment and performance recovery rather than interventional ablations that would isolate manifold geometry from other distillation components. In the revised version we will rephrase the abstract to present manifold alignment as a hypothesized mechanism supported by the correlation evidence, explicitly note the absence of isolating controls, and add a limitations paragraph discussing alternative explanations such as regularization effects from softened targets. We will also outline a possible future control experiment design. revision: partial
-
Referee: [Theoretical explanation] Theoretical explanation: The assertion that 'an LLM's generative capability fundamentally relies on the high-dimensional manifold constructed by its hidden layers' is introduced without a formal derivation or reference establishing manifold geometry as the primary determinant of generation rather than a correlate, rendering the explanatory account vulnerable to circularity with the CKA observations.
Authors: The theoretical section presents the manifold dependence as a working hypothesis motivated by the empirical CKA results and prior representation-learning literature rather than a formally derived theorem. We will revise the text to label it explicitly as a hypothesis, add supporting references from manifold learning and neural representation geometry, and remove any phrasing that implies primary causation without additional evidence, thereby reducing the risk of circularity. revision: yes
-
Referee: [Experiments] Experiments: The reported 'strong correlation' between manifold alignment and recovery does not rule out joint causation by non-geometric factors; without control conditions that hold alignment fixed while varying other distillation components, the geometric interpretation cannot be distinguished from simpler regularization accounts.
Authors: We concur that the reported correlations across SFT, quantization, and pruning settings do not exclude joint causation by non-geometric factors. The revised manuscript will expand the experimental discussion to acknowledge this limitation, emphasize that CKA is used here as a descriptive alignment metric rather than a causal proof, and include a dedicated subsection on alternative regularization interpretations. We will also suggest concrete control experiments for follow-up work. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper posits as a starting assumption that generative capability relies on the hidden-layer manifold and then uses CKA to measure alignment between student and teacher activations, reporting a correlation with performance recovery. No equations or steps are presented that reduce a claimed prediction or first-principles result to the inputs by construction. There are no fitted parameters renamed as predictions, no load-bearing self-citations for the central mechanism, and no uniqueness theorems or ansatzes imported from prior work by the same authors. The structure is an explicit assumption followed by an empirical correlation; this is self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM's generative capability fundamentally relies on the high-dimensional manifold constructed by its hidden layers.
invented entities (1)
-
high-dimensional manifold of hidden layers
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar
Tommaso Furlanello, Zachary C. Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar. Born again neural networks. InProceedings of the 35th International Conference on Machine Learning (ICML 2018), pp. 1607–1616,
2018
-
[2]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Overcomingcatastrophic forgettinginneuralnetworks.Proceedings of the national academy of sciences,114(13):3521–3526,2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, KieranMilan,JohnQuan,TiagoRamalho,AgnieszkaGrabska-Barwinska,etal. Overcomingcatastrophic forgettinginneuralnetworks.Proceedings of the national academy of sciences,114(13):3521–3526,2017. Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinto...
2017
-
[4]
Team Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Andrei A. Rusu, Neil C. Rabinowitz, Guillaume Desjardins, Hubert Sober, Koray Kavukcuoglu, and Raia Hadsell. Progressive neural networks. InarXiv preprint arXiv:1606.04671,
work page internal anchor Pith review arXiv
-
[6]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learn- ing.arXiv preprint arXiv:2601.19897,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.