Recognition: unknown
Mesh Based Simulations with Spatial and Temporal awareness
Pith reviewed 2026-05-09 14:57 UTC · model grok-4.3
The pith
Mesh-based ML models for fluid simulation gain accuracy and long-term stability by predicting entire local stencils and applying temporal cross-attention corrections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training on stencil-level multi-node targets instead of isolated node values, inserting a temporal cross-attention corrector in place of explicit stepping, and encoding mesh geometry with 3D rotary positional embeddings, the resulting models produce field predictions whose spatial derivatives remain consistent with the underlying PDE and whose temporal trajectories remain stable far beyond the training horizon while also supporting zero-shot prediction of additional physical fields.
What carries the argument
Stencil-level multi-node prediction objective together with a temporal cross-attention predictor-corrector and 3D rotary positional embeddings on unstructured meshes.
If this is right
- Long-horizon rollouts remain stable without rapid accumulation of local truncation errors.
- The learned representations transfer directly to downstream tasks such as pressure or wall-shear-stress prediction without retraining.
- The same training recipe improves performance across Graph Neural Networks, mesh Transformers, and related architectures.
- Spatial consistency is achieved without adding explicit physics-informed loss terms.
Where Pith is reading between the lines
- The approach could be tested on adaptive mesh refinement by training only on coarse stencils and rolling out to finer resolutions.
- Similar stencil objectives might reduce the need for separate physics-informed neural network regularizers in other PDE domains.
- Because the method removes explicit Euler stepping, larger effective time steps become feasible once the corrector is trained.
Load-bearing premise
That forcing the network to predict an entire local stencil at once will enforce spatial derivative consistency and that the temporal cross-attention corrector will stabilize stiff dynamics without introducing fresh instabilities or requiring dataset-specific retuning.
What would settle it
A controlled long-horizon rollout experiment on a stiff advection-dominated flow in which the stencil-plus-correction model accumulates larger error or diverges earlier than an otherwise identical node-wise explicit baseline would falsify the central claim.
Figures









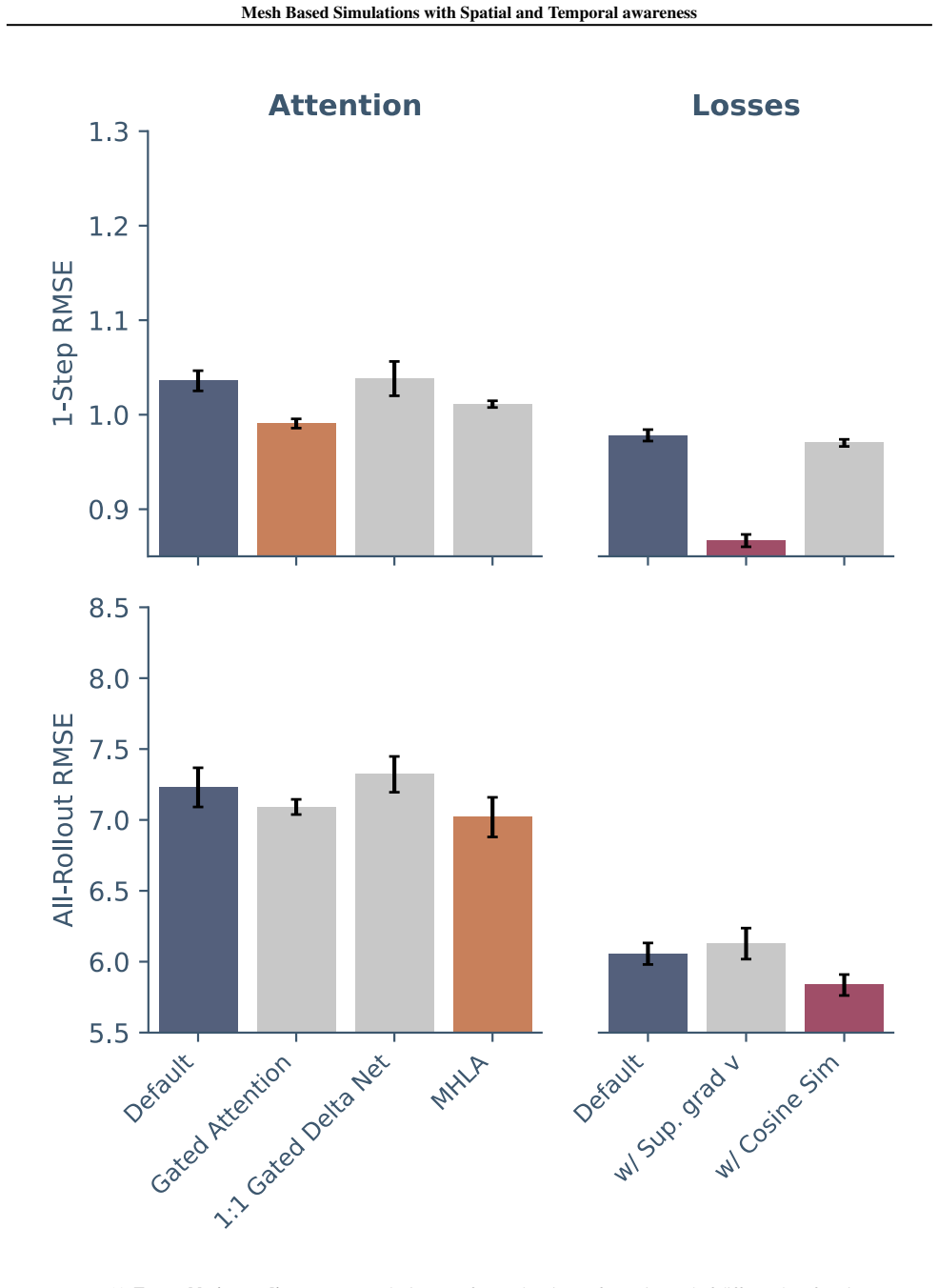
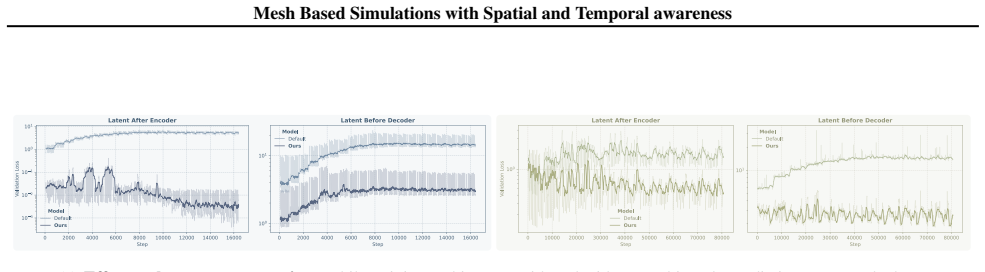

read the original abstract
Machine Learning surrogates for Computational Fluid Dynamics (CFD), particularly Graph Neural Networks (GNNs) and Transformers, have become a new important approach for accelerating physics simulations. However, we identify a critical bottleneck in the field: while architectures have advanced significantly, the common underlying training paradigms remain bound to naive assumptions, such as node-wise supervision and explicit Euler time-stepping. These legacy choices ignore the stiff dynamics and local flux continuity inherent to numerous partial differential equations resolution methods, such as Finite Element, Difference, or Volume (FEM). In this work, we propose a unified framework to bridge the gap between geometric deep learning and rigorous numerical analysis. We introduce three key innovations: (1) Multi Node Prediction, a stencil-level objective that predicts field values for a node's full local topology, enforcing spatial derivative consistency; (2) Temporal Correction, replacing unstable explicit schemes with a predictor-corrector via temporal Cross-Attention; and (3) Geometric Inductive Biases, leveraging 3D Rotary Positional Embeddings (RoPE) to robustly capture rotational symmetries in unstructured meshes. We evaluate this framework across three architectures (MeshGraphNet, Transolver, and a Transformer) on diverse physics datasets. Our approach yields consistent improvements in accuracy and stability, particularly in long-horizon rollouts, while producing latent representations that generalize to unseen subtasks such as Wall Shear Stress or Pressure prediction. Code is available at https://github.com/DonsetPG/graph-physics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for ML-based surrogates in CFD on unstructured meshes, identifying limitations in standard node-wise supervision and explicit Euler stepping. It proposes three innovations: (1) Multi-Node Prediction, a stencil-level loss that predicts values over a node's local topology to enforce spatial derivative consistency; (2) Temporal Correction, a predictor-corrector scheme using temporal cross-attention to replace explicit time-stepping; and (3) 3D Rotary Positional Embeddings to capture rotational symmetries. The framework is tested on MeshGraphNet, Transolver, and Transformer architectures across multiple physics datasets, claiming consistent gains in accuracy and long-horizon stability plus generalization of learned latents to unseen tasks such as wall-shear-stress and pressure prediction.
Significance. If the empirical gains are shown to stem from the proposed mechanisms rather than increased capacity or regularization, the work would usefully connect geometric deep learning with discrete numerical principles, potentially improving reliability of mesh-based simulators for stiff or long-time problems. The public code release and multi-architecture evaluation are positive features.
major comments (3)
- [Method (Multi Node Prediction subsection)] The central claim that Multi-Node Prediction enforces spatial derivative consistency (and thereby improves stability) is load-bearing yet unsupported by derivation. No section shows that minimizing the stencil-level objective implies matching of discrete gradients or fluxes at element interfaces, nor is there an analysis of the induced discrete operator.
- [Method (Temporal Correction subsection) and Experiments] The Temporal Correction mechanism is asserted to stabilize stiff dynamics without introducing new instabilities, but the manuscript provides no spectral-radius analysis, eigenvalue bounds, or ablation isolating the cross-attention corrector from the predictor. Long-horizon gains could arise from implicit regularization rather than the predictor-corrector structure.
- [Experiments and Results] The experimental section reports consistent improvements but does not supply quantitative metrics, error bars, dataset sizes, or fair ablations that isolate each innovation from baseline capacity increases. Without these, it is impossible to verify whether the architectural changes are the cause of the reported gains in accuracy, stability, or generalization.
minor comments (2)
- [Method] Notation for the stencil loss and the temporal attention mask should be defined explicitly with respect to the mesh connectivity.
- [Introduction] The abstract and introduction would benefit from a short table summarizing the three datasets and the exact baselines used for each architecture.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and describe the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [Method (Multi Node Prediction subsection)] The central claim that Multi-Node Prediction enforces spatial derivative consistency (and thereby improves stability) is load-bearing yet unsupported by derivation. No section shows that minimizing the stencil-level objective implies matching of discrete gradients or fluxes at element interfaces, nor is there an analysis of the induced discrete operator.
Authors: We agree that the current manuscript would benefit from a more explicit discussion of how the stencil-level objective relates to discrete gradient and flux consistency. The Multi-Node Prediction loss is constructed so that the model must produce coherent predictions across a node's local neighborhood, which by design encourages the learned update rule to respect local continuity properties similar to those enforced in finite-volume discretizations. We will revise the Multi-Node Prediction subsection to include a clearer explanation of the induced discrete operator and its consistency implications, together with any supporting analysis that can be derived. revision: yes
-
Referee: [Method (Temporal Correction subsection) and Experiments] The Temporal Correction mechanism is asserted to stabilize stiff dynamics without introducing new instabilities, but the manuscript provides no spectral-radius analysis, eigenvalue bounds, or ablation isolating the cross-attention corrector from the predictor. Long-horizon gains could arise from implicit regularization rather than the predictor-corrector structure.
Authors: We acknowledge that the manuscript currently lacks a spectral analysis of the learned time-stepping operator. The Temporal Correction module is intended to replace explicit Euler integration with a learned predictor-corrector that uses temporal cross-attention to produce a corrected state. We will add an ablation that isolates the contribution of the cross-attention corrector. While a complete eigenvalue analysis of the data-driven operator is difficult to obtain, we will expand the discussion to address possible regularization effects and the observed stability improvements in long-horizon rollouts. revision: partial
-
Referee: [Experiments and Results] The experimental section reports consistent improvements but does not supply quantitative metrics, error bars, dataset sizes, or fair ablations that isolate each innovation from baseline capacity increases. Without these, it is impossible to verify whether the architectural changes are the cause of the reported gains in accuracy, stability, or generalization.
Authors: We will substantially revise the Experiments and Results section to report quantitative metrics with error bars, explicit dataset sizes, and controlled ablations that match model capacity across variants. These additions will allow clearer isolation of the effects of Multi-Node Prediction, Temporal Correction, and 3D Rotary Positional Embeddings. revision: yes
Circularity Check
No circularity: innovations are new objectives and biases, not reductions to fitted inputs or self-citations.
full rationale
The paper's core claims rest on introducing Multi Node Prediction (stencil-level objective), Temporal Correction (predictor-corrector via cross-attention), and Geometric Inductive Biases (3D RoPE) as architectural and training changes to address node-wise supervision and explicit Euler issues. These are presented as proposals evaluated empirically on datasets for accuracy/stability gains and generalization, without any quoted equations showing a derived quantity reducing by construction to a fitted parameter, self-citation chain, or renamed input. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided text; the derivation chain is self-contained as empirical validation of new paradigms rather than tautological re-expression of priors.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unstructured meshes from CFD can be treated as graphs or sequences where local topology and temporal evolution obey the same continuity rules as finite-element or finite-volume discretizations.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
Learning the Dynamics of Physical Systems from Sparse Observations with Finite Element Networks , author =. International Conference on Learning Representations , year =
-
[2]
Yu, Youn-Yeol and Choi, Jeongwhan and Park, Jaehyeon and Lee, Kookjin and Park, Noseong , booktitle =
-
[3]
International Conference on Learning Representations , year =
Improving Long-Range Interactions in Graph Neural Simulators via Hamiltonian Dynamics , author =. International Conference on Learning Representations , year =
-
[4]
International Conference on Learning Representations , year =
Learning Flexible Body Collision Dynamics with Hierarchical Contact Mesh Transformer , author =. International Conference on Learning Representations , year =
-
[5]
International Conference on Learning Representations , year =
Janny, Steeven and B. International Conference on Learning Representations , year =
-
[6]
International Conference on Machine Learning , year =
Unisoma: A Unified Transformer-based Solver for Multi-Solid Systems , author =. International Conference on Machine Learning , year =
-
[7]
npj Digital Medicine , volume =
Physics constrained graph neural network for real time prediction of intracranial aneurysm hemodynamics , author =. npj Digital Medicine , volume =. 2026 , doi =
2026
-
[8]
Physics of Fluids , volume =
Fluid--structure interaction analysis of pulsatile flow in arterial aneurysms with physics-informed neural networks and computational fluid dynamics , author =. Physics of Fluids , volume =. 2025 , doi =
2025
-
[9]
Mechanics Research Communications , volume =
Enhanced Vascular Flow Simulations in Aortic Aneurysm via Physics-Informed Neural Networks and Deep Operator Networks , author =. Mechanics Research Communications , volume =
-
[10]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[11]
2021 , eprint=
Learning Mesh-Based Simulation with Graph Networks , author=. 2021 , eprint=
2021
-
[12]
2023 , eprint=
4D Gaussian Splatting for Real-Time Dynamic Scene Rendering , author=. 2023 , eprint=
2023
-
[13]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Feng, Jiarui and Chen, Yixin and Li, Fuhai and Sarkar, Anindya and Zhang, Muhan , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[14]
2023 , eprint=
Efficient Learning of Mesh-Based Physical Simulation with BSMS-GNN , author=. 2023 , eprint=
2023
-
[15]
2020 , eprint=
Learning to Simulate Complex Physics with Graph Networks , author=. 2020 , eprint=
2020
-
[16]
2023 , eprint=
GraphCast: Learning skillful medium-range global weather forecasting , author=. 2023 , eprint=
2023
-
[17]
2023 , eprint=
Adding Conditional Control to Text-to-Image Diffusion Models , author=. 2023 , eprint=
2023
-
[18]
2022 , eprint=
Hierarchical Text-Conditional Image Generation with CLIP Latents , author=. 2022 , eprint=
2022
-
[19]
2021 , eprint=
Learning Transferable Visual Models From Natural Language Supervision , author=. 2021 , eprint=
2021
-
[20]
Paul Garnier and Jonathan Viquerat and Jean Rabault and Aurélien Larcher and Alexander Kuhnle and Elie Hachem , keywords =. A review on deep reinforcement learning for fluid mechanics , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.compfluid.2021.104973 , url =
-
[21]
Direct shape optimization through deep reinforcement learning , journal =
Jonathan Viquerat and Jean Rabault and Alexander Kuhnle and Hassan Ghraieb and Aurélien Larcher and Elie Hachem , keywords =. Direct shape optimization through deep reinforcement learning , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.jcp.2020.110080 , url =
-
[22]
2023 , eprint=
Proposal for Numerical Benchmarking of Fluid-Structure Interaction in Cerebral Aneurysms , author=. 2023 , eprint=
2023
-
[23]
Enhancement of cerebrovascular 4D flow MRI velocity fields using machine learning and computational fluid dynamics simulation data , volume =
Rutkowski, David and Roldán-Alzate, Alejandro and Johnson, Kevin , year =. Enhancement of cerebrovascular 4D flow MRI velocity fields using machine learning and computational fluid dynamics simulation data , volume =. Scientific Reports , doi =
-
[24]
and Goetz, Aurèle and Rico, P
Hachem, Elie and Meliga, P. and Goetz, Aurèle and Rico, P. and Viquerat, J. and Larcher, Aurélien and Valette, R. and Sanches, Augusto and Lannelongue, V. and Ghraieb, H. and Nemer, Ramy and Ozpeynirci, Y. and Liebig, Thomas , year =. Reinforcement learning for patient-specific optimal stenting of intracranial aneurysms , volume =. Scientific Reports , doi =
-
[25]
and Livesu, M
Mancinelli, C. and Livesu, M. and Puppo, E. , year =. Smart Tools and Apps for Graphics - Eurographics Italian Chapter Conference , editor =
-
[26]
Improved denois- ing diffusion probabilistic models.arXiv preprint arXiv:2102.09672,
Alex Nichol and Prafulla Dhariwal , title =. CoRR , volume =. 2021 , url =. 2102.09672 , timestamp =
-
[27]
Parameter-Efficient Transfer Learning for NLP
Neil Houlsby and Andrei Giurgiu and Stanislaw Jastrzebski and Bruna Morrone and Quentin de Laroussilhe and Andrea Gesmundo and Mona Attariyan and Sylvain Gelly , title =. CoRR , volume =. 2019 , url =. 1902.00751 , timestamp =
work page Pith review arXiv 2019
-
[28]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Tero Karras and Timo Aila and Samuli Laine and Jaakko Lehtinen , title =. CoRR , volume =. 2017 , url =. 1710.10196 , timestamp =
work page internal anchor Pith review arXiv 2017
-
[29]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , journal =. 2021 , url =. 2106.09685 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Zhang and Alexander Sax and Amir Zamir and Leonidas J
Jeffrey O. Zhang and Alexander Sax and Amir Zamir and Leonidas J. Guibas and Jitendra Malik , title =. CoRR , volume =. 2019 , url =. 1912.13503 , timestamp =
-
[31]
Arun Mallya and Svetlana Lazebnik , title =. CoRR , volume =. 2017 , url =. 1711.05769 , timestamp =
-
[32]
Frontiers in Bioengineering and Biotechnology , VOLUME=
Goetz, Aurèle and Jeken-Rico, Pablo and Pelissier, Ugo and Chau, Yves and Sédat, Jacques and Hachem, Elie , TITLE=. Frontiers in Bioengineering and Biotechnology , VOLUME=. 2024 , URL=. doi:10.3389/fbioe.2024.1433811 , ISSN=
-
[33]
Arun Mallya and Svetlana Lazebnik , title =. CoRR , volume =. 2018 , url =. 1801.06519 , timestamp =
-
[34]
Overcoming catastrophic forgetting with hard attention to the task , journal =
Joan Serr. Overcoming catastrophic forgetting with hard attention to the task , journal =. 2018 , url =. 1801.01423 , timestamp =
-
[35]
Jonathan Tompson and Kristofer Schlachter and Pablo Sprechmann and Ken Perlin , title =. CoRR , volume =. 2016 , url =. 1607.03597 , timestamp =
-
[36]
Interaction networks for learning about objects, relations and physics.arXiv:1612.00222,
Peter W. Battaglia and Razvan Pascanu and Matthew Lai and Danilo Jimenez Rezende and Koray Kavukcuoglu , title =. CoRR , volume =. 2016 , url =. 1612.00222 , timestamp =
-
[37]
Giovanni Calzolari and Wei Liu , keywords =. Deep learning to replace, improve, or aid CFD analysis in built environment applications: A review , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.buildenv.2021.108315 , url =
-
[38]
APL Machine Learning , volume =
Patil, Aakash and Viquerat, Jonathan and Hachem, Elie , title = ". APL Machine Learning , volume =. 2023 , month =. doi:10.1063/5.0152212 , url =
-
[39]
2020 , eprint=
Deep Graph Library: A Graph-Centric, Highly-Performant Package for Graph Neural Networks , author=. 2020 , eprint=
2020
-
[40]
2021 , eprint=
Rethinking Graph Transformers with Spectral Attention , author=. 2021 , eprint=
2021
-
[41]
2021 , eprint=
A Generalization of Transformer Networks to Graphs , author=. 2021 , eprint=
2021
-
[42]
2024 , eprint=
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models , author=. 2024 , eprint=
2024
-
[43]
2019 , eprint=
Root Mean Square Layer Normalization , author=. 2019 , eprint=
2019
-
[44]
Nils Thuerey and Konstantin Weissenow and Harshit Mehrotra and Nischal Mainali and Lukas Prantl and Xiangyu Hu , title =. CoRR , volume =. 2018 , url =. 1810.08217 , timestamp =
-
[45]
U-net architectures for fast prediction of incompressible laminar flows. arXiv e-prints , keywords =. doi:10.48550/arXiv.1910.13532 , archivePrefix =. 1910.13532 , primaryClass =
-
[46]
, year =
Rinkel GJ, Djibuti M, Algra A, van Gijn J. , year =. Prevalence and risk of rupture of intracranial aneurysms: a systematic review. , doi =
-
[47]
, year =
Wiebers, David O et al. , year =. Unruptured intracranial aneurysms: natural history, clinical outcome, and risks of surgical and endovascular treatment , doi =
-
[48]
Fast Virtual Stenting with Active Contour Models in Intracranical Aneurysm , volume =
Zhong, Jingru and Long, Yunling and Yan, Huagang and Meng, Qianqian and Zhao, Jing and Zhang, Ying and Yang, Xinjian and Li, Haiyun , year =. Fast Virtual Stenting with Active Contour Models in Intracranical Aneurysm , volume =. Scientific Reports , doi =
-
[49]
Frontiers in Physiology , VOLUME=
Bisighini, Beatrice and Aguirre, Miquel and Biancolini, Marco Evangelos and Trovalusci, Federica and Perrin, David and Avril, Stéphane and Pierrat, Baptiste , TITLE=. Frontiers in Physiology , VOLUME=. 2023 , URL=. doi:10.3389/fphys.2023.1148540 , ISSN=
-
[50]
Frontiers in Medical Technology , VOLUME=
Avril, Stéphane , TITLE=. Frontiers in Medical Technology , VOLUME=. 2023 , URL=. doi:10.3389/fmedt.2023.1304223 , ISSN=
-
[51]
Journalism quarterly , keywords =
Taylor, Wilson L , biburl =. Journalism quarterly , keywords =
-
[52]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin and Ming. CoRR , volume =. 2018 , url =. 1810.04805 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Jascha Sohl. Deep Unsupervised Learning using Nonequilibrium Thermodynamics , journal =. 2015 , url =. 1503.03585 , timestamp =
work page internal anchor Pith review arXiv 2015
-
[54]
Guerreiro, António Loison, Duarte M
CroissantLLM: A Truly Bilingual French-English Language Model. arXiv e-prints , keywords =. doi:10.48550/arXiv.2402.00786 , archivePrefix =. 2402.00786 , primaryClass =
-
[55]
3d gaussian splatting for real-time radiance field rendering
3D Gaussian Splatting for Real-Time Radiance Field Rendering. arXiv e-prints , keywords =. doi:10.48550/arXiv.2308.04079 , archivePrefix =. 2308.04079 , primaryClass =
-
[56]
Mistral 7B. arXiv e-prints , keywords =. doi:10.48550/arXiv.2310.06825 , archivePrefix =. 2310.06825 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825
-
[57]
Radford, Alec and Narasimhan, Karthik and Salimans, Tim and Sutskever, Ilya , biburl =
-
[58]
Language Models are Unsupervised Multitask Learners , url =
Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya , biburl =. Language Models are Unsupervised Multitask Learners , url =
-
[59]
Relational inductive biases, deep learning, and graph networks
Peter W. Battaglia and Jessica B. Hamrick and Victor Bapst and Alvaro Sanchez. Relational inductive biases, deep learning, and graph networks , journal =. 2018 , url =. 1806.01261 , timestamp =
work page internal anchor Pith review arXiv 2018
-
[60]
Multiscale MeshGraphNets.arXiv preprint arXiv:2210.00612,
MultiScale MeshGraphNets. arXiv e-prints , keywords =. doi:10.48550/arXiv.2210.00612 , archivePrefix =. 2210.00612 , primaryClass =
-
[61]
Strategies for pre-training graph neural networks.arXiv preprint arXiv:1905.12265, 2019
Weihua Hu and Bowen Liu and Joseph Gomes and Marinka Zitnik and Percy Liang and Vijay S. Pande and Jure Leskovec , title =. CoRR , volume =. 2019 , url =. 1905.12265 , timestamp =
-
[62]
Qiaoyu Tan and Ninghao Liu and Xiao Huang and Rui Chen and Soo. CoRR , volume =. 2022 , url =. 2201.02534 , timestamp =
-
[63]
Ziniu Hu and Yuxiao Dong and Kuansan Wang and Kai. CoRR , volume =. 2020 , url =. 2006.15437 , timestamp =
-
[64]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Learning to Pre-train Graph Neural Networks , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v35i5.16552 , abstractNote=
-
[65]
, biburl =
Narain, Rahul and Samii, Armin and O'Brien, James F. , biburl =. Adaptive anisotropic remeshing for cloth simulation. , url =. ACM Trans. Graph. , keywords =
-
[66]
Comsol multiphysics® , title =
-
[67]
DOLFINx: the next generation FEniCS problem solving environment.Zenodo, 2023
Baratta, Igor A. and Dean, Joseph P. and Dokken, J. doi:10.5281/zenodo.10447666 , year =
-
[68]
ACM Transactions on Mathematical Software , year =
Construction of arbitrary order finite element degree-of-freedom maps on polygonal and polyhedral cell meshes , author =. ACM Transactions on Mathematical Software , year =. doi:10.1145/3524456 , pages =
-
[69]
Santurkar, S., Tsipras, D., Ilyas, A., and M ˛ adry, A
Basix: a runtime finite element basis evaluation library , author =. Journal of Open Source Software , year =. doi:10.21105/joss.03982 , pages =
-
[70]
2014 , volume =
Unified Form Language: A domain-specific language for weak formulations of partial differential equations , author =. 2014 , volume =
2014
-
[71]
and Blechta, Jan and Hake, Johan and Johansson, August and Kehlet, Benjamin and Logg, Anders and Richardson, Chris N
Alnaes, Martin S. and Blechta, Jan and Hake, Johan and Johansson, August and Kehlet, Benjamin and Logg, Anders and Richardson, Chris N. and Ring, Johannes and Rognes, Marie E. and Wells, Garth N. , journal =. The. 2015 , volume =
2015
-
[72]
2012 , doi =
Automated Solution of Differential Equations by the Finite Element Method , author =. 2012 , doi =
2012
-
[73]
, journal =
Logg, Anders and Wells, Garth N. , journal =. 2010 , volume =
2010
-
[74]
and Hake, Johan , year =
Logg, Anders and Wells, Garth N. and Hake, Johan , year =. Automated Solution of Differential Equations by the Finite Element Method , publisher =
-
[75]
2006 , volume =
A Compiler for Variational Forms , author =. 2006 , volume =
2006
-
[76]
2012 , booktitle =
Logg, Anders and. 2012 , booktitle =
2012
-
[77]
2010 , volume =
Optimisations for Quadrature Representations of Finite Element Tensors Through Automated Code Generation , author =. 2010 , volume =
2010
-
[78]
Kirby, Robert C. , journal =. Algorithm 839:. 2004 , volume =. doi:10.1145/1039813.1039820 , pages =
-
[79]
, year =
Kirby, Robert C. , year =. Automated Solution of Differential Equations by the Finite Element Method , publisher =
-
[80]
and Demmel, J
Adams, M. and Demmel, J. , booktitle=. Parallel Multigrid Solver for 3D Unstructured Finite Element Problems , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.