VTouch++: A Multimodal Dataset with Vision-Based Tactile Enhancement for Bimanual Manipulation
Pith reviewed 2026-05-10 00:04 UTC · model grok-4.3
The pith
A new multimodal dataset uses vision-based tactile sensing to supply high-fidelity physical signals for scalable bimanual robot learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the VTOUCH dataset. It leverages vision based tactile sensing to provide high-fidelity physical interaction signals, adopts a matrix-style task design to enable systematic learning, and employs automated data collection pipelines covering real-world, demand-driven scenarios to ensure scalability. To further validate the effectiveness of the dataset, we conduct extensive quantitative experiments on cross-modal retrieval as well as real-robot evaluation. Finally, we demonstrate real-world performance through generalizable inference across multiple robots, policies, and tasks.
What carries the argument
The VTOUCH dataset, built around vision-based tactile sensing for physical signals, a matrix-style task grid for systematic coverage, and automated collection pipelines for scale.
If this is right
- Matrix task organization allows models to learn bimanual skills in a structured, progressive manner.
- Automated pipelines produce large volumes of data that reflect real demand-driven scenarios.
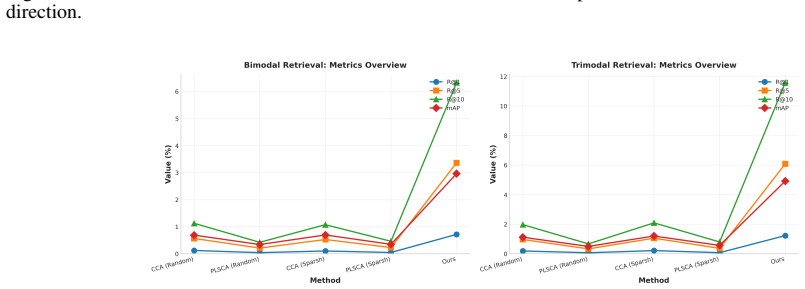
- Cross-modal retrieval experiments confirm that vision and tactile streams can be aligned within the dataset.
- Real-robot evaluations show that learned policies transfer across multiple robots and control approaches.
Where Pith is reading between the lines
- Vision as a tactile proxy could let existing camera-equipped robots gain contact awareness without extra hardware.
- The matrix design offers a template for organizing tasks in other multimodal robot datasets to reduce redundancy.
- Generalization results suggest the dataset may support rapid adaptation when a policy moves to a new robot or environment.
Load-bearing premise
Vision-based tactile sensing delivers physical interaction signals with enough fidelity to substitute for direct tactile sensors in training effective policies.
What would settle it
A controlled test in which policies trained on the dataset achieve no higher success rates on contact-rich bimanual tasks than vision-only baselines when evaluated on physical robots.
Figures











read the original abstract
Embodied intelligence has advanced rapidly in recent years; however, bimanual manipulation-especially in contact-rich tasks remains challenging. This is largely due to the lack of datasets with rich physical interaction signals, systematic task organization, and sufficient scale. To address these limitations, we introduce the VTOUCH dataset. It leverages vision based tactile sensing to provide high-fidelity physical interaction signals, adopts a matrix-style task design to enable systematic learning, and employs automated data collection pipelines covering real-world, demand-driven scenarios to ensure scalability. To further validate the effectiveness of the dataset, we conduct extensive quantitative experiments on cross-modal retrieval as well as real-robot evaluation. Finally, we demonstrate real-world performance through generalizable inference across multiple robots, policies, and tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the VTOUCH dataset, a multimodal collection for bimanual contact-rich manipulation. It uses vision-based tactile sensing to supply high-fidelity physical interaction signals, organizes tasks via a matrix-style design to support systematic learning, and relies on automated pipelines to collect data at scale across real-world scenarios. Effectiveness is validated through quantitative cross-modal retrieval experiments and real-robot transfer tests demonstrating generalization across robots, policies, and tasks.
Significance. If the reported fidelity, coverage, and transfer results hold, the dataset fills a documented gap in tactile-rich bimanual data and could accelerate policy learning for contact-rich tasks. The matrix organization and automated collection are practical strengths, and the dual validation (retrieval plus physical robot tests) provides concrete evidence of utility. The public dataset release itself constitutes a reusable community resource.
minor comments (2)
- [Abstract] Abstract: the title uses 'VTouch++' while the text repeatedly refers to 'VTOUCH'; a single consistent name should be adopted throughout.
- [Experiments] The quantitative results for cross-modal retrieval and real-robot evaluation are summarized but would benefit from an explicit table listing key metrics (e.g., retrieval accuracy, success rates) with standard deviations to allow direct comparison with prior datasets.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our manuscript on the VTOUCH dataset, including recognition of its contributions to high-fidelity tactile signals, matrix-style task organization, automated scalable collection, and validation via cross-modal retrieval and real-robot transfer experiments. We appreciate the recommendation for minor revision.
Circularity Check
No significant circularity
full rationale
The paper is a dataset introduction and empirical validation study rather than a derivation with equations or predictions. It describes the VTOUCH dataset construction via vision-based tactile sensing, matrix-style task organization, and automated collection pipelines, followed by cross-modal retrieval experiments and real-robot evaluations. No load-bearing steps reduce by construction to the inputs: there are no self-definitional relations, fitted parameters presented as predictions, uniqueness theorems imported from self-citations, or ansatzes smuggled via prior work. The central claims rest on reported data collection and experimental results that are externally verifiable and do not loop back to the dataset definition itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2022 , eprint=
Ego4D: Around the World in 3,000 Hours of Egocentric Video , author=. 2022 , eprint=
2022
-
[2]
2020 , eprint=
The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines , author=. 2020 , eprint=
2020
-
[3]
and Tzionas, Dimitrios , year=
Taheri, Omid and Ghorbani, Nima and Black, Michael J. and Tzionas, Dimitrios , year=. GRAB: A Dataset of Whole-Body Human Grasping of Objects , ISBN=. doi:10.1007/978-3-030-58548-8_34 , booktitle=
-
[4]
Fan, Zicong and Parelli, Maria and Kadoglou, Maria Eleni and Kocabas, Muhammed and Chen, Xu and Black, Michael J and Hilliges, Otmar , booktitle=
-
[5]
2019 , eprint=
ContactDB: Analyzing and Predicting Grasp Contact via Thermal Imaging , author=. 2019 , eprint=
2019
-
[6]
2020 , eprint=
ContactPose: A Dataset of Grasps with Object Contact and Hand Pose , author=. 2020 , eprint=
2020
-
[7]
DiffH2O: Diffusion-Based Synthesis of Hand-Object Interactions from Textual Descriptions , url=
Christen, Sammy and Hampali, Shreyas and Sener, Fadime and Remelli, Edoardo and Hodan, Tomas and Sauser, Eric and Ma, Shugao and Tekin, Bugra , year=. DiffH2O: Diffusion-Based Synthesis of Hand-Object Interactions from Textual Descriptions , url=. doi:10.1145/3680528.3687563 , booktitle=
-
[8]
2023 , eprint=
DexGraspNet: A Large-Scale Robotic Dexterous Grasp Dataset for General Objects Based on Simulation , author=. 2023 , eprint=
2023
-
[9]
2024 , eprint=
DexGraspNet 2.0: Learning Generative Dexterous Grasping in Large-scale Synthetic Cluttered Scenes , author=. 2024 , eprint=
2024
-
[10]
2022 , eprint=
Towards Human-Level Bimanual Dexterous Manipulation with Reinforcement Learning , author=. 2022 , eprint=
2022
-
[11]
arXiv preprint arXiv:2509.XXXX , year=
TWIST2: Scalable, Portable, and Holistic Humanoid Data Collection System , author=. arXiv preprint arXiv:2509.XXXX , year=
-
[12]
AgiBot World Colosseum , author=
-
[13]
, TITLE =
Yuan, Wenzhen and Dong, Siyuan and Adelson, Edward H. , TITLE =. Sensors , VOLUME =. 2017 , NUMBER =
2017
-
[14]
arXiv , year =
Digitizing Touch with an Artificial Multimodal Fingertip , author=. arXiv , year =
-
[15]
AnyTouch: Learning Unified Static-Dynamic Representation across Multiple Visuo-tactile Sensors , author=
-
[16]
V-HOP: Visuo-Haptic 6D Object Pose Tracking , url=
Li, Hongyu and Jia, Mingxi and Akbulut, Mete and Xiang, Yu and Konidaris, George and Sridhar, Srinath , year=. V-HOP: Visuo-Haptic 6D Object Pose Tracking , url=. doi:10.15607/rss.2025.xxi.037 , booktitle=
-
[17]
2025 , eprint=
DexCanvas: Bridging Human Demonstrations and Robot Learning for Dexterous Manipulation , author=. 2025 , eprint=
2025
-
[18]
Sensing and Recognizing Surface Textures Using a GelSight Sensor , journal =
Li, Rui and Adelson, Edward , year =. Sensing and Recognizing Surface Textures Using a GelSight Sensor , journal =
-
[19]
RoboNet: Large-Scale Multi-Robot Learning
Sudeep Dasari and Frederik Ebert and Stephen Tian and Suraj Nair and Bernadette Bucher and Karl Schmeckpeper and Siddharth Singh and Sergey Levine and Chelsea Finn , title =. CoRR , volume =. 2019 , url =. 1910.11215 , timestamp =
work page internal anchor Pith review arXiv 2019
-
[20]
2025 , eprint=
FreeTacMan: Robot-free Visuo-Tactile Data Collection System for Contact-rich Manipulation , author=. 2025 , eprint=
2025
-
[21]
The Thirteenth International Conference on Learning Representations , year=
Learning Unified Static-Dynamic Representation across Multiple Visuo-tactile Sensors , author=. The Thirteenth International Conference on Learning Representations , year=
-
[22]
2024 , publisher=
Suresh, Sudharshan and Qi, Haozhi and Wu, Tingfan and Fan, Taosha and Pineda, Luis and Lambeta, Mike and Malik, Jitendra and Kalakrishnan, Mrinal and Calandra, Roberto and Kaess, Michael and Ortiz, Joseph and Mukadam, Mustafa , journal=. 2024 , publisher=
2024
-
[23]
Water , VOLUME =
Kulanuwat, Lattawit and Chantrapornchai, Chantana and Maleewong, Montri and Wongchaisuwat, Papis and Wimala, Supaluk and Sarinnapakorn, Kanoksri and Boonya-aroonnet, Surajate , TITLE =. Water , VOLUME =. 2021 , NUMBER =
2021
-
[24]
arXiv preprint arXiv:2208.03063 , year=
RoboMimic: A Versatile Simulation Platform for Imitation Learning , author=. arXiv preprint arXiv:2208.03063 , year=
-
[25]
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , year=
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware , author=. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , year=
-
[26]
ICCV , pages=
A Metric for Distributions with Applications to Image Databases , author=. ICCV , pages=
-
[27]
Computational Optimal Transport , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.