Recognition: unknown
IRIS: Interpolative R\'enyi Iterative Self-play for Large Language Model Fine-Tuning
Pith reviewed 2026-05-10 01:12 UTC · model grok-4.3
The pith
An adjustable Rényi order parameter lets self-play fine-tuning adapt its objective as the model closes the gap to the target distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
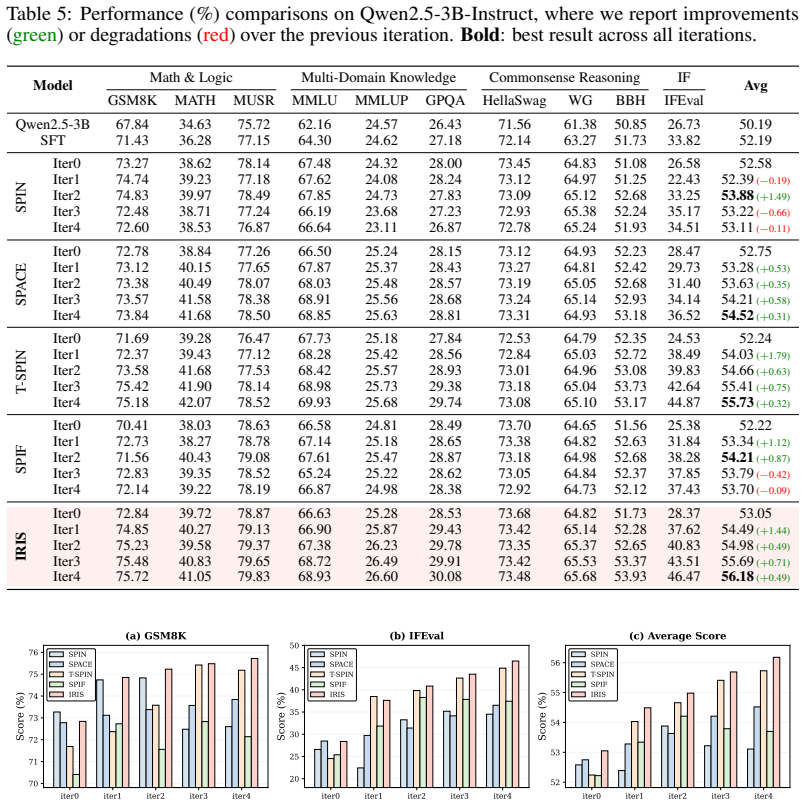
IRIS decomposes the self-play objective into two independent tilted risk terms, one over annotated data and one over synthetic data, whose relative weighting is controlled by the Rényi order alpha through exponential importance factors. An adaptive schedule adjusts alpha to the distributional gap between the current model and the target, the method is proved to possess a fixed-point property, and alpha is shown to modulate gradient concentration during updates.
What carries the argument
The Rényi order parameter alpha that interpolates between divergence regimes and is scheduled adaptively to the distributional gap between model and target.
If this is right
- Existing self-play methods such as SPIN, SPACE, and SPIF correspond to particular fixed values of alpha.
- Training dynamics remain stable by shifting from sharp importance weighting early in training to smoother weighting near convergence.
- Higher final performance becomes reachable with substantially fewer annotated samples than are needed for full supervised fine-tuning.
- Gradient updates can be made more or less concentrated by direct choice of the alpha schedule.
Where Pith is reading between the lines
- Similar adaptive interpolation between divergence measures may stabilize iterative self-improvement loops in other machine-learning settings.
- The unification suggests that choosing the divergence regime according to training stage is a general principle worth testing in reinforcement-learning-from-human-feedback pipelines.
- The method raises the possibility that fewer human annotations overall could suffice for alignment tasks if the adaptive schedule generalizes across model scales.
Load-bearing premise
The distributional gap between model and target can be measured reliably enough to set alpha without introducing instability or requiring per-task retuning.
What would settle it
A side-by-side run of IRIS with the adaptive alpha schedule versus the same method using any single fixed alpha value, on the same data splits and model, that shows no consistent performance gain for the adaptive version would falsify the claimed benefit of the schedule.
Figures




read the original abstract
Self-play fine-tuning enables large language models to improve beyond supervised fine-tuning without additional human annotations by contrasting annotated responses with self-generated ones. Many existing methods rely on a fixed divergence regime. SPIN is closely related to a KL-based regime, SPACE to a Jensen-Shannon-style objective via noise contrastive estimation, and SPIF to $\chi^2$-regularized self-play. Since these divergences exhibit different strengths depending on the distributional gap between model and target, no single choice appears to provide favorable learning dynamics across training stages. We propose IRIS (Interpolative R\'enyi Iterative Self-play), a R\'enyi-based self-play fine-tuning framework with a continuously adjustable objective. IRIS decomposes into two independent tilted risk terms over annotated and synthetic data, with exponential importance weights controlled by the order parameter $\alpha$. We show that several self-play objectives can be interpreted as limiting or representative regimes at particular values of $\alpha$, providing a unified theoretical perspective on these methods. An adaptive order schedule further adjusts $\alpha$ to the distributional gap, shifting from sharper importance weighting early in training to smoother refinement near convergence. Theoretically, we establish the fixed-point property of IRIS and analyze how $\alpha$ controls gradient concentration. Experiments on Zephyr-7B and Qwen2.5-3B across ten benchmarks show that IRIS improves upon baselines, reaching 44.57\% average score with gains across iterations. In our setting, IRIS with only 26$k$ annotated samples surpasses standard supervised fine-tuning trained on the full 200$k$ dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IRIS, a Rényi-divergence-based self-play fine-tuning framework for LLMs that uses an order parameter α to interpolate between divergence regimes. It unifies SPIN (KL), SPACE (JS-style), and SPIF (χ²) as special cases of α, introduces an adaptive schedule that adjusts α according to the distributional gap between model and target (sharper early, smoother later), proves a fixed-point property, and analyzes α's effect on gradient concentration. Experiments on Zephyr-7B and Qwen2.5-3B across ten benchmarks report an average score of 44.57% with iterative gains, claiming that IRIS trained on only 26k annotated samples outperforms standard SFT on the full 200k dataset.
Significance. If the empirical results hold under proper validation, IRIS offers a unified theoretical lens on self-play methods and a practical route to improved data efficiency by reducing reliance on large annotated sets. The fixed-point property and gradient analysis are clear theoretical strengths; the adaptive schedule is a plausible design choice for handling varying distributional gaps across training stages.
major comments (3)
- [Experiments] Experiments section: The central data-efficiency claim (IRIS at 26k annotated samples surpassing SFT at 200k) and the 44.57% average score are reported without error bars, standard deviations across runs, statistical significance tests, or details on the 26k subset selection protocol. This undermines assessment of whether the iterative gains are reliable or reproducible.
- [Method and Experiments] Adaptive order schedule (described in the method and experiments): The headline performance depends on the adaptive α schedule that shifts based on distributional gap, yet no ablations isolate its contribution versus fixed-α variants, test stability across tasks/models, or demonstrate that no per-task retuning is needed. This is load-bearing for the practical unification and efficiency claims.
- [Theoretical Analysis] Theoretical analysis: The fixed-point property and gradient concentration analysis are established for IRIS, but the manuscript provides no explicit proof details, assumptions on the adaptive schedule's interaction with the fixed point, or conditions under which the unification holds when α varies dynamically.
minor comments (2)
- [Method] Notation for the two tilted risk terms and exponential importance weights could be clarified with an explicit equation relating them to the Rényi objective.
- [Experiments] The abstract and experiments would benefit from a table summarizing per-benchmark scores and baselines for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which highlight important areas for strengthening the empirical validation, ablation studies, and theoretical exposition in our manuscript. We address each major comment below and commit to revisions that improve clarity and rigor without altering the core contributions of IRIS.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central data-efficiency claim (IRIS at 26k annotated samples surpassing SFT at 200k) and the 44.57% average score are reported without error bars, standard deviations across runs, statistical significance tests, or details on the 26k subset selection protocol. This undermines assessment of whether the iterative gains are reliable or reproducible.
Authors: We agree that the lack of error bars, standard deviations, and statistical tests weakens the assessment of result reliability. In the revised manuscript, we will rerun the key experiments on Zephyr-7B and Qwen2.5-3B with at least three random seeds, reporting means and standard deviations for the average score and per-benchmark results. We will add paired t-tests or Wilcoxon tests to establish statistical significance against baselines. For the 26k subset, we will explicitly state that it was obtained by stratified random sampling from the full 200k dataset to preserve the distribution of query difficulty and domains; this protocol will be detailed in the Experiments section along with a new appendix table showing per-run scores. revision: yes
-
Referee: [Method and Experiments] Adaptive order schedule (described in the method and experiments): The headline performance depends on the adaptive α schedule that shifts based on distributional gap, yet no ablations isolate its contribution versus fixed-α variants, test stability across tasks/models, or demonstrate that no per-task retuning is needed. This is load-bearing for the practical unification and efficiency claims.
Authors: We acknowledge the value of isolating the adaptive schedule's contribution. In the revision, we will add a dedicated ablation subsection comparing the full adaptive schedule against fixed-α baselines (α = 0.5, 1.0, 2.0) on the same benchmarks and models. We will also report results on an additional held-out task to assess cross-task stability and confirm that the schedule requires no per-task hyperparameter retuning, as α is computed automatically from the distributional gap at each iteration. These results will be presented with the same evaluation protocol as the main experiments. revision: yes
-
Referee: [Theoretical Analysis] Theoretical analysis: The fixed-point property and gradient concentration analysis are established for IRIS, but the manuscript provides no explicit proof details, assumptions on the adaptive schedule's interaction with the fixed point, or conditions under which the unification holds when α varies dynamically.
Authors: We agree that explicit proof details and discussion of the adaptive schedule are needed. In the revised manuscript, we will expand the theoretical section and add a full appendix containing the complete proof of the fixed-point property, including all assumptions (e.g., the objective is minimized via gradient steps and the distributional gap is non-increasing). We will clarify that the unification holds for any fixed α and that the adaptive schedule preserves the fixed-point property at convergence because α stabilizes as the gap approaches zero; we will also state the conditions under which dynamic α does not violate the unification (namely, that α remains within the valid range [0, ∞) throughout training). revision: yes
Circularity Check
No circularity: unification is algebraic observation; adaptive schedule is independent design choice
full rationale
The paper derives IRIS by expressing the objective as two tilted risks with exponential weights controlled by α, then algebraically shows that SPIN (KL), SPACE (JS via NCE), and SPIF (χ²) arise at specific α values or limits. This unification is a direct mathematical rewriting, not a fitted parameter or self-referential definition. The fixed-point property and gradient-concentration analysis are stated as independent theoretical results. The adaptive α schedule is introduced as an additional heuristic that adjusts to distributional gap; no equation shows that downstream performance predictions are forced by the schedule itself or by prior self-citations. Empirical claims (44.57 % average, 26 k samples beating 200 k SFT) rest on reported runs rather than definitional equivalence. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha
axioms (2)
- domain assumption IRIS objective possesses a fixed-point property
- domain assumption Distributional gap between model and target can be reliably estimated and used to adapt alpha
Reference graph
Works this paper leans on
-
[1]
Investigating regularization of self-play language models.arXiv preprint arXiv:2404.04291, 2024
Reda Alami, Abdalgader Abubaker, Mastane Achab, Mohamed El Amine Seddik, and Salem Lahlou. Investigating regularization of self-play language models.arXiv preprint arXiv:2404.04291, 2024
-
[2]
A general class of coefficients of divergence of one distribution from another.Journal of the Royal Statistical Society: Series B (Methodological), 28(1):131–142, 1966
Syed Mumtaz Ali and Samuel D Silvey. A general class of coefficients of divergence of one distribution from another.Journal of the Royal Statistical Society: Series B (Methodological), 28(1):131–142, 1966
1966
-
[3]
Springer, 2016
Shun-ichi Amari.Information Geometry and Its Applications. Springer, 2016
2016
-
[4]
Claude 3.5 sonnet
Anthropic. Claude 3.5 sonnet. https://www.anthropic.com/news/claude-3-5-sonnet ,
-
[5]
Accessed: 2026-04-04
2026
-
[6]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. InInternational Conference on Artificial Intelligence and Statistics, pages 4447–4455. PMLR, 2024
2024
-
[7]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review arXiv 2022
-
[8]
Open llm leaderboard (2023–2024)
Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Lewis Tunstall, and Thomas Wolf. Open llm leaderboard (2023–2024). https://huggingface.co/spaces/open-llm-leaderboard-old/open_ llm_leaderboard, 2023. Accessed: 2026-04-04
2023
-
[9]
On a measure of divergence between two statistical populations defined by their probability distributions.Bulletin of the Calcutta Mathematical Society, 35:99– 109, 1943
Anil Kumar Bhattacharyya. On a measure of divergence between two statistical populations defined by their probability distributions.Bulletin of the Calcutta Mathematical Society, 35:99– 109, 1943
1943
-
[10]
Varia- tional representations and neural network estimation of Rényi divergences.SIAM Journal on Mathematics of Data Science, 4(2):773–811, 2022
Jeremiah Birrell, Paul Dupuis, Markos A Katsoulakis, Luc Rey-Bellet, and Jie Wang. Varia- tional representations and neural network estimation of Rényi divergences.SIAM Journal on Mathematics of Data Science, 4(2):773–811, 2022
2022
-
[11]
Accurately computing the log-sum-exp and softmax functions.IMA Journal of Numerical Analysis, 41(4):2311–2330, 2021
Pierre Blanchard, Desmond J Higham, and Nicholas J Higham. Accurately computing the log-sum-exp and softmax functions.IMA Journal of Numerical Analysis, 41(4):2311–2330, 2021
2021
-
[12]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models.arXiv preprint arXiv:2401.01335, 2024
work page internal anchor Pith review arXiv 2024
-
[13]
Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[14]
Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
2024
-
[15]
Families of alpha-beta-and gamma-divergences: Flexible and robust measures of similarities.Entropy, 12(6):1532–1568, 2010
Andrzej Cichocki and Shun-ichi Amari. Families of alpha-beta-and gamma-divergences: Flexible and robust measures of similarities.Entropy, 12(6):1532–1568, 2010
2010
-
[16]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 10
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Information-type measures of difference of probability distributions and indirect observations.Studia Scientiarum Mathematicarum Hungarica, 2:299–318, 1967
Imre Csiszár. Information-type measures of difference of probability distributions and indirect observations.Studia Scientiarum Mathematicarum Hungarica, 2:299–318, 1967
1967
-
[18]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations, 2024
2024
-
[19]
Mucong Ding, Souradip Chakraborty, Vibhu Agrawal, Zora Che, Alec Koppel, Mengdi Wang, Amrit Bedi, and Furong Huang. SAIL: Self-improving efficient online alignment of large language models.arXiv preprint arXiv:2406.15567, 2024
-
[20]
Enhancing chat language models by scaling high-quality instructional conversations
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations.arXiv preprint arXiv:2305.14233, 2023
-
[21]
How abilities in large language models are affected by supervised fine-tuning data composition
Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li, Mingfeng Xue, Dayiheng Liu, Wei Wang, Zheng Yuan, Chang Zhou, and Jingren Zhou. How abilities in large language models are affected by supervised fine-tuning data composition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 177–198, 2024
2024
-
[22]
Asymptotic evaluation of certain Markov process expectations for large time
Monroe D Donsker and S R Srinivasa Varadhan. Asymptotic evaluation of certain Markov process expectations for large time. IV.Communications on Pure and Applied Mathematics, 36(2):183–212, 1983
1983
-
[23]
KTO: Model alignment as prospect theoretic optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. KTO: Model alignment as prospect theoretic optimization. InProceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[24]
Duanyu Feng, Bowen Qin, Chen Huang, Zheng Zhang, and Wenqiang Lei. Towards ana- lyzing and understanding the limitations of DPO: A theoretical perspective.ArXiv e-prints, arXiv:2404.04626, 2024
-
[25]
Sprec: Leveraging self-play to debias preference alignment for large language model-based recommendations.arXiv e-prints, pages arXiv–2412, 2024
Chongming Gao, Ruijun Chen, Shuai Yuan, Kexin Huang, Yuanqing Yu, and Xiangnan He. Sprec: Leveraging self-play to debias preference alignment for large language model-based recommendations.arXiv e-prints, pages arXiv–2412, 2024
2024
-
[26]
A framework for few-shot language model evaluation.Zenodo, 2023
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golber, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework ...
2023
-
[27]
Rényi divergence measures for commonly used univariate continuous distributions.Information Sciences, 249:124–131, 2013
Manuel Gil, Fady Alajaji, and Tamás Linder. Rényi divergence measures for commonly used univariate continuous distributions.Information Sciences, 249:124–131, 2013
2013
-
[28]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[29]
Gemini 2.5: Our most intelligent ai model
Google. Gemini 2.5: Our most intelligent ai model. https://blog.google/technology/ google-deepmind/gemini-model-thinking-updates-march-2025/ , 2025. Accessed: 2026-04-04
2025
-
[30]
Accelerate: Training and inference at scale made simple, efficient and adaptable
Sylvain Gugger, Lysandre Debut, Thomas Wolf, Philipp Schmid, Zachary Mueller, Sourab Manber, Marc Sun, and Benjamin Bossan. Accelerate: Training and inference at scale made simple, efficient and adaptable. 2022
2022
-
[31]
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models
Michael Gutmann and Aapo Hyvärinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. InProceedings of the thirteenth international con- ference on artificial intelligence and statistics, pages 297–304. JMLR Workshop and Conference Proceedings, 2010. 11
2010
-
[32]
Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics.Journal of machine learning research, 13(2), 2012
Michael U Gutmann and Aapo Hyvärinen. Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics.Journal of machine learning research, 13(2), 2012
2012
-
[33]
Measuring massive multitask language understanding.International Conference on Learning Representations, 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Ja- cob Steinhardt. Measuring massive multitask language understanding.International Conference on Learning Representations, 2021
2021
-
[34]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. Advances in Neural Information Processing Systems, 34:7294–7306, 2021
2021
-
[35]
José Miguel Hernández-Lobato, Yingzhen Li, Mark Rowland, Thang Bui, Daniel Hernández- Lobato, and Richard E. Turner. Black-box α-divergence minimization. InProceedings of the 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 1511–1520, 2016
2016
-
[36]
Neural networks for machine learning: Lecture 6a overview of mini-batch gradient descent
Geoffrey Hinton, Nitish Srivastava, and Kevin Swersky. Neural networks for machine learning: Lecture 6a overview of mini-batch gradient descent. Technical report, University of Toronto, 2012
2012
-
[37]
ORPO: Monolithic preference optimization without reference model
Jiwoo Hong, Noah Lee, and James Thorne. ORPO: Monolithic preference optimization without reference model. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
2024
-
[38]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[39]
Xiang Ji, Sanjeev Kulkarni, Mengdi Wang, and Tengyang Xie. Self-play with adversarial critic: Provable and scalable offline alignment for language models.arXiv preprint arXiv:2406.04274, 2024
-
[40]
RLAIF vs
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. RLAIF vs. RLHF: Scaling reinforcement learning from human feedback with AI feedback. InProceedings of the 41st International Conference on Machine Learning, volume 235. PMLR, 2024
2024
-
[41]
Shangzhe Li, Xuchao Zhang, Chetan Bansal, and Weitong Zhang. Your self-play algorithm is secretly an adversarial imitator: Understanding llm self-play through the lens of imitation learning.arXiv preprint arXiv:2602.01357, 2026
-
[42]
Tilted empirical risk minimization
Tian Li, Ahmad Beirami, Maziar Sanjabi, and Virginia Smith. Tilted empirical risk minimization. InInternational Conference on Learning Representations, 2021
2021
-
[43]
Rényi divergence variational inference
Yingzhen Li and Richard E Turner. Rényi divergence variational inference. InAdvances in Neural Information Processing Systems, volume 29, 2016
2016
-
[44]
Drift: Difference-aware reinforcement through iterative fine-tuning for language model
Wenjie Liao, Xiaohui Song, and Haonan Lu. Drift: Difference-aware reinforcement through iterative fine-tuning for language model. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 31988–31996, 2026
2026
-
[45]
Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning.arXiv preprint arXiv:2312.15685, 2023
-
[46]
SimPO: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. SimPO: Simple preference optimization with a reference-free reward. InAdvances in Neural Information Processing Systems, 2024
2024
-
[47]
Rényi differential privacy
Ilya Mironov. Rényi differential privacy. In2017 IEEE 30th Computer Security Foundations Symposium (CSF), pages 263–275. IEEE, 2017. 12
2017
-
[48]
Cross-task gener- alization via natural language crowdsourcing instructions
Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. Cross-task gener- alization via natural language crowdsourcing instructions. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3470–3487, 2022
2022
-
[49]
Contribution to the theory of the chi-square test
Jerzy Neyman. Contribution to the theory of the chi-square test. InProceedings of the First Berkeley Symposium on Mathematical Statistics and Probability, pages 239–273. University of California Press, 1949
1949
-
[50]
Estimating divergence func- tionals and the likelihood ratio by convex risk minimization.IEEE Transactions on Information Theory, 56(11):5847–5861, 2010
XuanLong Nguyen, Martin J Wainwright, and Michael I Jordan. Estimating divergence func- tionals and the likelihood ratio by convex risk minimization.IEEE Transactions on Information Theory, 56(11):5847–5861, 2010
2010
-
[51]
f-GAN: Training generative neu- ral samplers using variational divergence minimization
Sebastian Nowozin, Botond Cseke, and Ryota Tomioka. f-GAN: Training generative neu- ral samplers using variational divergence minimization. InAdvances in Neural Information Processing Systems, volume 29, 2016
2016
-
[52]
OpenAI. Gpt-4. https://openai.com/index/gpt-4-research/, 2023. Accessed: 2026- 04-04
2023
-
[53]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[54]
Arka Pal, Deep Karkhanis, Samuel Dooley, Manley Roberts, Siddartha Naidu, and Colin White. Smaug: Fixing failure modes of preference optimisation with DPO-positive.ArXiv e-prints, arXiv:2402.13228, 2024
-
[55]
Karl Pearson. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling.The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 50(302):157–175, 1900
1900
-
[56]
From r to q∗: Your language model is secretly aq-function
Rafael Rafailov, Joey Hejna, Ryan Park, and Chelsea Finn. From r to q∗: Your language model is secretly aq-function. InFirst Conference on Language Modeling, 2024
2024
-
[57]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[58]
ZeRO: Memory op- timizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. ZeRO: Memory op- timizations toward training trillion parameter models. InInternational Conference for High Performance Computing, Networking, Storage and Analysis, 2020
2020
-
[59]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. GPQA: A graduate-level google-proof Q&A benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review arXiv 2023
-
[60]
Learning or self-aligning? rethinking instruction fine-tuning
Mengjie Ren, Boxi Cao, Hongyu Lin, Cao Liu, Xianpei Han, Ke Zeng, Wan Guanglu, Xunliang Cai, and Le Sun. Learning or self-aligning? rethinking instruction fine-tuning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6090–6105, 2024
2024
-
[61]
On measures of entropy and information
Alfréd Rényi. On measures of entropy and information. InProceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pages 547–561. University of California Press, 1961
1961
-
[62]
Code Llama: Open Foundation Models for Code
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023. 13
work page internal anchor Pith review arXiv 2023
-
[63]
WinoGrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An adversarial winograd schema challenge at scale. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 13726–13734, 2021
2021
-
[64]
Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
2017
-
[65]
MuSR: Testing the limits of chain-of-thought with multistep soft reasoning
Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. MuSR: Testing the limits of chain-of-thought with multistep soft reasoning. InInternational Conference on Learning Representations, 2024
2024
-
[66]
Challenging BIG-Bench tasks and whether chain-of-thought can solve them.Findings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, 2023
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, and Jason Wei. Challenging BIG-Bench tasks and whether chain-of-thought can solve them.Findings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, 2023
2023
-
[67]
Large language models for data annotation and synthesis: A survey
Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, and Huan Liu. Large language models for data annotation and synthesis: A survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 930–957, 2024
2024
-
[68]
RSPO: Regularized self-play alignment of large language models.arXiv preprint arXiv:2503.00030, 2025
Xiaohang Tang, Sangwoong Yoon, Seongho Son, Huizhuo Yuan, Quanquan Gu, and Ilija Bogunovic. RSPO: Regularized self-play alignment of large language models.arXiv preprint arXiv:2503.00030, 2025
-
[69]
LaMDA: Language Models for Dialog Applications
Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng- Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. Lamda: Language models for dialog applications.arXiv preprint arXiv:2201.08239, 2022
work page Pith review arXiv 2022
-
[70]
Songjun Tu, Jiahao Lin, Xiangyu Tian, Qichao Zhang, Linjing Li, Yuqian Fu, Nan Xu, Wei He, Xiangyuan Lan, Dongmei Jiang, et al. Enhancing llm reasoning with iterative dpo: A comprehensive empirical investigation.arXiv preprint arXiv:2503.12854, 2025
-
[71]
Rush, and Thomas Wolf
Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Shengyi Huang, Kashif Rasul, Alvaro Bartolome, Alexander M. Rush, and Thomas Wolf. The alignment handbook. GitHub repository, 2024
2024
-
[72]
arXiv preprint arXiv:2310.16944 , year=
Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro V on Werra, Clémentine Fourrier, Nathan Habib, et al. Zephyr: Direct distillation of lm alignment.arXiv preprint arXiv:2310.16944, 2023
-
[73]
Rényi divergence and Kullback-Leibler divergence.IEEE Transactions on Information Theory, 60(7):3797–3820, 2014
Tim van Erven and Peter Harremoës. Rényi divergence and Kullback-Leibler divergence.IEEE Transactions on Information Theory, 60(7):3797–3820, 2014
2014
-
[74]
Beyond reverse KL: Generalizing direct preference optimization with diverse divergence constraints
Chaoqi Wang, Yibo Jiang, Chenghao Yang, Han Liu, and Yuxin Chen. Beyond reverse KL: Generalizing direct preference optimization with diverse divergence constraints. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[75]
Su, and Yaodong Yang
Mingzhi Wang, Chengdong Ma, Qizhi Chen, Linjian Meng, Yang Han, Jiancong Xiao, Zhaowei Zhang, Jing Huo, Weijie J. Su, and Yaodong Yang. Magnetic preference optimization: Achieving last-iterate convergence for language model alignment. InInternational Conference on Learning Representations, 2025
2025
-
[76]
Yibo Wang, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Lijun Zhang. Space: Noise contrastive estimation stabilizes self-play fine-tuning for large language models.arXiv preprint arXiv:2512.07175, 2025
-
[77]
Triplets better than pairs: Towards stable and effective self-play fine-tuning for llms
Yibo Wang, Hai-Long Sun, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Lijun Zhang. Triplets better than pairs: Towards stable and effective self-play fine-tuning for llms. arXiv preprint arXiv:2601.08198, 2026. 14
-
[78]
How far can camels go? exploring the state of instruction tuning on open resources.Advances in Neural Information Processing Systems, 36:74764–74786, 2023
Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Chandu, David Wadden, Kelsey MacMillan, Noah A Smith, Iz Beltagy, et al. How far can camels go? exploring the state of instruction tuning on open resources.Advances in Neural Information Processing Systems, 36:74764–74786, 2023
2023
-
[79]
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neural Information Processing Systems, 2024
2024
-
[80]
Shiguang Wu, Yaqing Wang, and Quanming Yao. Self-generative adversarial fine-tuning for large language models.arXiv preprint arXiv:2602.01137, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.