Recognition: unknown
ClawTrace: Cost-Aware Tracing for LLM Agent Skill Distillation
Pith reviewed 2026-05-08 05:59 UTC · model grok-4.3
The pith
Per-step cost tracking in LLM agent traces enables pruning of wasteful steps that cuts costs 32% across benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
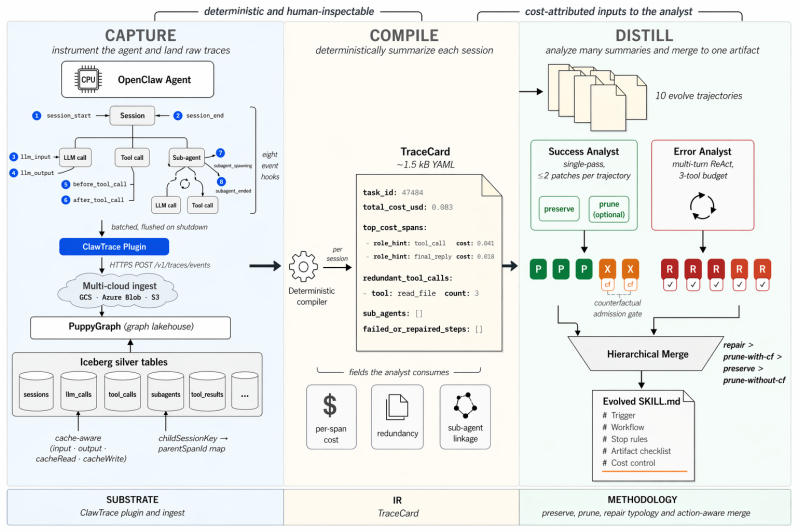
ClawTrace records full agent sessions and compiles them into compact TraceCards with per-step USD costs, token counts, and redundancy flags. CostCraft reads these cards to produce preserve, prune, and repair skill patches, where prune patches are each supported by a counterfactual argument against a named high-cost step. Ablations confirm that both cost attribution and prune patches independently lower quality regressions on 30 held-out SpreadsheetBench tasks; on 30 unrelated SkillsBench tasks the prune rules transfer and cut median cost by 32 percent while preserve rules cause regressions.
What carries the argument
TraceCard, a compact YAML summary of an agent session that attaches per-step USD cost, token counts, and redundancy flags to every LLM call, tool use, and sub-agent spawn, allowing counterfactual identification of non-essential expensive steps.
Load-bearing premise
Per-step costs can be accurately attributed and counterfactual arguments can reliably identify steps that did not affect the outcome without introducing bias or missing context.
What would settle it
Direct measurement of median cost and task success rate on SkillsBench tasks after applying prune patches distilled from SpreadsheetBench traces, compared against a no-prune baseline.
Figures





read the original abstract
Skill-distillation pipelines learn reusable rules from LLM agent trajectories, but they lack a key signal: how much each step costs. Without per-step cost, a pipeline cannot distinguish adding a missing step to fix a bug from removing an expensive step that never affected the outcome. We introduce ClawTrace, an agent tracing platform that records every LLM call, tool use, and sub-agent spawn during an agent session and compiles each session into a TraceCard: a compact YAML summary with per-step USD cost, token counts, and redundancy flags. Built on ClawTrace, CostCraft is a distillation pipeline that reads TraceCards and produces three types of skill patches. Preserve patches keep behaviors that led to success. Prune patches remove expensive steps that did not matter, each backed by a counterfactual argument against a named high-cost step. Repair patches fix failures grounded in oracle evidence. Ablations on 30 held-out SpreadsheetBench tasks show that both cost attribution and prune patches independently reduce quality regressions. When the same skill is applied to 30 unrelated SkillsBench tasks, an unexpected asymmetry emerges: prune rules transferred across benchmarks and cut median cost by 32%, while preserve rules, trained on benchmark-specific conventions, caused regressions on new task types. We release ClawTrace and TraceCards as open infrastructure for cost-aware agent research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ClawTrace, an agent tracing platform that records every LLM call, tool use, and sub-agent spawn, compiling sessions into TraceCards with per-step USD costs, token counts, and redundancy flags. Built on this, CostCraft distills TraceCards into preserve patches (keep successful behaviors), prune patches (remove expensive non-impactful steps via counterfactuals), and repair patches (fix failures with oracle evidence). Ablations on 30 held-out SpreadsheetBench tasks claim independent quality-regression reductions from cost attribution and pruning; cross-application to 30 SkillsBench tasks shows prune rules transfer (32% median cost cut) while preserve rules regress.
Significance. If the empirical claims hold with adequate controls, the work supplies open infrastructure for cost-aware skill distillation in LLM agents, addressing a gap where pipelines cannot distinguish necessary fixes from wasteful steps. The reported asymmetry in cross-benchmark transfer of prune versus preserve rules is a substantive observation that could guide future distillation design. Open release of ClawTrace and TraceCards is a clear strength for reproducibility.
major comments (2)
- [Ablations / Results] Ablations paragraph (abstract and presumed §4/Results): the central claim that cost attribution and prune patches independently reduce quality regressions on 30 held-out SpreadsheetBench tasks lacks any description of experimental setup, baselines, quality metric definition, statistical significance testing, or confound controls. This is load-bearing for the empirical contribution and prevents verification that the data support the stated conclusions.
- [Method / CostCraft] Prune patch description (abstract and presumed §3/Method): the counterfactual arguments used to identify high-cost steps that 'did not affect the outcome' are foundational to the prune mechanism, yet no details are provided on how these counterfactuals are constructed, validated, or protected against bias or missing context. This directly affects the reliability of the reported 32% cost reduction on SkillsBench.
minor comments (2)
- [Abstract] Abstract: the phrase 'compact YAML summary' for TraceCards would be clearer with a short illustrative excerpt or schema in the main text or appendix.
- [Discussion] The cross-benchmark asymmetry is presented as an empirical finding; a brief discussion of possible causes (e.g., benchmark-specific conventions) would improve interpretability without altering the core claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of open infrastructure for cost-aware agent skill distillation. We respond to each major comment below and will update the manuscript with additional details to address the concerns raised.
read point-by-point responses
-
Referee: [Ablations / Results] Ablations paragraph (abstract and presumed §4/Results): the central claim that cost attribution and prune patches independently reduce quality regressions on 30 held-out SpreadsheetBench tasks lacks any description of experimental setup, baselines, quality metric definition, statistical significance testing, or confound controls. This is load-bearing for the empirical contribution and prevents verification that the data support the stated conclusions.
Authors: We agree that the current description of the ablations is insufficient for verification. The manuscript will be revised to include a detailed experimental setup in §4: the 30 held-out tasks are randomly sampled from SpreadsheetBench excluding the training set; baselines include a no-cost-attribution variant and a no-prune variant; quality is measured by success rate regression (drop in task completion); we will add results from statistical tests (paired t-test, p < 0.05 reported); and controls for LLM version and prompt consistency. This will substantiate the independent reductions in quality regressions. revision: yes
-
Referee: [Method / CostCraft] Prune patch description (abstract and presumed §3/Method): the counterfactual arguments used to identify high-cost steps that 'did not affect the outcome' are foundational to the prune mechanism, yet no details are provided on how these counterfactuals are constructed, validated, or protected against bias or missing context. This directly affects the reliability of the reported 32% cost reduction on SkillsBench.
Authors: The details on counterfactual construction are indeed only briefly mentioned. We will expand §3 to describe: construction via step removal and re-execution on the same initial state using TraceCard context; validation through outcome equivalence checks and sample manual inspection; and bias mitigation by full context inclusion and noting limitations of potential missing information in traces. These additions will clarify the basis for the prune patches and the observed 32% cost reduction transfer to SkillsBench. revision: yes
Circularity Check
No significant circularity; empirical ablations are self-contained
full rationale
The paper introduces ClawTrace for per-step cost tracing and CostCraft for generating preserve/prune/repair patches, then reports empirical ablations on held-out SpreadsheetBench tasks and cross-benchmark transfer to SkillsBench. No derivation chain, equations, or first-principles predictions are present that could reduce to fitted inputs or self-definitions. Claims of independent benefits from cost attribution and pruning rest on experimental results rather than any self-referential construction. Self-citations are absent from the load-bearing claims, and the open release of TraceCards enables external verification. This is the standard case of an infrastructure-plus-ablations paper with no circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Per-step costs can be precisely attributed to individual actions in agent trajectories.
- domain assumption Counterfactual arguments can validly determine if a step did not affect the outcome.
Reference graph
Works this paper leans on
-
[1]
Agent skills enable a new class of realistic and trivially simple prompt injections,
David Schmotz, Sahar Abdelnabi, and Maksym Andriushchenko. Agent skills enable a new class of realistic and trivially simple prompt injections, 2025. URLhttps://arxiv.org/abs/2510.26328
-
[2]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Erchao Zhao, Xiaoxi Jiang, and Guanjun Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills, 2026. URL https://arxiv.org/abs/2603.25158
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Hanrong Zhang, Shicheng Fan, Henry Peng Zou, Yankai Chen, Zhenting Wang, Jiayu Zhou, Chengze Li, Wei- Chieh Huang, Yifei Yao, Kening Zheng, Xue Liu, Xiaoxiao Li, and Philip S. Yu. Coevoskills: Self-evolving agent skills via co-evolutionary verification, 2026. URLhttps://arxiv.org/abs/2604.01687
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
arXiv preprint arXiv:2603.01145 , year=
Yutao Yang, Junsong Li, Qianjun Pan, Bihao Zhan, Yuxuan Cai, Lin Du, Jie Zhou, Kai Chen, Qin Chen, Xin Li, Bo Zhang, and Liang He. Autoskill: Experience-driven lifelong learning via skill self-evolution, 2026. URL https://arxiv.org/abs/2603.01145
-
[5]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Binxu Li, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, X...
work page internal anchor Pith review arXiv 2026
-
[6]
Langsmith evaluation, 2024
LangChain. Langsmith evaluation, 2024. URL https://docs.langchain.com/langsmith/evaluation. Accessed: 2026-04-24
2024
-
[7]
Langfuse documentation, 2024
Langfuse. Langfuse documentation, 2024. URLhttps://langfuse.com/docs. Accessed: 2026-04-24
2024
-
[8]
Phoenix documentation: LLM evals, 2024
Arize AI. Phoenix documentation: LLM evals, 2024. URL https://arize.com/docs/phoenix/ evaluation/llm-evals. Accessed: 2026-04-24. 9
2024
-
[9]
Opentelemetry specification, 2024
OpenTelemetry Authors. Opentelemetry specification, 2024. URLhttps://opentelemetry.io/docs/specs/ otel/. Accessed: 2026-04-25
2024
-
[10]
Spreadsheetbench: Towards challenging real world spreadsheet manipulation, 2024
Zeyao Ma, Bohan Zhang, Jing Zhang, Jifan Yu, Xiaokang Zhang, Xiaohan Zhang, Sijia Luo, Xi Wang, and Jie Tang. Spreadsheetbench: Towards challenging real world spreadsheet manipulation, 2024. URL https: //arxiv.org/abs/2406.14991
-
[11]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward, 2026. URLhttps://arxiv.org/abs/2602.12430
work page internal anchor Pith review arXiv 2026
-
[12]
Swe-skills-bench: Do agent skills actually help in real-world software engineering?, 2026
Tingxu Han, Yi Zhang, Wei Song, Chunrong Fang, Zhenyu Chen, Youcheng Sun, and Lijie Hu. Swe-skills-bench: Do agent skills actually help in real-world software engineering?, 2026. URL https://arxiv.org/abs/2603. 15401
2026
-
[13]
Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766, 2026
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. Evoskill: Automated skill discovery for multi-agent systems, 2026. URLhttps://arxiv.org/abs/2603.02766
-
[14]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Boyuan Zheng, Michael Y . Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, and Yu Su. Skillweaver: Web agents can self-improve by discovering and honing skills, 2025. URLhttps://arxiv.org/abs/2504.07079
work page internal anchor Pith review arXiv 2025
-
[15]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models, 2023. URL https: //arxiv.org/abs/2305.16291
work page internal anchor Pith review arXiv 2023
-
[16]
Reflexion: Language agents with verbal reinforcement learning, 2023
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/2303. 11366
2023
-
[17]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T. Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, and Tomas Pfister. Reasoningbank: Scaling agent self-evolving with reasoning memory, 2026. URL https://arxiv.org/abs/2509.25140
work page internal anchor Pith review arXiv 2026
-
[18]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning, 2026. URLhttps://arxiv.org/abs/2602.08234
work page internal anchor Pith review arXiv 2026
-
[19]
Agentops: Enabling observability of llm agents
Liming Dong, Qinghua Lu, and Liming Zhu. Agentops: Enabling observability of llm agents, 2024. URL https://arxiv.org/abs/2411.05285
-
[20]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Lingjiao Chen, Matei Zaharia, and James Zou. Frugalgpt: How to use large language models while reducing cost and improving performance, 2023. URLhttps://arxiv.org/abs/2305.05176
work page internal anchor Pith review arXiv 2023
-
[21]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data, 2025. URL https://arxiv.org/abs/ 2406.18665
work page internal anchor Pith review arXiv 2025
-
[22]
Puppygraph: Query graph on data lakes, 2024
PuppyGraph. Puppygraph: Query graph on data lakes, 2024. URL https://www.puppygraph.com/. Accessed: 2026-04-25
2024
-
[23]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation, 2023. URLhttps://arxiv.org/abs/2308.08155
work page internal anchor Pith review arXiv 2023
-
[24]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. Metagpt: Meta programming for a multi-agent collaborative framework, 2024. URL https: //arxiv.org/abs/2308.00352
work page internal anchor Pith review arXiv 2024
-
[25]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for "mind" exploration of large language model society, 2023. URL https://arxiv. org/abs/2303.17760
work page internal anchor Pith review arXiv 2023
-
[26]
L-mars: Legal multi-agent workflow with orchestrated reasoning and agentic search,
Ziqi Wang and Boqin Yuan. L-mars: Legal multi-agent workflow with orchestrated reasoning and agentic search,
- [27]
-
[28]
When a cell is marked pending, compute it before ending the session
Hamel Husain and Shreya Shankar. LLM evals: Everything you need to know, January 2026. URL https: //hamel.dev/blog/posts/evals-faq/. Accessed: 2026-04-24. 10 Appendix A ClawTrace Platform Demo ClawTrace (https://www.clawtrace.ai/) is an observability and optimization platform for OpenClaw agents. Its goal is to make agents better, cheaper, and faster by g...
2026
-
[29]
Callinspect_mismatchesto identify the failure surface
-
[30]
Trace the failure to a specific agent decision or missing step in the TraceCard
-
[31]
If needed, callread_gold_snippetto confirm the expected output
-
[32]
Output format:JSON with fieldsaction(repair),rule,failure_type,evidence,confidence
Callfinal_patchwith the repair rule grounded in the observed failure and oracle evidence. Output format:JSON with fieldsaction(repair),rule,failure_type,evidence,confidence. Constraint:If you cannot diagnose the failure within 3 tool calls, emit a low-confidence patch. The merge step will deprioritize it. 14 C.3 Merge Operator Prompt Merge Operator System...
-
[33]
Repair patches with causal diagnosis (highest)
-
[34]
Prune patches with a named cost target and counterfactual
-
[35]
Preserve patches that appear in two or more trajectories
-
[36]
sb-task-47484
Singleton preserve patches (drop these). Conflict resolution:When two patches target the same behavior, repair supersedes prune, which supersedes preserve. When two patches of the same type conflict, keep the one with stronger evidence. Output structure:The merged skill must have exactly five sections: 1.Trigger— when the skill applies. 2.Workflow— step-b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.