Recognition: no theorem link
Coding with Eyes: Visual Feedback Unlocks Reliable GUI Code Generating and Debugging
Pith reviewed 2026-05-15 12:02 UTC · model grok-4.3
The pith
Visual feedback and simulated interactions enable LLM agents to debug GUI code more reliably than text alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VF-Coder is a vision-feedback-based multi-agent system that perceives visual information from the rendered GUI interface and directly interacts with program elements to identify potential logic and layout issues, thereby increasing the success rate of Gemini-3-Flash from 21.68% to 28.29% and the visual score from 0.4284 to 0.5584 on InteractGUI Bench.
What carries the argument
VF-Coder, a vision-feedback-based multi-agent system that supplies visual perception of the rendered interface and simulated user interactions to generate corrective feedback for GUI code.
If this is right
- GUI code debugging improves when agents can see the rendered screen and simulate interactions rather than relying on text outputs alone.
- Text-based approaches remain limited for event-driven programs and visual attributes that require direct inspection of the interface.
- InteractGUI Bench enables fine-grained measurement of both interaction logic and visual structure in GUI tasks.
- Multi-agent setups can use vision to locate and fix functional errors as well as appearance mismatches in one workflow.
- Base model performance on GUI generation rises when visual feedback is added, as shown by the lift from 21.68% to 28.29% success.
Where Pith is reading between the lines
- The same visual loop could be tested on web or mobile GUI frameworks to check whether desktop results generalize.
- Stronger vision-language models would likely widen the observed gap between text-only and visual-feedback methods.
- The benchmark could serve as a standard testbed for comparing alternative feedback mechanisms such as accessibility trees or pixel-level analysis.
- Integrating visual feedback early in code generation rather than only at debug time might further reduce the number of iterations required.
Load-bearing premise
Visual perception of the rendered interface combined with simulated interactions is sufficient to detect and correct both logic errors and layout problems that text-based feedback cannot resolve.
What would settle it
A GUI task whose errors depend on non-visible internal state such as network responses or hidden variables, where VF-Coder produces no gain over text-only debugging.
Figures






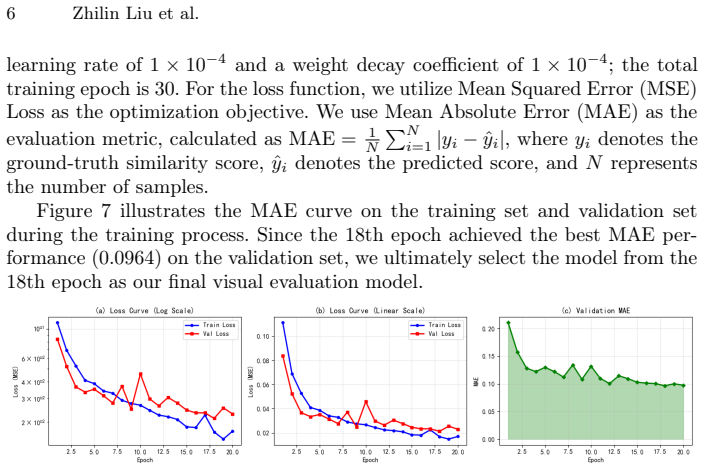

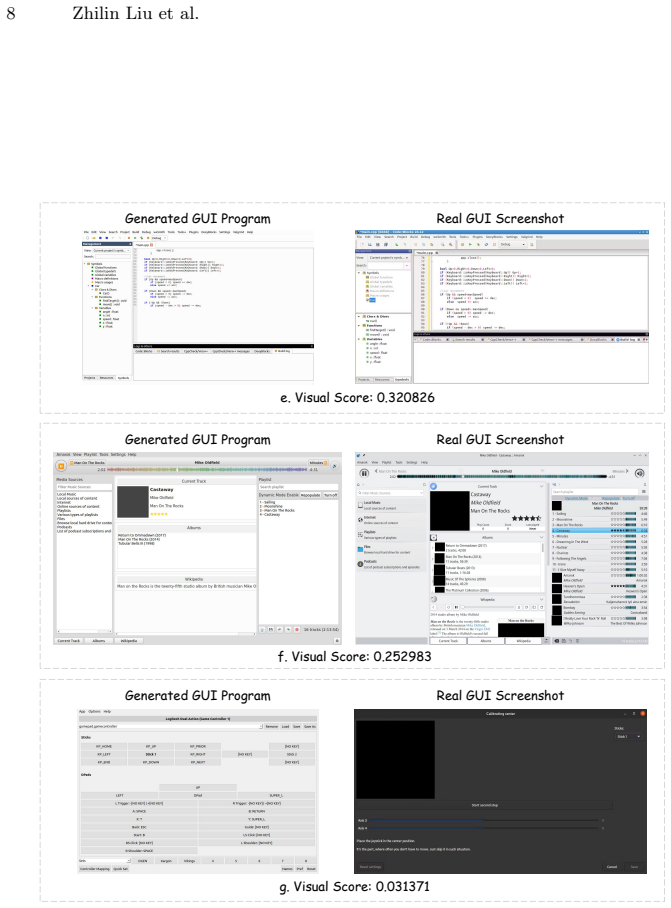






read the original abstract
Recent advances in Large Language Model (LLM)-based agents have shown remarkable progress in code generation. However, current agent methods mainly rely on text-output-based feedback (e.g. command-line outputs) for multi-round debugging and struggle in graphical user interface (GUI) that involve visual information. This is mainly due to two limitations: 1) GUI programs are event-driven, yet existing methods cannot simulate user interactions to trigger GUI element logic 2) GUI programs possess visual attributes, making it difficult for text-based approaches to assess whether the rendered interface meets user needs. To systematically address these challenges, we first introduce InteractGUI Bench, a novel benchmark comprising 984 commonly used real-world desktop GUI application tasks designed for fine-grained evaluation of both interaction logic and visual structure. Furthermore, we propose VF-Coder, a vision-feedback-based multi-agent system for debugging GUI code. By perceiving visual information and directly interacting with program interfaces, VF-Coder can identify potential logic and layout issues in a human-like manner. On InteractGUI Bench, our VF-Coder approach increases the success rate of Gemini-3-Flash from 21.68% to 28.29% and raises the visual score from 0.4284 to 0.5584, indicating the effectiveness of visual feedback in GUI debugging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InteractGUI Bench, a benchmark of 984 real-world desktop GUI tasks for fine-grained evaluation of interaction logic and visual structure, and proposes VF-Coder, a vision-feedback-based multi-agent system that perceives screenshots and simulates interactions to debug GUI code. It claims that VF-Coder raises Gemini-3-Flash success rate from 21.68% to 28.29% and visual score from 0.4284 to 0.5584 on the benchmark.
Significance. If the gains can be attributed specifically to visual feedback rather than the multi-agent scaffolding, the work would offer a practical method for overcoming text-only limitations in GUI code generation and debugging, particularly for layout and event-driven issues.
major comments (1)
- [Experiments] Experiments section: the headline improvements are attributed to visual perception plus interaction, yet no ablation is reported that holds the multi-agent loop, planning, and interaction simulation fixed while replacing screenshots with textual UI descriptions. This control is required to isolate the contribution of vision from the overall architecture.
minor comments (1)
- [Abstract] Abstract: concrete numerical results are stated without any description of the experimental protocol, baseline implementations, number of runs, statistical tests, or controls for confounds such as prompt variations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We agree that isolating the contribution of visual feedback is important for strengthening the claims and will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline improvements are attributed to visual perception plus interaction, yet no ablation is reported that holds the multi-agent loop, planning, and interaction simulation fixed while replacing screenshots with textual UI descriptions. This control is required to isolate the contribution of vision from the overall architecture.
Authors: We agree that this ablation is necessary to isolate the specific contribution of direct visual perception. In the revised manuscript, we will add a new control experiment that keeps the multi-agent loop, planning, and interaction simulation fixed while replacing screenshot inputs with textual UI descriptions (e.g., generated via accessibility trees or LLM-based captioning of the same interfaces). We will report success rates and visual scores for this text-only variant on InteractGUI Bench and compare them directly to the full VF-Coder results. This will clarify the incremental benefit of vision over the scaffolding alone. revision: yes
Circularity Check
Empirical benchmark results contain no definitional or self-referential circularity
full rationale
The paper introduces InteractGUI Bench as a new collection of 984 tasks and VF-Coder as a multi-agent architecture that uses screenshots plus simulated interactions. Reported gains (Gemini-3-Flash success 21.68 % → 28.29 %, visual score 0.4284 → 0.5584) are direct head-to-head measurements on the same fixed task set. No equations, fitted parameters, or self-citations are invoked to derive these numbers; the quantities are externally observable success and visual-match metrics. The derivation chain is therefore self-contained and does not reduce any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CoRR abs/2501.16692(2025).https : / / doi
Acharya, M., Zhang, Y., Leach, K., Huang, Y.: Optimizing code run- time performance through context-aware retrieval-augmented generation. CoRR abs/2501.16692(2025).https : / / doi . org / 10 . 48550 / ARXIV . 2501 . 16692, https://doi.org/10.48550/arXiv.2501.16692
- [2]
-
[3]
Antoniades, A., Örwall, A., Zhang, K., Xie, Y., Goyal, A., Wang, W.Y.: SWE- search: Enhancing software agents with monte carlo tree search and iterative refine- ment. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=G7sIFXugTX
work page 2025
-
[4]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al.: Program synthesis with large language models. arXiv preprint arXiv:2108.07732 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H.P.D.O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al.: Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Google, D.: Gemini 3 flash: Best for frontier intelligence at speed.https:// deepmind.google/models/gemini/flash/(2025)
work page 2025
-
[7]
Google, D.: Gemini 3.1 pro: Best for complex tasks and bringing creative concepts to life.https://deepmind.google/models/gemini/pro/(2026)
work page 2026
-
[8]
arXiv preprint arXiv:2406.12276 (2024)
Gupta, T., Weihs, L., Kembhavi, A.: Codenav: Beyond tool-use to using real-world codebases with llm agents. arXiv preprint arXiv:2406.12276 (2024)
-
[9]
In: European conference on computer vision
He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks. In: European conference on computer vision. pp. 630–645. Springer (2016)
work page 2016
-
[10]
Measuring Coding Challenge Competence With APPS
Hendrycks, D., Basart, S., Kadavath, S., Mazeika, M., Arora, A., Guo, E., Burns, C., Puranik, S., He, H., Song, D., et al.: Measuring coding challenge competence with apps. arXiv preprint arXiv:2105.09938 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
arXiv preprint arXiv:2501.17167 (2025)
Hu, Y., Zhou, Q., Chen, Q., Li, X., Liu, L., Zhang, D., Kachroo, A., Oz, T., Tripp, O.: Qualityflow: An agentic workflow for program synthesis controlled by llm quality checks. arXiv preprint arXiv:2501.17167 (2025)
-
[12]
Jain, N., Han, K., Gu, A., Li, W.D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., Stoica, I.: Livecodebench: Holistic and contamination free evalua- tion of large language models for code. In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= chfJJYC3iL
work page 2025
-
[13]
In: 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE)
Jiang, X., Dong, Y., Tao, Y., Liu, H., Jin, Z., Li, G.: Rocode: Integrating backtrack- ing mechanism and program analysis in large language models for code generation. In: ICSE. pp. 334–346 (2025),https://doi.org/10.1109/ICSE55347.2025.00133
-
[14]
Jimenez, C.E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., Narasimhan, K.R.: SWE-bench: Can language models resolve real-world github issues? In: The Twelfth International Conference on Learning Representations (2024),https: //openreview.net/forum?id=VTF8yNQM66
work page 2024
-
[15]
In: ICML deep learning workshop
Koch, G., Zemel, R., Salakhutdinov, R., et al.: Siamese neural networks for one- shot image recognition. In: ICML deep learning workshop. vol. 2, pp. 1–30. Lille (2015)
work page 2015
-
[16]
arXiv preprint arXiv:2403.09029 (2024) 16 Zhilin Liu et al
Laurençon,H.,Tronchon,L.,Sanh,V.:Unlockingtheconversionofwebscreenshots into html code with the websight dataset. arXiv preprint arXiv:2403.09029 (2024) 16 Zhilin Liu et al
-
[17]
Li, J., Li, G., Zhang, X., Zhao, Y., Dong, Y., Jin, Z., Li, B., Huang, F., Li, Y.: Evocodebench: An evolving code generation benchmark with domain- specific evaluations. In: NeurIPS (2024),http://papers.nips.cc/paper_files/ paper / 2024 / hash / 6a059625a6027aca18302803743abaa2 - Abstract - Datasets _ and_Benchmarks_Track.html
work page 2024
-
[18]
Li, J., Li, G., Zhao, Y., Li, Y., Liu, H., Zhu, H., Wang, L., Liu, K., Fang, Z., Wang, L., Ding, J., Zhang, X., Zhu, Y., Dong, Y., Jin, Z., Li, B., Huang, F., Li, Y., Gu, B., Yang, M.: Deveval: A manually-annotated code generation benchmark aligned with real-world code repositories. In: ACL (Findings). pp. 3603–3614 (2024),https: //doi.org/10.18653/v1/202...
-
[19]
Science378(6624), 1092–1097 (2022)
Li, Y., Choi, D., Chung, J., Kushman, N., Schrittwieser, J., Leblond, R., Eccles, T., Keeling, J., Gimeno, F., Dal Lago, A., et al.: Competition-level code generation with alphacode. Science378(6624), 1092–1097 (2022)
work page 2022
-
[20]
Lu, Z., Yang, Y., Ren, H., Hou, H., Xiao, H., Wang, K., Shi, W., Zhou, A., Zhan, M., Li, H.: Webgen-bench: Evaluating llms on generating interactive and func- tional websites from scratch. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[21]
arXiv preprint arXiv:2412.13501 (2024)
Nguyen, D., Chen, J., Wang, Y., Wu, G., Park, N., Hu, Z., Lyu, H., Wu, J., Aponte, R., Xia, Y., et al.: Gui agents: A survey. arXiv preprint arXiv:2412.13501 (2024)
-
[22]
com / zh - Hans - CN / index / introducing-gpt-5-2/(2025)
OpenAI: Introducing gpt-5.2.https : / / openai . com / zh - Hans - CN / index / introducing-gpt-5-2/(2025)
work page 2025
-
[23]
CausalGraph2LLM: Evaluating LLMs for causal queries
Si, C., Zhang, Y., Li, R., Yang, Z., Liu, R., Yang, D.: Design2code: Benchmark- ing multimodal code generation for automated front-end engineering. In: NAACL (Long Papers). pp. 3956–3974 (2025),https://doi.org/10.18653/v1/2025. naacl-long.199
-
[24]
In: Forty-second International Conference on Machine Learning (2025)
Sohrabizadeh, A., Song, J., Liu, M., Roy, R., Lee, C., Raiman, J., Catanzaro, B.: Nemotron-CORTEXA: Enhancing LLM agents for software engineering tasks via improved localization and solution diversity. In: Forty-second International Conference on Machine Learning (2025)
work page 2025
-
[25]
arXiv preprint arXiv:2508.03923 (2025)
Song, L., Dai, Y., Prabhu, V., Zhang, J., Shi, T., Li, L., Li, J., Savarese, S., Chen, Z., Zhao, J., et al.: Coact-1: Computer-using agents with coding as actions. arXiv preprint arXiv:2508.03923 (2025)
-
[26]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Sun, Y., Zhao, S., Yu, T., Wen, H., Va, S., Xu, M., Li, Y., Zhang, C.: Gui-xplore: Empowering generalizable gui agents with one exploration. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19477–19486 (2025)
work page 2025
-
[27]
Team, C.: Cursor document.https://cursor.com/cn/docs(2025)
work page 2025
-
[28]
Team, G.C.: Build, debug & deploy with ai.https://geminicli.com/(2025)
work page 2025
-
[29]
Kimi K2.5: Visual Agentic Intelligence
Team, K., Bai, T., Bai, Y., Bao, Y., Cai, S., Cao, Y., Charles, Y., Che, H., Chen, C., Chen, G., et al.: Kimi k2. 5: Visual agentic intelligence. arXiv preprint arXiv:2602.02276 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Wang, H., Zou, H., Song, H., Feng, J., Fang, J., Lu, J., Liu, L., Luo, Q., Liang, S., Huang, S., et al.: Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning. arXiv preprint arXiv:2509.02544 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Wang, R., Han, X., Ji, L., Wang, S., Baldwin, T., Li, H.: Toolgen: Unified tool retrieval and calling via generation. In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= XLMAMmowdY
work page 2025
-
[32]
Wu, F., Gao, C., Li, S., Wen, X.C., Liao, Q.: Mllm-based ui2code automation guided by ui layout information. Proceedings of the ACM on Software Engineering 2(ISSTA), 1123–1145 (2025) Visual Feedback Unlocks Reliable GUI Code Generating and Debugging 17
work page 2025
-
[33]
arXiv preprint arXiv:2411.03292 (2024)
Xiao, J., Wan, Y., Huo, Y., Wang, Z., Xu, X., Wang, W., Xu, Z., Wang, Y., Lyu, M.R.: Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping. arXiv preprint arXiv:2411.03292 (2024)
-
[34]
arXiv preprint arXiv:2505.07473 (2025)
Xu, K., Mao, Y., Guan, X., Feng, Z.: Web-bench: A llm code benchmark based on web standards and frameworks. arXiv preprint arXiv:2505.07473 (2025)
-
[35]
arXiv preprint arXiv:2507.05791 (2025)
Yang, Y., Li, D., Dai, Y., Yang, Y., Luo, Z., Zhao, Z., Hu, Z., Huang, J., Saha, A., Chen, Z., et al.: Gta1: Gui test-time scaling agent. arXiv preprint arXiv:2507.05791 (2025)
-
[36]
Ye, H., Yang, A.Z., Hu, C., Wang, Y., Zhang, T., Le Goues, C.: Adverintent- agent: Adversarial reasoning for repair based on inferred program intent. Proc. ACM Softw. Eng.2(ISSTA) (Jun 2025).https://doi.org/10.1145/3728939, https://doi.org/10.1145/3728939
-
[37]
In: 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE)
Yuan, M., Chen, J., Xing, Z., Quigley, A., Luo, Y., Luo, T., Mohammadi, G., Lu, Q., Zhu, L.: Designrepair: Dual-stream design guideline-aware frontend repair with large language models. In: 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). p. 2483–2494. IEEE (Apr 2025).https://doi. org/10.1109/icse55347.2025.00109,http://dx.doi.o...
-
[38]
Zhang, K., Li, J., Li, G., Shi, X., Jin, Z.: Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges. In: ACL (1). pp. 13643–13658 (2024),https://doi.org/10.18653/v1/2024.acl- long.737
-
[39]
arXiv preprint arXiv:2305.04087 (2023)
Zhang, K., Li, Z., Li, J., Li, G., Jin, Z.: Self-edit: Fault-aware code editor for code generation. arXiv preprint arXiv:2305.04087 (2023)
-
[40]
arXiv preprint arXiv:2506.15655 (2025)
Zhang, Y., Zhao, X., Wang, Z.Z., Yang, C., Wei, J., Wu, T.: cast: Enhancing code retrieval-augmented generation with structural chunking via abstract syntax tree. arXiv preprint arXiv:2506.15655 (2025)
-
[41]
arXiv preprint arXiv:2512.22047 (2025)
Zhou, H., Zhang, X., Tong, P., Zhang, J., Chen, L., Kong, Q., Cai, C., Liu, C., Wang, Y., Zhou, J., et al.: Mai-ui technical report: Real-world centric foundation gui agents. arXiv preprint arXiv:2512.22047 (2025)
-
[42]
Zhu, H., Zhang, Y., Zhao, B., Ding, J., Liu, S., Liu, T., Wang, D., Liu, Y., Li, Z.: Frontendbench: A benchmark for evaluating llms on front-end development via automatic evaluation. arXiv preprint arXiv:2506.13832 (2025) Visual Feedback Unlocks Reliable GUI Code Generating and Debugging 1 A More discussions of Proposed InteractGUI Bench In this section, ...
-
[43]
For icons or images that cannot be implemented, you may use rectangular boxes as placeholders
1:1 reproduces all the visual contents from the screenshots (including layout, colors, fonts, spacing, text content and all UI elements). For icons or images that cannot be implemented, you may use rectangular boxes as placeholders
-
[44]
Implements all the interaction logic mentioned in the instructions
-
[45]
Generates complete, directly runnable code without any syntax errors {instruction} Requirements:
-
[46]
File Structure • You are allowed to implement all functionality in a single code file, or generate multiple code files, no matter what, you must use main.py as the entry point (ensure that running python main.py can start the GUI program). • If you generate multiple files, all files must be placed in the same directory • You are NOT allowed to create subd...
-
[47]
You are recommended to use setAccessibleName() to set the accessible name
Component Naming • Please strictly use the element names marked with single quotes '' in the instructions to name components such as icon buttons, text buttons, input boxes, etc., ensuring these elements can be accessed through accessibility tools. You are recommended to use setAccessibleName() to set the accessible name
-
[48]
Output Format • Each file must use independent code blocks, formatted as: ```python filename="main.py" # code here ``` Fig. 13:The prompt used for base models (e.g., GPT-5.2, Claude-4.5-Sonnet) to gen- erate GUI apps on InteractGUI Bench Prompt: Your Task You are a GUI programming assistant responsible for executing complex GUI program debugging tasks. Yo...
-
[49]
Verify that the interaction logic mentioned in the instructions can be correctly executed
Test interaction logic according to instruction requirements: Follow the navigation path described in the instructions (e.g., starting from a specific page, clicking certain buttons/elements, navigating to target pages). Verify that the interaction logic mentioned in the instructions can be correctly executed. If any step in the navigation path fails (e.g...
-
[50]
Check visual consistency with reference images: If a reference page screenshot is provided, compare the current page with the reference image to check if the visual layout, element positions, and styles are consistent. **Focus only on structural visual information (layout, element positions, styles), and do NOT check content- related elements such as imag...
-
[51]
If scrolling operation (scroll) is ineffective → Still cannot find the required content, indicating the interface may not support scrolling or is out of screen range, should immediately report through action=terminate
-
[52]
If clicking operation (click) is ineffective → Indicates button failure or event not bound, should immediately report the specific problem through action=terminate
-
[53]
Do not try the same operation a third time, do not look for other reasons to continue, must immediately terminate and report Output format: Thought: You should think step by step and provide a detailed thought process before generating the next action. Action: - You need to use functions within <tools></tools> XML tags to perform actions based on observat...
-
[54]
Carefully analyze bug descriptions, reference page screenshot and the rendering interface screenshot when error occurs to understand the root cause of problems
-
[55]
Locate the parts that need modification in the source code
-
[56]
Use SEARCH/REPLACE blocks for precise incremental modifications
-
[57]
Ensure fixes do not introduce new problems and the visual rendering effect is as consistent as possible with the reference page screenshot Output Format Requirements - SEARCH/REPLACE Blocks Use the following format for code modifications (this avoids regenerating the entire file, saves tokens, and reduces error risk): filename.ext ```language <<<<<<< SEAR...
-
[58]
Exact Match: The SEARCH part must exactly match the file content character by character (including spaces, indentation, comments)
-
[59]
Replace Once: Each SEARCH/REPLACE block will only replace the first occurrence
-
[60]
Multiple Modifications: If multiple modifications are needed, use multiple independent blocks
-
[61]
Keep It Concise: Only include the lines that need modification and a small amount of context (2-5 lines), do not include large unchanged code sections
-
[62]
16:The prompt used for VF-Coder’s Code Fixer
Create New Files: Leave the SEARCH part empty, put the new file content in the REPLACE part Fig. 16:The prompt used for VF-Coder’s Code Fixer
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.