Recognition: 2 theorem links
When Correct Isn't Usable: Improving Structured Output Reliability in Small Language Models
Pith reviewed 2026-05-08 18:47 UTC · model grok-4.3
The pith
Small language models reach 84-87% valid structured outputs on math benchmarks when system prompts are discovered by an automated meta-agent optimizer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that an iterative system-prompt optimizer called AloLab, driven by a capable meta-agent with only black-box API access to the target model, can discover prompts that make small language models generate outputs that are simultaneously mathematically correct and valid JSON on GSM8K and MATH, attaining 84-87% output accuracy on GSM8K and 34-40% on MATH over five independent runs, with 29 of 30 paired comparisons against the best static prompt reaching statistical significance at p less than 0.05, all while keeping inference latency close to the naive baseline and without fine-tuning.
What carries the argument
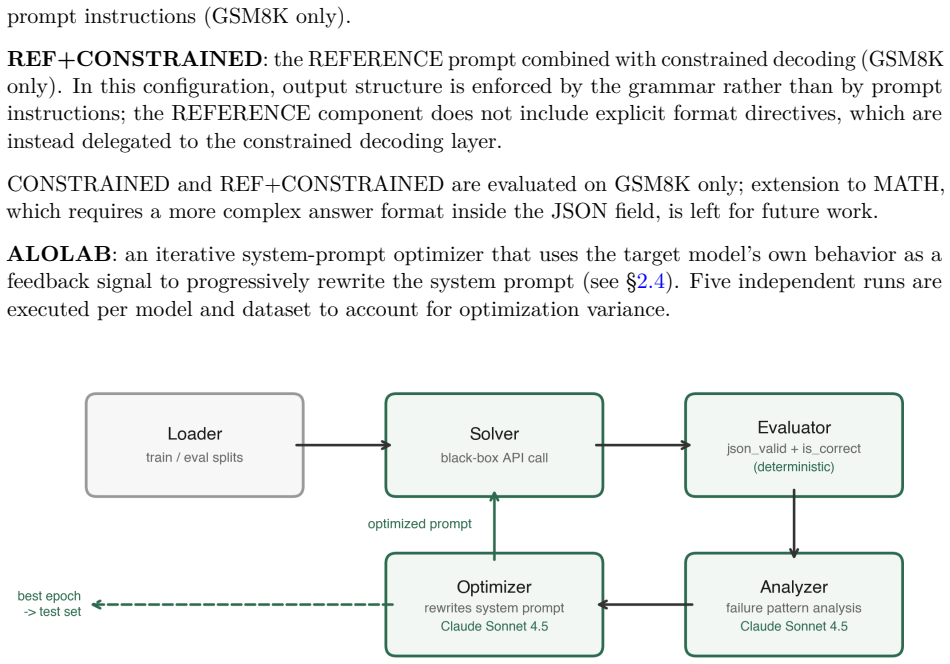
AloLab, an iterative system-prompt optimizer that proposes, tests, and refines prompt variations for a target model using only black-box output feedback from benchmark runs.
If this is right
- Output accuracy, the joint requirement of task correctness and format validity, becomes the operative metric and exposes failures that task accuracy alone hides.
- Constrained decoding is no longer necessary for format compliance, avoiding its 3.6x to 8.2x latency cost and occasional task-performance degradation.
- The same format non-compliance pattern occurs in both open small models and closed large models such as GPT-4o, where reference prompting yields zero valid outputs.
- Optimization quality scales with meta-agent capability, as shown by the drop in mean accuracy and rise in variance when a weaker meta-agent is substituted.
- No model fine-tuning or internal access is required, so the method applies directly to any model available through an API.
Where Pith is reading between the lines
- The same black-box iterative search could be applied to other structured-output contracts such as code snippets or tabular data without changing the core procedure.
- Production systems could run periodic re-optimization on fresh data distributions to keep prompts aligned with evolving model behavior or task requirements.
- Lower performance on the harder MATH benchmark relative to GSM8K suggests the method may need longer optimization budgets or richer feedback signals when task complexity increases.
- Combining the discovered prompts with light post-processing or verification steps might push output accuracy still higher while retaining the latency advantage.
Load-bearing premise
The meta-agent can discover system prompts that generalize to new examples rather than overfitting to the specific problems seen during optimization.
What would settle it
Applying the final optimized prompt to a fresh collection of math problems never used in the optimization loop and measuring whether output accuracy falls back to the near-zero levels observed with reference prompts.
Figures





read the original abstract
Deployed language models must produce outputs that are both correct and format-compliant. We study this structured-output reliability gap using two mathematical benchmarks -- GSM8K and MATH -- as a controlled testbed: ground truth is unambiguous and the output contract is strict (JSON with required fields). We evaluate three 7-9B models under five prompting strategies and report output accuracy -- the joint event of mathematical correctness and valid JSON structure -- as the primary metric. A systematic format failure emerges: NAIVE prompting (no system prompt) achieves up to 85% task accuracy on GSM8K but 0% output accuracy across all models and datasets. REFERENCE prompting (a minimal hand-written JSON format prompt) fares little better, yielding 0% output accuracy for two of four models tested. Constrained decoding enforces syntactic validity but incurs 3.6x-8.2x latency overhead and in several settings degrades task performance substantially. To overcome this limitation, we developed AloLab, an iterative system-prompt optimizer (meta-agent: Claude Sonnet 4.5) requiring only black-box API access to the target model; it reaches 84-87% output accuracy on GSM8K and 34-40% on MATH across five independent runs per model, with 29/30 paired McNemar comparisons against the best static prompt significant at p < 0.05, at near-NAIVE inference latency and without model fine-tuning. The same format failure extends to GPT-4o (OpenAI, 2024), a proprietary closed-source model: REFERENCE achieves 0% output accuracy due to systematic markdown-fence wrapping, while AloLab reaches 95.2% [94.8, 95.6]. An ablation replacing the Sonnet 4.5 meta-agent with Claude 3 Haiku reduces mean output accuracy to 61.0% and increases run-to-run standard deviation from <1 pp to 21.8 pp, confirming that meta-agent capability is a primary driver of optimization quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines the gap between task accuracy and structured output reliability (correct reasoning plus valid JSON) in 7-9B language models on GSM8K and MATH. It shows that NAIVE and REFERENCE prompting yield near-zero output accuracy despite high task accuracy, while constrained decoding adds substantial latency. The authors introduce AloLab, a black-box iterative system-prompt optimizer driven by a meta-agent (Claude Sonnet 4.5), which achieves 84-87% output accuracy on GSM8K and 34-40% on MATH across five runs, with 29/30 McNemar tests significant at p<0.05 versus static baselines, at near-NAIVE latency and no fine-tuning. The same pattern is shown for GPT-4o, and an ablation with a weaker meta-agent (Haiku) degrades performance.
Significance. If the central claims hold, the work is significant for practical deployment of small models in structured-output settings, demonstrating that prompt optimization can close the reliability gap without fine-tuning or latency penalties. Credit is due for the multi-run design, McNemar statistical tests, meta-agent ablation, and extension to a closed-source model. The empirical patterns are consistent across models and datasets, supporting the reported gains under the stated conditions.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation description: the AloLab optimization is performed via repeated black-box interactions on the GSM8K and MATH test sets themselves, with no mention of a held-out validation split, early stopping on separate data, or post-optimization evaluation on distributionally shifted problems. This makes it unclear whether the discovered prompts capture general format-compliance strategies or exploit benchmark-specific patterns (e.g., common JSON field orderings or error modes), directly affecting the claim of improved structured-output reliability for arbitrary tasks.
- [Results] Results section (implied by the 29/30 McNemar comparisons): while the paired significance tests are reported, the absence of cross-benchmark testing or out-of-distribution evaluation means the headline gains (84-87% GSM8K, 34-40% MATH) may not demonstrate a reliable method beyond these two math datasets, as the skeptic concern about overfitting is not addressed by the current experimental design.
minor comments (2)
- [Abstract] The abstract states 'near-NAIVE inference latency' but does not quantify the exact overhead or number of meta-agent queries per optimization run, which would help assess practicality.
- [Methods] Prompt trajectories and exact stopping criteria for AloLab are not visible, limiting reproducibility even though multiple runs and ablations are provided.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for highlighting important considerations regarding the evaluation methodology. We address each major comment below and propose revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the AloLab optimization is performed via repeated black-box interactions on the GSM8K and MATH test sets themselves, with no mention of a held-out validation split, early stopping on separate data, or post-optimization evaluation on distributionally shifted problems. This makes it unclear whether the discovered prompts capture general format-compliance strategies or exploit benchmark-specific patterns (e.g., common JSON field orderings or error modes), directly affecting the claim of improved structured-output reliability for arbitrary tasks.
Authors: We agree that the optimization process was performed directly on the GSM8K and MATH test sets, as described in the methods section of the manuscript. This approach was chosen because AloLab is intended as a practical tool for optimizing prompts for a given task using available labeled data, without requiring a separate validation set. The meta-agent evaluates both task correctness and format compliance on each iteration, which encourages discovery of robust strategies rather than dataset-specific artifacts. The low variance across five independent optimization runs (standard deviation <1 pp for Sonnet 4.5) and the significant degradation when using a weaker meta-agent (Haiku) provide evidence against simple overfitting. Nevertheless, we acknowledge the concern and will revise the abstract and evaluation sections to explicitly disclose the use of test data for optimization and to include a discussion of potential limitations regarding generalization to new tasks. We will also add a note on how practitioners could use a held-out set for early stopping in deployment scenarios. revision: yes
-
Referee: [Results] Results section (implied by the 29/30 McNemar comparisons): while the paired significance tests are reported, the absence of cross-benchmark testing or out-of-distribution evaluation means the headline gains (84-87% GSM8K, 34-40% MATH) may not demonstrate a reliable method beyond these two math datasets, as the skeptic concern about overfitting is not addressed by the current experimental design.
Authors: We recognize that the current experiments are limited to two mathematical reasoning benchmarks, which serve as a controlled testbed with clear ground truth and strict output requirements. The inclusion of results on GPT-4o extends the findings beyond small open models. However, we agree that cross-benchmark and out-of-distribution evaluations would provide stronger evidence for the general applicability of AloLab. In the revised manuscript, we will expand the discussion section to explicitly address this limitation, including potential risks of benchmark-specific optimization and suggestions for future work involving additional datasets (e.g., non-mathematical tasks or shifted distributions). We maintain that the statistical significance across multiple runs and models supports the reliability of the gains within the evaluated settings. revision: partial
Circularity Check
No circularity in empirical evaluation of prompting strategies
full rationale
The paper is a purely empirical study reporting output accuracy metrics from five prompting strategies (including the iterative AloLab meta-agent optimizer) evaluated on public GSM8K and MATH benchmarks. No equations, derivations, fitted parameters, or first-principles claims appear in the text. Performance numbers are direct experimental measurements with McNemar tests; the method description relies on black-box API interactions without self-referential definitions, load-bearing self-citations, or ansatzes. Any generalization concerns (e.g., overfitting to test distributions) are validity issues, not reductions of the reported results to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Target models respond to system prompts in a manner that permits iterative improvement of output format and correctness through black-box queries.
- domain assumption Output accuracy (joint mathematical correctness and valid JSON) is the appropriate primary metric for structured-output reliability.
invented entities (1)
-
AloLab
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Claude 3 model card
Anthropic. Claude 3 model card. Technical report, Anthropic, 2024. URL https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
2024
-
[2]
Claude sonnet 4.5 system card
Anthropic. Claude sonnet 4.5 system card. Technical report, Anthropic, 2025. URL https://www.anthropic.com/claude-sonnet-4-5-system-card
2025
-
[3]
Training Verifiers to Solve Math Word Problems
K. Cobbe et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page Pith review arXiv 2021
-
[4]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team . Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
S. Geng et al. JSONSchemaBench : A rigorous benchmark of structured outputs for language models. arXiv preprint arXiv:2501.10868, 2025
-
[6]
Gemini 3 flash model card
Google DeepMind . Gemini 3 flash model card. Technical report, Google DeepMind, 2025. URL https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf
2025
-
[7]
A. Grattafiori et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
S. Hamilton and D. Mimno. Lost in space: Finding the right tokens for structured output. arXiv preprint arXiv:2502.14969, 2025
-
[9]
Measuring Mathematical Problem Solving With the MATH Dataset
D. Hendrycks et al. Measuring mathematical problem solving with the MATH dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review arXiv 2021
-
[10]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
B. Jin et al. Search-R1 : Training LLMs to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516, 2025
work page Pith review arXiv 2025
-
[11]
Khattab et al
O. Khattab et al. DSPy : Compiling declarative language model calls into state-of-the-art pipelines. In International Conference on Learning Representations, 2024
2024
- [12]
-
[13]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
I. Mirzadeh et al. GSM -symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229, 2024
work page Pith review arXiv 2024
-
[14]
N. M \"u ndler et al. Constrained decoding of diffusion LLMs with context-free grammars. arXiv preprint arXiv:2508.10111, 2025
- [15]
-
[16]
GPT-4o system card
OpenAI . GPT-4o system card. Technical report, OpenAI, 2024. URL https://openai.com/index/gpt-4o-system-card
2024
-
[17]
Park et al
K. Park et al. Grammar-aligned decoding. In Advances in Neural Information Processing Systems, 2024
2024
-
[18]
Pryzant et al
R. Pryzant et al. Automatic prompt optimization with `` G radient descent'' and beam search. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[19]
Towards reasoning ability of small language models,
G. Srivastava et al. Towards reasoning ability of small language models. arXiv preprint arXiv:2502.11569, 2025
-
[20]
Sun et al
X. Sun et al. Earley-driven dynamic pruning for efficient structured decoding. In International Conference on Machine Learning, 2025
2025
- [21]
-
[22]
S. Tenckhoff et al. LLMStructBench : Benchmarking large language model structured data extraction. arXiv preprint arXiv:2602.14743, 2026
-
[23]
SynCode: LLM Generation with Grammar Augmentation,
S. Ugare et al. SynCode : LLM generation with grammar augmentation. arXiv preprint arXiv:2403.01632, 2024
-
[24]
Z. Wang et al. Verifiable format control for large language model generations. arXiv preprint arXiv:2502.04498, 2025
-
[25]
B. T. Willard and R. Louf. Efficient guided generation for large language models. arXiv preprint arXiv:2307.09702, 2023
work page internal anchor Pith review arXiv 2023
-
[26]
A. Yang et al. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2024
work page internal anchor Pith review arXiv 2024
-
[27]
Large Language Models as Optimizers
C. Yang et al. Large language models as optimizers. arXiv preprint arXiv:2309.03409, 2023
work page internal anchor Pith review arXiv 2023
-
[28]
arXiv preprint arXiv:2603.08068 , year=
Y. Ye et al. In-context reinforcement learning for tool use in large language models. arXiv preprint arXiv:2603.08068, 2026
-
[29]
Zhou et al
Y. Zhou et al. Large language models are human-level prompt engineers. In International Conference on Learning Representations, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.