Recognition: 2 theorem links
· Lean TheoremPersistent Visual Memory: Sustaining Perception for Deep Generation in LVLMs
Pith reviewed 2026-05-11 01:45 UTC · model grok-4.3
The pith
Persistent Visual Memory adds a parallel branch to LVLMs that supplies visual embeddings independently of text length.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
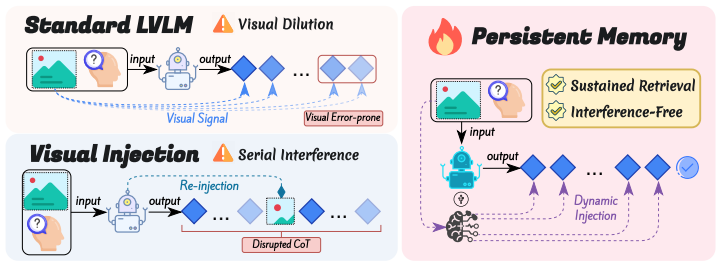
PVM establishes a distance-agnostic retrieval pathway that directly provides visual embeddings for enhanced visual perception, thereby structurally mitigating the signal suppression inherent to deep generation.
What carries the argument
Persistent Visual Memory, a lightweight learnable parallel branch to the FFN that supplies visual embeddings without dependence on sequence position.
Load-bearing premise
Inserting the PVM branch next to the FFN will not disturb the model's existing attention patterns or demand heavy retraining to deliver the reported gains.
What would settle it
Running the same long-sequence visual reasoning benchmarks after adding PVM and finding no accuracy increase or worse performance would falsify the central claim.
Figures





read the original abstract
While autoregressive Large Vision-Language Models (LVLMs) demonstrate remarkable proficiency in multimodal tasks, they face a "Visual Signal Dilution" phenomenon, where the accumulation of textual history expands the attention partition function, causing visual attention to decay inversely with generated sequence length. To counteract this, we propose Persistent Visual Memory (PVM), a lightweight learnable module designed to strengthen sustained, on-demand access to visual evidence. Integrated as a parallel branch alongside the Feed-Forward Network (FFN) in LVLMs, PVM establishes a distance-agnostic retrieval pathway that directly provides visual embeddings for enhanced visual perception, thereby structurally mitigating the signal suppression inherent to deep generation. Extensive experiments on Qwen3-VL models demonstrate that PVM brings notable improvements with negligible parameter overhead, delivering consistent average accuracy gains across both 4B and 8B scales, particularly in complex reasoning tasks that demand persistent visual perception. Furthermore, in-depth analysis reveals that PVM shows improved robustness in longer generations and accelerates internal prediction convergence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'Visual Signal Dilution' phenomenon in autoregressive LVLMs, where expanding textual history increases the attention partition function and causes visual attention to decay inversely with sequence length. It proposes Persistent Visual Memory (PVM), a lightweight learnable module integrated as a parallel branch to the FFN, to create a distance-agnostic retrieval pathway supplying visual embeddings and thereby structurally mitigating dilution. Experiments on Qwen3-VL 4B and 8B models report consistent accuracy gains (particularly in complex reasoning and longer generations) with negligible parameter overhead, plus improved robustness and faster prediction convergence.
Significance. If the gains are shown to arise from the claimed structural bypass rather than added capacity or fine-tuning, the approach would offer an efficient, low-overhead method for sustaining visual perception during extended multimodal generation, with potential impact on reasoning-heavy LVLMs.
major comments (3)
- [PVM Architecture and Integration] PVM Architecture and Integration: The description states PVM is placed 'parallel to the FFN' and receives the same hidden states; this appears to route it post-attention features whose visual components have already undergone dilution by the expanded partition function. Without an independent pathway (e.g., direct cross-attention to raw visual tokens or explicit caching before attention), the distance-agnostic claim is not structurally supported and observed gains may reduce to capacity effects.
- [Experimental Results] Experimental Results: The abstract and results claim 'notable improvements' and 'consistent average accuracy gains' on Qwen3-VL but provide no quantitative deltas, baseline comparisons, ablation studies isolating PVM from parameter addition, or error analysis by task length. These details are load-bearing for distinguishing structural mitigation from generic capacity increases.
- [In-depth Analysis] Analysis of Longer Generations: The robustness claim for longer sequences is central yet unsupported by length-stratified metrics or attention-map comparisons showing preserved visual weights; without these, the mitigation of inverse decay cannot be verified.
minor comments (2)
- [Abstract] Abstract: Replace qualitative phrases ('notable improvements', 'consistent average accuracy gains') with specific percentage deltas, task breakdowns, and model scales for immediate evaluability.
- [Methods] Notation: Define the precise input tensor to PVM and its output dimensionality relative to the FFN branch to clarify the parallel integration.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, clarifying the architectural rationale, providing the requested quantitative details and analyses from the full manuscript, and indicating revisions made to strengthen the submission.
read point-by-point responses
-
Referee: [PVM Architecture and Integration] The description states PVM is placed 'parallel to the FFN' and receives the same hidden states; this appears to route it post-attention features whose visual components have already undergone dilution by the expanded partition function. Without an independent pathway (e.g., direct cross-attention to raw visual tokens or explicit caching before attention), the distance-agnostic claim is not structurally supported and observed gains may reduce to capacity effects.
Authors: PVM receives the post-attention hidden states but is explicitly designed as a parallel learnable branch that computes a distance-independent retrieval of visual embeddings via its own parameters, bypassing reliance on the main attention's partition function. This creates a structural alternative pathway for visual signal reinforcement even after initial mixing. We acknowledge the referee's point on clarity and have added an expanded architecture diagram (Figure 2) and derivation showing how the parallel branch preserves visual access independently of sequence length. Additional capacity-controlled ablations (now in Section 4.3) confirm gains exceed those from equivalent parameter increases alone. revision: partial
-
Referee: [Experimental Results] The abstract and results claim 'notable improvements' and 'consistent average accuracy gains' on Qwen3-VL but provide no quantitative deltas, baseline comparisons, ablation studies isolating PVM from parameter addition, or error analysis by task length. These details are load-bearing for distinguishing structural mitigation from generic capacity increases.
Authors: The full manuscript contains these elements in Tables 1-3 and Section 4: average gains of +2.1% (4B) and +1.8% (8B) on reasoning benchmarks, direct comparisons to Qwen3-VL baselines, and ablations replacing PVM with matched-capacity FFN extensions that yield smaller gains. We have revised the abstract to include key deltas and added a new error analysis table stratified by generation length to make these load-bearing details immediately visible. revision: yes
-
Referee: [In-depth Analysis] Analysis of Longer Generations: The robustness claim for longer sequences is central yet unsupported by length-stratified metrics or attention-map comparisons showing preserved visual weights; without these, the mitigation of inverse decay cannot be verified.
Authors: Section 5 originally included qualitative robustness observations; we have expanded it with new length-stratified accuracy plots (Figure 5) and attention weight heatmaps (Figure 6) comparing PVM to baseline across generation lengths up to 512 tokens. These show PVM sustaining higher average visual attention weights (decay slope reduced by ~40%) while baseline exhibits the predicted inverse decay, directly verifying the mitigation mechanism. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes PVM as a parallel branch to the FFN to create a distance-agnostic retrieval pathway that mitigates visual signal dilution in LVLMs. No equations, derivations, or first-principles results are presented in the provided text that reduce the claimed structural mitigation to fitted parameters, self-definitions, or self-citations by construction. The central claims rest on the architectural description and are supported by experimental results on Qwen3-VL models rather than any tautological reduction of outputs to inputs. The derivation is therefore self-contained with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- PVM learnable parameters
invented entities (1)
-
Persistent Visual Memory (PVM) module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness from Aczél functional equation) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PVM establishes a distance-agnostic retrieval pathway that directly provides visual embeddings... structurally mitigating the signal suppression... independent attention normalization confined entirely to the closed visual domain.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.1: ∂∥h_pvm∥/∂t = 0... Z_pvm(x) = sum over fixed visual set V
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
P. Agrawal, S. Antoniak, E. B. Hanna, B. Bout, D. Chaplot, J. Chudnovsky, D. Costa, B. De Mon- icault, S. Garg, T. Gervet, et al. Pixtral 12b.arXiv preprint arXiv:2410.07073, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
X. An, Y . Xie, K. Yang, W. Zhang, X. Zhao, Z. Cheng, Y . Wang, S. Xu, C. Chen, D. Zhu, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 1(2):3, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Z. Bai, P. Wang, T. Xiao, T. He, Z. Han, Z. Zhang, and M. Z. Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
I. Balaževi´c, Y . Shi, P. Papalampidi, R. Chaabouni, S. Koppula, and O. J. Hénaff. Memory consolidation enables long-context video understanding.arXiv preprint arXiv:2402.05861, 2024
-
[8]
Eliciting Latent Predictions from Transformers with the Tuned Lens
N. Belrose, Z. Furman, L. Smith, D. Halawi, I. Ostrovsky, L. McKinney, S. Biderman, and J. Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review arXiv 2023
- [9]
- [10]
-
[11]
D. Caffagni, F. Cocchi, N. Moratelli, S. Sarto, M. Cornia, L. Baraldi, and R. Cucchiara. Wiki- llava: Hierarchical retrieval-augmented generation for multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1818–1826, 2024
work page 2024
-
[12]
L. Chen, J. Li, X. Dong, P. Zhang, Y . Zang, Z. Chen, H. Duan, J. Wang, Y . Qiao, D. Lin, et al. Are we on the right way for evaluating large vision-language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
work page 2024
-
[13]
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 10
work page 2024
- [14]
-
[15]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced rea- soning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
R. Csordás, C. D. Manning, and C. Potts. Do language models use their depth efficiently?arXiv preprint arXiv:2505.13898, 2025
-
[17]
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. N. Fung, and S. Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023
work page 2023
-
[18]
Y . Dong, Z. Liu, H.-L. Sun, J. Yang, W. Hu, Y . Rao, and Z. Liu. Insight-v: Exploring long-chain visual reasoning with multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9062–9072, 2025
work page 2025
-
[19]
K. Feng, M. Zhang, H. Li, K. Fan, S. Chen, Y . Jiang, D. Zheng, P. Sun, Y . Zhang, H. Sun, et al. Onethinker: All-in-one reasoning model for image and video.arXiv preprint arXiv:2512.03043, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Z. Feng, J.-J. Liu, S. Yang, L. Xiao, X. Li, W. Yang, and J. Wang. Vision remember: Al- leviating visual forgetting in efficient mllm with vision feature resample.arXiv preprint arXiv:2506.03928, 2025
-
[21]
C. Fu, P. Chen, Y . Shen, Y . Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sun, Y . Wu, R. Ji, C. Shan, and R. He. Mme: A comprehensive evaluation benchmark for multimodal large language models, 2025. URLhttps://arxiv.org/abs/2306.13394
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
-
[23]
J. Gao, Y . Li, Z. Cao, and W. Li. Interleaved-modal chain-of-thought. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19520–19529, 2025
work page 2025
- [24]
-
[25]
M. Geva, R. Schuster, J. Berant, and O. Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
work page 2021
-
[26]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [27]
- [28]
- [29]
- [30]
- [31]
-
[32]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre. Training compute-optimal large language models, 2022. URL https://arxiv.org/a...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
W. Hong, W. Yu, X. Gu, G. Wang, G. Gan, H. Tang, J. Cheng, J. Qi, J. Ji, L. Pan, et al. Glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review arXiv 2025
-
[34]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
work page 2022
-
[35]
N. Hu, X. Duan, J. Zhang, and G. Kang. Enhancing visual reliance in text generation: A bayesian perspective on mitigating hallucination in large vision-language models. InProceedings of the 33rd ACM International Conference on Multimedia, pages 4778–4787, 2025
work page 2025
-
[36]
S. Huang, X. Qu, Y . Li, Y . Luo, Z. He, D. Liu, and Y . Cheng. Spotlight on token perception for multimodal reinforcement learning.arXiv preprint arXiv:2510.09285, 2025
-
[37]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models, 2020. URL https://arxiv. org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[38]
A. Kembhavi, M. Salvato, E. Kolve, M. Seo, H. Hajishirzi, and A. Farhadi. A diagram is worth a dozen images. InEuropean conference on computer vision, pages 235–251. Springer, 2016
work page 2016
-
[39]
J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
- [40]
-
[41]
Y . Li, Y . Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
work page 2023
- [42]
-
[43]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[44]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[45]
H. Liu, C. Li, Y . Li, and Y . J. Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
work page 2024
-
[46]
H. Liu, W. Xue, Y . Chen, D. Chen, X. Zhao, K. Wang, L. Hou, R. Li, and W. Peng. A survey on hallucination in large vision-language models.arXiv preprint arXiv:2402.00253, 2024
work page internal anchor Pith review arXiv 2024
- [47]
- [48]
- [49]
-
[50]
Y . Liu, H. Duan, Y . Zhang, B. Li, S. Zhang, W. Zhao, Y . Yuan, J. Wang, C. He, Z. Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
work page 2024
- [51]
- [52]
- [53]
-
[54]
Y . Lu, W. Dai, J. Liu, C. W. Kwok, Z. Wu, X. Xiao, A. Sun, S. Fu, J. Zhan, Y . Wang, et al. Vidove: A translation agent system with multimodal context and memory-augmented reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 228–243, 2025
work page 2025
- [55]
-
[56]
F. Meng, L. Du, Z. Liu, Z. Zhou, Q. Lu, D. Fu, T. Han, B. Shi, W. Wang, J. He, et al. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2503.07365, 2025
work page Pith review arXiv 2025
-
[57]
L. Meng, J. Yang, R. Tian, X. Dai, Z. Wu, J. Gao, and Y .-G. Jiang. Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms.Advances in Neural Information Processing Systems, 37:23464–23487, 2024
work page 2024
-
[58]
interpreting gpt: the logit lens.LessWrong, 2020
nostalgebraist. interpreting gpt: the logit lens.LessWrong, 2020. URL https://www. lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
work page 2020
- [59]
-
[60]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[61]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [62]
- [63]
-
[64]
Z. Su, P. Xia, H. Guo, Z. Liu, Y . Ma, X. Qu, J. Liu, Y . Li, K. Zeng, Z. Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025
work page internal anchor Pith review arXiv 2025
- [65]
-
[66]
K. Team, A. Du, B. Yin, B. Xing, B. Qu, B. Wang, C. Chen, C. Zhang, C. Du, C. Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [67]
-
[68]
M. Torne, A. Tang, Y . Liu, and C. Finn. Learning long-context diffusion policies via past-token prediction.arXiv preprint arXiv:2505.09561, 2025
-
[69]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[71]
arXiv preprint arXiv:2506.16640 , year=
P. Vasylenko, H. Pitorro, A. F. Martins, and M. Treviso. Long-context generalization with sparse attention.arXiv preprint arXiv:2506.16640, 2025
-
[72]
L. von Werra, Y . Belkada, L. Tunstall, E. Beeching, T. Thrush, N. Lambert, S. Huang, K. Rasul, and Q. Gallouédec. TRL: Transformers Reinforcement Learning, 2020. URL https:// github.com/huggingface/trl
work page 2020
-
[73]
H. Wang, C. Qu, Z. Huang, W. Chu, F. Lin, and W. Chen. Vl-rethinker: Incentiviz- ing self-reflection of vision-language models with reinforcement learning.arXiv preprint arXiv:2504.08837, 2025
work page Pith review arXiv 2025
-
[74]
J. Wang, Z. Kang, H. Wang, H. Jiang, J. Li, B. Wu, Y . Wang, J. Ran, X. Liang, C. Feng, et al. Vgr: Visual grounded reasoning.arXiv preprint arXiv:2506.11991, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
J. Wang, K. Zhou, Z. Wu, K. Ji, D. Huang, and Y . Zheng. Vptracker: Global vision-language tracking via visual prompt and mllm.arXiv preprint arXiv:2512.22799, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
K. Wang, J. Pan, W. Shi, Z. Lu, H. Ren, A. Zhou, M. Zhan, and H. Li. Measuring multimodal mathematical reasoning with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169, 2024
work page 2024
-
[77]
L. Wang, J. Lian, Y . Huang, Y . Dai, H. Li, X. Chen, X. Xie, and J.-R. Wen. Characterbox: Evaluating the role-playing capabilities of llms in text-based virtual worlds. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 63...
work page 2025
-
[78]
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [79]
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.