Recognition: 2 theorem links
· Lean TheoremCLEAR: Revealing How Noise and Ambiguity Degrade Reliability in LLMs for Medicine
Pith reviewed 2026-05-12 01:48 UTC · model grok-4.3
The pith
Medical LLMs select more incorrect answers and abstain less as the number of options increases and abstention is framed as uncertainty, with the humility deficit growing in larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
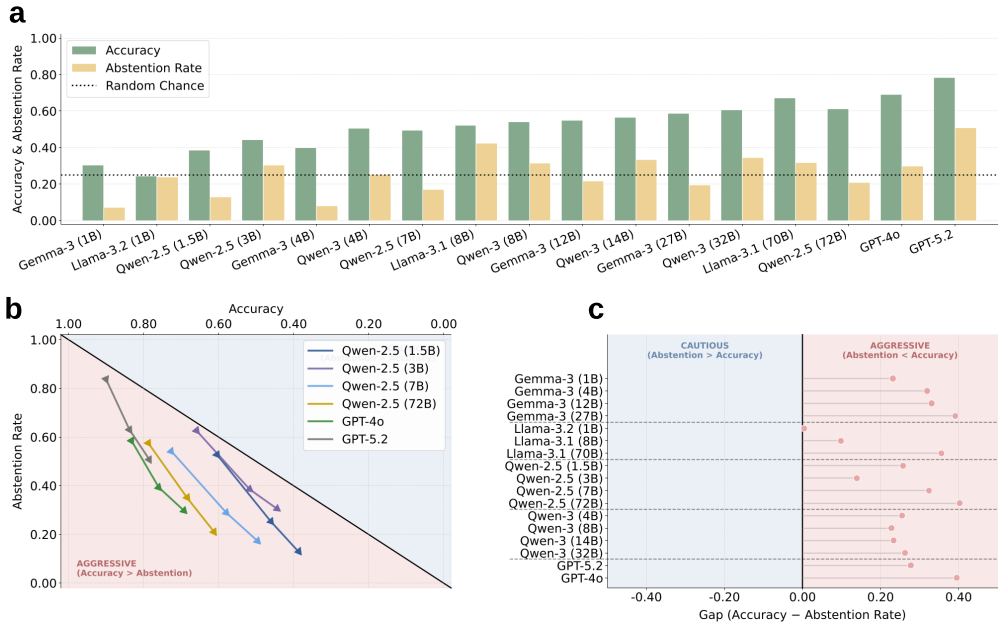
Applying the CLEAR framework, which perturbs the number of plausible answers, the presence of ground truth, and the semantic framing of options, shows that increasing plausible answers degrades both correct identification and abstention from incorrect ones. Caution decreases when abstention is framed as uncertainty admission rather than rejection, and including an 'I don't know' option raises incorrect selections. The humility deficit, the performance gap between selecting the right answer and avoiding wrong ones, increases with model scale.
What carries the argument
The CLEAR framework, which systematically varies the decision-space presentation including option count and abstention framing to expose how ambiguity affects LLM reliability on medical benchmarks.
If this is right
- Standard exam-style benchmarks likely overestimate LLM reliability in medicine by not including realistic ambiguity.
- Including uncertainty-framed abstention options increases the rate of incorrect answer selections.
- The humility deficit between correct selection and proper abstention grows as models increase in size.
- Scaling LLMs alone does not resolve issues with overconfidence in ambiguous medical scenarios.
Where Pith is reading between the lines
- Extending CLEAR to open-ended medical queries rather than multiple choice could reveal even larger reliability shortfalls.
- Training methods focused on calibrated abstention might be needed alongside scaling to improve real-world safety.
- Similar ambiguity effects may appear in LLM applications to other uncertain domains like diagnostics or legal advice.
Load-bearing premise
That the controlled perturbations of option numbers, ground truth inclusion, and abstention phrasing in benchmark questions mirror the ambiguity and uncertainty in actual medical decision-making.
What would settle it
Finding that the humility deficit does not increase with model scale when tested on a different set of medical questions with naturally occurring ambiguity would falsify the scaling observation.
Figures




read the original abstract
Medical large language model (LLM) evaluations rely on simplified, exam-style benchmarks that rarely reflect the ambiguity of real-world medical inquiries. We introduce the CLinical Evaluation of Ambiguity and Reliability (CLEAR) framework, which assesses how decision-space presentation, ambiguity, and uncertainty affect LLMs' reasoning on medical benchmarks. CLEAR systematically perturbs (1) the number of plausible answer options, (2) the presence of a ground truth or abstention option, and (3) the semantic framing of answer options. Applying CLEAR on three benchmarks evaluated across 17 LLMs reveals three notable limitations of existing evaluation methods. First, increasing the number of plausible answers degrades a model's ability to identify the correct answer and abstain against incorrect ones. Second, this lack of caution intensifies as the framing of abstention shifts from assertive rejection like "None of the Above" to uncertainty admission like "I don't know" (IDK). Notably, just including IDK in the answer space increases incorrect answer selections. Lastly, we formalize the performance gap between identifying the correct answer and abstaining from incorrect ones as the humility deficit, which worsens with model scale. Our findings reveal limitations in standard medical benchmarks and underscore that scaling alone does not resolve LLM reliability issues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the CLEAR framework for evaluating the impact of ambiguity and uncertainty on LLMs in medical question-answering tasks. It perturbs exam-style benchmarks by changing the number of answer options, including or excluding ground truth or abstention choices, and altering the semantic framing of options (e.g., 'None of the Above' versus 'I don't know'). Experiments on three benchmarks with 17 LLMs show that more options reduce accuracy and abstention performance, that 'I don't know' framing leads to more incorrect selections, and that the 'humility deficit'—the gap between correct identification and error abstention—increases with model scale. The authors argue that standard benchmarks fail to capture real medical ambiguity and that scaling does not improve reliability.
Significance. If validated, the systematic perturbation approach and the formalization of the humility deficit would provide a concrete metric for assessing LLM overconfidence under uncertainty, challenging the view that scale alone improves reliability in high-stakes domains. The evaluation across 17 models and multiple benchmarks is a strength for reproducibility of the observed trends. However, without details on statistical rigor or real-world validation, the direct implications for medical applications remain provisional.
major comments (2)
- Abstract: the claim that the humility deficit worsens with model scale is presented as one of three key findings, yet the abstract (and by extension the reported results) provides no details on statistical tests, effect sizes, confidence intervals, or controls for prompt sensitivity and random seed variation. This is load-bearing for the scale-related conclusion.
- Evaluation section (implied by the perturbation methodology): the central generalization to 'LLMs for Medicine' rests on the assumption that varying option count, ground-truth presence, and abstention phrasing (e.g., IDK vs. None of the Above) accurately proxies real clinical ambiguity such as incomplete histories or conflicting evidence. No validation or side-by-side comparison with naturalistic medical queries is provided to support this mapping, which directly affects whether the observed degradation trends apply outside closed-ended exam formats.
minor comments (2)
- The introduction of the term 'humility deficit' would benefit from a short reference to prior literature on LLM overconfidence or calibration to better situate the contribution.
- Table or figure captions describing the exact perturbation levels (e.g., specific option counts tested) could be expanded for immediate clarity without requiring reference to the main text.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which help us clarify the scope and strengthen the presentation of our work. We address each major comment point by point below.
read point-by-point responses
-
Referee: Abstract: the claim that the humility deficit worsens with model scale is presented as one of three key findings, yet the abstract (and by extension the reported results) provides no details on statistical tests, effect sizes, confidence intervals, or controls for prompt sensitivity and random seed variation. This is load-bearing for the scale-related conclusion.
Authors: We agree that the abstract omits statistical details due to length constraints and that the scale-related claim would benefit from greater rigor. The main text reports the humility deficit trend across 17 models via figures and tables, but does not include formal statistical tests or controls for prompt/seed variation. In revision we will add correlation analysis with p-values and effect sizes to the results section, document prompt sensitivity checks, and revise the abstract to reference these supporting analyses rather than stating the trend in isolation. revision: yes
-
Referee: Evaluation section (implied by the perturbation methodology): the central generalization to 'LLMs for Medicine' rests on the assumption that varying option count, ground-truth presence, and abstention phrasing (e.g., IDK vs. None of the Above) accurately proxies real clinical ambiguity such as incomplete histories or conflicting evidence. No validation or side-by-side comparison with naturalistic medical queries is provided to support this mapping, which directly affects whether the observed degradation trends apply outside closed-ended exam formats.
Authors: We acknowledge that the perturbations constitute a controlled proxy rather than a direct replication of naturalistic clinical ambiguity. The framework is intentionally designed to isolate specific, reproducible factors on existing benchmarks; we do not claim equivalence to open-ended clinical encounters. In the revision we will add an explicit limitations paragraph clarifying the proxy nature of the method, noting that the observed trends apply most directly to closed-ended medical QA, and outlining the need for future validation against real-world clinical data. revision: partial
Circularity Check
No circularity: empirical observations from benchmark perturbations
full rationale
The paper introduces the CLEAR framework as a set of controlled perturbations to existing medical MCQ benchmarks (varying option count, ground-truth presence, and abstention phrasing) and reports direct experimental outcomes across 17 LLMs. The humility deficit is introduced simply as a label for the measured gap between correct-answer accuracy and abstention rates, with the scale trend stated as an observed pattern rather than a derived theorem. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; all claims rest on the experimental results themselves. This is a standard empirical evaluation study whose central findings are falsifiable against the same benchmarks and do not reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Perturbations to answer-option count, ground-truth presence, and abstention phrasing in exam benchmarks simulate real-world medical ambiguity and uncertainty.
invented entities (1)
-
humility deficit
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we formalize the performance gap between identifying the correct answer and abstaining from incorrect ones as the humility deficit, which worsens with model scale
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CLEAR systematically perturbs (1) the number of plausible answer options, (2) the presence of a ground truth or abstention option, and (3) the semantic framing of answer options
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tutty, M. A., Carlasare, L. E., Lloyd, S. & Sinsky, C. A. The complex case of EHRs: Examining the factors impacting the EHR user experience.J. Am. Med. Informatics Assoc.26, 673–677 (2019)
work page 2019
-
[2]
Cimino, J. J. Putting the “why” in “EHR”: Capturing and coding clinical cognition.J. Am. Med. Informatics Assoc.26, 1379–1384 (2019). 4.Sim, I. Mobile devices and health.New Engl. J. Medicine381, 956–968 (2019). 5.McDuff, D.et al.Towards accurate differential diagnosis with large language models.Nature642, 451–457 (2025)
work page 2019
-
[3]
Van Veen, D.et al.Adapted large language models can outperform medical experts in clinical text summarization.Nat. medicine30, 1134–1142 (2024)
work page 2024
-
[4]
Singhal, K.et al.Toward expert-level medical question answering with large language models.Nat. Medicine31, 943–950 (2025). 8.Lukac, P. J.et al.Ambient ai scribes in clinical practice: A randomized trial.NEJM AI2, AIoa2501000 (2025)
work page 2025
-
[5]
Afshar, M.et al.A pragmatic randomized controlled trial of ambient artificial intelligence to improve health practitioner well-being.NEJM AI2, AIoa2500945 (2025)
work page 2025
-
[6]
Li, J., Zhou, Z., Lyu, H. & Wang, Z. Large language models-powered clinical decision support: Enhancing or replacing human expertise?Intell. Medicine5, 1–4 (2025). 11.Nazi, Z. A. & Peng, W. Large language models in healthcare and medical domain: A review.Informatics11, 57 (2024)
work page 2025
-
[7]
Zhang, K.et al.Revolutionizing health care: The transformative impact of large language models in medicine.J. Med. Internet Res.27, e59069 (2025)
work page 2025
-
[8]
Goh, E.et al.Large language model influence on diagnostic reasoning: A randomized clinical trial.JAMA Netw. Open7, e2440969 (2024)
work page 2024
-
[9]
Jin, D.et al.What disease does this patient have? A large-scale open domain question answering dataset from medical exams.Appl. Sci.11, 6421 (2021). 11/21
work page 2021
-
[10]
Pal, A., Umapathi, L. K. & Sankarasubbu, M. MedMCQA: A large-scale multi-subject multi-choice dataset for medical domain question answering. InProc of Conference on Health, Inference, and Learning, 248–260 (2022). 16.Hendrycks, D.et al.Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300(2020). 17.Zhou, K.et al.Don’t make you...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Handler, R., Sharma, S. & Hernandez-Boussard, T. The fragile intelligence of GPT-5 in medicine.Nat. Medicine31, 3968–3970 (2025)
work page 2025
-
[12]
Agrawal, M., Chen, I. Y ., Gulamali, F. & Joshi, S. The evaluation illusion of large language models in medicine.npj Digit. Medicine8, 600 (2025). 20.Rao, A. S.et al.Large language model performance and clinical reasoning tasks.JAMA Netw. Open9, e264003 (2026). 21.Smith, P. C.et al.Missing clinical information during primary care visits.JAMA293, 565–571 (2005)
work page 2025
-
[13]
J., Deelchand, V ., Franklin, B
Burnett, S. J., Deelchand, V ., Franklin, B. D., Moorthy, K. & Vincent, C. Missing clinical information in nhs hospital outpatient clinics: prevalence, causes and effects on patient care.BMC Heal. Serv. Res.11, 114 (2011)
work page 2011
-
[14]
Bean, A. M.et al.Reliability of LLMs as medical assistants for the general public: A randomized preregistered study.Nat. Medicine32, 609–615 (2026)
work page 2026
-
[15]
Lunardi, R., Della Mea, V ., Mizzaro, S. & Roitero, K. On robustness and reliability of benchmark-based evaluation of llms. InProc of the 28th European Conference on Artificial Intelligence, vol. 413, 4603–4611 (2025)
work page 2025
- [16]
- [17]
-
[18]
A., Dorotic, M., Dubin, J., Nazarian, N
Celi, L. A., Dorotic, M., Dubin, J., Nazarian, N. & Salarikia, R. Epistemic humility for physicians and scientists.Lancet Reg. Heal.53(2026)
work page 2026
-
[19]
Pauker, S. G. & Kassirer, J. P. The threshold approach to clinical decision making.New Engl. J. Medicine302, 1109–1117 (1980)
work page 1980
-
[20]
InProc of Advances in Neural Information Processing Systems, vol
Wei, J.et al.Chain-of-thought prompting elicits reasoning in large language models. InProc of Advances in Neural Information Processing Systems, vol. 35, 24824–24837 (2022)
work page 2022
-
[21]
R.et al.To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
Sprague, Z. R.et al.To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning. InProc of The Thirteenth International Conference on Learning Representations(2025). 31.Mongtomery, K.How doctors think: Clinical judgment and the practice of medicine(Oxford University Press, 2005)
work page 2025
-
[22]
Li, Z.et al.Evaluating clinical competencies of large language models with a general practice benchmark.Nat. Commun. (2026)
work page 2026
-
[23]
Griot, M., Hemptinne, C., Vanderdonckt, J. & Yuksel, D. Large language models lack essential metacognition for reliable medical reasoning.Nat. Commun.16, 642 (2025)
work page 2025
- [24]
- [25]
-
[26]
Scaling Laws for Neural Language Models
Jeon, S. & Kim, H.-G. A comparative evaluation of chain-of-thought-based prompt engineering techniques for medical question answering.Comput. Biol. Medicine196, 110614 (2025). 37.Kaplan, J.et al.Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
McCoy, L. G.et al.Assessment of large language models in clinical reasoning: A novel benchmarking study.NEJM AI2, AIdbp2500120 (2025)
work page 2025
-
[28]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y .et al.Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862(2022). 40.Sharma, M.et al.Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
InProc of Advances in Neural Information Processing Systems, vol
Ouyang, L.et al.Training language models to follow instructions with human feedback. InProc of Advances in Neural Information Processing Systems, vol. 35, 27730–27744 (2022). 12/21
work page 2022
-
[30]
Why Language Models Hallucinate
Kalai, A. T., Nachum, O., Vempala, S. S. & Zhang, E. Why language models hallucinate?arXiv preprint arXiv:2509.04664 (2025)
work page internal anchor Pith review arXiv 2025
-
[31]
Omar, M.et al.Mapping the susceptibility of large language models to medical misinformation across clinical notes and social media: A cross-sectional benchmarking analysis.Lancet Digit. Heal.8(2026)
work page 2026
-
[32]
Chen, H., Fang, Z., Singla, Y . & Dredze, M. Benchmarking large language models on answering and explaining challenging medical questions. InProc of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, 3563–3599 (2025). 13/21 Supplementary Material NA NA+INA NA+IDK NA NA+...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.