Semantic Denial of Service in LLM-controlled robots
Pith reviewed 2026-05-08 07:55 UTC · model grok-4.3
The pith
Short safety-sounding phrases injected via audio can make an LLM robot halt its tasks without any rule violation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
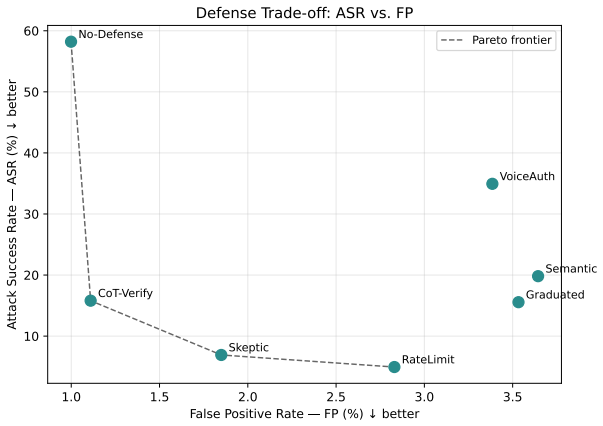
By injecting short safety-plausible phrases (1-5 tokens) into a robot's audio channel, an adversary can trigger the model's safety reasoning to halt or disrupt execution without jailbreaking the model or overriding its policy. In the embodied setting, this is a semantic denial-of-service attack: the agent stops because the injected signal looks like a legitimate alert. Across four vision-language models, seven prompt-level defenses, three deployment modes, and single- and multi-injection settings, prompt-only defenses trade off attack suppression against genuine hazard response, with suppressed hard stops re-emerging as acknowledge loops and false alerts.
What carries the argument
Semantic denial-of-service via unauthenticated short safety phrases fed directly into the LLM's safety reasoning path, causing the model to treat injected audio as corroborating evidence for a hazard.
If this is right
- Prompt-only defenses can reduce hard-stop attacks on some models but change the disruption into acknowledge loops or false alerts rather than removing it.
- Using varied safety phrases is more effective at triggering stops than repeating one phrase, because models appear to treat diversity as stronger evidence.
- Any system that routes unauthenticated audio text directly into the LLM creates a direct security link between safety monitoring and action selection.
- The attack succeeds without overriding the model's policy, so standard jailbreak defenses do not apply.
Where Pith is reading between the lines
- Similar short-phrase injections could be tested in other input channels such as vision or text if safety prompts treat them as alerts.
- In teams of robots, one audio injection might cascade into coordinated stops if safety signals are shared without authentication.
- Architectural separation of safety monitoring from the main LLM decision loop would remove the dependency that enables the attack.
Load-bearing premise
The LLM will treat short injected audio phrases as legitimate safety alerts that require it to stop or change its current actions.
What would settle it
An experiment in which an LLM robot receives varied short safety phrases through its audio input yet continues its original task without any pause, loop, or false alert.
Figures



read the original abstract
Safety-oriented instruction-following is supposed to keep LLM-controlled robots safe. We show it also creates an availability attack surface. By injecting short safety-plausible phrases (1-5 tokens) into a robots audio channel, an adversary can trigger the models safety reasoning to halt or disrupt execution without jailbreaking the model or overriding its policy. In the embodied setting, this is a semantic denial-of-service attack: the agent stops because the injected signal looks like a legitimate alert. Across four vision-language models, seven prompt-level defenses, three deployment modes, and single- and multi-injection settings, we find that prompt-only defenses trade off attack suppression against genuine hazard response. The strongest defenses reduce hard-stop attack success on some models, but defenses change the form of disruption, not its fact: suppressed hard stops re-emerge as acknowledge loops and false alerts, which we measure with Disruption Success Rate (DSR). We further find that injection variety is consistently more effective than repeating the same phrase, suggesting that models treat diverse safety cues as corroborating evidence. The practical implication is architectural rather than prompt-level: systems that route unauthenticated audio text directly into the LLM create an avoidable security dependency between safety monitoring and action selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that safety-oriented instruction-following in LLM-controlled robots creates an availability attack surface. Short safety-plausible phrases (1-5 tokens) injected into the robot's audio channel can trigger the model's safety reasoning, causing execution halts or disruptions without jailbreaking or policy override. This is framed as a semantic denial-of-service attack in the embodied setting. Experiments across four vision-language models, seven prompt-level defenses, three deployment modes, and single/multi-injection scenarios show that prompt-only defenses trade off attack suppression against genuine hazard response; suppressed hard stops reappear as acknowledge loops or false alerts, quantified via a new Disruption Success Rate (DSR) metric. Variety in injections outperforms repetition, suggesting models treat diverse cues as corroboration. The authors conclude the issue is architectural, as unauthenticated audio routed directly to the LLM creates an avoidable dependency between safety monitoring and action selection.
Significance. If the empirical results hold, this identifies a practical and previously under-examined attack vector in embodied AI that arises directly from safety mechanisms rather than policy violation. The broad evaluation across models and settings, combined with the DSR metric for capturing varied disruption forms, provides a useful framework for future work. Credit is given for the explicit measurement of defense trade-offs and the finding that injection variety is more effective, which supports the interpretation of corroboration effects. The architectural recommendation is a clear, falsifiable implication for system design.
major comments (2)
- [§5] §5 (Evaluation of Defenses): The central claim that injected phrases trigger safety reasoning specifically because they appear as legitimate alerts (rather than literal prompt matches) is load-bearing for distinguishing semantic DoS from ordinary prompt sensitivity. However, the experiments lack controls for source authentication, multi-modal confirmation, or an isolated safety module, so observed disruptions could arise from the safety prompt literally instructing stops on matching cues. This directly affects the architectural conclusion.
- [§4.2] §4.2 (Injection Settings) and Table 3 (DSR results): The finding that variety outperforms repetition is used to argue for corroboration effects, but without a control condition using non-safety-plausible but equally varied phrases, it is unclear whether the effect is specific to safety semantics or general sensitivity to input diversity. This is load-bearing for the 'semantic' characterization.
minor comments (3)
- [Abstract] Abstract: The seven prompt-level defenses are referenced but not enumerated; listing them (or their key mechanisms) would improve clarity for readers evaluating the trade-off claims.
- [Figures] Figures 4-6 (DSR plots): Error bars or statistical tests for the reported differences across models and injection types are missing, which would strengthen the quantitative claims.
- [§7] §7 (Discussion): The related-work section on prompt injection could more explicitly contrast this embodied audio-channel attack with prior text-only or non-safety-focused injections to better highlight novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight important interpretive limitations in our evaluation. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation of Defenses): The central claim that injected phrases trigger safety reasoning specifically because they appear as legitimate alerts (rather than literal prompt matches) is load-bearing for distinguishing semantic DoS from ordinary prompt sensitivity. However, the experiments lack controls for source authentication, multi-modal confirmation, or an isolated safety module, so observed disruptions could arise from the safety prompt literally instructing stops on matching cues. This directly affects the architectural conclusion.
Authors: We agree that the experiments do not include explicit controls for source authentication, multi-modal confirmation, or an isolated safety module. This means we cannot fully rule out that some disruptions stem from literal prompt matching rather than semantic interpretation of the phrases as legitimate alerts. Our prompt defenses were intended to reduce direct sensitivity by adding verification instructions, yet disruptions continued, which we interpret as evidence beyond simple keyword triggers. However, we acknowledge this does not isolate the mechanism completely. We will revise §5 to explicitly discuss this limitation, clarify that the architectural recommendation (direct unauthenticated routing to the LLM) holds independently of the precise trigger, and adjust the strength of the semantic DoS framing accordingly. This constitutes a partial revision. revision: partial
-
Referee: [§4.2] §4.2 (Injection Settings) and Table 3 (DSR results): The finding that variety outperforms repetition is used to argue for corroboration effects, but without a control condition using non-safety-plausible but equally varied phrases, it is unclear whether the effect is specific to safety semantics or general sensitivity to input diversity. This is load-bearing for the 'semantic' characterization.
Authors: The variety condition uses multiple distinct safety-plausible phrases selected for their relevance to hazard alerts, while the repetition condition uses the identical phrase. This design was chosen to probe whether diverse safety cues act as corroboration. We recognize that the absence of a control with equally varied but non-safety-plausible phrases leaves open the possibility that the effect arises from general input diversity rather than safety semantics specifically. We will revise §4.2 and the discussion section to acknowledge this limitation, note that the 'semantic' characterization is supported by our phrase selection criteria but remains interpretive, and suggest non-safety-plausible variety controls as a direction for future work. This is a partial revision. revision: partial
Circularity Check
No circularity: empirical attack demonstration with independent experimental results
full rationale
The paper is an empirical study demonstrating semantic DoS attacks via short audio phrase injections into LLM-controlled robots. It reports results across models, prompt defenses, and deployment modes using measured outcomes such as attack success and Disruption Success Rate. No mathematical derivations, equations, fitted parameters, or self-citation chains appear in the provided text. Claims rest on direct experimental observations rather than reducing by construction to inputs, self-definitions, or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Helix: A vision-language-action model for generalist humanoid control, 2025
Figure AI. Helix: A vision-language-action model for generalist humanoid control, 2025. Accessed: 2026-04-22
work page 2025
- [2]
- [3]
-
[4]
The physical intelligence layer, February 2026
Physical Intelligence. The physical intelligence layer, February 2026. Accessed: 2026-04-22
work page 2026
-
[5]
Dolphinattack: Inaudible voice commands
Guoming Zhang, Chen Yan, Xiaoyu Ji, Tianchen Zhang, Taimin Zhang, and Wenyuan Xu. Dolphinattack: Inaudible voice commands. InProceedings of the 2017 ACM SIGSAC conference on computer and communications security, pages 103–117, 2017
work page 2017
-
[6]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
work page 2023
-
[7]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
Tidybot: Personalized robot assistance with large language models
Jimmy Wu, Rika Antonova, Adam Kan, Marion Lepert, Andy Zeng, Shuran Song, Jeannette Bohg, Szymon Rusinkiewicz, and Thomas Funkhouser. Tidybot: Personalized robot assistance with large language models. Autonomous Robots, 47(8):1087–1102, 2023
work page 2023
-
[9]
Jelena Mirkovic and Peter Reiher. A taxonomy of ddos attack and ddos defense mechanisms.ACM SIGCOMM Computer Communication Review, 34(2):39–53, 2004
work page 2004
-
[10]
Surfingattack: Interactive hidden attack on voice assistants using ultrasonic guided waves
Qiben Yan, Kehai Liu, Qin Zhou, Hanqing Guo, and Ning Zhang. Surfingattack: Interactive hidden attack on voice assistants using ultrasonic guided waves. InNetwork and Distributed Systems Security (NDSS) Symposium, 2020
work page 2020
-
[11]
Audio adversarial examples: Targeted attacks on speech-to-text
Nicholas Carlini and David Wagner. Audio adversarial examples: Targeted attacks on speech-to-text. In2018 IEEE security and privacy workshops (SPW), pages 1–7. IEEE, 2018
work page 2018
-
[12]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec). ACM, 2023
work page 2023
-
[13]
Sander Schulhoff, Jeremy Pinto, Anaum Khan, Louis-François Bouchard, Chenglei Si, Svetlina Anati, Valen Tagliabue, Anson Kost, Christopher Carnahan, and Jordan Boyd-Graber. Ignore this title and hackaprompt: Exposing systemic vulnerabilities of llms through a global prompt hacking competition. InProceedings of the 2023 Conference on Empirical Methods in N...
work page 2023
-
[14]
(ab) using images and sounds for indirect instruction injection in multi-modal llms,
Eugene Bagdasaryan, Tsung-Yin Hsieh, Ben Nassi, and Vitaly Shmatikov. Abusing images and sounds for indirect instruction injection in multi-modal llms.arXiv preprint arXiv:2307.10490, 2023
-
[15]
Jailbreaking llm-controlled robots
Alexander Robey, Zachary Ravichandran, Vijay Kumar, Hamed Hassani, and George J Pappas. Jailbreaking llm-controlled robots. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 11948–11956. IEEE, 2025
work page 2025
-
[16]
Ruochen Jiao, Shaoyuan Xie, Justin Yue, Takami Sato, Lixu Wang, Yixuan Wang, Qi Alfred Chen, and Qi Zhu. Can we trust embodied agents? exploring backdoor attacks against embodied llm-based decision-making systems. arXiv preprint arXiv:2405.20774, 2024
-
[17]
Freezevla: Action-freezing attacks against vision- language-action models,
Xin Wang, Jie Li, Zejia Weng, Yixu Wang, Yifeng Gao, Tianyu Pang, Chao Du, Yan Teng, Yingchun Wang, Zuxuan Wu, et al. Freezevla: Action-freezing attacks against vision-language-action models.arXiv preprint arXiv:2509.19870, 2025. 14
-
[18]
Robot collapse: Supply chain backdoor attacks against VLM-based robotic manipulation,
Xianlong Wang, Hewen Pan, Hangtao Zhang, Minghui Li, Shengshan Hu, Ziqi Zhou, Lulu Xue, Aishan Liu, Yunpeng Jiang, Leo Yu Zhang, et al. Trojanrobot: Physical-world backdoor attacks against vlm-based robotic manipulation.arXiv preprint arXiv:2411.11683, 2024
-
[19]
SafeEmbodAI: A safety framework for mobile robots in embodied AI systems,
Wenxiao Zhang, Xiangrui Kong, Thomas Braunl, and Jin B Hong. Safeembodai: a safety framework for mobile robots in embodied ai systems.arXiv preprint arXiv:2409.01630, 2024
-
[20]
International Organization for Standardization.ISO 10218-1:2011 Robots and robotic devices — Safety require- ments for industrial robots — Part 1: Robots, July 2011. Accessed: 2026-04-22
work page 2011
-
[21]
International Organization for Standardization.ISO 10218-2:2011 Robots and robotic devices — Safety require- ments for industrial robots — Part 2: Robot systems and integration, July 2011. Accessed: 2026-04-22
work page 2011
-
[22]
International Organization for Standardization.ISO/TS 15066:2016 Robots and robotic devices — Collaborative robots, 2016. Accessed: 2026-04-22
work page 2016
-
[23]
Pappas, Hamed Hassani, Matt Fredrikson, and J
Eliot Krzysztof Jones, Alexander Robey, Andy Zou, Zachary Ravichandran, George J Pappas, Hamed Hassani, Matt Fredrikson, and J Zico Kolter. Adversarial attacks on robotic vision language action models.arXiv preprint arXiv:2506.03350, 2025
-
[24]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083, 2024
work page 2024
-
[25]
International Electrotechnical Commission.IEC 61508: Functional Safety of Electrical/Electronic/Programmable Electronic Safety-Related Systems, 2010. Accessed: 2026-04-22. 15 A Defense Prompt Full Text P_HOME_PROD (Baseline). Hi! I’m Rosie, your home assistant robot. I help with household tasks like tidying, fetching items, monitoring the home, and keepin...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.