CreativityBench: Evaluating Agent Creative Reasoning via Affordance-Based Tool Repurposing
Pith reviewed 2026-05-10 20:22 UTC · model grok-4.3
The pith
Large language models select plausible objects for creative tasks but rarely identify the specific parts, affordances, and physical mechanisms required to solve them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
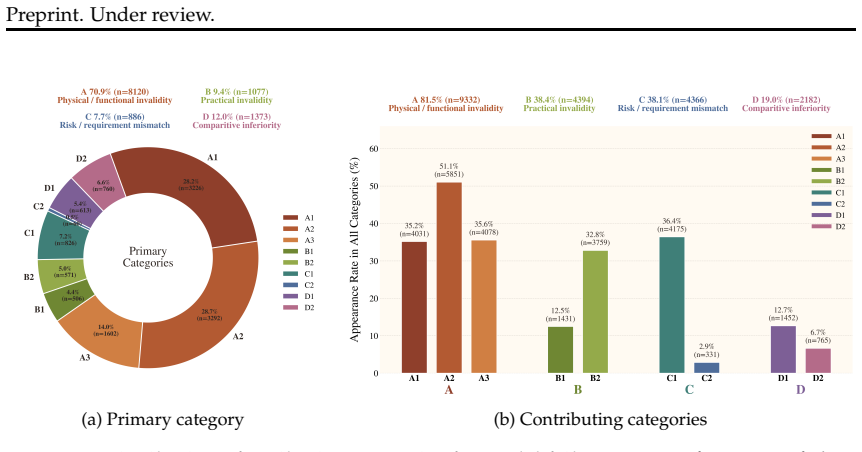
The paper claims that affordance-based creative tool use exposes a clear limitation in state-of-the-art LLMs: models frequently nominate a reasonable object yet fail to isolate the relevant parts, attribute the correct affordances to those parts, or articulate the underlying physical mechanism that would make the repurposed solution work under the stated constraints.
What carries the argument
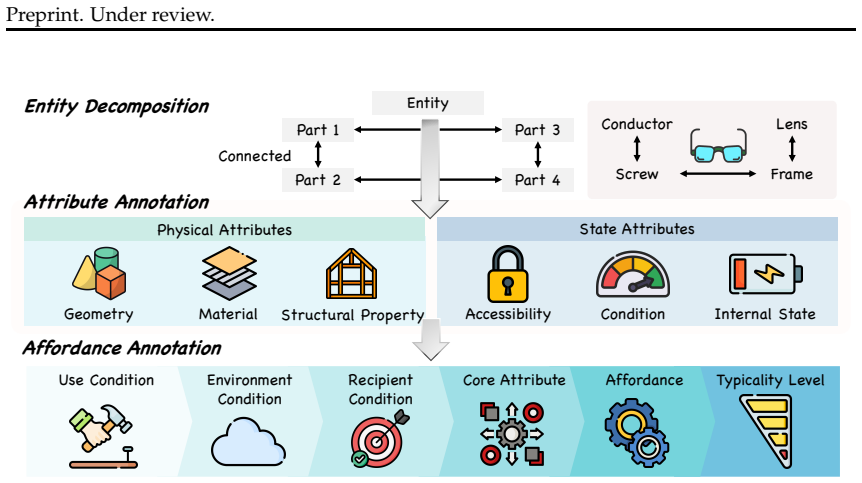
CreativityBench, built on a 4K-entity affordance knowledge base with 150K+ annotations that explicitly connects objects, parts, attributes, and non-canonical uses, then used to synthesize 14K grounded tasks requiring identification of physically plausible repurposings.
If this is right
- Strong general reasoning ability does not reliably transfer to discovering non-obvious affordances.
- Further increases in model scale produce quickly diminishing returns on this class of creative tasks.
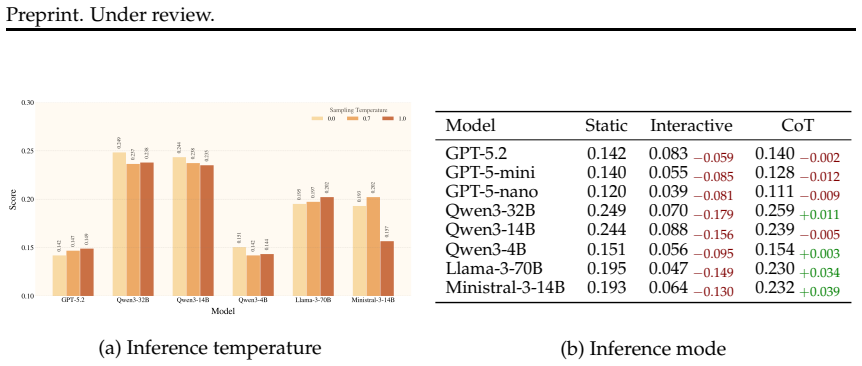
- Standard inference-time techniques such as Chain-of-Thought provide only marginal help in identifying parts and physical mechanisms.
- Agent planning and reasoning modules will need dedicated affordance reasoning components to handle novel tool-use scenarios.
Where Pith is reading between the lines
- The benchmark could be adapted to test whether vision-language models improve when given direct visual access to object parts.
- Persistent failures here would predict similar limitations in real-world robotic systems that must improvise with unfamiliar tools.
- Architectural additions beyond scale, such as explicit simulation of physical interactions, may be required to close the gap.
Load-bearing premise
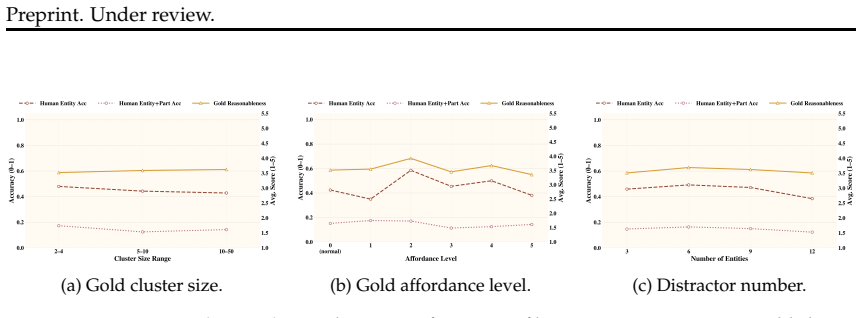
The 14K tasks and the affordance knowledge base isolate creative reasoning about parts and mechanisms without being undermined by gaps in general knowledge, construction biases, or annotation errors.
What would settle it
A model that achieves high accuracy on the full tasks by correctly naming the required parts, their specific affordances, and the physical mechanism for the majority of the 14K items would falsify the reported performance gap.
Figures
















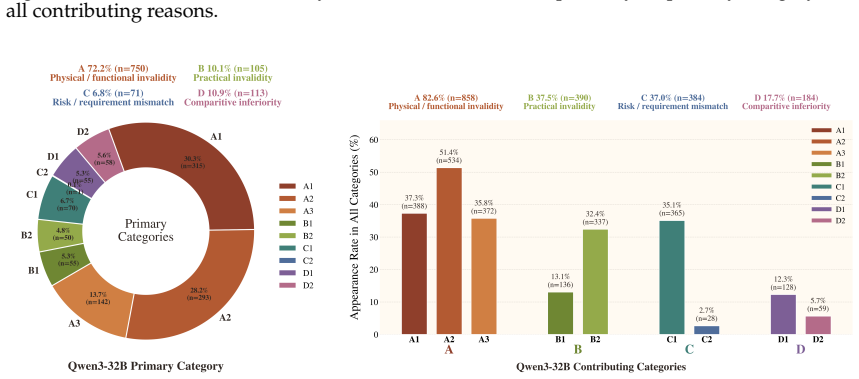
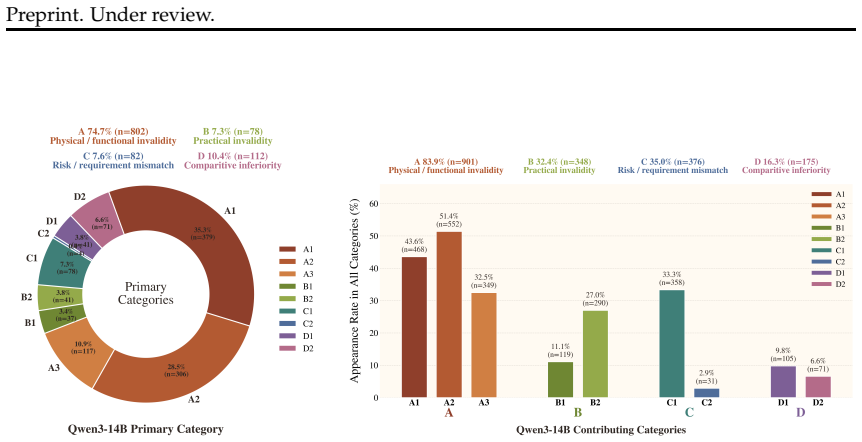
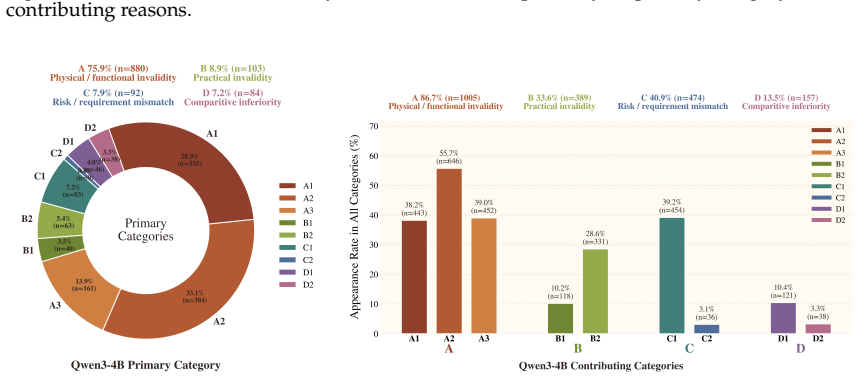
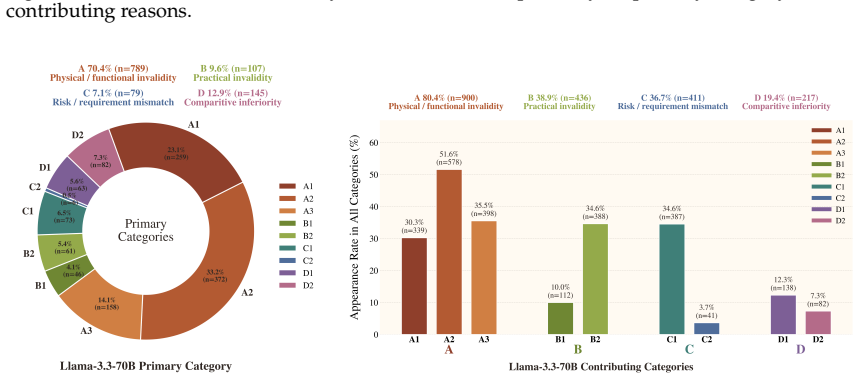
read the original abstract
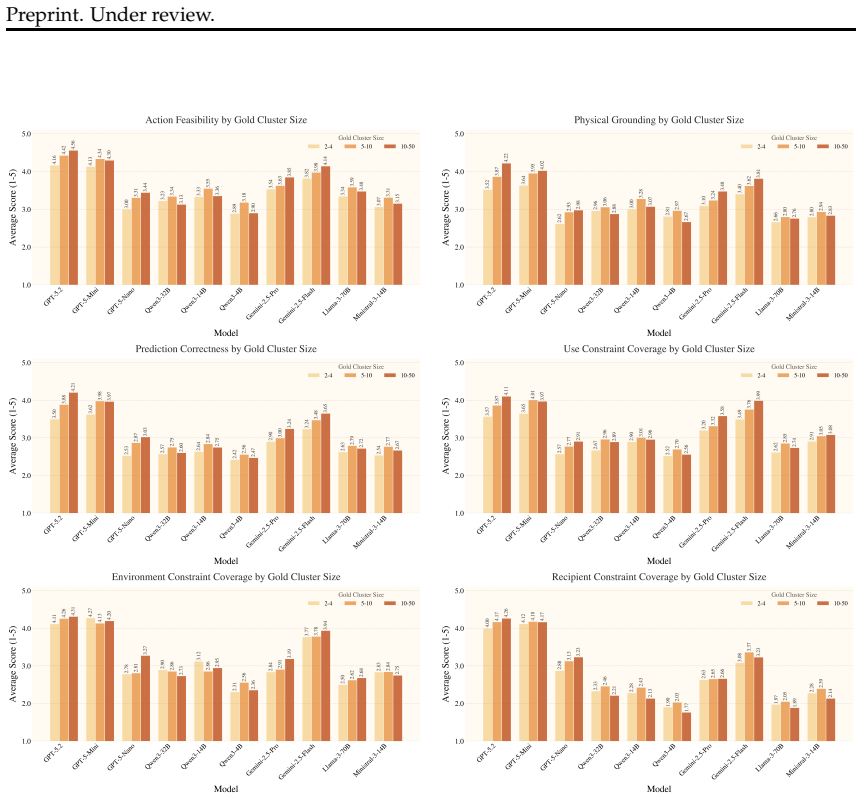
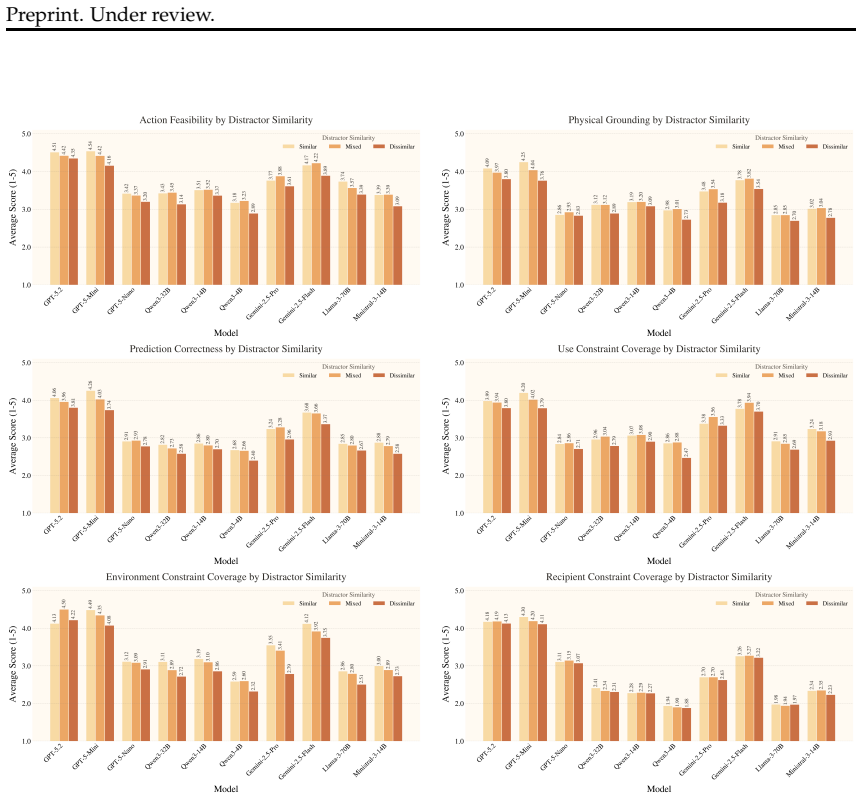
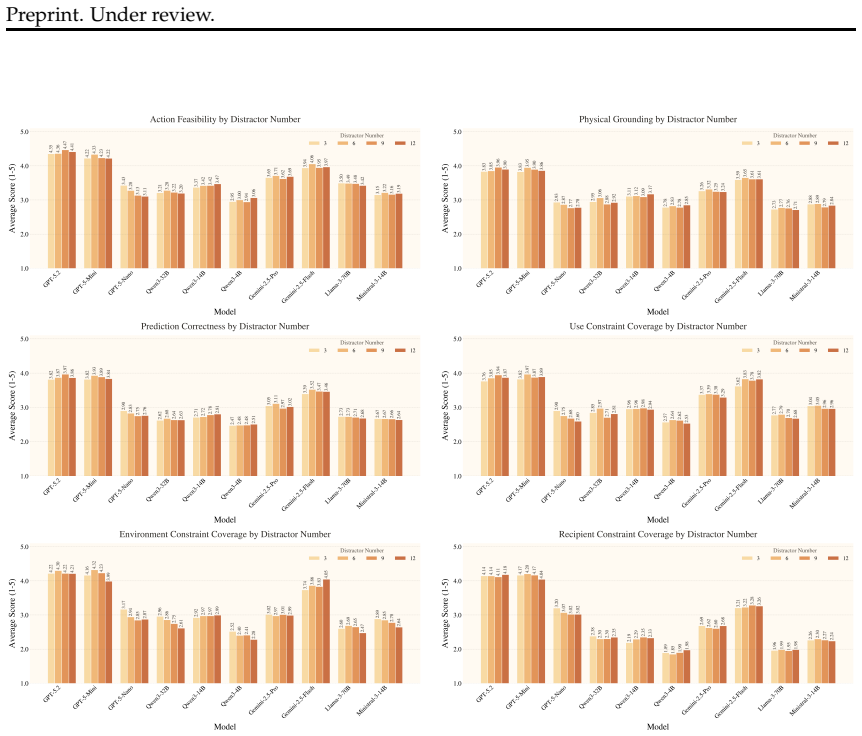
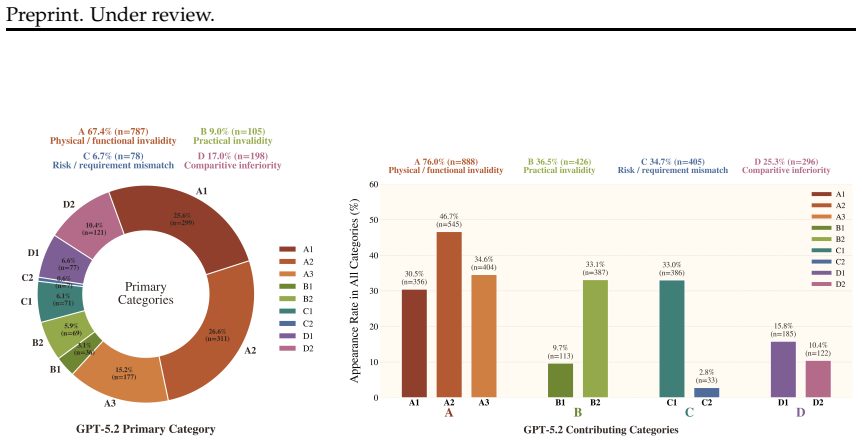
Recent advances in large language models have led to strong performance on reasoning and environment-interaction tasks, yet their ability for creative problem-solving remains underexplored. We study this capability through the lens of creative tool use, where a model repurposes available objects by reasoning about their affordances and attributes rather than relying on canonical usage. As a first step, we introduce CreativityBench, a benchmark for evaluating affordance-based creativity in LLMs. To this end, we build a large-scale affordance knowledge base (KB) with 4K entities and 150K+ affordance annotations, explicitly linking objects, parts, attributes, and actionable uses. Building on this KB, we generate 14K grounded tasks that require identifying non-obvious yet physically plausible solutions under constraints. Evaluations across 10 state-of-the-art LLMs, including closed and open-source models, show that models can often select a plausible object, but fail to identify the correct parts, their affordances, and the underlying physical mechanism needed to solve the task, leading to a significant drop in performance. Furthermore, improvements from model scaling quickly saturate, strong general reasoning does not reliably translate to creative affordance discovery, and common inference-time strategies such as Chain-of-Thought yield limited gains. These results suggest that creative tool use remains a major challenge for current models, and that CreativityBench provides a useful testbed for studying this missing dimension of intelligence, with potential implications for planning and reasoning modules in future agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CreativityBench, a benchmark for evaluating creative reasoning in LLMs through affordance-based tool repurposing. It builds a knowledge base of 4K entities with 150K+ annotations linking objects, parts, attributes, and uses, then generates 14K grounded tasks requiring non-obvious yet physically plausible solutions under constraints. Evaluations on 10 state-of-the-art LLMs (closed and open-source) show models often select a plausible object but fail to identify correct parts, affordances, and physical mechanisms, causing large performance drops. Scaling saturates quickly, general reasoning does not transfer reliably to creative discovery, and inference-time methods like Chain-of-Thought yield limited gains. The work positions the benchmark as a testbed for this dimension of intelligence with implications for agent planning.
Significance. If the KB and tasks can be shown to isolate creative affordance reasoning without substantial confounds from annotation errors or alternative valid solutions, the results would be significant for highlighting a persistent gap in LLM capabilities beyond standard reasoning benchmarks. The scale of the resource is a clear strength and could serve as a useful testbed for future agent research. However, the current lack of validation details limits the strength of the conclusions.
major comments (2)
- [§3] §3 (Affordance Knowledge Base): No validation details, inter-annotator agreement, or error-rate estimates are reported for the 150K+ annotations. This is load-bearing for the central claim because modest annotation errors could mislabel valid creative repurposings as failures, so that observed performance drops may reflect KB incompleteness rather than deficits in creative reasoning.
- [§4] §4 (Task Generation): The method for generating the 14K tasks does not describe any filtering to ensure the KB-designated mechanism is the unique physically plausible solution or to exclude tasks admitting equally valid non-KB alternatives. Without this, model failures cannot be unambiguously attributed to missing creative reasoning rather than benchmark construction artifacts.
minor comments (2)
- [Abstract] Abstract and §5 (Experiments): The abstract reports performance drops but supplies no concrete metrics for scoring parts/affordances/mechanisms, no baseline details, and no statistical significance tests, making it hard to gauge the reliability of the cross-model comparisons.
- [§5] §5 (Experiments): Adding a small number of qualitative task examples with model outputs in the main text (rather than solely in the appendix) would help readers understand the precise nature of the identified failures.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address each major comment below and have revised the manuscript to provide the requested validation details and clarifications.
read point-by-point responses
-
Referee: [§3] §3 (Affordance Knowledge Base): No validation details, inter-annotator agreement, or error-rate estimates are reported for the 150K+ annotations. This is load-bearing for the central claim because modest annotation errors could mislabel valid creative repurposings as failures, so that observed performance drops may reflect KB incompleteness rather than deficits in creative reasoning.
Authors: We agree that explicit validation details are necessary to substantiate the central claims. The knowledge base was assembled by integrating structured data from multiple public resources on object attributes and uses, followed by targeted manual review by the authors to ensure grounding in physical properties. In the revised manuscript we have expanded §3 with a new subsection that describes the full construction pipeline, the cross-referencing steps used to link objects, parts, attributes, and uses, and the results of a post-hoc manual audit performed on a random sample of annotations. This addition directly addresses the possibility that annotation errors are driving the reported performance gaps. revision: yes
-
Referee: [§4] §4 (Task Generation): The method for generating the 14K tasks does not describe any filtering to ensure the KB-designated mechanism is the unique physically plausible solution or to exclude tasks admitting equally valid non-KB alternatives. Without this, model failures cannot be unambiguously attributed to missing creative reasoning rather than benchmark construction artifacts.
Authors: We acknowledge that some tasks may admit multiple physically plausible solutions and that the original description of the generation procedure was insufficiently detailed. The tasks are constructed by selecting constraints that make the canonical use inapplicable, thereby requiring the model to discover a non-obvious part-attribute-use chain from the KB. In the revised manuscript we have expanded §4 to include the precise generation algorithm, the heuristics applied to enforce physical plausibility, and an explicit statement that the benchmark evaluates whether a model can recover the KB-specified creative solution rather than every possible solution. We have also added a short analysis of a sampled subset of tasks confirming that the designated mechanism is the most direct creative repurposing under the given constraints. These changes clarify how failures can be attributed to limitations in affordance-based creative reasoning. revision: yes
Circularity Check
No circularity: purely empirical benchmark construction and evaluation
full rationale
The paper builds an affordance KB from 4K entities and 150K+ annotations, generates 14K tasks, and reports LLM performance metrics across 10 models. No equations, derivations, fitted parameters, or predictions exist that could reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. All claims rest on external experimental outcomes rather than self-referential logic, satisfying the default non-circular expectation for benchmark papers.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we build a large-scale affordance knowledge base (KB) with 4K entities and 150K+ affordance annotations, explicitly linking objects, parts, attributes, and actionable uses... generate 14K grounded tasks
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
models can often select a plausible object, but fail to identify the correct parts, their affordances, and the underlying physical mechanism
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Use only tools/items explicitly available in the task description. 27 Preprint. Under review
-
[6]
If a complete solution is impossible, return the best partial plan and explain why it cannot be completed. TASK DESCRIPTION: {problem} Return JSON: {{ "solvable": "Yes or No", "solvable_explanation": "1-3 sentences about why the given task is solvable or not", "solution_steps": ["Step 1: ...", "Step 2: ...", ...], "final_solution": "One concise paragraph ...
-
[7]
Use only tools/items explicitly available in the task description
-
[8]
Respect physical constraints if the task description restricts physical attributes such as size or state
-
[9]
Invent new tools using tools/items explicitly available in the task description if it is needed
-
[10]
Provide practical steps that can actually be executed
-
[11]
Do not involve any unnecessary steps to achieve the task's goal
-
[12]
If a complete solution is impossible, return the best partial plan and explain why it cannot be completed. Required reasoning procedure:
-
[13]
State the task goal and concrete success condition
-
[14]
List all available tools/items from the prompt (no additions)
-
[15]
For each relevant tool, identify the key part(s), infer physical properties, and derive part-level affordances useful for this task
-
[16]
Build a step-by-step plan where each step references tool parts and the affordance being used
-
[17]
Validate each step against stated constraints (e.g., broken/unusable items, size mismatch, blocked function, state limitations)
-
[18]
Keep the plan practical and minimal with no unnecessary actions. TASK DESCRIPTION: {problem} Return JSON: {{ "task_goal": "...", "success_condition": "...", "identified_constraints": ["...", "..."], "tool_inventory": [ {{ "tool": "...", "relevant_parts": [ {{ "part": "... or NA", "inferred_physical_properties": ["...", "..."], "affordances_for_task": [".....
-
[19]
win" if solution1_score > solution2_score -
Determine winner: - "win" if solution1_score > solution2_score - "lose" if solution2_score > solution1_score - "tie" if both are equal
-
[20]
Give a short rationale (1-2 sentences). 32 Preprint. Under review. TASK DESCRIPTION: {problem} GROUND-TRUTH SOLUTION: {ground_truth_solution} CANDIDATE SOLUTION1 (DEFAULT PROMPT OUTPUT): {solution1} CANDIDATE SOLUTION2 (COT PROMPT OUTPUT): {solution2} Return STRICT JSON: {{ "correctness": {{ "winner": "win or lose or tie", "rationale": "1-2 sentences." }}...
-
[21]
List ALL the common parts (both externally visible and internally hidden ones)
-
[22]
Limit to 8 parts maximum, can be less if the object is simple and parts are obvious
-
[23]
Your parts should better have explicit boundaries which divide the object's different function units or affordance mechanisms
-
[24]
Include components that may have useful affordances themselves (e.g. screws, batteries, etc.)
-
[25]
a blade contains cutting edge, so it's one part)
Parts must be non-overlapping and cover the whole object (e.g. a blade contains cutting edge, so it's one part)
-
[26]
Imagine a specific entity when you annotate the parts, don't include any optional parts or uncertain wording, all parts should be necessary and essential to the entity's function
-
[27]
Parts with same function differing only by position or direction should be annotated as ONE part
-
[28]
For each part: specify connected parts and describe function/connection **Schema:** ```json {{ "entity_name": "...", "parts": ["part1", "part2", ...], "relations": {{ "part1": {{ "connected_to": ["part2", "part3"], "connection": "Description of part1, its function, and connection" }}, ... }} }} ``` **Example (prescription reading glasses):** ```json {{ "e...
-
[29]
**Geometry & Shape:** shape, size, thickness (thin/medium/thick/NA), local_features
-
[30]
**Material & Structural:** material, rigidity (very rigid/rigid/semi-rigid/flexible/soft), durability (very fragile/fragile/normal/sturdy/very sturdy), elasticity (non-elastic/springy/stretchable/very stretchable), surface
-
[31]
**Mass:** weight (very light/light/moderate/heavy/very heavy)
-
[32]
**Others:** Other important attributes for affordance (1-2 sentences)
-
[33]
NA" only if truly not important for creative affordance - Be assertive; avoid
**Summary:** Comprehensive summary of all attributes **Requirements:** - Generate 2-3 physical attribute combinations for this part - Each combination must be plausible, internally consistent, and diverse - Include common variations (e.g., plastic vs steel) - Include one unusual but plausible variation if it creates distinctive affordances - All fields re...
-
[34]
**Access State:** - Visibility: visible, partially visible, hidden (relative to whole entity) - Availability: free, partially blocked (easily freed by hand), blocked (requires tools)
-
[35]
**Condition State:** - Moisture: dry, slightly wet, wet, NA - Temperature: cold, slightly cold, slightly hot, hot, NA (room temp)
-
[36]
**Internal State:** - Internal: empty, partially filled, full, NA (physical or abstract capacity)
-
[37]
**Others:** Other important state attributes (1-2 sentences)
-
[38]
NA" if not important - Be assertive; avoid
**Summary:** Comprehensive summary of all state attributes **Requirements:** - Generate 2-3 state attribute combinations for this part - Must be consistent with physical attributes - Include common/typical state and unusual but plausible states - All combinations must be plausible, consistent, and diverse - All fields required; use "NA" if not important -...
-
[39]
NA" if part is free and directly usable - Otherwise describe preparation steps (e.g.,
**Use Condition:** What preparation is needed to access this affordance? - "NA" if part is free and directly usable - Otherwise describe preparation steps (e.g., "break the lens", "remove from case") - Based on visibility/availability from state attributes
-
[40]
**Environment Condition:** What environmental conditions are needed for this affordance? - Focus on scenario/environment requirements (e.g., "lighting available", "power source nearby") - NOT about the part itself or recipient, but about external conditions - "NA" if no special environment needed
-
[41]
**Attribute:** What attributes enable this affordance? - List relevant attributes that are needed to be considered for this affordance; your stated attributes must be derived from the given physical + state attributes above; do not introduce new attributes that are not provided - Format: JSON list of lists`[["attribute statement", "physical/state", "visua...
-
[42]
**Affordance:** What can this part be used for? - Brief, clear description of the function/purpose - Can be original normal function (must have at least one original normal function) OR creative alternative use - Must be plausible and grounded in this part's given physical and state attributes above - Must act upon a recipient to take effect: passive or d...
-
[43]
**Level:** Categorize the affordance type and suitability - "Normal 0" = Original intended normal function of the part within the entity (must have at least one original normal function) - "Emergency 1-5" = Creative/alternative use - 1 = Rarely used, only if nothing else available; difficult to access or imperfect; in real life people rarely use this affo...
-
[44]
thin to medium thickness, soft to semi-rigid rigidity, not harder than glass
**Recipient Condition:** What attributes must the recipient have? - Every affordance must have a recipient. It can be the object, person, or material that this part acts upon - Define scope and limits using attribute categories (shape, size, rigidity, durability, surface, etc.) - Be fine-grained and comprehensive - Example: "thin to medium thickness, soft...
-
[45]
**Example Recipient:** List 3-4 concrete examples - Must satisfy the recipient condition - The proposed recipient must be concrete and specific things or objects that can be easily found in real life, rather than abstract concepts or ideas - Choose diverse examples reflecting affordance scope
-
[46]
**Failure Case:** When will this affordance NOT work? - Comprehensively consider all failure situations: * Use condition failures (can't access/prepare the part) * Environment condition failures (lack of necessary environmental factors) * Recipient condition failures (recipient too hard/thick/incompatible) * Action condition failures (user lacks skill/for...
-
[47]
NA"): - 0: required external environment setup in gold is not mentioned at all in the predicted
environment_condition_covered (0/1/2/"NA"): - 0: required external environment setup in gold is not mentioned at all in the predicted "how_to_use". - 1: required external environment setup in gold is mentioned, but not all are covered in the predicted " how_to_use". - 2: required external environment setup in gold is covered well and reasonable in the pre...
-
[48]
NA"): - 0: required preparation/access of the tool-part is not mentioned at all in the predicted
use_condition_covered (0/1/2/"NA"): - 0: required preparation/access of the tool-part is not mentioned at all in the predicted "how_to_use". - 1: required preparation/access of the tool-part is mentioned, but not all are covered in the predicted " how_to_use". 46 Preprint. Under review. - 2: required preparation/access of the tool-part is covered well and...
-
[49]
NA"): - 0: recipient-side prerequisites are not mentioned at all in the predicted
recipient_condition_covered (0/1/2/"NA"): - 0: recipient-side prerequisites are not mentioned at all in the predicted "how_to_use". - 1: recipient-side prerequisites are mentioned, but not all are covered in the predicted "how_to_use". - 2: recipient-side prerequisites are covered well and reasonable. - False: recipient assumptions are not met in the pred...
-
[50]
attributes_grounding (0/1/2): [compare to the key enabling attributes] - 0: the predicted action is not grounded in the key enabling attributes of the gold affordance, or it violates some attributes of the part. - 1: the predicted action is mostly grounded in the key enabling attributes of the gold affordance, but not all are covered or implied. - 2: the ...
-
[51]
prediction_correctness (0/1/2): [compare to the gold solution] - 0: compared with the gold solution the predicted "how_to_use" is completely wrong, not working at all. - 1: compared with the gold solution the predicted "how_to_use" is partially workable but missing crucial details/ order/precision. - 2: compared with the gold solution the predicted "how_t...
-
[52]
action_feasibility (0/1/2): [not compare to the gold solution, but focus on the action itself] - 0: the action itself is physically impossible, not working at all, very unlikely to be used in practice, or unsafe. - 1: the action itself is partially workable but still there are some steps that are not plausible, aligned with common sense or not feasible. -...
-
[53]
NA"): [Do NOT directly compare with the gold, it's only for reference] -
environment_condition_covered (0/1/2/"NA"): [Do NOT directly compare with the gold, it's only for reference] - "NA": in your reasoning, deeply consider for the predicted use of the part to accomplish the task, if the external environment setup is needed; if not, then please give "NA". - 0: the environment setup is needed but in the predicted use, it is no...
-
[54]
NA"): [Do NOT directly compare with the gold, it's only for reference] -
use_condition_covered (0/1/2/"NA"): [Do NOT directly compare with the gold, it's only for reference] - "NA": in your reasoning,deeply consider for the predicted use of the part to accomplish the task, if the preparation/access of the part is needed; if not, then please give "NA". - 0: the preparation/access of the part is needed but in the predicted use, ...
-
[55]
NA"): [Do NOT directly compare with the gold, it's only for reference] -
recipient_condition_covered (0/1/2/"NA"): [Do NOT directly compare with the gold, it's only for reference] - "NA": in your reasoning, deeply consider for the predicted use of the part to accomplish the task, if the recipient-side prerequisites are needed; if not, then please give "NA". - 0: the recipient-side prerequisites are needed but in the predicted ...
-
[56]
attributes_grounding (0/1/2): [Compare with the physical and state attributes of the predicted part] - 0: the predicted action is not grounded in the key enabling attributes of the part, or it violates some attributes of the part. - 1: the predicted action is mostly grounded in the key enabling attributes of the gold affordance, but not all are covered or...
-
[57]
environment_condition_covered_reason
action_feasibility (0/1/2): [Please only focus on the predicted action itself] - 0: the action itself is physically impossible, not working at all, very unlikely to be used in practice, or unsafe. - 1: the action itself is partially workable but still there are some steps that are not plausible, aligned with common sense or not feasible. - 2: the action i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.