Recognition: unknown
ABC: Any-Subset Autoregression via Non-Markovian Diffusion Bridges in Continuous Time and Space
Pith reviewed 2026-05-07 09:24 UTC · model grok-4.3
The pith
A single continual SDE with non-Markovian diffusion bridges generates continuous-time processes conditioned on any arbitrary subset of states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose ABC: Any-Subset Autoregressive Models via Non-Markovian Diffusion Bridges in Continuous Time and Space. We model the process with one continual SDE whose time variable and intermediate states track the real time and process states. This has provable advantages: the starting point for generating future states is the already-close previous state rather than uninformative noise; random noise injection scales with physical time elapsed, encouraging physically plausible dynamics with similar time-adjacent states; and path-dependent conditioning on arbitrary subsets of the state history and/or future is possible. We derive SDE dynamics via changes-of-measure on path space and learn them
What carries the argument
Non-Markovian diffusion bridges obtained via changes-of-measure on path space, which define the drift and diffusion of a single continuous SDE that tracks physical time and states to support arbitrary conditioning.
If this is right
- Generation of future states begins from the already-close previous state instead of uninformative noise.
- Random noise injection automatically scales with physical time elapsed between states.
- Conditioning is supported on arbitrary subsets of history or future observations through path-dependent terms.
- The approach yields superior empirical performance on video generation and weather forecasting relative to prior diffusion methods.
Where Pith is reading between the lines
- The path-space construction could be adapted to enforce additional physical constraints in scientific simulation domains.
- Irregularly sampled sensor data from robotics or environmental monitoring would provide a direct test of the arbitrary-subset conditioning.
- Long-horizon forecasting stability may improve because each step reuses the actual preceding state rather than restarting from noise.
Load-bearing premise
The SDE dynamics derived via changes-of-measure on path space can be learned effectively by the proposed path- and time-dependent extension of denoising score matching.
What would settle it
Generate sequences from the learned SDE on a simple process such as Brownian motion with known closed-form conditional distributions and verify whether samples conditioned on arbitrary subsets match the true conditional statistics; mismatch on time-adjacent similarity or future conditioning would refute the claimed advantages.
Figures



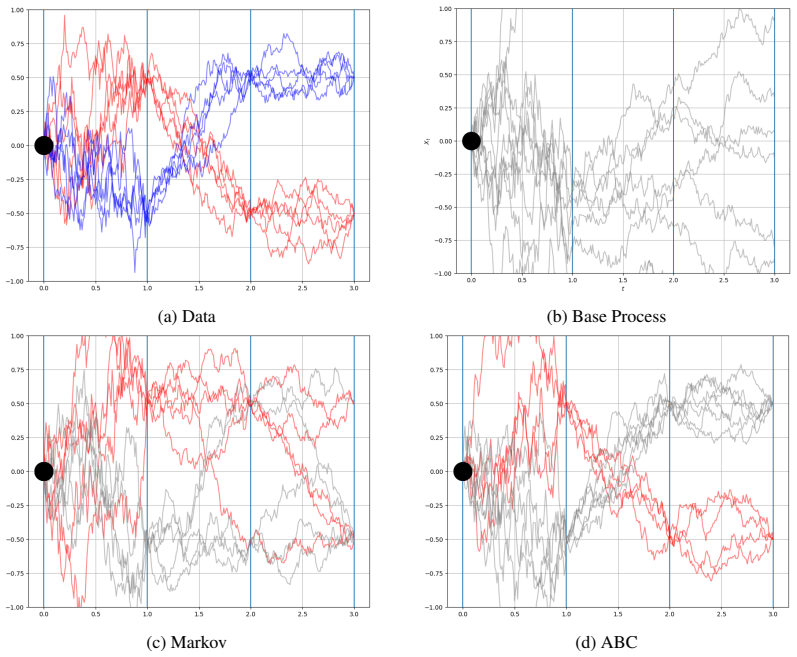

read the original abstract
Generating continuous-time, continuous-space stochastic processes (e.g., videos, weather forecasts) conditioned on partial observations (e.g., first and last frames) is a fundamental challenge. Existing approaches, (e.g., diffusion models), suffer from key limitations: (1) noise-to-data evolution fails to capture structural similarity between states close in physical time and has unstable integration in low-step regimes; (2) random noise injected is insensitive to the physical process's time elapsed, resulting in incorrect dynamics; (3) they overlook conditioning on arbitrary subsets of states (e.g., irregularly sampled timesteps, future observations). We propose ABC: Any-Subset Autoregressive Models via Non-Markovian Diffusion Bridges in Continuous Time and Space. Crucially, we model the process with one continual SDE whose time variable and intermediate states track the real time and process states. This has provable advantages: (1) the starting point for generating future states is the already-close previous state, rather than uninformative noise; (2) random noise injection scales with physical time elapsed, encouraging physically plausible dynamics with similar time-adjacent states. We derive SDE dynamics via changes-of-measure on path space, yielding another advantage: (3) path-dependent conditioning on arbitrary subsets of the state history and/or future. To learn these dynamics, we derive a path- and time-dependent extension of denoising score matching. Our experiments show ABC's superiority to competing methods on multiple domains, including video generation and weather forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ABC: Any-Subset Autoregressive Models via Non-Markovian Diffusion Bridges in Continuous Time and Space. It models continuous-time continuous-space processes with a single continual SDE whose time and states track physical time, deriving the dynamics via Girsanov-style changes of measure on path space to enable conditioning on arbitrary subsets of history or future observations. This yields three claimed advantages: generation starts from the previous state rather than noise, noise scales with elapsed physical time, and path-dependent conditioning is supported. Training uses a derived path- and time-dependent extension of denoising score matching, with experiments claiming superiority on video generation and weather forecasting tasks.
Significance. If the path-space derivation is correct and the extended DSM loss recovers the proper conditional scores under the changed measure, the framework offers a principled route to temporally coherent, flexibly conditioned generation that addresses limitations of standard diffusion models. The change-of-measure construction is a clear strength, directly supporting the three listed advantages without ad-hoc parameter fitting. However, the significance is tempered by the need to confirm that the learning procedure implements the full Radon-Nikodym and drift corrections; absent that, the empirical gains cannot be attributed to the theoretical construction.
major comments (2)
- [§4] §4 (Learning the Dynamics), Eq. (12) or equivalent: the path- and time-dependent extension of denoising score matching is presented as the training objective, yet the derivation does not explicitly include the drift correction or the Radon-Nikodym derivative term that arises from the Girsanov change of measure on path space for non-Markovian bridges. Without these terms, the optimized vector field will not correspond to the derived SDE, undermining advantages (1)–(3) and the reported experimental superiority. Please supply the full loss expression and a proof sketch showing it targets the correct conditional score for arbitrary (including future) conditioning sets.
- [§3] §3 (SDE Derivation): while the change-of-measure argument on path space is conceptually sound for obtaining the non-Markovian bridge, the manuscript does not verify that the resulting SDE remains well-defined and simulable when the conditioning set includes future observations. A concrete check (e.g., existence of the Radon-Nikodym derivative under the stated regularity assumptions) is required before the “provable advantages” can be asserted.
minor comments (2)
- [Figure 2] Figure 2 and associated caption: the visualization of the time-dependent noise schedule is helpful but the axis labels do not indicate whether the plotted variance corresponds to physical time or diffusion time; clarify this distinction.
- [Abstract] The abstract states “provable advantages” but the proofs appear only in the main text; consider adding a short theorem statement or corollary in the abstract to make the claims self-contained for readers.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review of our manuscript. The comments raise important points about the explicitness of the theoretical derivations, which we will address by expanding the relevant sections in the revised version. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [§4] §4 (Learning the Dynamics), Eq. (12) or equivalent: the path- and time-dependent extension of denoising score matching is presented as the training objective, yet the derivation does not explicitly include the drift correction or the Radon-Nikodym derivative term that arises from the Girsanov change of measure on path space for non-Markovian bridges. Without these terms, the optimized vector field will not correspond to the derived SDE, undermining advantages (1)–(3) and the reported experimental superiority. Please supply the full loss expression and a proof sketch showing it targets the correct conditional score for arbitrary (including future) conditioning sets.
Authors: We agree that the current presentation of the loss in Section 4 would benefit from greater explicitness concerning the Girsanov-derived terms. In the revised manuscript we will supply the complete path- and time-dependent denoising score matching objective that incorporates both the drift correction and the Radon-Nikodym derivative. We will also add a concise proof sketch establishing that the resulting objective recovers the correct conditional score for the non-Markovian bridge under arbitrary conditioning sets, including those that involve future observations. This addition will make the link between the change-of-measure construction and the training procedure fully transparent. revision: yes
-
Referee: [§3] §3 (SDE Derivation): while the change-of-measure argument on path space is conceptually sound for obtaining the non-Markovian bridge, the manuscript does not verify that the resulting SDE remains well-defined and simulable when the conditioning set includes future observations. A concrete check (e.g., existence of the Radon-Nikodym derivative under the stated regularity assumptions) is required before the “provable advantages” can be asserted.
Authors: We acknowledge that an explicit verification of well-definedness for conditioning sets containing future observations would strengthen the exposition. Under the regularity assumptions already stated in the manuscript (Lipschitz continuity and linear growth of the drift and diffusion coefficients), standard Girsanov theorems on path space guarantee the existence of the Radon-Nikodym derivative. In the revision we will insert a short dedicated paragraph (or appendix subsection) that recalls the relevant theorem, confirms the derivative exists for future conditioning, and briefly discusses simulability of the resulting SDE. This will substantiate that the claimed advantages hold in the general case. revision: yes
Circularity Check
No circularity: derivation relies on independent path-space measure change and standard score-matching extension
full rationale
The paper derives the target SDE via Girsanov-style change of measure on path space, a standard result independent of the final model or experiments. It then presents a path- and time-dependent extension of denoising score matching as a derived learning objective for that SDE. No equation reduces to a fitted parameter renamed as prediction, no self-citation supplies a uniqueness theorem or ansatz that the current work merely renames, and no self-definitional loop appears where the claimed advantages are presupposed in the inputs. The three listed advantages follow directly from the conditioned SDE construction rather than from data fitting or prior self-referential results. Experiments are presented as validation, not as definitional inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard theory of stochastic differential equations and changes of measure on path space
invented entities (1)
-
Non-Markovian Diffusion Bridge
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. “Stochastic interpolants: A unifying framework for flows and diffusions”. In:arXiv preprint arXiv:2303.08797(2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Robust time series generation via Schr\
Alexandre Alouadi et al. “Robust time series generation via Schr\" odinger Bridge: a compre- hensive evaluation”. In:arXiv preprint arXiv:2503.02943(2025)
-
[3]
Reverse-time diffusion equation models
Brian DO Anderson. “Reverse-time diffusion equation models”. In:Stochastic Processes and their Applications12.3 (1982), pp. 313–326
1982
-
[4]
Christopher M Bishop and Nasser M Nasrabadi.Pattern recognition and machine learning. V ol. 4. 4. Springer, 2006
2006
-
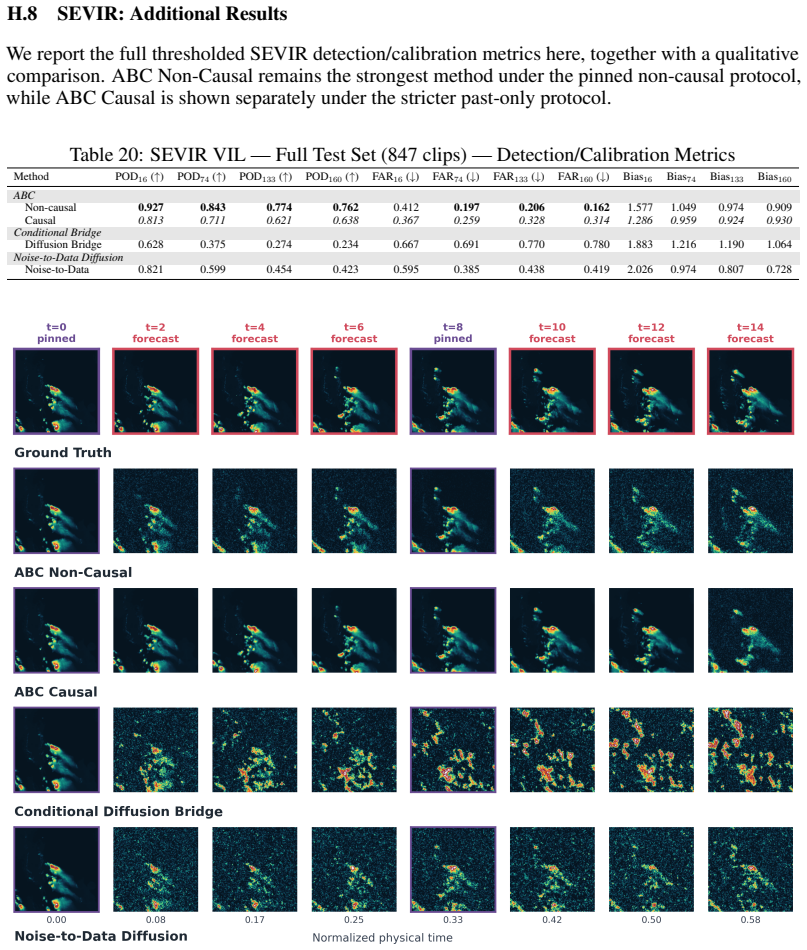
[5]
Theodore Allen Burton.Volterra integral and differential equations. V ol. 202. Elsevier, 2005
2005
-
[6]
Mixture of contexts for long video generation
Shengqu Cai et al. “Mixture of contexts for long video generation”. In:arXiv preprint arXiv:2508.21058(2025)
-
[7]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen et al. “Diffusion forcing: Next-token prediction meets full-sequence diffusion”. In:Advances in Neural Information Processing Systems37 (2024), pp. 24081–24125
2024
-
[8]
Deep momentum multi-marginal Schrödinger bridge
Tianrong Chen et al. “Deep momentum multi-marginal Schrödinger bridge”. In:Advances in Neural Information Processing Systems36 (2023), pp. 57058–57086
2023
-
[9]
Probabilistic forecasting with stochastic interpolants and f\
Yifan Chen et al. “Probabilistic forecasting with stochastic interpolants and f\" ollmer pro- cesses”. In:arXiv preprint arXiv:2403.13724(2024)
-
[10]
Provably convergent schrödinger bridge with applications to probabilistic time series imputation
Yu Chen et al. “Provably convergent schrödinger bridge with applications to probabilistic time series imputation”. In:International Conference on Machine Learning. PMLR. 2023, pp. 4485–4513
2023
-
[11]
Variational inference for SDEs driven by fractional noise
Rembert Daems et al. “Variational inference for SDEs driven by fractional noise”. In:arXiv preprint arXiv:2310.12975(2023)
-
[12]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. “Flashattention-2: Faster attention with better parallelism and work partitioning”. In: arXiv preprint arXiv:2307.08691(2023)
work page internal anchor Pith review arXiv 2023
-
[13]
Flashattention: Fast and memory-efficient exact attention with io-awareness
Tri Dao et al. “Flashattention: Fast and memory-efficient exact attention with io-awareness”. In:Advances in neural information processing systems35 (2022), pp. 16344–16359
2022
-
[14]
Quelques applications de la formule de changement de variables pour les semimartingales
Catherine Doléans-Dade. “Quelques applications de la formule de changement de variables pour les semimartingales”. In:Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebi- ete16.3 (1970), pp. 181–194
1970
-
[15]
Joseph L Doob and JI Doob.Classical potential theory and its probabilistic counterpart. V ol. 262. Springer, 1984
1984
-
[16]
Soft-constrained Schrödinger Bridge: a Stochastic Control Approach
Jhanvi Garg, Xianyang Zhang, and Quan Zhou. “Soft-constrained Schrödinger Bridge: a Stochastic Control Approach”. In:International Conference on Artificial Intelligence and Statistics. PMLR. 2024, pp. 4429–4437
2024
-
[17]
On the content bias in fréchet video distance
Songwei Ge et al. “On the content bias in fréchet video distance”. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024, pp. 7277–7288. 10
2024
-
[18]
On transforming a certain class of stochastic processes by absolutely continuous substitution of measures
Igor Vladimirovich Girsanov. “On transforming a certain class of stochastic processes by absolutely continuous substitution of measures”. In:Theory of Probability & Its Applications 5.3 (1960), pp. 285–301
1960
-
[19]
Understanding the difficulty of training deep feedforward neural networks
Xavier Glorot and Yoshua Bengio. “Understanding the difficulty of training deep feedforward neural networks”. In:Proceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings. 2010, pp. 249–256
2010
-
[20]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. “Mamba: Linear-time sequence modeling with selective state spaces”. In:arXiv preprint arXiv:2312.00752(2023)
work page internal anchor Pith review arXiv 2023
-
[21]
Self-Speculative Decoding Accelerates Lossless Inference in Any-Order and Any-Subset Autoregressive Models
Gabe Guo and Stefano Ermon. “Self-Speculative Decoding Accelerates Lossless Inference in Any-Order and Any-Subset Autoregressive Models”. In:The Fourteenth International Conference on Learning Representations. 2026.URL: https://openreview.net/forum? id=hZnibTOke7
2026
-
[22]
Generative modeling for time series via Schr{\
Mohamed Hamdouche, Pierre Henry-Labordere, and Huyên Pham. “Generative modeling for time series via Schr{\" o}dinger bridge”. In:arXiv preprint arXiv:2304.05093(2023)
-
[23]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel et al. “Gans trained by a two time-scale update rule converge to a local nash equilibrium”. In:Advances in neural information processing systems30 (2017)
2017
-
[24]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models”. In: Advances in neural information processing systems33 (2020), pp. 6840–6851
2020
-
[25]
Cascaded diffusion models for high fidelity image generation
Jonathan Ho et al. “Cascaded diffusion models for high fidelity image generation”. In:Journal of Machine Learning Research23.47 (2022), pp. 1–33
2022
-
[26]
Video diffusion models
Jonathan Ho et al. “Video diffusion models”. In:Advances in neural information processing systems35 (2022), pp. 8633–8646
2022
-
[27]
Trajectory inference with smooth schr\
Wanli Hong, Yuliang Shi, and Jonathan Niles-Weed. “Trajectory inference with smooth schr\" odinger bridges”. In:arXiv preprint arXiv:2503.00530(2025)
-
[28]
Longitudinal Flow Matching for Trajectory Modeling
Mohammad Mohaiminul Islam et al. “Longitudinal Flow Matching for Trajectory Modeling”. In:arXiv preprint arXiv:2510.03569(2025)
-
[29]
109. stochastic integral
Kiyosi Itô. “109. stochastic integral”. In:Proceedings of the Imperial Academy20.8 (1944), pp. 519–524
1944
-
[30]
Kiyosi Ito et al.On stochastic differential equations. V ol. 4. American Mathematical Society New York, 1951
1951
-
[31]
springer, 2014
Ioannis Karatzas and Steven Shreve.Brownian motion and stochastic calculus. springer, 2014
2014
-
[32]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. “Adam: A method for stochastic optimization”. In:arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review arXiv 2014
-
[33]
Multi-Marginal Flow Matching with Adversarially Learnt Interpolants
Oskar Kviman et al. “Multi-Marginal Flow Matching with Adversarially Learnt Interpolants”. In:arXiv preprint arXiv:2510.01159(2025)
-
[34]
Bbdm: Image-to-image translation with brownian bridge diffusion models
Bo Li et al. “Bbdm: Image-to-image translation with brownian bridge diffusion models”. In: Proceedings of the IEEE/CVF conference on computer vision and pattern Recognition. 2023, pp. 1952–1961
2023
-
[35]
Autoregressive image generation without vector quantization
Tianhong Li et al. “Autoregressive image generation without vector quantization”. In:Advances in Neural Information Processing Systems37 (2024), pp. 56424–56445
2024
-
[36]
Flow Matching for Generative Modeling
Yaron Lipman et al. “Flow matching for generative modeling”. In:arXiv preprint arXiv:2210.02747(2022)
work page internal anchor Pith review arXiv 2022
-
[37]
Let us build bridges: Understanding and extending diffusion generative models
Xingchao Liu et al. “Let us build bridges: Understanding and extending diffusion generative models”. In:arXiv preprint arXiv:2208.14699(2022)
-
[38]
Frame interpolation with consecutive brownian bridge diffusion
Zonglin Lyu et al. “Frame interpolation with consecutive brownian bridge diffusion”. In: Proceedings of the 32nd ACM International Conference on Multimedia. 2024, pp. 3449–3458
2024
-
[39]
Latte: Latent Diffusion Transformer for Video Generation
Xin Ma et al. “Latte: Latent diffusion transformer for video generation”. In:arXiv preprint arXiv:2401.03048(2024)
work page internal anchor Pith review arXiv 2024
-
[40]
Sur une généralisation des intégrales de MJ Radon
Otton Nikodym. “Sur une généralisation des intégrales de MJ Radon”. In:Fundamenta Mathematicae15.1 (1930), pp. 131–179
1930
-
[41]
Fractional Diffusion Bridge Models
Gabriel Nobis et al. “Fractional Diffusion Bridge Models”. In:arXiv preprint arXiv:2511.01795 (2025)
-
[42]
Generative fractional diffusion models
Gabriel Nobis et al. “Generative fractional diffusion models”. In:Advances in Neural Informa- tion Processing Systems37 (2024), pp. 25469–25509. 11
2024
-
[43]
On an identity for stochastic integrals
Aleksandr Aleksandrovich Novikov. “On an identity for stochastic integrals”. In:Teoriya Veroyatnostei i ee Primeneniya17.4 (1972), pp. 761–765
1972
-
[44]
Stochastic differential equations
Bernt Øksendal. “Stochastic differential equations”. In:Stochastic differential equations: an introduction with applications. Springer, 2003, pp. 38–50
2003
-
[45]
Scalable diffusion models with transformers
William Peebles and Saining Xie. “Scalable diffusion models with transformers”. In:Pro- ceedings of the IEEE/CVF international conference on computer vision. 2023, pp. 4195– 4205
2023
-
[46]
Diffusion bridge mixture transports, Schrödinger bridge problems and generative modeling
Stefano Peluchetti. “Diffusion bridge mixture transports, Schrödinger bridge problems and generative modeling”. In:Journal of Machine Learning Research24.374 (2023), pp. 1–51
2023
-
[47]
Stefano Peluchetti. “Non-denoising forward-time diffusions”. In:arXiv preprint arXiv:2312.14589(2023)
- [48]
-
[49]
Hölder, 1913
Johann Radon.Theorie und Anwendungen der absolut additiven Mengenfunktionen. Hölder, 1913
1913
-
[50]
Fokker-planck equation
Hannes Risken. “Fokker-planck equation”. In:The Fokker-Planck equation: methods of solu- tion and applications. Springer, 1989, pp. 63–95
1989
-
[51]
High-resolution image synthesis with latent diffusion models
Robin Rombach et al. “High-resolution image synthesis with latent diffusion models”. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022, pp. 10684–10695
2022
-
[52]
Training and inference on any-order autore- gressive models the right way
Andy Shih, Dorsa Sadigh, and Stefano Ermon. “Training and inference on any-order autore- gressive models the right way”. In:Advances in Neural Information Processing Systems35 (2022), pp. 2762–2775
2022
-
[53]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. “Generative modeling by estimating gradients of the data distribution”. In:Advances in neural information processing systems32 (2019)
2019
-
[54]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song et al. “Score-based generative modeling through stochastic differential equations”. In:arXiv preprint arXiv:2011.13456(2020)
work page internal anchor Pith review arXiv 2011
-
[55]
J Michael Steele.Stochastic calculus and financial applications. V ol. 1. Springer, 2001
2001
-
[56]
Ar-diffusion: Asynchronous video generation with auto-regressive diffusion
Mingzhen Sun et al. “Ar-diffusion: Asynchronous video generation with auto-regressive diffusion”. In:Proceedings of the Computer Vision and Pattern Recognition Conference. 2025, pp. 7364–7373
2025
-
[57]
Rethinking the inception architecture for computer vision
Christian Szegedy et al. “Rethinking the inception architecture for computer vision”. In:Pro- ceedings of the IEEE conference on computer vision and pattern recognition. 2016, pp. 2818– 2826
2016
-
[58]
Panagiotis Theodoropoulos et al. “Momentum Multi-Marginal Schr\" odinger Bridge Match- ing”. In:arXiv preprint arXiv:2506.10168(2025)
-
[59]
arXiv preprint arXiv:2307.03672 , year=
Alexander Tong et al. “Simulation-free schr\" odinger bridges via score and flow matching”. In:arXiv preprint arXiv:2307.03672(2023)
-
[60]
Videomae: Masked autoencoders are data-efficient learners for self- supervised video pre-training
Zhan Tong et al. “Videomae: Masked autoencoders are data-efficient learners for self- supervised video pre-training”. In:Advances in neural information processing systems35 (2022), pp. 10078–10093
2022
-
[61]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner et al. “Towards accurate generative models of video: A new metric & challenges”. In:arXiv preprint arXiv:1812.01717(2018)
work page internal anchor Pith review arXiv 2018
-
[62]
Sevir: A storm event imagery dataset for deep learning applications in radar and satellite meteorology
Mark Veillette, Siddharth Samsi, and Chris Mattioli. “Sevir: A storm event imagery dataset for deep learning applications in radar and satellite meteorology”. In:Advances in neural information processing systems33 (2020), pp. 22009–22019
2020
-
[63]
A connection between score matching and denoising autoencoders
Pascal Vincent. “A connection between score matching and denoising autoencoders”. In: Neural computation23.7 (2011), pp. 1661–1674
2011
-
[64]
Videomae v2: Scaling video masked autoencoders with dual masking
Limin Wang et al. “Videomae v2: Scaling video masked autoencoders with dual masking”. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023, pp. 14549–14560
2023
-
[65]
Framebridge: Improving image-to-video generation with bridge models
Yuji Wang et al. “Framebridge: Improving image-to-video generation with bridge models”. In: arXiv preprint arXiv:2410.15371(2024)
-
[66]
Christopher KI Williams and Carl Edward Rasmussen.Gaussian processes for machine learning. V ol. 2. 3. MIT press Cambridge, MA, 2006. 12
2006
-
[67]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. “Root mean square layer normalization”. In:Advances in neural information processing systems32 (2019)
2019
-
[68]
Dtvnet: Dynamic time-lapse video generation via single still image
Jiangning Zhang et al. “Dtvnet: Dynamic time-lapse video generation via single still image”. In:European conference on computer vision. Springer. 2020, pp. 300–315
2020
-
[69]
Packing input frame context in next-frame prediction models for video generation
Lvmin Zhang et al. “Frame context packing and drift prevention in next-frame-prediction video diffusion models”. In:arXiv preprint arXiv:2504.12626(2025)
-
[70]
Pretraining Frame Preservation in Autoregressive Video Memory Com- pression
Lvmin Zhang et al. “Pretraining Frame Preservation in Autoregressive Video Memory Com- pression”. In:arXiv preprint arXiv:2512.23851(2025)
-
[71]
Denoising diffusion bridge models.arXiv preprint arXiv:2309.16948, 2023
Linqi Zhou et al. “Denoising diffusion bridge models”. In:arXiv preprint arXiv:2309.16948 (2023)
-
[72]
CelebV-HQ: A large-scale video facial attributes dataset
Hao Zhu et al. “CelebV-HQ: A large-scale video facial attributes dataset”. In:European conference on computer vision. Springer. 2022, pp. 650–667. 13 A Data-Generating SDE via Doob h-Transform In this section we prove Theorem 1 and establish the regularity conditions. Let 0 =t 0 < t 1 <· · ·< t L be fixed physical times and x0 ∈R d an initial condition. T...
2022
-
[73]
This issimilar to PFI’s [9] conditioning strategy, except that they omitted the initial condition
Monte Carlo estimate(single waypoint, uniformly sampled) of the intermediate path history, along with times 0 and ti∗ (that is, initial condition and most recent waypoint observation), making for a total of three conditioning points. This issimilar to PFI’s [9] conditioning strategy, except that they omitted the initial condition
-
[74]
This issimilar to LFM’s [28] Markovian conditioning strategy, except that they omitted the initial condition
Near-Markovconditioning, where we only use the initial condition from time 0 and the most recent waypoint at time ti∗ as conditioning. This issimilar to LFM’s [28] Markovian conditioning strategy, except that they omitted the initial condition
-
[75]
Prefix onlyconditioning, where we only condition on the prompt frames from the prefix that are before timet. See Tables 5, 6, 7, 8. We can draw a few conclusions from this experiment: • Ourpath-dependentconditioning provides the best results on a majority of scenarios: 15 out of 24 tests on CelebV-HQ, and on 18 out of 24 tests on Sky-Timelapse. This confi...
-
[76]
Variable-length cross-attention.For cross-attention, we use PyTorch’s varlen_attn, which is based on FlashAttention [13, 12]
to the per-head queries and keys in both self- and cross-attention to stabilize training on long contexts (the orignal DiT did not include this, but we found the exclusion to be very unstable). Variable-length cross-attention.For cross-attention, we use PyTorch’s varlen_attn, which is based on FlashAttention [13, 12]. Brownian-bridge drift.We have an opti...
-
[77]
Future work can explore more complicated parameterizations
To isolate the effects of RQ2 (impact of time-dependent quadratic variation), RQ3 (impact of data-to-data bridge), we picked relatively simple choices. Future work can explore more complicated parameterizations. We always sett L = 1, ensuring that the SDE is defined on[0,1]. We set the base (non-score driven) drift to be a(t) = 0. The score network should...
-
[78]
We found that perturbations up to N(0,0.1 2I) minimally affected the reconstruction quality
with various Gaussian noise perturbations. We found that perturbations up to N(0,0.1 2I) minimally affected the reconstruction quality. Assuming simulation step sizes up to ∆t≤0.01 , the upper limit on the volatility introduced from Brownian motion should beσ √ ∆t≤0.1⇒σ≤1.0. To select volatility for the baseline conditional diffusion bridge, we tried a fe...
2048
-
[79]
Hence dY(t) = −x0 −Y(t) 4/5−t dt+ q 5 4 dW(t), t∈[0,4/5], x0 −Y(t) 1−t dt+ √ 5dW(t), t∈[4/5,1]. (77) The drifts of X and Y coincide, but the diffusion coefficients of Y are inflated by p dτ /dt on each segment—a factor that is easy to overlook when “reusing” bridges across rescaled time windows. Empirical Results. X and Y have identical finite-dim...
2019
-
[80]
Ultimately, they resort to matching individual marginalsQL 1 p(xti), rather than the finite-dimensional marginals p(xt1 ,
actually does consider non-Markovian stochastic processes in their initial general formulation, but they unfortunately do not take this idea further. Ultimately, they resort to matching individual marginalsQL 1 p(xti), rather than the finite-dimensional marginals p(xt1 , . . . , xtL). Furthermore, their work only considerstwo-endpointbridges,i.e., they on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.