Recognition: unknown
The Reasoning Trap: An Information-Theoretic Bound on Closed-System Multi-Step LLM Reasoning
Pith reviewed 2026-05-10 15:49 UTC · model grok-4.3
The pith
Closed-system LLM reasoning degrades evidence information over iterative steps due to the data processing inequality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
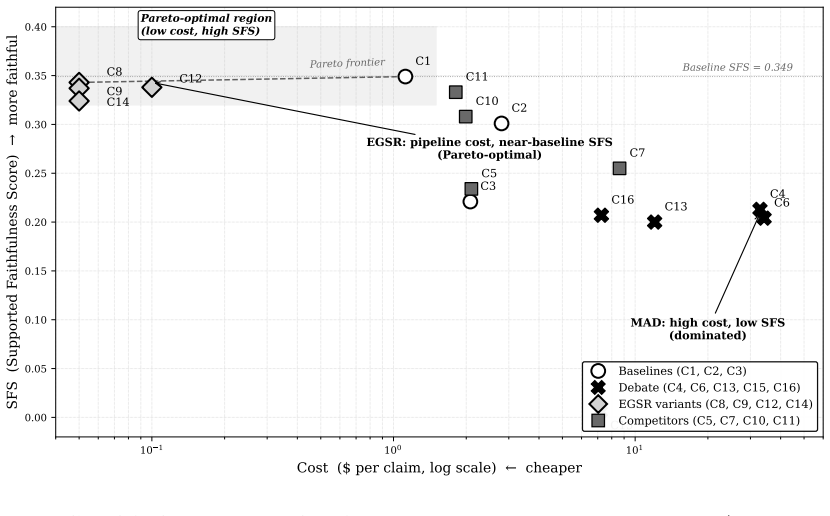
The central claim is that under standard multi-agent debate, the sequence of outputs forms a Markov chain with respect to the initial evidence E, implying by the Data Processing Inequality that the expected mutual information between E and the output at step t+1 is at most that at step t. This bound explains the Reasoning Trap, where faithfulness metrics decline even as accuracy is preserved. Experiments across conditions confirm that closed protocols like majority-vote debate reduce supported faithfulness scores sharply, while an evidence-grounded inquiry method recovers nearly all baseline performance.
What carries the argument
The DPI Bound (Theorem 1), which applies the Data Processing Inequality to the Markov chain E to O zero to O one and onward in closed-system reasoning to show non-increasing mutual information with evidence.
Load-bearing premise
The outputs produced in standard multi-agent debate form a Markov chain relative to the initial evidence, with no hidden shared state that would allow later outputs to retain more information about the evidence than earlier ones.
What would settle it
A demonstration of a closed-system protocol where the measured mutual information or supported faithfulness score increases or remains constant over multiple steps, while strictly satisfying the conditional independence of the Markov chain.
Figures
















read the original abstract
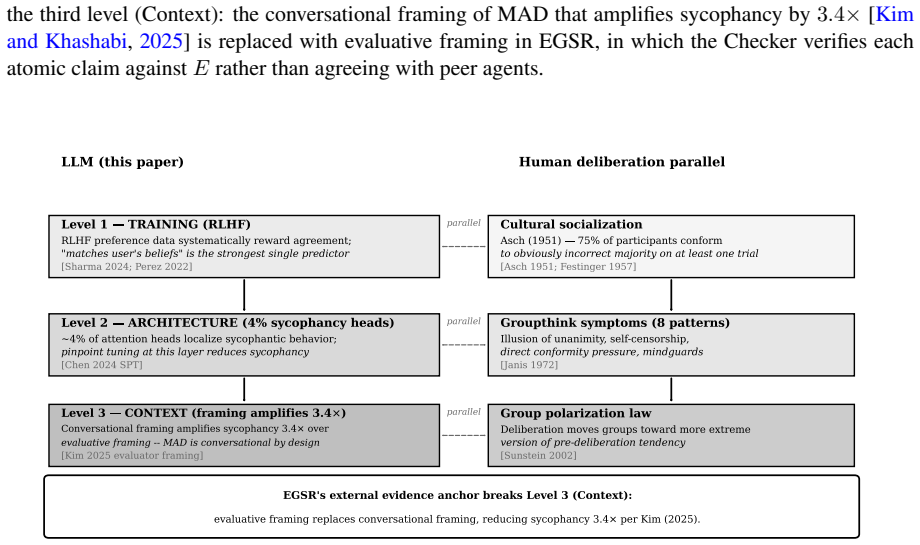
When copies of the same language model are prompted to debate, they produce diverse phrasings of one perspective rather than diverse perspectives. Multi-agent debate (MAD), and more broadly closed-system reasoning where agents iteratively transform each other's outputs, tends to preserve answer accuracy while degrading the reasoning behind those answers. We name the multi-agent case the Debate Trap and the broader phenomenon the Reasoning Trap, offering a programmatic theory of evidence-grounded reasoning failure.The framework has three parts: (i) SFS (Supported Faithfulness Score), a claim-level metric verifying decomposed atomic claims against provided evidence (decomposer-invariant rankings: Spearman rho=1.0); (ii) EGSR (Evidence-Grounded Socratic Reasoning), replacing adversarial argumentation with evidence-grounded inquiry; (iii) Theorem 1 (DPI Bound): under standard MAD, the chain E -> O^0 -> O^1 -> ... is Markov, and the Data Processing Inequality implies E[I(E;O^{t+1})] <= E[I(E;O^t)]. Three companion results -- open-system recovery (Theorem 2), EGSR accumulation (Lemma 2), and vote-aggregation floor (Proposition 1) -- partition multi-step LLM reasoning by its information-theoretic relationship to E. Across 16 conditions on SciFact (300 claims) and FEVER (1,000 claims), DebateCV (C13) preserves 88% of baseline accuracy while SFS drops 43%; majority-vote MAD (C15) reduces SFS to 1.7% of baseline (p < 10^{-6}, d = -0.96); EGSR recovers 98%. An R6 cohort study (Korean n=10x30 FEVER; English n=3x200 SciFact) finds inter-rater Fleiss kappa <= +0.018 with 0.8-1.4 Likert intra-rater shifts across language and domain -- the human agreement that faithfulness metrics have been calibrated against is not itself stable. We offer one falsifiable conjecture: any closed-system reasoning protocol preserving Theorem 1's Markov structure is, in expectation, subject to the same DPI bound.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multi-agent debate (MAD) and closed-system iterative LLM reasoning exhibit a 'Debate Trap' and broader 'Reasoning Trap' in which answer accuracy is preserved while faithfulness of reasoning to initial evidence E degrades. It introduces the Supported Faithfulness Score (SFS) as a claim-level, decomposer-invariant metric (Spearman rho=1.0), Evidence-Grounded Socratic Reasoning (EGSR) as an alternative protocol, and Theorem 1 asserting that under standard MAD the chain E → O^0 → O^1 → … is Markov so that the Data Processing Inequality yields E[I(E;O^{t+1})] ≤ E[I(E;O^t)]. Experiments across 16 conditions on SciFact (300 claims) and FEVER (1,000 claims) show DebateCV preserves 88% accuracy while SFS drops 43%, majority-vote MAD reduces SFS to 1.7% of baseline (p<10^{-6}, d=-0.96), and EGSR recovers 98%; a human study reports Fleiss kappa ≤0.018. A falsifiable conjecture generalizes the bound to any closed-system protocol preserving the Markov structure.
Significance. If the Markov assumption is shown to hold, the work supplies a principled information-theoretic account of evidence-grounding failure in iterative LLM reasoning together with a practical recovery method (EGSR) and a falsifiable conjecture. The reported effect sizes are large and statistically significant, SFS rankings are decomposer-invariant, and the partition into open-system recovery (Theorem 2), accumulation (Lemma 2), and vote floor (Proposition 1) is cleanly stated. The near-zero human agreement, however, limits the external calibration of SFS.
major comments (2)
- [Theorem 1] Theorem 1: The DPI application requires the Markov property O^{t+1} ⊥ E | O^t. Standard MAD re-prompts each agent with the original evidence E plus debate history, introducing an explicit dependence on E that violates the conditional independence. The manuscript asserts the chain is Markov under 'standard MAD' without verification or prompting details that would preserve the property. This assumption is load-bearing for the central bound and the conjecture; observed SFS degradation may instead arise from prompt-length or attention effects.
- [Human Evaluation / R6 cohort study] Human Evaluation: The reported Fleiss kappa ≤ +0.018 (with 0.8–1.4 Likert intra-rater shifts) indicates near-chance agreement. This instability questions the reliability of the human labels used to calibrate SFS, even though the metric itself shows perfect rank invariance across decomposers.
minor comments (1)
- [Abstract] The cohort-study notation 'n=10x30 FEVER; English n=3x200 SciFact' is ambiguous and should be expanded for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, with clarifications and proposed revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Theorem 1] Theorem 1: The DPI application requires the Markov property O^{t+1} ⊥ E | O^t. Standard MAD re-prompts each agent with the original evidence E plus debate history, introducing an explicit dependence on E that violates the conditional independence. The manuscript asserts the chain is Markov under 'standard MAD' without verification or prompting details that would preserve the property. This assumption is load-bearing for the central bound and the conjecture; observed SFS degradation may instead arise from prompt-length or attention effects.
Authors: We thank the referee for identifying this critical assumption. We acknowledge that re-including the original evidence E in subsequent prompts technically introduces a direct dependence, which can violate the strict conditional independence required for the Markov chain. In our experimental protocols, the iterative generation conditions primarily on the prior output O^t and debate history, but E remains in context. We will revise the manuscript to: (1) include the exact prompting templates in an appendix, (2) qualify Theorem 1 as applying under the approximation where new information from E is not actively extracted beyond the initial step, and (3) add a discussion of potential confounds such as prompt length or attention dilution. The empirical SFS degradation remains robust across conditions and supports the broader Reasoning Trap claim even if the bound is approximate. This constitutes a partial revision. revision: partial
-
Referee: [Human Evaluation / R6 cohort study] Human Evaluation: The reported Fleiss kappa ≤ +0.018 (with 0.8–1.4 Likert intra-rater shifts) indicates near-chance agreement. This instability questions the reliability of the human labels used to calibrate SFS, even though the metric itself shows perfect rank invariance across decomposers.
Authors: We agree that the near-zero Fleiss kappa (≤ +0.018) and intra-rater shifts demonstrate instability in human judgments of faithfulness; this is presented in the paper as a substantive result of the R6 study, showing that human agreement on reasoning faithfulness is unreliable across languages and domains. SFS itself is not calibrated or trained on these human labels. Its validation rests on the decomposer-invariant rank correlation (Spearman rho = 1.0) and its ability to track the predicted information loss in the experiments. We will expand the discussion section to clarify that the human study underscores the value of automated, objective metrics like SFS rather than serving as its calibration source. No changes to the reported SFS results or core claims are needed. This constitutes a partial revision to improve interpretation. revision: partial
Circularity Check
No circularity: Theorem 1 applies standard DPI to an asserted Markov modeling assumption
full rationale
The paper's derivation chain consists of introducing SFS as an empirical metric (with reported Spearman rho=1.0 for decomposer invariance), defining EGSR as an alternative protocol, and stating Theorem 1 as the application of the known Data Processing Inequality to the modeling claim that standard MAD produces a Markov chain E → O^t. This is not a self-definitional reduction, fitted parameter renamed as prediction, self-citation load-bearing step, uniqueness theorem, smuggled ansatz, or renamed known result; the Markov property is presented as an assumption whose preservation makes the bound falsifiable via the paper's own conjecture. No equations reduce to their inputs by construction, and the central information-theoretic claim remains independent of the paper's own fitted values or prior self-references.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The sequence of outputs under standard multi-agent debate forms a Markov chain conditioned on the initial evidence E.
- standard math The Data Processing Inequality applies to the mutual information quantities I(E; O^t) in this LLM output chain.
invented entities (3)
-
Supported Faithfulness Score (SFS)
no independent evidence
-
Evidence-Grounded Socratic Reasoning (EGSR)
no independent evidence
-
Reasoning Trap / Debate Trap
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AI safety via debate , author=. arXiv preprint arXiv:1805.00899 , year=
work page internal anchor Pith review arXiv
-
[2]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author=. arXiv preprint arXiv:2305.14325 , year=
work page internal anchor Pith review arXiv
-
[3]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author=. arXiv preprint arXiv:2305.19118 , year=
work page internal anchor Pith review arXiv
-
[4]
arXiv preprint arXiv:2402.06634 , year=
SocraSynth: Multi-LLM Reasoning with Conditional Statistics , author=. arXiv preprint arXiv:2402.06634 , year=
-
[5]
arXiv preprint arXiv:2312.01823 , year=
Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication , author=. arXiv preprint arXiv:2312.01823 , year=
-
[6]
arXiv preprint , year=
CodeCoT: Multi-Agent Code Generation through Chain-of-Thought Debate , author=. arXiv preprint , year=
-
[7]
MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning , author=. arXiv preprint arXiv:2311.10537 , year=
-
[8]
More Agents Is All You Need , author=. arXiv preprint arXiv:2402.05120 , year=
- [9]
-
[10]
arXiv preprint arXiv:2505.22960 , year=
Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness , author=. arXiv preprint arXiv:2505.22960 , year=
-
[11]
On Scalable Oversight with Weak
Kenton, Zachary and Siegel, Noah and others , journal=. On Scalable Oversight with Weak
-
[12]
arXiv preprint arXiv:2503.15904 , year=
Does Debate Actually Help Humans Identify the Truth? , author=. arXiv preprint arXiv:2503.15904 , year=
-
[13]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Debate or Vote: Which Yields Better Decisions in Multi-Agent Large Language Models? , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[15]
arXiv preprint arXiv:2603.06801 , year=
Breaking the Martingale Curse: Multi-Agent Debate via Asymmetric Cognitive Potential Energy , author=. arXiv preprint arXiv:2603.06801 , year=
-
[16]
Demystifying Multi-Agent Debate: The Role of Confidence and Diversity , author=. arXiv preprint arXiv:2601.19921 , year=
-
[17]
Stay Focused: Problem Drift in Multi-Agent Debate
Stay Focused: Problem Drift in Multi-Agent Debate , author=. arXiv preprint arXiv:2502.19559 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang Wei and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh , booktitle=
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Long-form Factuality in Large Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[20]
Song, Yixiao and Pagnoni, Artidoro and Park, Jieyu and Iyyer, Mohit , journal=
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[22]
International Conference on Learning Representations (ICLR) , year=
Chain-of-Thought Reasoning In The Wild Is Not Always Faithful , author=. International Conference on Learning Representations (ICLR) , year=
-
[23]
arXiv preprint arXiv:2402.13950 , year=
Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning , author=. arXiv preprint arXiv:2402.13950 , year=
-
[24]
2026 , note=
Shen, Xu and Wang, Song and Tan, Zhen and Yao, Laura and Zhao, Xinyu and Xu, Kaidi and Wang, Xin and Chen, Tianlong , booktitle=. 2026 , note=
2026
-
[25]
On the Hardness of Faithful Chain-of-Thought Reasoning in Large Language Models , author=. arXiv preprint arXiv:2406.10625 , year=
-
[26]
International Conference on Learning Representations (ICLR) , year=
Towards Understanding Sycophancy in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[27]
Pitre, Priya and Ramakrishnan, Naren and Wang, Xuan , booktitle=
-
[28]
When Identity Skews Debate: Anonymization for Bias-Reduced Multi-Agent Reasoning
When Identity Skews Debate: Anonymization for Bias-Reduced Multi-Agent Reasoning , author=. arXiv preprint arXiv:2510.07517 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Challenging the Evaluator:
Kim, Jaehyuk and Khashabi, Daniel , journal=. Challenging the Evaluator:
-
[30]
Discovering Language Model Behaviors with Model-Written Evaluations
Discovering Language Model Behaviors with Model-Written Evaluations , author=. arXiv preprint arXiv:2212.09251 , year=
work page internal anchor Pith review arXiv
-
[31]
arXiv preprint , year=
Peacemaker or Troublemaker: Sycophancy in Multi-Agent Debate , author=. arXiv preprint , year=
-
[32]
From Yes-Men to Truth-Tellers: Addressing Sycophancy in
Chen, Wei and others , booktitle=. From Yes-Men to Truth-Tellers: Addressing Sycophancy in
-
[33]
arXiv preprint arXiv:2305.14999 , year=
The Art of Socratic Questioning: Recursive Thinking with Large Language Models , author=. arXiv preprint arXiv:2305.14999 , year=
-
[34]
He, Hangfeng and Zhang, Hongming and Roth, Dan , booktitle=
-
[35]
2025 , note=
Shi, Zhen and others , journal=. 2025 , note=
2025
-
[36]
Proceedings of the Association for Computational Linguistics (ACL) , year=
Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations , author=. Proceedings of the Association for Computational Linguistics (ACL) , year=
-
[37]
arXiv preprint , year=
Improving Socratic Question Generation using Data Augmentation and Preference Optimization , author=. arXiv preprint , year=
-
[38]
Wu, Jiying and Li, Yue and Li, Subhadeep , journal=. Can
-
[39]
NeurIPS Workshop , year=
Task Complexity in Multi-Agent Debate , author=. NeurIPS Workshop , year=
-
[40]
arXiv preprint , year=
Talk Isn't Always Cheap: Multi-Agent Debate Harms Reasoning , author=. arXiv preprint , year=
-
[41]
Evaluating
Kim, Seongho and others , journal=. Evaluating
-
[42]
Koupaee, Mahnaz and others , journal=
-
[43]
Han, Jie and others , journal=
-
[44]
Proceedings of ACL , year=
Direct Evaluation of Chain-of-Thought in Multi-hop Reasoning with Knowledge Graphs , author=. Proceedings of ACL , year=
-
[45]
arXiv preprint , year=
Chain-of-Thought Obscures Hallucination Cues for Humans , author=. arXiv preprint , year=
-
[46]
arXiv preprint , year=
Walk The Talk: Measuring the Faithfulness of Generated Reasoning , author=. arXiv preprint , year=
-
[47]
arXiv preprint , year=
Robust Answers, Fragile Logic: Decoupling Reasoning Ability from Reasoning Faithfulness , author=. arXiv preprint , year=
-
[48]
Mittal, Avni and Arike, Rauno , journal=
-
[49]
arXiv preprint arXiv:2601.02170 , year=
Streaming Hallucination Detection in Long Chain-of-Thought Reasoning , author=. arXiv preprint arXiv:2601.02170 , year=
-
[50]
Wanner, Jonas and others , journal=
-
[51]
Nie, Yuxia and others , journal=
-
[52]
Rajendhran, Anirudh and others , journal=
-
[53]
Lage, Thomas and others , journal=
-
[54]
Akbar, Zaid and others , journal=
-
[55]
Scalable
Brown-Cohen, Jonah and Irving, Geoffrey and Piliouras, Georgios , journal=. Scalable
-
[56]
arXiv preprint , year=
A Safety Case for Debate-Based Alignment , author=. arXiv preprint , year=
-
[57]
AAAI Conference on Artificial Intelligence , year=
Debate Helps Weak-to-Strong Generalization , author=. AAAI Conference on Artificial Intelligence , year=
-
[58]
ICML MI Workshop , year=
Winning Arguments: What Makes Debaters Convincing and Judges Accurate , author=. ICML MI Workshop , year=
-
[59]
Proceedings of EMNLP , pages=
Fact or Fiction: Verifying Scientific Claims , author=. Proceedings of EMNLP , pages=
-
[60]
Thorne, James and Vlachos, Andreas and Christodoulopoulos, Christos and Mittal, Arpit , booktitle=
-
[61]
Proceedings of NAACL , year=
Generating Literal and Implied Subquestions to Fact-Check Complex Claims , author=. Proceedings of NAACL , year=
-
[62]
Kamoi, Ryo and Goyal, Tanya and Rodriguez, Juan Diego and Durrett, Greg , booktitle=
-
[63]
Schlichtkrull, Michael and Deng, Zhijiang and Vlachos, Andreas , journal=
-
[64]
Constitutional
Bai, Yuntao and others , journal=. Constitutional
-
[65]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. arXiv preprint arXiv:2303.11366 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
Biometrics , volume=
The measurement of observer agreement for categorical data , author=. Biometrics , volume=. 1977 , publisher=
1977
-
[67]
Educational and Psychological Measurement , volume=
A coefficient of agreement for nominal scales , author=. Educational and Psychological Measurement , volume=. 1960 , publisher=
1960
-
[68]
Psychological Bulletin , volume=
Measuring nominal scale agreement among many raters , author=. Psychological Bulletin , volume=. 1971 , publisher=
1971
-
[69]
Guo, Han and others , journal=
-
[70]
Yu, Qichao and others , journal=
-
[71]
Adaptive Data Flywheel:
Shukla, Anand and others (NVIDIA) , journal=. Adaptive Data Flywheel:
-
[72]
Metacognition for Safe
Walker, Daniel and others , journal=. Metacognition for Safe
-
[73]
Yang, Yuhao and others (SJTU+OPPO) , journal=
-
[74]
Kargupta, Priyanka and Han, Ishika and others , booktitle=
-
[75]
Sleeper Agents: Training Deceptive
Hubinger, Evan and others , journal=. Sleeper Agents: Training Deceptive
-
[76]
Unmasking the Shadows of
Guo, Linke , journal=. Unmasking the Shadows of
-
[77]
Advances in Neural Information Processing Systems , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
ICLR , year=
Measuring Massive Multitask Language Understanding , author=. ICLR , year=
-
[79]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Advances in Neural Information Processing Systems , volume=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.