Recognition: 2 theorem links
· Lean TheoremSplitZip: Ultra Fast Lossless KV Compression for Disaggregated LLM Serving
Pith reviewed 2026-05-12 01:10 UTC · model grok-4.3
The pith
SplitZip achieves over 600 GB/s lossless KV cache compression on GPUs by encoding frequent exponents with fixed-length codes and routing rare ones through a sparse escape stream.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
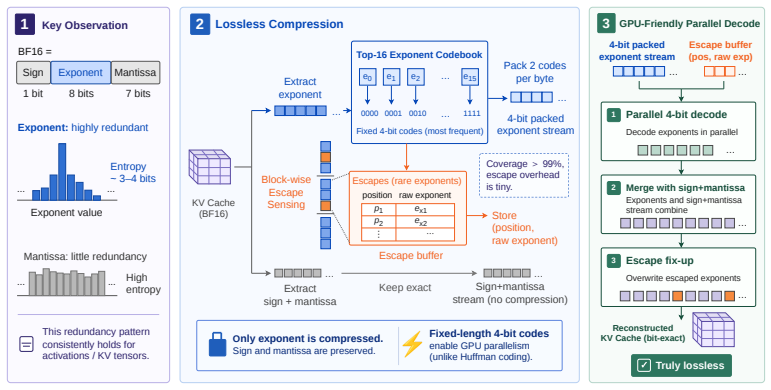
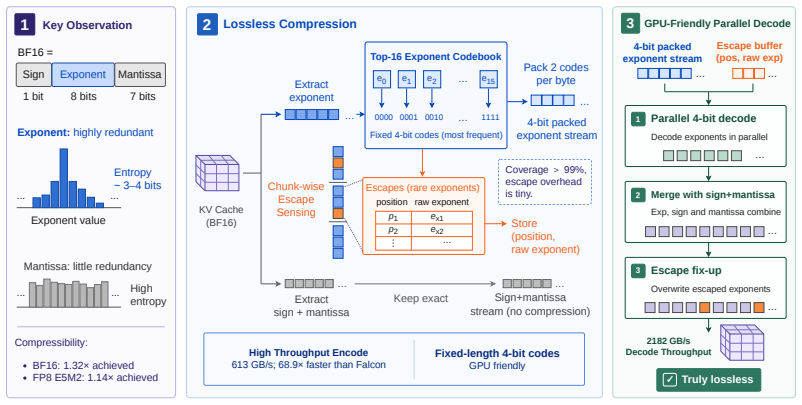
SplitZip preserves KV tensors bitwise by encoding the most frequent exponent values from an offline-calibrated top-16 codebook with fixed-length codes and routing rare exponents through a sparse escape stream of (position, value) pairs. The resulting dense-plus-sparse structure runs at high throughput on GPUs without online histogramming or variable-length decoding.
What carries the argument
The offline top-16 exponent codebook that supplies fixed-length codes for the dense path together with a sparse escape correction stream for rare values.
If this is right
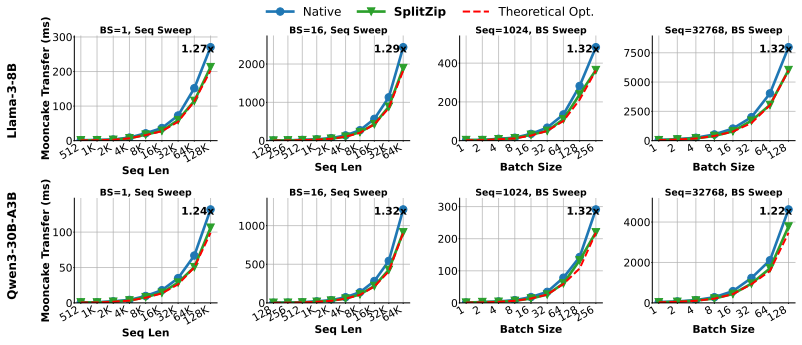
- KV cache transfers between prefill and decode workers become up to 1.32 times faster while remaining exactly lossless.
- Time-to-first-token improves by up to 1.30 times in disaggregated serving setups.
- Request throughput rises by 1.23 times because the transfer step no longer dominates latency.
- The same exponent-coding approach yields up to 1.14 times compression on FP8 KV caches relative to native E5M2 storage.
Where Pith is reading between the lines
- Disaggregated clusters could support longer contexts or higher concurrency by reducing the network bandwidth required for each request.
- Operators might lower the cost of high-bandwidth interconnects between prefill and decode nodes if the compression is adopted widely.
- Periodic recalibration of the codebook on representative production traces would be needed to keep performance stable across changing workloads.
Load-bearing premise
The distribution of exponents seen during online prefill will stay close enough to the offline top-16 calibration that most values receive short codes and the escape stream stays small.
What would settle it
Run SplitZip end-to-end on a long-context or agentic workload whose exponent distribution differs from the calibration set and check whether the measured compression ratio drops below 1.1 times or the transfer speedup disappears.
Figures

read the original abstract
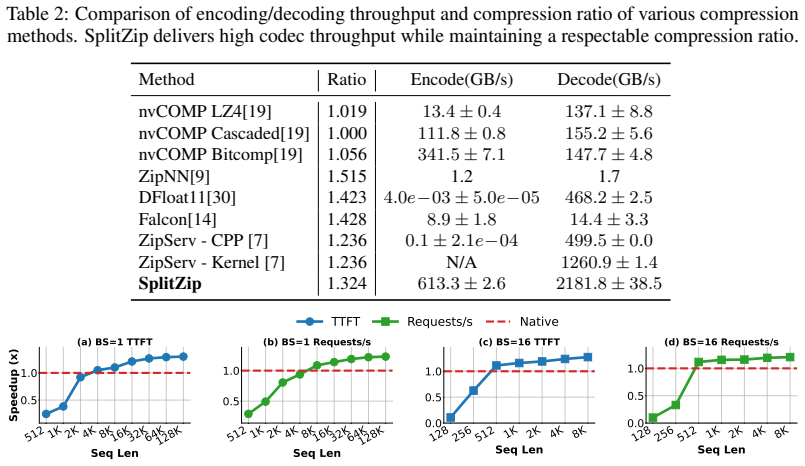
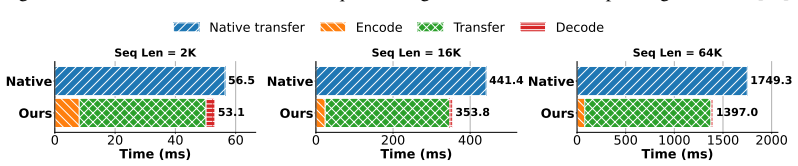
Contemporary systems serving large language models (LLMs) have adopted prefill-decode disaggregation to better load-balance between the compute-bound prefill phase and the memory-bound decode phase. Under this design, prefill workers generate a KV cache that must be transferred to decode workers before token generation can begin. With these workers residing on different physical systems, this transfer becomes a significant bottleneck to serving LLMs at scale. This bottleneck gets exacerbated for long-input and agentic workloads. Existing lossless codecs are not suited to this setting as they primarily target offline weight compression, run on the CPU, or use variable-length coding whose decompression is fast but compression is too slow to keep up with KV production during prefill. We introduce SplitZip, a GPU-friendly lossless compressor for KV cache transfer that preserves KV tensors bitwise and integrates into existing serving frameworks without changes to model execution. SplitZip exploits redundancy in floating-point exponents of KV activations, encoding the most frequent exponent values with fixed-length codes and routing rare exponents through a sparse escape stream of (position, value). An offline calibrated top-16 exponent codebook eliminates online-histogramming, while the regular dense path and sparse escape correction make both encoding and decoding efficient on GPUs. On real BF16 activation tensors, SplitZip achieves $613.3$ GB/s compression throughput and $2181.8$ GB/s decompression throughput, substantially outperforming prior lossless compressors on the latency-critical codec path. End-to-end transfer experiments show up to $1.32\times$ speedup for BF16 KV cache transfer, $1.30\times$ speedup for TTFT, and $1.23\times$ increase on Request Throughput. The same approach extends to FP8 KV caches, providing up to $1.14\times$ compression over native E5M2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SplitZip, a GPU-optimized lossless compressor for KV cache tensors in prefill-decode disaggregated LLM serving. It exploits observed redundancy in BF16 (and FP8) floating-point exponents by encoding the 16 most frequent values with a fixed 4-bit codebook calibrated offline and routing infrequent exponents through a sparse escape stream of (position, value) pairs. The design avoids online histogramming and variable-length coding to achieve high throughput on the critical compression path while preserving tensors bitwise and integrating into existing serving stacks without model changes. On real BF16 activation tensors it reports 613.3 GB/s compression and 2181.8 GB/s decompression throughput, yielding up to 1.32× KV transfer speedup, 1.30× TTFT improvement, and 1.23× request throughput increase; the same approach gives up to 1.14× compression for FP8 E5M2 caches.
Significance. If the offline top-16 codebook generalizes and escape overhead stays negligible across models and workloads, SplitZip would provide a practical, drop-in reduction in the KV transfer bottleneck that currently limits disaggregated serving for long-context and agentic workloads. The reported throughputs substantially exceed typical CPU-based lossless codecs and the GPU-friendly dense-plus-sparse structure is a clear engineering contribution. Reproducible end-to-end speedups on real tensors would be a useful data point for the community.
major comments (2)
- [Abstract and experimental evaluation] The headline speedups (1.32× transfer, 1.30× TTFT, 1.23× throughput) rest on the claim that an offline-calibrated top-16 exponent codebook keeps the sparse escape stream negligible on online prefill KV tensors. No escape-rate statistics, calibration corpus description, or sensitivity sweeps across models, layers, or context lengths are supplied; if escape density rises, both throughput and effective compression ratio degrade, undermining the central efficiency argument.
- [Method and evaluation sections] The lossless (bitwise-preserving) property is asserted for both the dense codebook path and the escape correction, yet the verification procedure—bit-exact tensor comparison, checksums, or test-suite coverage—is not described. This is load-bearing for the “lossless” claim and for any downstream correctness guarantees in serving systems.
minor comments (1)
- [Introduction / System overview] A small diagram or pseudocode snippet illustrating the data-flow between prefill worker, SplitZip encoder, network transfer, and decode worker would clarify integration without model changes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we provide point-by-point responses to the major comments and outline the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation] The headline speedups (1.32× transfer, 1.30× TTFT, 1.23× throughput) rest on the claim that an offline-calibrated top-16 exponent codebook keeps the sparse escape stream negligible on online prefill KV tensors. No escape-rate statistics, calibration corpus description, or sensitivity sweeps across models, layers, or context lengths are supplied; if escape density rises, both throughput and effective compression ratio degrade, undermining the central efficiency argument.
Authors: We agree with the referee that the manuscript would benefit from explicit escape-rate statistics and sensitivity analysis to support the efficiency claims. In the revised version, we will add these details to the experimental evaluation section. Specifically, we will describe the calibration corpus used for the offline top-16 codebook and present escape-rate measurements across different models, layers, and context lengths. We will also include sensitivity sweeps to demonstrate that the escape stream remains negligible under the evaluated conditions, thereby reinforcing the reported speedups without degradation. revision: yes
-
Referee: [Method and evaluation sections] The lossless (bitwise-preserving) property is asserted for both the dense codebook path and the escape correction, yet the verification procedure—bit-exact tensor comparison, checksums, or test-suite coverage—is not described. This is load-bearing for the “lossless” claim and for any downstream correctness guarantees in serving systems.
Authors: We acknowledge that the current manuscript does not detail the verification procedure for the lossless property. In the revised manuscript, we will expand the method section to describe our verification process, which involves bit-exact tensor comparisons between original and reconstructed KV caches, along with checksum validations and comprehensive test-suite coverage. This addition will substantiate the bitwise-preserving nature of both the dense codebook path and the escape correction mechanism. revision: yes
Circularity Check
No circularity; algorithmic design with offline calibration is self-contained
full rationale
The paper presents SplitZip as a direct GPU implementation that encodes frequent BF16 exponents via a fixed offline top-16 codebook and routes rare values through an explicit sparse escape stream of (position, value) pairs. This construction is described as an engineering choice based on observed exponent redundancy in KV tensors, with throughput numbers reported as measured results on real activation data rather than any derived prediction. No equations reduce a claimed result to its own fitted parameters by construction, no self-citation supplies a load-bearing uniqueness theorem, and the calibration step is a one-time preprocessing step external to the online compression path. The derivation chain therefore contains no self-definitional, fitted-input, or ansatz-smuggling reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- top-16 exponent codebook
axioms (1)
- domain assumption KV activations in BF16 and FP8 formats exhibit sufficient redundancy in floating-point exponents to allow effective lossless compression via fixed codes for common values and sparse handling for rare ones.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosurereality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SplitZip exploits redundancy in floating-point exponents of KV activations, encoding the most frequent exponent values with fixed-length codes and routing rare exponents through a sparse escape stream of (position, value). An offline calibrated top-16 exponent codebook eliminates online-histogramming
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the compression ratio is ρ=2/(3/2 + 3ϵ). As escape rates decrease, ρ approaches 4/3 asymptotically
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Quad length codes for lossless compression of e4m3, 2026
Aditya Agrawal, Albert Magyar, Hiteshwar Eswaraiah, Patrick Sheridan, Pradeep Janedula, Ravi Krishnan Venkatesan, Krishna Nair, and Ravi Iyer. Quad length codes for lossless compression of e4m3, 2026. URL https://arxiv.org/abs/2602.17849
-
[2]
Single-stage huffman encoder for ml compression, 2026
Aditya Agrawal, Albert Magyar, Hiteshwar Eswaraiah, Patrick Sheridan, Pradeep Janedula, Ravi Krishnan Venkatesan, Krishna Nair, and Ravi Iyer. Single-stage huffman encoder for ml compression, 2026. URL https://arxiv.org/abs/2601.10673
-
[3]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer, 2020. URLhttps://arxiv.org/abs/2004.05150
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URLhttps://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Sglang.https://github.com/sgl-project/sglang, 2026
LMSYS Corp. Sglang.https://github.com/sgl-project/sglang, 2026
work page 2026
-
[7]
Zipserv: Fast and memory-efficient llm inference with hardware-aware lossless compression
Ruibo Fan, Xiangrui Yu, Xinglin Pan, Zeyu Li, Weile Luo, Qiang Wang, Wei Wang, and Xiaowen Chu. Zipserv: Fast and memory-efficient llm inference with hardware-aware lossless compression. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 2, ASPLOS ’26, page 2264–2280, Ne...
-
[8]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021. URL https://arxiv.org/ abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Zipnn: Lossless compression for ai models.arXiv preprint arXiv:2411.05239, 2024
Moshik Hershcovitch, Andrew Wood, Leshem Choshen, Guy Girmonsky, Roy Leibovitz, Ilias Ennmouri, Michal Malka, Peter Chin, Swaminathan Sundararaman, and Danny Harnik. Zipnn: Lossless compression for ai models, 2024. URLhttps://arxiv.org/abs/2411.05239
-
[10]
Mahoney, Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Richard Charles Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Sophia Shao, Kurt Keutzer, and Amir Gholami. KVQuant: Towards 10 million context length LLM inference with KV cache quantization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=0LXotew9Du
work page 2024
-
[11]
Disaggregated inference at scale with pytorch & vllm
Hongyi Jia, Jinghui Zhang, Lu Fang, Stephen Chen, Yan Cui, Ye (Charlotte) Qi, and Zijing Liu. Disaggregated inference at scale with pytorch & vllm. https://pytorch.org/blog/ disaggregated-inference-at-scale-with-pytorch-vllm/ , September 2025. PyTorch Blog. Ac- cessed: April 26, 2026
work page 2025
-
[12]
Weiqing Li, Guochao Jiang, Xiangyong Ding, Zhangcheng Tao, Chuzhan Hao, Chenfeng Xu, Yuewei Zhang, and Hao Wang. Flowkv: A disaggregated inference framework with low-latency kv cache transfer and load-aware scheduling, 2025. URLhttps://arxiv.org/abs/2504.03775
-
[13]
SnapKV: LLM knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. SnapKV: LLM knows what you are looking for before generation. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=poE54GOq2l
work page 2024
-
[14]
A high-throughput gpu framework for adaptive lossless compression of floating-point data, 2025
Zheng Li, Weiyan Wang, Ruiyuan Li, Chao Chen, Xianlei Long, Linjiang Zheng, Quanqing Xu, and Chuanhui Yang. A high-throughput gpu framework for adaptive lossless compression of floating-point data, 2025. URLhttps://arxiv.org/abs/2511.04140. 10
-
[15]
PM-KVQ: Progressive mixed-precision KV cache quantization for long-cot LLMs
Tengxuan Liu, Shiyao Li, Jiayi Yang, Tianchen Zhao, Feng Zhou, Xiaohui Song, Guohao Dai, Shengen Yan, Huazhong Yang, and Yu Wang. PM-KVQ: Progressive mixed-precision KV cache quantization for long-cot LLMs. InThe F ourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=Vem6FQvRvq
work page 2026
-
[16]
Pointer sentinel mixture models,
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models,
-
[17]
URLhttps://arxiv.org/abs/1609.07843
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Meta. The llama 3 herd of models, 2024. URLhttps://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Dynamo.https://github.com/ai-dynamo/dynamo, 2026
NVIDIA. Dynamo.https://github.com/ai-dynamo/dynamo, 2026
work page 2026
-
[20]
Nvcomp.https://github.com/NVIDIA/nvcomp, 2026
NVIDIA. Nvcomp.https://github.com/NVIDIA/nvcomp, 2026
work page 2026
-
[21]
Splitwise: Efficient generative llm inference using phase splitting,
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting, 2024. URL https: //arxiv.org/abs/2311.18677
-
[22]
Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter
Ruoyu Qin, Weiran He, Yaoyu Wang, Zheming Li, Xinran Xu, Yongwei Wu, Weimin Zheng, and Mingxing Zhang. Prefill-as-a-service: Kvcache of next-generation models could go cross-datacenter, 2026. URL https://arxiv.org/abs/2604.15039
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Mooncake: A kvcache-centric disaggregated architecture for llm serving
Qin Ruoyu, Li Zheming, He Weiran, Cui Jialei, Tang Heyi, Ren Feng, Ma Teng, Cai Shangming, Zhang Yineng, Zhang Mingxing, Wu Yongwei, Zheng Weimin, and Xu Xinran. Mooncake: A kvcache-centric disaggregated architecture for llm serving.ACM Trans. Storage, nov 2025. ISSN 1553-3077. doi: 10.1145/3773772. URLhttps://doi.org/10.1145/3773772
-
[24]
KVLinC: Hadamard Rotation with Linear Correction for KV Cache Quantization,
Utkarsh Saxena and Kaushik Roy. Kvlinc: Kv cache quantization with hadamard rotation and linear correction.arXiv preprint arXiv:2510.05373, 2025
-
[25]
vllm.https://github.com/vllm-project/vllm, 2026
vLLM Team. vllm.https://github.com/vllm-project/vllm, 2026
work page 2026
-
[26]
Zirui Wang, Tingfeng Lan, Zhaoyuan Su, Juncheng Yang, and Yue Cheng. Zipllm: Efficient llm storage via model-aware synergistic data deduplication and compression, 2025. URL https://arxiv.org/abs/ 2505.06252
-
[27]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=NG7sS51zVF
work page 2024
-
[28]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Huff-llm: End-to- end lossless compression for efficient llm inference,
Patrick Yubeaton, Tareq Mahmoud, Shehab Naga, Pooria Taheri, Tianhua Xia, Arun George, Yasmein Khalil, Sai Qian Zhang, Siddharth Joshi, Chinmay Hegde, and Siddharth Garg. Huff-llm: End-to-end lossless compression for efficient llm inference, 2025. URLhttps://arxiv.org/abs/2502.00922
-
[30]
KV cache is 1 bit per channel: Efficient large language model inference with coupled quantization
Tianyi Zhang, Jonah Wonkyu Yi, Zhaozhuo Xu, and Anshumali Shrivastava. KV cache is 1 bit per channel: Efficient large language model inference with coupled quantization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum? id=pNnvzQsS4P
work page 2024
-
[31]
Tianyi Zhang, Mohsen Hariri, Shaochen Zhong, Vipin Chaudhary, Yang Sui, Xia Hu, and Anshumali Shrivastava. 70% size, 100% accuracy: Lossless LLM compression for efficient GPU inference via dynamic-length float (DFloat11). InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=xdNAVP7TGy
work page 2025
-
[32]
H2o: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Re, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2o: Heavy-hitter oracle for efficient generative inference of large language models. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/...
work page 2023
-
[33]
Distserve: disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve: disaggregating prefill and decoding for goodput-optimized large language model serving. In Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation, OSDI’24, USA, 2024. USENIX Association. ISBN 978-1-939133-40-3
work page 2024
-
[34]
Head-driven phrase structure grammar parsing on penn treebank, 2020
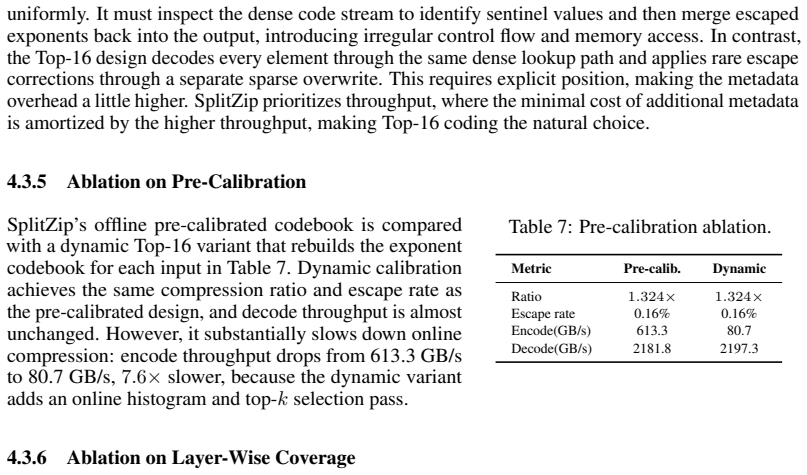
Junru Zhou and Hai Zhao. Head-driven phrase structure grammar parsing on penn treebank, 2020. URL https://arxiv.org/abs/1907.02684. 12 A Quad64 V ectorized Encoding Table 8: Quad64 vectorization ablation. Variant Encode Speedup GB/s Scalar pair encode 416.21.00× Quad64 encode 613.31.47× We further ablate the low-level GPU encoding layout. The baseline los...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.