Recognition: unknown
Bridging Coarse and Fine Recognition: A Hybrid Approach for Open-Ended Multi-Granularity Object Recognition in Interactive Educational Games
Pith reviewed 2026-05-10 07:40 UTC · model grok-4.3
The pith
Hybrid model combining MLLM and CLIP narrows fine-grained gap to 0.2% and boosts general recognition by 2.5%
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
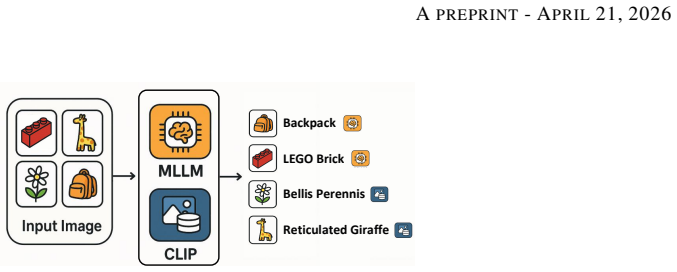
HyMOR integrates an MLLM for open-ended and coarse-grained object recognition with a CLIP model for fine-grained identification of domain-specific objects such as animals and plants. This hybrid design enables accurate object understanding across multiple semantic granularities, serving as a robust perceptual foundation for downstream multi-modal content generation and interactive gameplay. Extensive experiments on the TBO dataset and others demonstrate that HyMOR narrows the fine-grained recognition gap with CLIP to 0.2% while improving general object recognition by 2.5% over a baseline MLLM, with an overall 23.2% improvement in average Sentence-BERT similarity.
What carries the argument
The HyMOR hybrid framework that lets the MLLM handle open-ended and coarse recognition while the CLIP model handles fine-grained identification.
If this is right
- Enables accurate multi-granularity object perception for interactive educational games.
- Provides a foundation for multi-modal content generation.
- Achieves improved recognition performance on both general and fine-grained tasks.
- Introduces the TBO dataset for content-rich educational evaluation scenarios.
Where Pith is reading between the lines
- The approach may apply to other areas requiring multi-level recognition, such as autonomous driving or medical diagnosis.
- Future tests could involve integrating the hybrid into actual game prototypes to measure user engagement.
- The use of SBert similarity as the metric could be supplemented with human evaluations for educational relevance.
Load-bearing premise
The hybrid integration of the MLLM and CLIP model yields the measured improvements without performance trade-offs or conflicts between the components.
What would settle it
Running the HyMOR system on the TBO dataset and finding that its fine-grained SBert score is more than 0.2% below CLIP's or its general recognition improvement is below 2.5% compared to the baseline MLLM would disprove the central performance claims.
Figures




read the original abstract
Recent advances in Multimodal Large Language Models (MLLMs) have enabled open-ended object recognition, yet they struggle with fine-grained tasks. In contrast, CLIP-style models excel at fine-grained recognition but lack broad coverage of general object categories. To bridge this gap, we propose \textbf{HyMOR}, a \textbf{Hy}brid \textbf{M}ulti-granularity open-ended \textbf{O}bject \textbf{R}ecognition framework that integrates an MLLM with a CLIP model. In HyMOR, the MLLM performs open-ended and coarse-grained object recognition, while the CLIP model specializes in fine-grained identification of domain-specific objects such as animals and plants. This hybrid design enables accurate object understanding across multiple semantic granularities, serving as a robust perceptual foundation for downstream multi-modal content generation and interactive gameplay. To support evaluation in content-rich and educational scenarios, we introduce TBO (TextBook Objects), a dataset containing 20,942 images annotated with 8,816 object categories extracted from textbooks. Extensive experiments demonstrate that HyMOR narrows the fine-grained recognition gap with CLIP to 0.2\% while improving general object recognition by 2.5\% over a baseline MLLM, measured by average Sentence-BERT (SBert) similarity. Overall, HyMOR achieves a 23.2\% improvement in average SBert across all evaluated datasets, highlighting its effectiveness in enabling accurate perception for multi-modal game content generation and interactive learning applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HyMOR, a hybrid framework integrating an MLLM for open-ended/coarse-grained object recognition with a CLIP model for fine-grained domain-specific tasks (e.g., animals/plants). It introduces the TBO dataset (20,942 images, 8,816 textbook-derived categories) for educational evaluation and reports empirical gains via average Sentence-BERT similarity: narrowing the fine-grained gap to CLIP by 0.2%, improving general recognition by 2.5% over a baseline MLLM, and achieving a 23.2% overall SBert lift across datasets, positioning the method as a perceptual foundation for interactive educational games and multi-modal content generation.
Significance. If the central claims hold under more rigorous validation, the work offers a pragmatic hybrid route to multi-granularity recognition that could benefit CV applications in education and games by combining broad coverage with fine discrimination. The TBO dataset is a constructive addition for domain-specific benchmarking. The purely empirical nature of the gains and the chosen metric, however, limit immediate impact until the evaluation is strengthened.
major comments (3)
- [Abstract] Abstract: The headline claims (0.2% fine-grained gap to CLIP, 2.5% general gain over MLLM, 23.2% overall SBert improvement) rest exclusively on average Sentence-BERT similarity to TBO ground-truth labels. This metric can assign high scores to semantically related but factually incorrect descriptions (e.g., “sparrow” vs. “finch”), which directly undermines validation of open-ended multi-granularity recognition where multiple valid granularities exist and factual precision matters for educational use.
- [Abstract] Abstract and method description: No explicit fusion rule, routing mechanism, or conflict-resolution strategy between MLLM and CLIP outputs is provided. Without this, it is impossible to verify that the reported gains occur without hidden trade-offs on either the coarse or fine-grained axis, which is load-bearing for the hybrid-design claim.
- [Experiments] Experiments section (TBO dataset): As the sole educational dataset and newly introduced, TBO requires details on annotation protocol, inter-annotator agreement, and controls for category bias or label ambiguity to support the assertion that HyMOR supplies a “robust perceptual foundation” for interactive games; these are currently absent.
minor comments (1)
- [Abstract] Abstract: The expansion of the HyMOR acronym is given but could be repeated on first use in the main text for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate clarifications and additional details where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims (0.2% fine-grained gap to CLIP, 2.5% general gain over MLLM, 23.2% overall SBert improvement) rest exclusively on average Sentence-BERT similarity to TBO ground-truth labels. This metric can assign high scores to semantically related but factually incorrect descriptions (e.g., “sparrow” vs. “finch”), which directly undermines validation of open-ended multi-granularity recognition where multiple valid granularities exist and factual precision matters for educational use.
Authors: We acknowledge that Sentence-BERT similarity, while suitable for capturing semantic alignment across granularities, does not fully guarantee factual precision and can score related but incorrect labels highly. This is a valid limitation for educational applications. In the revised manuscript we will supplement the SBert results with exact-match accuracy, top-5 label accuracy, and a targeted human evaluation on a subset of TBO samples to better substantiate the claims of factual reliability. revision: yes
-
Referee: [Abstract] Abstract and method description: No explicit fusion rule, routing mechanism, or conflict-resolution strategy between MLLM and CLIP outputs is provided. Without this, it is impossible to verify that the reported gains occur without hidden trade-offs on either the coarse or fine-grained axis, which is load-bearing for the hybrid-design claim.
Authors: The current description states that the MLLM handles open-ended/coarse recognition and CLIP is applied to domain-specific fine-grained cases, but we agree an explicit mechanism is required. We will add a dedicated subsection with the routing rule (MLLM output triggers CLIP only on detected domain categories via keyword matching on coarse labels) and include ablation results demonstrating that coarse performance is preserved while fine-grained accuracy improves, with no measurable trade-off. revision: yes
-
Referee: [Experiments] Experiments section (TBO dataset): As the sole educational dataset and newly introduced, TBO requires details on annotation protocol, inter-annotator agreement, and controls for category bias or label ambiguity to support the assertion that HyMOR supplies a “robust perceptual foundation” for interactive games; these are currently absent.
Authors: We agree that the TBO dataset description is insufficient for a new benchmark. In the revised version we will expand the dataset section with the full annotation protocol (textbook page alignment by domain experts, multi-annotator labeling), inter-annotator agreement statistics (Fleiss’ kappa), and bias-mitigation steps (hierarchical category review and ambiguity flagging). These additions will directly support the robustness claim. revision: yes
Circularity Check
No circularity: empirical results from hybrid model evaluation
full rationale
The paper introduces HyMOR as a hybrid MLLM+CLIP framework and reports measured performance gains (0.2% gap to CLIP, 2.5% over MLLM, 23.2% overall SBert lift) on TBO and other datasets. These are direct experimental comparisons to external baselines using Sentence-BERT similarity; no equations, fitted parameters, or derivation steps are present that reduce the reported quantities to the model's own inputs by construction. The TBO dataset and fusion approach are described as new contributions without self-referential definitions or load-bearing self-citations that would create circularity. The central claims remain independent empirical observations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal Large Language Models enable open-ended object recognition but struggle with fine-grained tasks.
- domain assumption CLIP-style models excel at fine-grained recognition but lack broad coverage of general object categories.
invented entities (2)
-
HyMOR framework
no independent evidence
-
TBO dataset
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[3]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[4]
Learning adversarial semantic embeddings for zero-shot recognition in open worlds.Pattern Recognition, 149:110258, 2024
Tianqi Li, Guansong Pang, Xiao Bai, Jin Zheng, Lei Zhou, and Xin Ning. Learning adversarial semantic embeddings for zero-shot recognition in open worlds.Pattern Recognition, 149:110258, 2024
2024
-
[5]
Structural feature enhanced transformer for fine-grained image recognition.Pattern Recognition, 169:111955, 2026
Ying Yu, Wei Wei, Cairong Zhao, Jin Qian, and Enhong Chen. Structural feature enhanced transformer for fine-grained image recognition.Pattern Recognition, 169:111955, 2026
2026
-
[6]
Bioclip: A vision foundation model for the tree of life
Samuel Stevens, Jiaman Wu, Matthew J Thompson, Elizabeth G Campolongo, Chan Hee Song, David Edward Carlyn, Li Dong, Wasila M Dahdul, Charles Stewart, Tanya Berger-Wolf, et al. Bioclip: A vision foundation model for the tree of life. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19412–19424, 2024
2024
-
[7]
Why are visually-grounded language models bad at image classification? InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
Yuhui Zhang, Alyssa Unell, Xiaohan Wang, Dhruba Ghosh, Yuchang Su, Ludwig Schmidt, and Serena Yeung- Levy. Why are visually-grounded language models bad at image classification? InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[8]
African or european swallow? benchmarking large vision- language models for fine-grained object classification
Gregor Geigle, Radu Timofte, and Goran Glavaš. African or european swallow? benchmarking large vision- language models for fine-grained object classification. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2653–2669, 2024
2024
-
[9]
Analyzing and boosting the power of fine- grained visual recognition for multi-modal large language models
Hulingxiao He, Geng Li, Zijun Geng, Jinglin Xu, and Yuxin Peng. Analyzing and boosting the power of fine- grained visual recognition for multi-modal large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[10]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[11]
Sigmoid loss for language image pre- training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[12]
Democratizing fine-grained visual recognition with large language models
M Liu, S Roy, W Li, Z Zhong, N Sebe, E Ricci, et al. Democratizing fine-grained visual recognition with large language models. In12th International Conference on Learning Representations, ICLR 2024. International Conference on Learning Representations, ICLR, 2024
2024
-
[13]
Learning attention-guided pyramidal features for few-shot fine-grained recognition.Pattern Recognition, 130:108792, 2022
Hao Tang, Chengcheng Yuan, Zechao Li, and Jinhui Tang. Learning attention-guided pyramidal features for few-shot fine-grained recognition.Pattern Recognition, 130:108792, 2022
2022
-
[14]
Exploiting spatial relation for fine-grained image classification.Pattern Recognition, 91:47–55, 2019
Lei Qi, Xiaoqiang Lu, and Xuelong Li. Exploiting spatial relation for fine-grained image classification.Pattern Recognition, 91:47–55, 2019
2019
-
[15]
A feature consistency driven attention erasing network for fine-grained image retrieval.Pattern Recognition, 128:108618, 2022
Qi Zhao, Xu Wang, Shuchang Lyu, Binghao Liu, and Yifan Yang. A feature consistency driven attention erasing network for fine-grained image retrieval.Pattern Recognition, 128:108618, 2022
2022
-
[16]
Self-attention based fine-grained cross-media hybrid network.Pattern Recognition, 130:108748, 2022
Wei Shan, Dan Huang, Jiangtao Wang, Feng Zou, and Suwen Li. Self-attention based fine-grained cross-media hybrid network.Pattern Recognition, 130:108748, 2022
2022
-
[17]
Huan Liu, Lingyu Xiao, Jiangjiang Liu, Xiaofan Li, Ze Feng, Sen Yang, and Jingdong Wang. Revisiting mllms: An in-depth analysis of image classification abilities.arXiv preprint arXiv:2412.16418, 2024
-
[18]
Towards open world object detection
KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Vineeth N Balasubramanian. Towards open world object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5830–5840, 2021
2021
-
[19]
Detecting everything in the open world: Towards universal object detection
Zhenyu Wang, Yali Li, Xi Chen, Ser-Nam Lim, Antonio Torralba, Hengshuang Zhao, and Shengjin Wang. Detecting everything in the open world: Towards universal object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11433–11443, 2023. 10 APREPRINT- APRIL21, 2026
2023
-
[20]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In2013 IEEE International Conference on Computer Vision Workshops, Dec 2013
2013
-
[22]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024
2024
-
[23]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
The caltech-ucsd birds-200- 2011 dataset.california institute of technology, 2011
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200- 2011 dataset.california institute of technology, 2011
2011
-
[25]
O. M. Parkhi, A. Vedaldi, A. Zisserman, and C. V . Jawahar. Cats and dogs. In2012 IEEE Conference on Computer Vision and Pattern Recognition, Jun 2012
2012
-
[26]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Dec 2008
2008
-
[27]
Combined scaling for zero-shot transfer learning.Neurocomputing, 555:126658, 2023
Hieu Pham, Zihang Dai, Golnaz Ghiasi, Kenji Kawaguchi, Hanxiao Liu, Adams Wei Yu, Jiahui Yu, Yi-Ting Chen, Minh-Thang Luong, Yonghui Wu, et al. Combined scaling for zero-shot transfer learning.Neurocomputing, 555:126658, 2023
2023
-
[28]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016
work page Pith review arXiv 2016
-
[29]
Gemma Team. Gemma 3. 2025
2025
-
[30]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review arXiv 2024
-
[31]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 11
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.