Recognition: unknown
Breaking MCP with Function Hijacking Attacks: Novel Threats for Function Calling and Agentic Models
Pith reviewed 2026-05-09 23:59 UTC · model grok-4.3
The pith
Agentic AI models can be forced to invoke attacker-chosen functions via a hijacking attack that ignores query context and function set details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a function hijacking attack manipulates the tool selection process of agentic models to force invocation of a specific attacker-chosen function. This attack is largely agnostic to context semantics and remains robust across different function sets. It can be trained to produce universal adversarial functions that succeed across multiple queries and payload configurations. Experiments on five instructed and reasoning models using the BFCL dataset reach attack success rates from 70 percent to 100 percent. These results demonstrate concrete vulnerabilities in the function calling interface beyond traditional prompt injection methods.
What carries the argument
The function hijacking attack (FHA), a prompt-based manipulation that overrides the model's normal selection of which external function to invoke.
Load-bearing premise
The high success rates and robustness to function sets shown in the experiments will continue to appear when the same attack is applied to real-world deployments with varied and unpredictable function sets.
What would settle it
Testing the attack on a fresh set of models and function-calling tasks that were never seen during development and recording success rates below 50 percent would show the reported performance does not generalize.
Figures























read the original abstract
The growth of agentic AI has drawn significant attention to function calling Large Language Models (LLMs), which are designed to extend the capabilities of AI-powered system by invoking external functions. Injection and jailbreaking attacks have been extensively explored to showcase the vulnerabilities of LLMs to user prompt manipulation. The expanded capabilities of agentic models introduce further vulnerabilities via their function calling interface. Recent work in LLM security showed that function calling can be abused, leading to data tampering and theft, causing disruptive behavior such as endless loops, or causing LLMs to produce harmful content in the style of jailbreaking attacks. This paper introduces a novel function hijacking attack (FHA) that manipulates the tool selection process of agentic models to force the invocation of a specific, attacker-chosen function. While existing attacks focus on semantic preference of the model for function-calling tasks, we show that FHA is largely agnostic to the context semantics and robust to the function sets, making it applicable across diverse domains. We further demonstrate that FHA can be trained to produce universal adversarial functions, enabling a single attacked function to hijack tool selection across multiple queries and payload configurations. We conducted experiments on 5 different models, including instructed and reasoning variants, reaching 70% to 100% ASR over the established BFCL dataset. Our findings further demonstrate the need for strong guardrails and security modules for agentic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a novel Function Hijacking Attack (FHA) that manipulates the tool selection process of function-calling agentic LLMs to force invocation of an attacker-chosen function. It claims FHA is largely agnostic to context semantics and robust to varying function sets (unlike prior semantic-preference attacks), supports training of universal adversarial functions effective across queries, and achieves 70-100% attack success rate (ASR) on the BFCL benchmark across five models (instructed and reasoning variants). The work concludes by calling for stronger guardrails in agentic systems.
Significance. If the generality claims hold, the result would be significant for LLM security: it identifies a non-semantic attack vector on tool-use interfaces that could affect deployed agentic systems across domains. The multi-model evaluation on a standard benchmark (BFCL) provides concrete empirical grounding, and the universal-adversarial-function direction is a potentially useful extension. However, the current evidence base is too narrow to establish the claimed robustness properties.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: The central claim that FHA is 'largely agnostic to the context semantics and robust to the function sets' is load-bearing yet unsupported by the reported results. The 70-100% ASR is measured only on the fixed BFCL dataset; no ablation varies function-set size, description style, or domain while holding the attack construction fixed, leaving open the possibility that success still depends on BFCL-specific semantic cues or distributions.
- [Methods] Methods/Attack Construction section: The manuscript provides no concrete details on how the FHA is implemented, how the attack prompt or function is constructed, what baselines or controls are used for comparison, or how confounding factors (model-specific prompting, tool-count effects) are isolated. Without these, the high ASR figures cannot be assessed for reproducibility or validity.
- [Experiments] Universal adversarial functions claim: The assertion that a single attacked function can hijack tool selection 'across multiple queries and payload configurations' requires explicit cross-query and cross-payload evaluation; the current BFCL results do not demonstrate this property.
minor comments (2)
- [Title and Abstract] The title references 'MCP' without expansion or definition in the abstract; clarify the acronym and its relation to the function-calling setting.
- [Abstract] The abstract states results on 'instructed and reasoning variants' but does not name the five models or variants; add this information for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The central claim that FHA is 'largely agnostic to the context semantics and robust to the function sets' is load-bearing yet unsupported by the reported results. The 70-100% ASR is measured only on the fixed BFCL dataset; no ablation varies function-set size, description style, or domain while holding the attack construction fixed, leaving open the possibility that success still depends on BFCL-specific semantic cues or distributions.
Authors: We acknowledge that dedicated ablations on function-set size, description style, and domain would strengthen the generality claims. BFCL already spans diverse functions and domains with consistent high ASR, but we will add explicit ablations and clarify the scope of our robustness statements in the revision. revision: partial
-
Referee: [Methods] Methods/Attack Construction section: The manuscript provides no concrete details on how the FHA is implemented, how the attack prompt or function is constructed, what baselines or controls are used for comparison, or how confounding factors (model-specific prompting, tool-count effects) are isolated. Without these, the high ASR figures cannot be assessed for reproducibility or validity.
Authors: We agree that additional implementation details are required. The revised manuscript will expand the Methods section with precise descriptions of FHA construction, attack prompt and function design, baselines, and controls for confounding factors including tool count and prompting variations. revision: yes
-
Referee: [Experiments] Universal adversarial functions claim: The assertion that a single attacked function can hijack tool selection 'across multiple queries and payload configurations' requires explicit cross-query and cross-payload evaluation; the current BFCL results do not demonstrate this property.
Authors: The BFCL results cover multiple queries, but we recognize the need for targeted cross-query and cross-payload tests. We will include dedicated experiments evaluating the universal adversarial functions on held-out queries and varied payloads in the revision. revision: yes
Circularity Check
No circularity: purely empirical attack demonstration
full rationale
The paper introduces FHA via description and then reports empirical attack success rates (70-100% ASR) measured on the external BFCL benchmark across five models. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-referential definitions appear. Claims of semantic agnosticism and robustness are presented as experimental outcomes on the fixed benchmark rather than derived quantities. No self-citation chains or ansatzes are invoked to justify core results; the work is self-contained as an empirical security evaluation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Function Hijacking Attack (FHA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2407.00121. Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, and Xander Davies. Agentharm: A benchmark for measuring harmfulness of llm agents,
-
[2]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
URLhttps: //arxiv.org/abs/2410.09024. Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, and Pavlo Molchanov. Small language models are the future of agentic ai,
work page internal anchor Pith review arXiv
-
[3]
URLhttps: //arxiv.org/abs/2506.02153. Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,
-
[4]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
URLhttps://arxiv.org/abs/2406.13352. Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges. In Kate Larson (ed.),Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, pp....
work page internal anchor Pith review arXiv
-
[5]
Large language model based multi-agents: A survey of progress and challenges,
doi: 10.24963/ijcai.2024/890. URLhttps://doi.org/10.24963/ijcai.2024/890. Survey Track. 14 Jonathan Hayase, Ema Borevkovic, Nicholas Carlini, Florian Tramèr, and Milad Nasr. Query-based adver- sarial prompt generation,
-
[6]
Query-based adversarial prompt generation
URLhttps://arxiv.org/abs/2402.12329. Feng He, Tianqing Zhu, Dayong Ye, Bo Liu, Wanlei Zhou, and Philip S. Yu. The emerged security and privacy of llm agent: A survey with case studies,
-
[7]
The emerged security and privacy of LLM agent: A survey with case studies,
URLhttps://arxiv.org/abs/2407.19354. Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. Model context protocol (mcp): Landscape, security threats, and future research directions,
-
[8]
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
URLhttps://arxiv.org/abs/2503.23278. IBM-Research. Granite foundation models (whitepaper),
work page internal anchor Pith review arXiv
-
[9]
URLhttps://arxiv.org/abs/2310.06825. Ishan Kavathekar, Raghav Donakanti, Ponnurangam Kumaraguru, and Karthik Vaidhyanathan. Small models, big tasks: An exploratory empirical study on small language models for function calling,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Wilhelm Kirch (ed.).Pearson’s Correlation Coefficient, pp
URLhttps://arxiv.org/abs/2504.19277. Wilhelm Kirch (ed.).Pearson’s Correlation Coefficient, pp. 1090–1091. Springer Netherlands, Dordrecht,
-
[11]
doi: 10.1007/978-1-4020-5614-7_2569
ISBN 978-1-4020-5614-7. doi: 10.1007/978-1-4020-5614-7_2569. URLhttps://doi.org/10.1007/ 978-1-4020-5614-7_2569. Deepak Kumar, Riccardo Paccagnella, Paul Murley, Eric Hennenfent, Joshua Mason, Adam Bates, and Michael Bailey. Skill squatting attacks on amazon alexa. In27th USENIX Security Symposium (USENIX Security 18), pp. 33–47, Baltimore, MD, August
-
[12]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
URLhttps://arxiv.org/abs/2310.04451. Graziano A. Manduzio, Federico A. Galatolo, Mario G. C. A. Cimino, Enzo Pasquale Scilingo, and Lorenzo Cominelli. Improving small-scale large language models function calling for reasoning tasks,
work page internal anchor Pith review arXiv
-
[13]
URL https://arxiv.org/abs/2410.18890. OpenAI and al. Gpt-4 technical report,
-
[14]
URLhttps://arxiv.org/abs/2303.08774. Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Gorilla: Large Language Model Connected with Massive APIs
URLhttps://arxiv.org/abs/2305.15334. Qwen-Team. Qwen3 technical report,
work page internal anchor Pith review arXiv
-
[16]
URLhttps://arxiv.org/abs/2505.09388. Ambrish Rawat, Stefan Schoepf, Giulio Zizzo, Giandomenico Cornacchia, Muhammad Zaid Hameed, Kieran Fraser, Erik Miehling, Beat Buesser, Elizabeth M. Daly, Mark Purcell, Prasanna Sattigeri, Pin-Yu Chen, and Kush R. Varshney. Attack atlas: A practitioner’s perspective on challenges and pitfalls in red teaming genai,
work page internal anchor Pith review Pith/arXiv arXiv
- [17]
-
[18]
URLhttps://arxiv.org/abs/2302.04761. 15 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models,
work page internal anchor Pith review arXiv
-
[19]
LLaMA: Open and Efficient Foundation Language Models
URL https://arxiv.org/abs/2302.13971. Anahit Vassilev, Alina Oprea, Alyssa Fordyce, and Hilary Andersen. Adversarial machine learning: A taxonomy and terminology of attacks and mitigations. Nist trustworthy and responsible ai, National Institute of Standards and Technology, Gaithersburg, MD,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
A survey on large language model based autonomous agents,
URLhttps://nvlpubs.nist.gov/ nistpubs/ai/NIST.AI.100-2e2025.pdf. Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6), March 2024a. ISSN 2095-2236. doi: 1...
-
[21]
MPMA: Preference Manipulation Attack against Model Context Protocol,
URLhttps://arxiv. org/abs/2505.11154. Zijun Wang, Haoqin Tu, Jieru Mei, Bingchen Zhao, Yisen Wang, and Cihang Xie. Attngcg: Enhancing jailbreaking attacks on llms with attention manipulation, 2024b. URLhttps://arxiv.org/abs/2410. 09040. Mengsong Wu, Tong Zhu, Han Han, Xiang Zhang, Wenbiao Shao, and Wenliang Chen. Chain-of-tools: Utilizing massive unseen t...
-
[22]
Chain-of-Tools: Utilizing massive unseen tools in chain-of-thought reasoning
URLhttps:// arxiv.org/abs/2503.16779. Zihui Wu, Haichang Gao, Jianping He, and Ping Wang. The dark side of function calling: Pathways to jailbreaking large language models,
-
[23]
The dark side of function calling: Pathways to jailbreaking large language models
URLhttps://arxiv.org/abs/2407.17915. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models,
-
[24]
ReAct: Synergizing Reasoning and Acting in Language Models
URLhttps://arxiv.org/abs/2210.03629. Sibo Yi, Yule Liu, Zhen Sun, Tianshuo Cong, Xinlei He, Jiaxing Song, Ke Xu, and Qi Li. Jailbreak attacks and defenses against large language models: A survey,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
URLhttps://arxiv.org/abs/2407.04295. Jiahao Yu, Haozheng Luo, Jerry Yao-Chieh Hu, Wenbo Guo, Han Liu, and Xinyu Xing. Mind the in- conspicuous: Revealing the hidden weakness in aligned llms’ refusal boundaries,
work page internal anchor Pith review arXiv
-
[26]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang
URLhttps: //arxiv.org/abs/2405.20653. Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents,
-
[27]
Breaking agents: Compromising autonomous LLM agents through malfunction amplification
URL https://arxiv.org/abs/2407.20859. Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models,
-
[28]
URLhttps://arxiv.org/abs/2406.04313. 16 Appendix Table of Contents A Function Calling Syntax of Different Models 18 B GCG Algorithm Adapted to the Function-Calling Task 18 B.1 Simple FHA algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 B.2 Universal FHA algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . ....
-
[29]
Figures (1), (2) and (3) detail the prompts used for the reformulation (1) and argument-variation (2), and multi-intent variation (3) strategies, respectively
26 G Synthetic Data Generation G.1 Prompts Figure 18 shows the prompts used to perform synthetic data generation usingGPT-4o-mini(OpenAI & al., 2024). Figures (1), (2) and (3) detail the prompts used for the reformulation (1) and argument-variation (2), and multi-intent variation (3) strategies, respectively. Synthetic data generation (1). Forumlation Div...
2024
-
[30]
Specifically, we observe a peak on lower values for strategy (3), representing the queries containing different intents from the original prompt
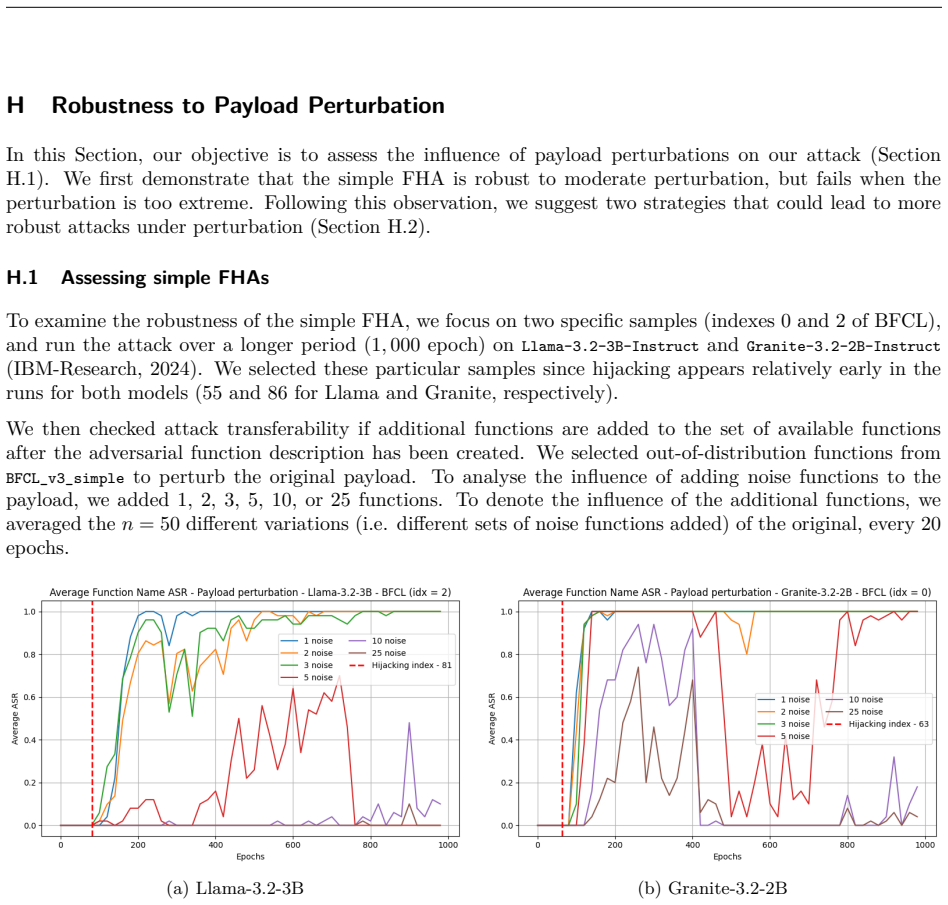
and more spread toward lower values. Specifically, we observe a peak on lower values for strategy (3), representing the queries containing different intents from the original prompt. (a) Distance to prompt (b) Intra-batches distance Figure 20: Analysis of the Data Augmentation strategies -FunSecBenchdataset. 28 H Robustness to Payload Perturbation In this...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.