Recognition: unknown
Exploring the Role of Synthetic Data Augmentation in Controllable Human-Centric Video Generation
Pith reviewed 2026-05-09 22:19 UTC · model grok-4.3
The pith
Experiments show synthetic data complements real data to improve motion realism, temporal consistency, and identity preservation in controllable human video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
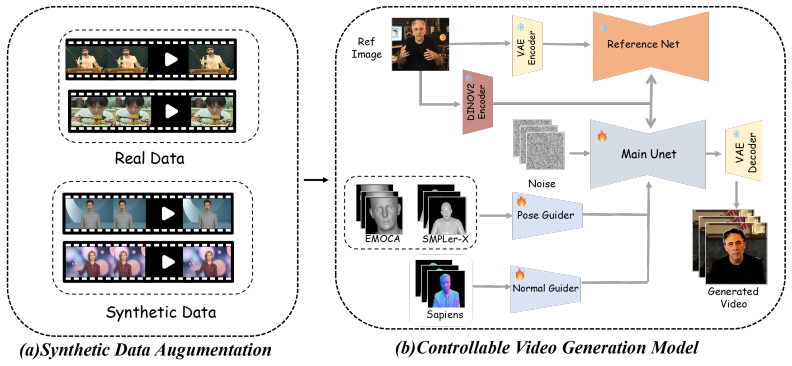
A diffusion-based framework that supplies fine-grained control over appearance and motion also serves as a unified testbed for measuring synthetic-real data interactions; extensive experiments using this testbed demonstrate that synthetic and real data are complementary and that efficient selection of synthetic samples measurably boosts motion realism, temporal consistency, and identity preservation.
What carries the argument
The diffusion-based framework providing fine-grained appearance and motion control while acting as a unified testbed to isolate synthetic-real data interactions.
If this is right
- Synthetic data can scalably supplement scarce real video datasets for rare actions and identities.
- Efficient synthetic-sample selection improves generated video quality without increasing real-data collection costs.
- The same framework can be reused to test other data-mixture strategies in human-centric generation.
- Insights from the study apply directly to building more data-efficient and generalizable video generators.
Where Pith is reading between the lines
- The selection techniques could be automated with a small validation set to reduce manual tuning.
- Similar complementary effects may appear in other generative domains such as image or 3D synthesis.
- Reducing dependence on large real-video collections could ease privacy and licensing constraints in deployed systems.
Load-bearing premise
The diffusion framework can accurately isolate and quantify how synthetic and real data interact even though a Sim2Real gap remains.
What would settle it
Training the same model on real data alone versus real data plus the authors' selected synthetic samples and observing no gain (or a loss) in quantitative metrics for motion realism, temporal consistency, and identity preservation would falsify the central claim.
Figures




read the original abstract
Controllable human video generation aims to produce realistic videos of humans with explicitly guided motions and appearances,serving as a foundation for digital humans, animation, and embodied AI.However, the scarcity of largescale, diverse, and privacy safe human video datasets poses a major bottleneck, especially for rare identities and complex actions.Synthetic data provides a scalable and controllable alternative,yet its actual contribution to generative modeling remains underexplored due to the persistent Sim2Real gap.In this work,we systematically investigate the impact of synthetic data on controllable human video generation. We propose a diffusion-based framework that enables fine-grained control over appearance and motion while providing a unfied testbed to analyze how synthetic data interacts with real world data during training. Through extensive experiments, we reveal the complementary roles of synthetic and real data and demonstrate possible methods for efficiently selecting synthetic samples to enhance motion realism,temporal consistency,and identity preservation.Our study offers the first comprehensive exploration of synthetic data's role in human-centric video synthesis and provides practical insights for building data-efficient and generalizable generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a diffusion-based framework for controllable human-centric video generation that serves as a unified testbed for analyzing interactions between synthetic and real data. Through experiments, it claims to reveal complementary roles of the two data sources and to demonstrate effective methods for selecting synthetic samples that improve motion realism, temporal consistency, and identity preservation, addressing data scarcity and privacy issues in the domain.
Significance. If the experimental claims hold, the work provides the first systematic exploration of synthetic data augmentation in this setting and offers practical selection strategies that could improve data efficiency and generalization in generative video models. This is valuable given the bottlenecks in real human video datasets.
major comments (2)
- [Abstract] The abstract states that the framework 'enables fine-grained control' and provides a 'unified testbed' to isolate synthetic-real interactions, yet no details are supplied on the control mechanisms, loss terms, or isolation protocol (e.g., how motion and appearance are disentangled or how the Sim2Real gap is quantified). This makes the central claim that the testbed 'accurately isolates' effects difficult to evaluate.
- [Abstract] The claim that synthetic-sample selection methods 'enhance motion realism, temporal consistency, and identity preservation' is presented as a key finding, but the abstract supplies neither the selection criteria, the quantitative metrics used, nor any comparison tables showing effect sizes relative to baselines or random selection. Without these, the practical utility of the proposed methods cannot be assessed.
minor comments (3)
- [Abstract] Typo: 'unfied' should be 'unified'.
- [Abstract] The phrase 'large scale' should be hyphenated as 'large-scale' for consistency with standard technical writing.
- [Abstract] The abstract mentions 'extensive experiments' but does not list any specific datasets, model architectures, or evaluation protocols; adding a brief enumeration would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work's significance and the recommendation for minor revision. The comments highlight opportunities to improve the abstract's clarity, which we will address by incorporating concise references to key technical elements and quantitative results while respecting length constraints.
read point-by-point responses
-
Referee: [Abstract] The abstract states that the framework 'enables fine-grained control' and provides a 'unified testbed' to isolate synthetic-real interactions, yet no details are supplied on the control mechanisms, loss terms, or isolation protocol (e.g., how motion and appearance are disentangled or how the Sim2Real gap is quantified). This makes the central claim that the testbed 'accurately isolates' effects difficult to evaluate.
Authors: We acknowledge that the abstract's brevity leaves some aspects implicit. The full manuscript details the control mechanisms in Section 3 (separate pose and appearance encoders with cross-attention conditioning in the diffusion U-Net), the loss terms (standard DDPM denoising loss augmented with temporal smoothness and identity consistency regularizers), and the isolation protocol (controlled synthetic-to-real mixing ratios with evaluation on held-out real videos, quantifying the Sim2Real gap via FID, motion trajectory error, and perceptual metrics). To strengthen the abstract, we will add a brief clause referencing these elements and the testbed's design for isolating data interactions. revision: yes
-
Referee: [Abstract] The claim that synthetic-sample selection methods 'enhance motion realism, temporal consistency, and identity preservation' is presented as a key finding, but the abstract supplies neither the selection criteria, the quantitative metrics used, nor any comparison tables showing effect sizes relative to baselines or random selection. Without these, the practical utility of the proposed methods cannot be assessed.
Authors: We agree this addition would better convey the findings' utility. Section 4.3 describes the selection criteria (motion quality filtering via pose estimator confidence, diversity via feature clustering, and identity consistency via embedding similarity). Metrics include FID and motion realism scores for realism, optical-flow-based temporal coherence, and ArcFace-based identity preservation, with Tables 2–4 reporting effect sizes (e.g., consistent gains over random selection and no-selection baselines). We will revise the abstract to note the selection strategy and the observed improvements in the three aspects. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical exploration of synthetic data effects in controllable human video generation via a diffusion-based framework. It contains no mathematical derivations, equations, predictions, or first-principles results that could reduce to inputs by construction. All claims rest on experimental observations of data interactions, with no self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations. The reader's assessment of score 2.0 aligns with the absence of any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yohann Cabon, Naila Murray, and Martin Humenberger. Vir- tual kitti 2.arXiv preprint arXiv:2001.10773, 2020
work page internal anchor Pith review arXiv 2001
-
[2]
Smpler-x: Scaling up expressive human pose and shape estimation.Advances in Neural In- formation Processing Systems, 36:11454–11468, 2023
Zhongang Cai, Wanqi Yin, Ailing Zeng, Chen Wei, Qing- ping Sun, Wang Yanjun, Hui En Pang, Haiyi Mei, Mingyuan Zhang, Lei Zhang, et al. Smpler-x: Scaling up expressive human pose and shape estimation.Advances in Neural In- formation Processing Systems, 36:11454–11468, 2023
2023
-
[3]
Estelle Chigot, Dennis G Wilson, Meriem Ghrib, and Thomas Oberlin. Style transfer with diffusion models for synthetic-to-real domain adaptation.arXiv preprint arXiv:2505.16360, 2025
-
[4]
Emoca: Emotion driven monocular face capture and animation
Radek Dan ˇeˇcek, Michael J Black, and Timo Bolkart. Emoca: Emotion driven monocular face capture and animation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 20311–20322, 2022
2022
-
[5]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 4690–4699, 2019
2019
-
[6]
Looking to listen at the cocktail party: 8 Table 1
Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T Freeman, and Michael Rubinstein. Looking to listen at the cocktail party: 8 Table 1. Comparison between models w/o finetune on synthetic data. PSNR↑SSIM↑LPIPS↓FVD↓ID-Sim↑ Baseline 20.0446 0.7219 0.1781 8.7054 0.4322 Finetuned20.7764 0.7220 0.1727 7.1540 0.4666 T...
-
[7]
High-fidelity and freely controllable talking head video generation
Yue Gao, Yuan Zhou, Jinglu Wang, Xiao Li, Xiang Ming, and Yan Lu. High-fidelity and freely controllable talking head video generation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 5609–5619, 2023
2023
-
[8]
Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020
2020
-
[9]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text- to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023
work page internal anchor Pith review arXiv 2023
-
[10]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[11]
Video dif- fusion models.Advances in neural information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video dif- fusion models.Advances in neural information processing systems, 35:8633–8646, 2022
2022
-
[12]
Sim2real in robotics and automation: Applications and challenges.IEEE transactions on automation science and engineering, 18(2): 398–400, 2021
Sebastian H ¨ofer, Kostas Bekris, Ankur Handa, Juan Camilo Gamboa, Melissa Mozifian, Florian Golemo, Chris Atkeson, Dieter Fox, Ken Goldberg, John Leonard, et al. Sim2real in robotics and automation: Applications and challenges.IEEE transactions on automation science and engineering, 18(2): 398–400, 2021
2021
-
[13]
Image quality metrics: Psnr vs
Alain Hore and Djemel Ziou. Image quality metrics: Psnr vs. ssim. In2010 20th international conference on pattern recognition, pages 2366–2369. IEEE, 2010
2010
-
[14]
Animate anyone: Consistent and controllable image- to-video synthesis for character animation
Li Hu. Animate anyone: Consistent and controllable image- to-video synthesis for character animation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8153–8163, 2024
2024
-
[15]
Animate anyone 2: High-fidelity character image animation with environment affordance,
Li Hu, Guangyuan Wang, Zhen Shen, Xin Gao, Dechao Meng, Lian Zhuo, Peng Zhang, Bang Zhang, and Liefeng Bo. Animate anyone 2: High-fidelity character image animation with environment affordance.arXiv preprint arXiv:2502.06145, 2025
-
[16]
Faces that speak: Jointly synthesising talking face and speech from text
Youngjoon Jang, Ji-Hoon Kim, Junseok Ahn, Doyeop Kwak, Hong-Sun Yang, Yoon-Cheol Ju, Il-Hwan Kim, Byeong- Yeol Kim, and Joon Son Chung. Faces that speak: Jointly synthesising talking face and speech from text. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8818–8828, 2024
2024
-
[17]
Sapiens: Foundation for human vision mod- els
Rawal Khirodkar, Timur Bagautdinov, Julieta Martinez, Su Zhaoen, Austin James, Peter Selednik, Stuart Anderson, and Shunsuke Saito. Sapiens: Foundation for human vision mod- els. InEuropean Conference on Computer Vision, pages 206–228. Springer, 2024
2024
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Common diffusion noise schedules and sample steps are flawed
Shanchuan Lin, Bingchen Liu, Jiashi Li, and Xiao Yang. Common diffusion noise schedules and sample steps are flawed. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 5404–5411, 2024
2024
-
[21]
Smpl: A skinned multi- person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi- person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023
2023
-
[22]
Mimo: Controllable character video synthesis with spatial decomposed modeling
Yifang Men, Yuan Yao, Miaomiao Cui, and Liefeng Bo. Mimo: Controllable character video synthesis with spatial decomposed modeling. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21181– 21191, 2025
2025
-
[23]
Dense pose transfer
Natalia Neverova, Riza Alp Guler, and Iasonas Kokkinos. Dense pose transfer. InProceedings of the European confer- ence on computer vision (ECCV), pages 123–138, 2018. 9
2018
-
[24]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[26]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
work page Pith review arXiv 2024
-
[27]
Playing for data: Ground truth from computer games
Stephan R Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. InEuropean conference on computer vision, pages 102–118. Springer, 2016
2016
-
[28]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[29]
CAD2RL: Real Single-Image Flight without a Single Real Image
Fereshteh Sadeghi and Sergey Levine. Cad2rl: Real single- image flight without a single real image.arXiv preprint arXiv:1611.04201, 2016
work page Pith review arXiv 2016
-
[30]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review arXiv 2022
-
[31]
Fake it till you make it: Learning trans- ferable representations from synthetic imagenet clones
Mert B ¨ulent Sarıyıldız, Karteek Alahari, Diane Larlus, and Yannis Kalantidis. Fake it till you make it: Learning trans- ferable representations from synthetic imagenet clones. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 8011–8021, 2023
2023
-
[32]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review arXiv 2002
-
[33]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[34]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[35]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Woj- ciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017
2017
-
[36]
Training deep networks with synthetic data: Bridging the reality gap by domain randomization
Jonathan Tremblay, Aayush Prakash, David Acuna, Mark Brophy, Varun Jampani, Cem Anil, Thang To, Eric Camer- acci, Shaad Boochoon, and Stan Birchfield. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. InProceedings of the IEEE confer- ence on computer vision and pattern recognition workshops, pages 969–977, 2018
2018
-
[37]
Stableanimator: High- quality identity-preserving human image animation
Shuyuan Tu, Zhen Xing, Xintong Han, Zhi-Qi Cheng, Qi Dai, Chong Luo, and Zuxuan Wu. Stableanimator: High- quality identity-preserving human image animation. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 21096–21106, 2025
2025
-
[38]
Shuyuan Tu, Zhen Xing, Xintong Han, Zhi-Qi Cheng, Qi Dai, Chong Luo, Zuxuan Wu, and Yu-Gang Jiang. Sta- bleanimator++: Overcoming pose misalignment and face distortion for human image animation.arXiv preprint arXiv:2507.15064, 2025
-
[39]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. To- wards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review arXiv 2018
-
[40]
Haowen Wang, Guowei Zhang, Xiang Zhang, Zeyuan Chen, Haiyang Xu, Dou Hoon Kwark, and Zhuowen Tu. Ex- ploring the equivalence of closed-set generative and real data augmentation in image classification.arXiv preprint arXiv:2508.09550, 2025
-
[41]
Disco: Disentangled control for realistic human dance generation
Tan Wang, Linjie Li, Kevin Lin, Yuanhao Zhai, Chung- Ching Lin, Zhengyuan Yang, Hanwang Zhang, Zicheng Liu, and Lijuan Wang. Disco: Disentangled control for realistic human dance generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9326–9336, 2024
2024
-
[42]
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. Video-to- video synthesis.arXiv preprint arXiv:1808.06601, 2018
-
[43]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[44]
Magicanimate: Temporally consistent human im- age animation using diffusion model
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, and Mike Zheng Shou. Magicanimate: Temporally consistent human im- age animation using diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1481–1490, 2024
2024
-
[45]
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, and Yu Qiao. Accvideo: Accelerating video diffusion model with synthetic dataset.arXiv preprint arXiv:2503.19462, 2025
-
[46]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[47]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018
2018
-
[48]
Yuang Zhang, Jiaxi Gu, Li-Wen Wang, Han Wang, Junqi Cheng, Yuefeng Zhu, and Fangyuan Zou. Mim- icmotion: High-quality human motion video generation with confidence-aware pose guidance.arXiv preprint arXiv:2406.19680, 2024
-
[49]
Youliang Zhang, Zhaoyang Li, Duomin Wang, Jiahe Zhang, Deyu Zhou, Zixin Yin, Xili Dai, Gang Yu, and Xiu Li. 10 Speakervid-5m: A large-scale high-quality dataset for audio- visual dyadic interactive human generation.arXiv preprint arXiv:2507.09862, 2025
-
[50]
RealisDance: Equip controllable character animation with realistic hands
Jingkai Zhou, Benzhi Wang, Weihua Chen, Jingqi Bai, Dongyang Li, Aixi Zhang, Hao Xu, Mingyang Yang, and Fan Wang. Realisdance: Equip controllable character anima- tion with realistic hands.arXiv preprint arXiv:2409.06202, 2024
-
[51]
Generative inbetweening through frame- wise conditions-driven video generation
Tianyi Zhu, Dongwei Ren, Qilong Wang, Xiaohe Wu, and Wangmeng Zuo. Generative inbetweening through frame- wise conditions-driven video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27968–27978, 2025. 11
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.