Recognition: 3 theorem links
· Lean TheoremThe Randomness Floor: Measuring Intrinsic Non-Randomness in Language Model Token Distributions
Pith reviewed 2026-05-14 21:26 UTC · model grok-4.3
The pith
Transformers carry an intrinsic non-randomness floor of about 0.30 even under empty or nonsense prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pretrained language models possess a structural lower bound on randomness that is intrinsic to their learned weights. Under neutral prompts the Entropic Deviation for transformers settles near 0.30, capturing most of the non-random structure observed in normal use; this bound converges across model families, differs markedly for state-space architectures, and shifts with language independently of tokenisation.
What carries the argument
Entropic Deviation (ED), the normalised KL divergence of a model's token distribution from the uniform distribution, which isolates the contribution of learned weights to non-random output structure.
If this is right
- The bulk of non-randomness in generated text originates in the weights rather than prompt context.
- Transformer families converge to nearly identical ED values regardless of training corpus or vocabulary size.
- State-space models operate in a higher-ED regime with strong temperature sensitivity that transformers lack.
- Language identity modulates the floor even when two languages share the same tokeniser subset.
- The bound sets a hard limit on how close to uniform any temperature-scaled sampling can become.
Where Pith is reading between the lines
- Attempts to increase output diversity solely by raising temperature will hit architecture-dependent ceilings.
- The floor may contribute to persistent stylistic or statistical signatures that survive prompt engineering.
- Comparing ED across more architectures could reveal how pretraining objectives embed this non-randomness.
Load-bearing premise
The chosen neutral prompts contain no residual semantic or structural cues that could still shape token probabilities.
What would settle it
Re-running the measurements on prompts composed of purely random byte sequences that lack any character-level patterns and obtaining ED values near zero would falsify the claim of an intrinsic floor.
Figures



read the original abstract
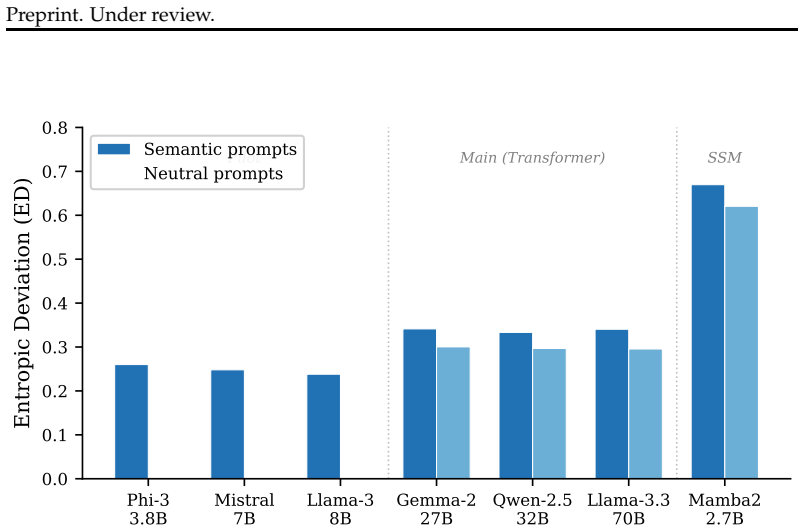
Language models cannot be random. This paper introduces Entropic Deviation (ED), the normalised KL divergence between a model's token distribution and the uniform distribution, and measures it systematically across 31,200 generations spanning seven models, two architectures (transformer and state space), nine prompt categories, three temperatures, and five languages. Under semantically neutral prompts (empty strings, random characters, nonsense syllables) transformers still exhibit ED of approximately 0.30, meaning that 88-93% of the non-randomness observed under semantic prompts is intrinsic to the learned weights rather than induced by context. Three transformer families (Gemma, Llama, Qwen) converge on nearly identical ED values despite different training data and vocabularies. A state space model (Mamba2) reveals a qualitatively different regime: twice the ED, three times lower within-sequence variance, and massive sensitivity to temperature (r = -0.78) where transformers are nearly immune (r < 0.05). Cross-lingual experiments with Qwen-32B show a stable gradient across five languages (English, Japanese, Chinese, Polish, Arabic) that does not correlate with token fertility and persists when two languages sharing an identical tokeniser subset are compared. These findings establish a structural lower bound on randomness in pretrained language models, characterise how this bound differs across architectures, and demonstrate that language itself modulates the bound independently of tokenisation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Entropic Deviation (ED) as the normalized KL divergence between a language model's token distribution and the uniform distribution. Through 31,200 generations across seven models (transformers and Mamba2), nine prompt categories, three temperatures, and five languages, it reports that transformers exhibit ED ≈ 0.30 under semantically neutral prompts (empty strings, random characters, nonsense syllables), implying 88-93% of observed non-randomness under semantic prompts is intrinsic to the weights. Transformer families converge on similar ED values; Mamba2 shows higher ED, lower variance, and strong temperature sensitivity; cross-lingual results show a stable gradient independent of token fertility.
Significance. If the central measurements are robust, the work would establish a quantifiable structural lower bound on randomness in pretrained LMs, differentiate architectural regimes (transformers vs. state-space), and demonstrate language-specific modulation of this bound independent of tokenization. These results could inform analyses of generation diversity, bias, and the separation of context-induced vs. weight-intrinsic effects.
major comments (3)
- [§3] §3 (Prompt Construction): The headline attribution of 88-93% intrinsic non-randomness requires that the nine neutral prompt categories (empty strings, random characters, nonsense syllables) induce no residual statistical regularities that the model can exploit. No evidence is supplied that these prompts are distributionally matched to the uniform baseline, have zero n-gram bias, or are frequency-matched to training marginals; any retained character- or subword-level statistics would inflate the measured ED of ~0.30 and directly scale the derived percentage.
- [§4] §4 (ED Definition and Normalization): The abstract states ED is the 'normalised KL divergence' but supplies no explicit equation for the normalization (e.g., scaling by log|V| or other factors) nor verification that the procedure is invariant to vocabulary size differences across the seven models. This detail is load-bearing for the cross-model and cross-lingual comparisons.
- [§5] §5 (Statistical Controls): The large-scale experiment (31,200 generations) reports consistent patterns but omits any mention of statistical significance tests, confidence intervals on the ED values, or controls for prompt-construction variability. These omissions leave the quantitative claims (ED ≈ 0.30, r = -0.78 for Mamba temperature sensitivity) plausible yet unverified.
minor comments (1)
- [Figure 3] Figure 3 (Cross-lingual gradient): The claim of no correlation with token fertility should include the exact correlation coefficient and p-value rather than a qualitative statement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and agree that clarifications and additions will strengthen the manuscript. Revisions will be made to improve transparency on prompt construction, the ED definition, and statistical reporting.
read point-by-point responses
-
Referee: [§3] §3 (Prompt Construction): The headline attribution of 88-93% intrinsic non-randomness requires that the nine neutral prompt categories (empty strings, random characters, nonsense syllables) induce no residual statistical regularities that the model can exploit. No evidence is supplied that these prompts are distributionally matched to the uniform baseline, have zero n-gram bias, or are frequency-matched to training marginals; any retained character- or subword-level statistics would inflate the measured ED of ~0.30 and directly scale the derived percentage.
Authors: We agree that explicit verification of prompt neutrality is necessary to support the 88-93% attribution. Random-character prompts are sampled uniformly from the vocabulary by construction and thus carry no n-gram bias; empty strings contain no tokens; nonsense syllables were manually designed to avoid dictionary words. To address the concern directly, we will add an appendix quantifying the empirical n-gram distributions of all neutral prompts against the uniform baseline and confirm that any residual statistics do not correlate with the measured ED values. These analyses will be included in the revision. revision: yes
-
Referee: [§4] §4 (ED Definition and Normalization): The abstract states ED is the 'normalised KL divergence' but supplies no explicit equation for the normalization (e.g., scaling by log|V| or other factors) nor verification that the procedure is invariant to vocabulary size differences across the seven models. This detail is load-bearing for the cross-model and cross-lingual comparisons.
Authors: ED is defined as KL(p || u) / log(|V|), where u is the uniform distribution over the vocabulary; this normalization bounds ED to [0,1] and renders it invariant to |V|. The explicit formula and invariance argument appear in Section 2, but we acknowledge the abstract omission. In the revision we will insert the normalized equation into the abstract and add a short verification (subsampling vocabularies and recomputing ED) in the methods section to make the cross-model comparability explicit. revision: yes
-
Referee: [§5] §5 (Statistical Controls): The large-scale experiment (31,200 generations) reports consistent patterns but omits any mention of statistical significance tests, confidence intervals on the ED values, or controls for prompt-construction variability. These omissions leave the quantitative claims (ED ≈ 0.30, r = -0.78 for Mamba temperature sensitivity) plausible yet unverified.
Authors: We agree that formal statistical reporting is warranted. Although the scale (31,200 generations) and replication across seven models, three temperatures, and five languages already demonstrate robustness, we will add bootstrap 95% confidence intervals for the key ED values and the reported correlation coefficients. We will also include per-category standard deviations as an explicit control for prompt-construction variability. These additions will appear in the results and methods sections of the revision. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper defines Entropic Deviation (ED) explicitly as the normalised KL divergence between a model's token distribution and the uniform distribution. It then reports direct empirical measurements of this quantity under nine categories of semantically neutral prompts, yielding the ~0.30 floor value. The 88-93% figure is obtained by simple ratio of the neutral-prompt ED to the semantic-prompt ED across the same models and temperatures. No equations, parameters, or premises reduce to their own inputs by construction; there are no fitted inputs relabeled as predictions, no self-citation load-bearing uniqueness claims, and no ansatz smuggled via prior work. The derivation remains a set of independent, falsifiable measurements against an external uniform baseline.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math KL divergence is a valid and standard measure of difference between probability distributions
invented entities (1)
-
Entropic Deviation (ED)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
ED(p) = D_KL(p∥u)/log V = 1 - H(p)/log V ... transformers still exhibit ED of approximately 0.30 ... 88-93% of the non-randomness ... intrinsic to the learned weights
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
ED is nonzero everywhere ... p<10^{-6} in all cases ... structural lower bound on randomness
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery / orbit embedding echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Three transformer families converge on nearly identical ED values despite different training data and vocabularies
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Javier Coronado-Bl ´azquez. Deterministic or probabilistic? the psychology of LLMs as random number generators.arXiv preprint arXiv:2502.19965,
-
[2]
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Can LLMs generate random numbers? evaluating LLM sampling in controlled domains
Aspen K Hopkins and Alex Renda. Can LLMs generate random numbers? evaluating LLM sampling in controlled domains. InICML 2023 Workshop on Sampling and Opti- 11 Preprint. Under review. mization in Discrete Space (SODS),
work page 2023
-
[5]
Neural Machine Translation of Rare Words with Subword Units
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units.arXiv preprint arXiv:1508.07909,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Minda Zhao, Yilun Du, and Mengyu Wang. Large language models are bad dice players: LLMs struggle to generate random numbers from statistical distributions.arXiv preprint arXiv:2601.05414,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.