Recognition: 3 theorem links
· Lean TheoremMeasuring Accuracy and Energy-to-Solution of Quantum Fine-Tuning of Foundational AI Models
Pith reviewed 2026-05-08 18:09 UTC · model grok-4.3
The pith
Quantum fine-tuning of foundational AI models achieves around 24% lower classification error than classical baselines with energy-to-solution breaking even near 34 qubits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that quantum fine-tuning delivers models whose classification error is approximately 24% lower than that of the best classical fine-tuned models tested. For the shallow circuits employed, QPU energy consumption scales linearly with qubit count while classical simulation scales exponentially, indicating an energy-to-solution crossover near 34 qubits. These outcomes are obtained through direct power instrumentation on actual quantum hardware and remain competitive despite noise and small qubit numbers.
What carries the argument
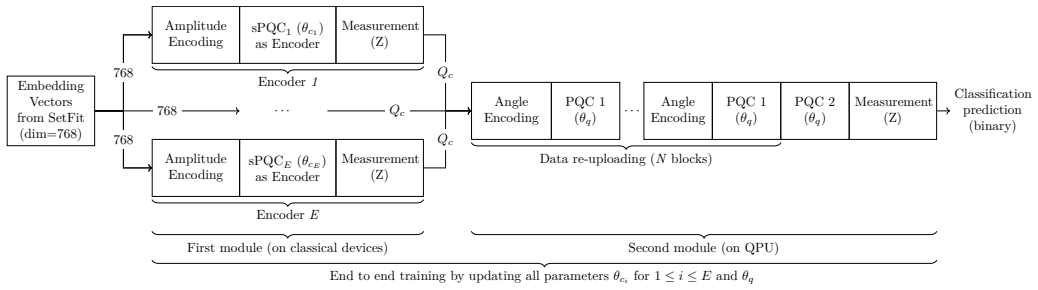
The hybrid quantum-classical fine-tuning pipeline with direct power-consumption instrumentation on a trapped-ion quantum processor.
If this is right
- Quantum fine-tuned models can exceed classical accuracy in classification tasks on current noisy hardware.
- Energy-to-solution favors the quantum approach once qubit counts reach approximately 34 for shallow circuits.
- Energy-to-solution serves as a concrete, hardware-measurable metric for comparing quantum and classical AI pipelines.
- End-to-end validation on real quantum processors is feasible rather than relying only on simulation.
Where Pith is reading between the lines
- If linear scaling holds on larger devices, quantum fine-tuning could become preferable for training bigger models where classical energy costs grow prohibitive.
- The same energy metric could be used to benchmark other hybrid quantum machine-learning tasks and locate their break-even points.
- Combining the pipeline with tensor-network techniques might produce further gains in both accuracy and energy use.
Load-bearing premise
The observed accuracy gains and linear energy scaling will continue when the same pipeline is applied to larger foundational models or deeper circuits.
What would settle it
Running the identical fine-tuning pipeline on quantum hardware with 40 or more qubits and checking whether classification error improvement stays near 24% and whether energy scales linearly past the predicted break-even point.
Figures



read the original abstract
We present an experimental study of energy-to-solution (ETS) of hybrid quantum-classical applications, enabled by direct instrumentation of power consumption of a Forte Enterprise trapped-ion quantum processor. We apply this methodology to a hybrid quantum-classical pipeline for quantum fine-tuning of foundational AI models, and validate the approach end-to-end on quantum hardware. Despite noise and limited qubit counts, the resulting models achieve accuracy competitive with and exceeding classical baselines such as logistic regression and support vector classifiers. Our results show that QPU energy consumption scales approximately linearly with qubit number for shallow circuits, while classical simulation exhibits exponential scaling, indicating a break-even for ETS around 34 qubits. The classification error improvement of the best quantum fine-tuned model over the best classical fine-tuned model considered in this study is around 24%. We further contextualize these findings with comparisons to tensor network methods. This work establishes energy-to-solution as a measurable and scalable metric for evaluating quantum applications and provides experimental evidence of favorable energy-accuracy trade-offs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an experimental study of energy-to-solution (ETS) for a hybrid quantum-classical pipeline that performs quantum fine-tuning of foundational AI models. Direct power measurements on a trapped-ion QPU (Forte Enterprise) are used to show that the best quantum fine-tuned models achieve approximately 24% lower classification error than the best classical baselines (logistic regression and support vector classifiers) considered. QPU energy consumption is reported to scale linearly with qubit number for shallow circuits, in contrast to the exponential scaling of classical simulation, yielding a projected ETS break-even at around 34 qubits. Comparisons to tensor-network methods are included, and ETS is positioned as a practical metric for quantum applications.
Significance. If the accuracy gains and linear-scaling extrapolation hold, the work supplies rare hardware-validated data on energy consumption for quantum AI fine-tuning and demonstrates a concrete path toward favorable energy-accuracy trade-offs. The direct instrumentation of QPU power draw and the end-to-end execution on real hardware are clear strengths that move the discussion beyond purely theoretical scaling arguments.
major comments (3)
- [Energy scaling and break-even discussion] The 34-qubit ETS break-even projection rests on an extrapolation of linear QPU energy scaling observed only for small qubit counts and shallow circuits. The manuscript supplies neither the explicit fitting procedure, uncertainties on the linear coefficients, nor any analysis of how circuit depth or noise would grow with larger foundational models, all of which are load-bearing for the central claim.
- [Accuracy results] The stated 24% classification-error improvement is presented without error bars, confidence intervals, or details on the number of experimental repetitions and statistical tests. This omission makes it impossible to judge whether the reported advantage is robust or lies within run-to-run variability.
- [Experimental methods and pipeline description] No description is given of the quantum circuit depths employed, the precise structure of the hybrid fine-tuning ansatz, or any noise-mitigation techniques applied on the trapped-ion device. These details are required to assess whether the observed accuracy edge can be expected to persist beyond the current small-qubit, shallow-circuit regime.
minor comments (3)
- [Abstract and introduction] The abstract and introduction refer to 'foundational AI models' yet the experiments appear to use comparatively small models; a brief clarification of model sizes and parameter counts would improve context.
- [Figures] Energy-scaling figures would be clearer if they overlaid the raw measurement points, the fitted line, and uncertainty bands rather than showing only the trend.
- [Baseline comparisons] A short discussion of how the chosen classical baselines compare with more advanced fine-tuning methods (e.g., LoRA or prompt tuning) would strengthen the comparative claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have identified key areas where additional details and clarifications will strengthen the manuscript. We address each of the major comments below, providing explanations and indicating the revisions we will implement.
read point-by-point responses
-
Referee: [Energy scaling and break-even discussion] The 34-qubit ETS break-even projection rests on an extrapolation of linear QPU energy scaling observed only for small qubit counts and shallow circuits. The manuscript supplies neither the explicit fitting procedure, uncertainties on the linear coefficients, nor any analysis of how circuit depth or noise would grow with larger foundational models, all of which are load-bearing for the central claim.
Authors: We agree that the extrapolation requires more rigorous support. In the revised manuscript, we will explicitly describe the linear fitting procedure applied to the measured energy data across qubit counts of 2 to 8, including the regression coefficients, their standard errors from the fit, and R-squared values. Additionally, we will include a new subsection discussing the limitations of the projection, such as the assumption of constant circuit depth and the potential impact of increased noise and depth in larger models. This will temper the claim while retaining the indicative nature of the 34-qubit break-even point based on current hardware data. revision: yes
-
Referee: [Accuracy results] The stated 24% classification-error improvement is presented without error bars, confidence intervals, or details on the number of experimental repetitions and statistical tests. This omission makes it impossible to judge whether the reported advantage is robust or lies within run-to-run variability.
Authors: We will revise the results section to include error bars representing the standard deviation from 15 independent experimental runs for each model. We will also report 95% confidence intervals and perform a statistical comparison (Wilcoxon signed-rank test) between the quantum and classical models to confirm the significance of the 24% error reduction. These additions will demonstrate the robustness of the accuracy improvement. revision: yes
-
Referee: [Experimental methods and pipeline description] No description is given of the quantum circuit depths employed, the precise structure of the hybrid fine-tuning ansatz, or any noise-mitigation techniques applied on the trapped-ion device. These details are required to assess whether the observed accuracy edge can be expected to persist beyond the current small-qubit, shallow-circuit regime.
Authors: We will substantially expand the Methods section to detail the quantum circuit implementation. Specifically, we will describe the circuit depths (ranging from 3 to 7 layers depending on the model size), the structure of the hybrid fine-tuning ansatz (a variational quantum eigensolver-inspired circuit with parameterized rotation gates and entangling operations, combined with classical neural network layers), and the noise-mitigation strategies used, including symmetry verification and post-selection on measurement outcomes. These details will help evaluate the potential for scaling the approach. revision: yes
Circularity Check
No significant circularity; results are empirical measurements and data-driven extrapolations.
full rationale
The paper reports direct hardware measurements of classification accuracy (24% error improvement) and power consumption on a trapped-ion QPU for shallow circuits. Linear QPU scaling and exponential classical scaling are observed from those measurements, with the 34-qubit break-even obtained by extrapolating the fitted trends. No derivation chain, equation, or claim reduces by construction to a self-definition, fitted parameter renamed as prediction, or self-citation load-bearing premise. All central results are presented as experimental outcomes rather than first-principles derivations.
Axiom & Free-Parameter Ledger
free parameters (1)
- break-even qubit count
Reference graph
Works this paper leans on
-
[1]
How much structure is needed for huge quantum speedups?
S. Aaronson, “How much structure is needed for huge quantum speedups?,”arXiv preprint arXiv:2209.06930, 2022
-
[2]
Systematic literature review: Quantum machine learning and its applications,
D. Peral-García, J. Cruz-Benito, and F. J. García-Peñalvo, “Systematic literature review: Quantum machine learning and its applications,” Computer Science Review, vol. 51, p. 100619, 2024
2024
-
[3]
Exponential quantum advantage in processing massive classical data
H. Zhao, A. Zlokapa, H. Neven, R. Babbush, J. Preskill, J. R. McClean, and H.-Y . Huang, “Exponential quantum advantage in processing mas- sive classical data,”arXiv preprint arXiv:2604.07639, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Is quantum computing green? an estimate for an energy-efficiency quantum advantage,
D. Jaschke and S. Montangero, “Is quantum computing green? an estimate for an energy-efficiency quantum advantage,”Quantum Science and Technology, vol. 8, no. 2, p. 025001, 2023
2023
-
[5]
Machine learning of high dimensional data on a noisy quantum processor,
E. Peters, J. Caldeira, A. Ho, S. Leichenauer, M. Mohseni, H. Neven, P. Spentzouris, D. Strain, and G. N. Perdue, “Machine learning of high dimensional data on a noisy quantum processor,”npj Quantum Information, vol. 7, no. 1, p. 161, 2021
2021
-
[6]
High dimensional quantum machine learning with small quantum computers,
S. C. Marshall, C. Gyurik, and V . Dunjko, “High dimensional quantum machine learning with small quantum computers,”Quantum, vol. 7, p. 1078, 2023
2023
-
[7]
Estimating the carbon footprint of bloom, a 176b parameter language model,
A. S. Luccioni, S. Viguier, and A.-L. Ligozat, “Estimating the carbon footprint of bloom, a 176b parameter language model,”Journal of machine learning research, vol. 24, no. 253, pp. 1–15, 2023
2023
-
[8]
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Y . Sun, X. Li, K. Dalal, J. Xu, A. Vikram, G. Zhang, Y . Dubois, X. Chen, X. Wang, S. Koyejo,et al., “Learning to (learn at test time): Rnns with expressive hidden states,”URL https://arxiv. org/abs/2407.04620, 2024
work page internal anchor Pith review arXiv 2024
-
[9]
Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition,
H. Jung, S. Lee, J. Yim, S. Park, and J. Kim, “Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition,” inProceedings of the IEEE international conference on computer vision, pp. 2983–2991, 2015
2015
-
[10]
Fine-Tuning Deep Neural Networks in Continuous Learning Scenarios,
C. Käding, E. Rodner, A. Freytag, and J. Denzler, “Fine-Tuning Deep Neural Networks in Continuous Learning Scenarios,” inComputer Vision – ACCV 2016 Workshops(C.-S. Chen, J. Lu, and K.-K. Ma, eds.), (Cham), pp. 588–605, Springer International Publishing, 2017
2016
-
[11]
Growing a Brain: Fine- Tuning by Increasing Model Capacity,
Y .-X. Wang, D. Ramanan, and M. Hebert, “Growing a Brain: Fine- Tuning by Increasing Model Capacity,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 2471–2480, 2017
2017
-
[12]
Quantum lan- guage model fine tuning,
S. Kim, J. Mei, C. Girotto, M. Yamada, and M. Roetteler, “Quantum lan- guage model fine tuning,”IEEE International Conference on Quantum Computing and Engineering, 2025
2025
-
[13]
Quantum technologies for climate change: Preliminary assessment,
C. Berger, A. Di Paolo, T. Forrest, S. Hadfield, N. Sawaya, M. St˛ echły, and K. Thibault, “Quantum technologies for climate change: Preliminary assessment,”arXiv preprint arXiv:2107.05362, 2021
-
[14]
Exploring the trade-off between computational power and energy efficiency: An analysis of the evolution of quantum computing and its relation to classical computing,
E. Desdentado, C. Calero, M. Á. Moraga, M. Serrano, and F. García, “Exploring the trade-off between computational power and energy efficiency: An analysis of the evolution of quantum computing and its relation to classical computing,”Journal of Systems and Software, vol. 217, p. 112165, 2024
2024
-
[15]
Achieving energetic superi- ority through system-level quantum circuit simulation,
R. Fu, Z. Su, H.-S. Zhong, X. Zhao, J. Zhang, F. Pan, P. Zhang, X. Zhao, M.-C. Chen, C.-Y . Lu,et al., “Achieving energetic superi- ority through system-level quantum circuit simulation,”arXiv preprint arXiv:2407.00769, 2024
-
[16]
Landauer versus nernst: What is the true cost of cooling a quantum system?,
P. Taranto, F. Bakhshinezhad, A. Bluhm, R. Silva, N. Friis, M. P. Lock, G. Vitagliano, F. C. Binder, T. Debarba, E. Schwarzhans,et al., “Landauer versus nernst: What is the true cost of cooling a quantum system?,”PRX Quantum, vol. 4, no. 1, p. 010332, 2023
2023
-
[17]
Efficiently cooling quantum systems with finite resources: Insights from thermodynamic geometry,
P. Taranto, P. Lipka-Bartosik, N. A. Rodríguez-Briones, M. Perarnau- Llobet, N. Friis, M. Huber, and P. Bakhshinezhad, “Efficiently cooling quantum systems with finite resources: Insights from thermodynamic geometry,”Physical review letters, vol. 134, no. 7, p. 070401, 2025
2025
-
[18]
Quantum technologies need a quantum energy initiative,
A. Auffèves, “Quantum technologies need a quantum energy initiative,” PRX Quantum, vol. 3, no. 2, p. 020101, 2022
2022
-
[19]
Energy-consumption advantage of quantum computation,
F. Meier and H. Yamasaki, “Energy-consumption advantage of quantum computation,”PRX Energy, vol. 4, no. 2, p. 023008, 2025
2025
-
[20]
Are quantum computers really energy efficient?,
S. Chen, “Are quantum computers really energy efficient?,” 2023
2023
-
[21]
Optimizing resource efficiencies for scalable full- stack quantum computers,
M. Fellous-Asiani, J. H. Chai, Y . Thonnart, H. K. Ng, R. S. Whitney, and A. Auffèves, “Optimizing resource efficiencies for scalable full- stack quantum computers,”PRX Quantum, vol. 4, no. 4, p. 040319, 2023
2023
-
[22]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th In- ternational Joint Conference on Natural Language Processing (EMNLP- IJCNLP)(K. Inui, J. Jiang, V . Ng, and X. Wan, eds.), (Hong Kong, China), pp. 3982–3992, A...
2019
-
[23]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 1 (Long and Short Papers)(J. Burstein, C. Doran, and T. Solorio, ed...
2019
-
[24]
Efficient few-shot learn- ing without prompts,
L. Tunstall, N. Reimers, U. E. S. Jo, L. Bates, D. Korat, M. Wasserblat, and O. Pereg, “Efficient Few-Shot Learning Without Prompts,”arXiv, Sept. 2022. arXiv:2209.11055 [cs]
-
[25]
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank,
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Ng, and C. Potts, “Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank,” inProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing(D. Yarowsky, T. Baldwin, A. Korhonen, K. Livescu, and S. Bethard, eds.), (Seattle, Washington, USA), pp. 163...
2013
-
[26]
M. A. Nielsen and I. Chuang,Quantum computation and quantum information. Cambridge University Press Edition, 2016: American Association of Physics Teachers, 2002
2016
-
[27]
Supervised quantum machine learning mod- els are kernel methods
M. Schuld, “Supervised quantum machine learning models are kernel methods,”arXiv, Apr. 2021. arXiv:2101.11020 [quant-ph, stat]
-
[28]
Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent,
J. Lee, L. Xiao, S. Schoenholz, Y . Bahri, R. Novak, J. Sohl-Dickstein, and J. Pennington, “Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent,” inAdvances in Neural Information Processing Systems, vol. 32, Curran Associates, Inc., 2019
2019
-
[29]
Neural Networks as Kernel Learners: The Silent Alignment Effect,
A. Atanasov, B. Bordelon, and C. Pehlevan, “Neural Networks as Kernel Learners: The Silent Alignment Effect,” inInternational Conference on Learning Representations, Oct. 2021
2021
-
[30]
Data re-uploading for a universal quantum classifier,
A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, “Data re-uploading for a universal quantum classifier,”Quantum, vol. 4, p. 226, Feb. 2020. Publisher: Verein zur Förderung des Open Access Publizierens in den Quantenwissenschaften
2020
-
[31]
Enhancing quantum computer performance via symmetrization,
A. Maksymov, J. Nguyen, Y . Nam, and I. Markov, “Enhancing quantum computer performance via symmetrization,”arXiv preprint arXiv:2301.07233, 2023
-
[32]
mlco2/codecarbon: v2.4.1,
B. Courty, V . Schmidt, S. Luccioni, Goyal-Kamal, MarionCoutarel, B. Feld, J. Lecourt, LiamConnell, A. Saboni, Inimaz, supatomic, M. Lé- val, L. Blanche, A. Cruveiller, ouminasara, F. Zhao, A. Joshi, A. Bogroff, H. de Lavoreille, N. Laskaris, E. Abati, D. Blank, Z. Wang, A. Catovic, M. Alencon, M. St˛ echły, C. Bauer, L. O. N. de Araújo, JPW, and MinervaB...
2024
-
[33]
Slurm: Simple linux utility for resource management,
A. B. Yoo, M. A. Jette, and M. Grondona, “Slurm: Simple linux utility for resource management,” inWorkshop on job scheduling strategies for parallel processing, pp. 44–60, Springer, 2003
2003
-
[34]
NVIDIA L4 Tensor Core GPU Datasheet
“NVIDIA L4 Tensor Core GPU Datasheet.”
-
[35]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
V . Bergholm, J. Izaac, M. Schuld, C. Gogolin, S. Ahmed, V . Ajith, M. S. Alam, G. Alonso-Linaje, B. AkashNarayanan, A. Asadi, J. M. Arrazola, U. Azad, S. Banning, C. Blank, T. R. Bromley, B. A. Cordier, J. Ceroni, A. Delgado, O. D. Matteo, A. Dusko, T. Garg, D. Guala, A. Hayes, R. Hill, A. Ijaz, T. Isacsson, D. Ittah, S. Jahangiri, P. Jain, E. Jiang, A. ...
work page internal anchor Pith review arXiv 2022
-
[36]
Automatic differentiation in PyTorch,
A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in PyTorch,” inAdvances in Neural Information Processing Systems 2017 Workshop on Autodiff, Oct. 2017
2017
-
[37]
Growing the internet while reducing energy consumption
“Growing the internet while reducing energy consumption.”
-
[38]
Hybrid Quantum-Classical Approach to Quantum Optimal Control,
J. Li, X. Yang, X. Peng, and C.-P. Sun, “Hybrid Quantum-Classical Approach to Quantum Optimal Control,”Physical Review Letters, vol. 118, p. 150503, Apr. 2017. Publisher: American Physical Society
2017
-
[39]
The density-matrix renormalization group in the age of matrix product states,
U. Schollwöck, “The density-matrix renormalization group in the age of matrix product states,”Annals of physics, vol. 326, no. 1, pp. 96–192, 2011
2011
-
[40]
Efficient classical simulation of slightly entangled quantum computations,
G. Vidal, “Efficient classical simulation of slightly entangled quantum computations,”Physical review letters, vol. 91, no. 14, p. 147902, 2003
2003
-
[41]
Encoding of matrix product states into quantum circuits of one-and two-qubit gates,
S.-J. Ran, “Encoding of matrix product states into quantum circuits of one-and two-qubit gates,”Physical Review A, vol. 101, no. 3, p. 032310, 2020
2020
-
[42]
Cost function dependent barren plateaus in shallow parametrized quantum circuits,
M. Cerezo, A. Sone, T. V olkoff, L. Cincio, and P. J. Coles, “Cost function dependent barren plateaus in shallow parametrized quantum circuits,” Nature communications, vol. 12, no. 1, p. 1791, 2021
2021
-
[43]
Oak Ridge National Labs Frontier
“Oak Ridge National Labs Frontier.” https://www.olcf.ornl.gov/frontier/
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.