How Well Can We Decode Vowels from Auditory EEG -- A Rigorous Cross-Subject Benchmark with Honest Assessment
Pith reviewed 2026-05-10 00:30 UTC · model grok-4.3
The pith
Vowel decoding from auditory EEG reaches 25 percent accuracy under strict cross-subject evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
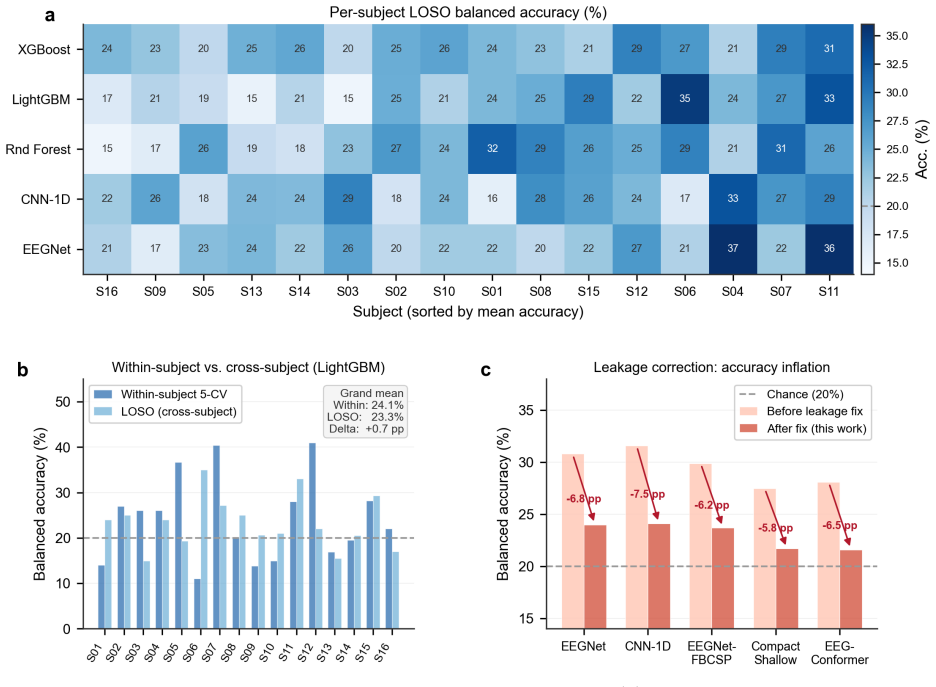
Under strict leave-one-subject-out evaluation with training-only normalization and explicit anti-leakage controls on the OpenNeuro ds006104 dataset, the best models achieve 24.5 percent accuracy with full features using XGBoost and 25.5 percent with differential entropy features using LightGBM, compared to 20 percent chance; vowel information proves real but weak and is carried primarily by early transient auditory responses.
What carries the argument
The leave-one-subject-out cross-validation protocol with training-only normalization applied across 14 pipelines from classical ML, deep learning, and Riemannian methods.
If this is right
- Vowel information is detectable but weak and concentrated in early transient auditory responses.
- Classical machine learning approaches remain competitive with deep learning models in this low-signal regime.
- Strong pairwise advantages between models largely disappear after multiple-comparison correction.
- Reproducible code release allows future studies to test new pipelines on the same strict benchmark.
Where Pith is reading between the lines
- BCI applications for speech decoding may need subject-specific adaptation or much larger multi-subject training sets to reach practical utility.
- The modest cross-subject results suggest that research emphasis should shift toward improving robustness across individuals rather than within-subject accuracy alone.
- Similar strict benchmarks could be run on consonant or word-level decoding to determine whether the performance ceiling is specific to vowels or general to auditory EEG phoneme tasks.
Load-bearing premise
The 16-subject dataset and chosen leave-one-subject-out protocol with training-only normalization fully capture real-world cross-subject generalization without residual leakage or cohort-specific artifacts.
What would settle it
A new method that reaches 40 percent or higher accuracy on the same dataset under identical leave-one-subject-out conditions with training-only normalization would falsify the claim of limited performance.
Figures










read the original abstract
EEG based phoneme decoding is promising for brain computer interfaces, but many prior studies rely on within subject evaluation, small cohorts, or weak leakage control. We present a reproducible cross subject benchmark for five class vowel decoding (a, e, i, o, u) from auditory EEG using OpenNeuro ds006104 (16 subjects, 61 channels, 256 Hz). Under strict leave one subject out evaluation with training only normalization and explicit anti leakage checks, we compare 14 pipelines from classical machine learning, deep learning, and Riemannian methods. The best full feature model (XGBoost) reaches 24.5 percent accuracy (chance 20 percent), while differential entropy features with LightGBM reach 25.5 percent in feature specific analysis. After multiple comparison correction, strong pairwise model advantages are limited. Classical methods are competitive with deep models in this low signal regime. Additional analyses (ablation, pairwise vowels, within subject CV, ERP, temporal generalization, and electrode importance) indicate that vowel information is real but weak and mainly carried by early transient auditory responses. We release code and evaluation scripts for full reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a reproducible cross-subject benchmark for five-class vowel decoding (a, e, i, o, u) from auditory EEG on the OpenNeuro ds006104 dataset (16 subjects, 61 channels). It evaluates 14 pipelines spanning classical ML (XGBoost, LightGBM with differential entropy), deep learning, and Riemannian methods under strict leave-one-subject-out (LOSO) evaluation with training-only normalization and explicit anti-leakage controls. The best reported accuracies are 24.5% (XGBoost, full features) and 25.5% (differential entropy + LightGBM, feature-specific), both above the 20% chance level. After multiple-comparison correction, strong pairwise advantages are limited. Additional analyses (ablations, pairwise vowels, within-subject CV, ERP, temporal generalization, electrode importance) indicate that vowel information is real but weak and carried mainly by early transient auditory responses. Code and evaluation scripts are released for full reproducibility.
Significance. If the results hold, the work supplies a high-standard, leakage-controlled empirical baseline for cross-subject phoneme decoding in a low-signal regime. It demonstrates that classical methods remain competitive with deep models, that performance gains after correction are modest, and that information is localized to early auditory transients. The explicit protocol (LOSO, training-only normalization, anti-leakage checks, multiple-comparison correction, ablations) together with public code release constitutes a reusable benchmark that can raise standards in the BCI/auditory-EEG literature and temper expectations for practical applications.
minor comments (2)
- [Abstract and Results] Abstract and results section: the 24.5% (full-feature XGBoost) and 25.5% (DE+LightGBM) figures are presented separately; a single summary table that clearly separates full-feature versus feature-specific pipelines would improve readability.
- [Methods] Methods: the 14 pipelines are described in text; a compact table listing each pipeline's feature set, classifier, and key hyperparameters would aid quick comparison.
Simulated Author's Rebuttal
We thank the referee for their positive and detailed assessment of the manuscript. Their summary accurately reflects the scope, methods, and findings of our work, and we appreciate the recommendation to accept.
Circularity Check
No significant circularity
full rationale
This is a purely empirical benchmark paper reporting cross-subject vowel decoding accuracies from public EEG data under LOSO evaluation. Reported results (24.5% XGBoost full features, 25.5% differential entropy + LightGBM) are direct outputs of standard ML training and testing pipelines with explicit leakage controls; no equations, ansatzes, or self-citations reduce these accuracies to fitted parameters or prior results by construction. The derivation chain consists of data preprocessing, feature extraction, model fitting, and evaluation—none of which are self-referential or load-bearing on unverified self-citations. The paper is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Auditory EEG contains decodable information about spoken vowels that generalizes across subjects when properly controlled for leakage
Reference graph
Works this paper leans on
-
[1]
Christian Herff, Dominic Heger, Adriana de Pesters, Dominik Telaar, Peter Brunner, Gerwin Schalk, and Tanja Schultz. Brain-to-text: decoding spoken phrases from phone representations in the brain.Frontiers in Neuroscience, 9:217, 2015. doi: 10.3389/fnins. 2015.00217
-
[2]
Neuroprosthesis for decoding speech in a paralyzed person with anarthria
David A Moses, Sean L Metzger, Jessie R Liu, Gopala K Anumanchipalli, Joseph G Makin, Pengfei F Sun, Josh Chartier, Maximilian E Dougherty, Patricia M Liu, Gary M Abrams, et al. Neuroprosthesis for decoding speech in a paralyzed person with anarthria. New England Journal of Medicine, 385(3):217–227, 2021. doi: 10.1056/NEJMoa2027540
-
[3]
Nature Machine Intelligence5 (2023) https://doi.org/10.1038/s42256-023-00714-5 35
Alexandre D´ efossez, Charlotte Caucheteux, J´ er´ emy Rapin, Ori Kabeli, and Jean-R´ emi King. Decoding speech perception from non-invasive brain recordings.Nature Machine Intelligence, 5(10):1097–1107, 2023. doi: 10.1038/s42256-023-00714-5
-
[4]
URL https://dx.doi.org/10.1088/ 1741-2552/ad546d
Vinay Jayaram and Alexandre Barachant. MOABB: trustworthy algorithm benchmarking for BCIs.Journal of Neural Engineering, 15(6):066011, 2018. doi: 10.1088/1741-2552/ aadea0
-
[5]
Chuong H Nguyen, George K Karavas, and Panagiotis Artemiadis. Inferring imagined speech using EEG signals: a new approach using Riemannian manifold features.Journal of Neural Engineering, 15(1):016002, 2018. doi: 10.1088/1741-2552/aa8235. 29
-
[6]
Debadatta Dash, Paul Ferrari, and Jun Wang. Decoding imagined and spoken phrases from non-invasive neural (MEG) signals.Frontiers in Neuroscience, 14:290, 2020. doi: 10.3389/fnins.2020.00290
-
[7]
Christian Herff and Tanja Schultz. Automatic speech recognition from neural signals: a focused review.Frontiers in Neuroscience, 10:429, 2016. doi: 10.3389/fnins.2016.00429
-
[8]
Classi- fication of covariance matrices using a Riemannian-based kernel for BCI applications
Alexandre Barachant, St´ ephane Bonnet, Marco Congedo, and Christian Jutten. Classi- fication of covariance matrices using a Riemannian-based kernel for BCI applications. Neurocomputing, 112:172–178, 2013. doi: 10.1016/j.neucom.2012.12.039
-
[9]
Marco Congedo, Alexandre Barachant, and Rajendra Bhatia. Riemannian geometry for EEG-based brain-computer interfaces; a primer and a review.Brain-Computer Interfaces, 4(3):155–174, 2017. doi: 10.1080/2326263X.2017.1297192
-
[10]
He He and Dongrui Wu. Transfer learning for brain–computer interfaces: A Euclidean space data alignment approach.IEEE Transactions on Biomedical Engineering, 67(2): 399–410, 2020. doi: 10.1109/TBME.2019.2913914
-
[11]
Vernon J Lawhern, Amelia J Solon, Nicholas R Waytowich, Stephen M Gordon, Chou P Hung, and Brent J Lance. EEGNet: a compact convolutional neural network for EEG- based brain–computer interfaces.Journal of Neural Engineering, 15(5):056013, 2018. doi: 10.1088/1741-2552/aace8c
-
[12]
Ruo-Nan Duan, Jia-Yi Zhu, and Bao-Liang Lu. Differential entropy feature for EEG-based emotion classification.Proceedings of the 6th International IEEE/EMBS Conference on Neural Engineering, pages 81–84, 2013. doi: 10.1109/NER.2013.6695876
-
[13]
Jo˜ ao Pedro Carvalho Moreira, Vin´ ıcius Rezende Carvalho, Eduardo Mazoni An- drade Mar¸ cal Mendes, Ariah Fallah, Terrence J Sejnowski, Claudia Lainscsek, and Lindy Comstock. An open-access EEG dataset for speech decoding: Exploring the role of articu- lation and coarticulation.Scientific Data, 12:247, 2025. doi: 10.1038/s41597-025-05187-2
-
[14]
doi:https://doi.org/10.1016/j.neuroimage .2011.01.048
Alexandre Gramfort, Martin Luessi, Eric Larson, Denis A Engemann, Daniel Strohmeier, Christian Brodbeck, Lauri Parkkonen, and Matti S H¨ am¨ al¨ ainen. MNE software for pro- cessing MEG and EEG data.NeuroImage, 86:446–460, 2014. doi: 10.1016/j.neuroimage. 2013.10.027
-
[15]
Eeg conformer: Convolutional transformer for eeg decoding and visualization,
Yonghao Song, Qingqing Zheng, Bingchuan Liu, and Xiaorong Gao. EEG conformer: Convolutional transformer for EEG decoding and visualization.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31:710–719, 2023. doi: 10.1109/TNSRE. 2022.3230250. 30
-
[16]
Risto N¨ a¨ at¨ anen and Terence Picton. The n1 wave of the human electric and magnetic response to sound: a review and an analysis of the component structure.Psychophysiology, 24(4):375–425, 1987. doi: 10.1111/j.1469-8986.1987.tb00311.x
-
[17]
James Hillenbrand, Laura A Getty, Michael J Clark, and Kimberlee Wheeler. Acoustic characteristics of American English vowels.Journal of the Acoustical Society of America, 97(5):3099–3111, 1995. doi: 10.1121/1.411872
-
[18]
Characterizing the dynamics of mental repre- sentations: the temporal generalization method.Trends in Cognitive Sciences, 18(4): 203–210, 2014
Jean-R´ emi King and Stanislas Dehaene. Characterizing the dynamics of mental repre- sentations: the temporal generalization method.Trends in Cognitive Sciences, 18(4): 203–210, 2014
2014
-
[19]
Human Brain Mapping38(2017) https://doi.org/10.1002/hbm.23730
Robin Tibor Schirrmeister, Jost Tobias Springenberg, Lukas Dominique Josef Fiederer, Martin Glasstetter, Katharina Eggensperger, Michael Tangermann, Frank Hutter, Wol- fram Burgard, and Tonio Ball. Deep learning with convolutional neural networks for EEG decoding and visualization.Human Brain Mapping, 38(11):5391–5420, 2017. doi: 10.1002/hbm.23730
-
[20]
BRANT: Foundation model for intracranial neural signal.Advances in Neural Information Processing Systems, 36, 2024
Daoze Yang, Zhizhang Li, Junru Yang, Chenxin Jiang, Tinglin Zhang, and Yang Zhang. BRANT: Foundation model for intracranial neural signal.Advances in Neural Information Processing Systems, 36, 2024. 31
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.