Recognition: 3 theorem links
· Lean TheoremFluxFlow: Conservative Flow-Matching for Astronomical Image Super-Resolution
Pith reviewed 2026-05-08 18:51 UTC · model grok-4.3
The pith
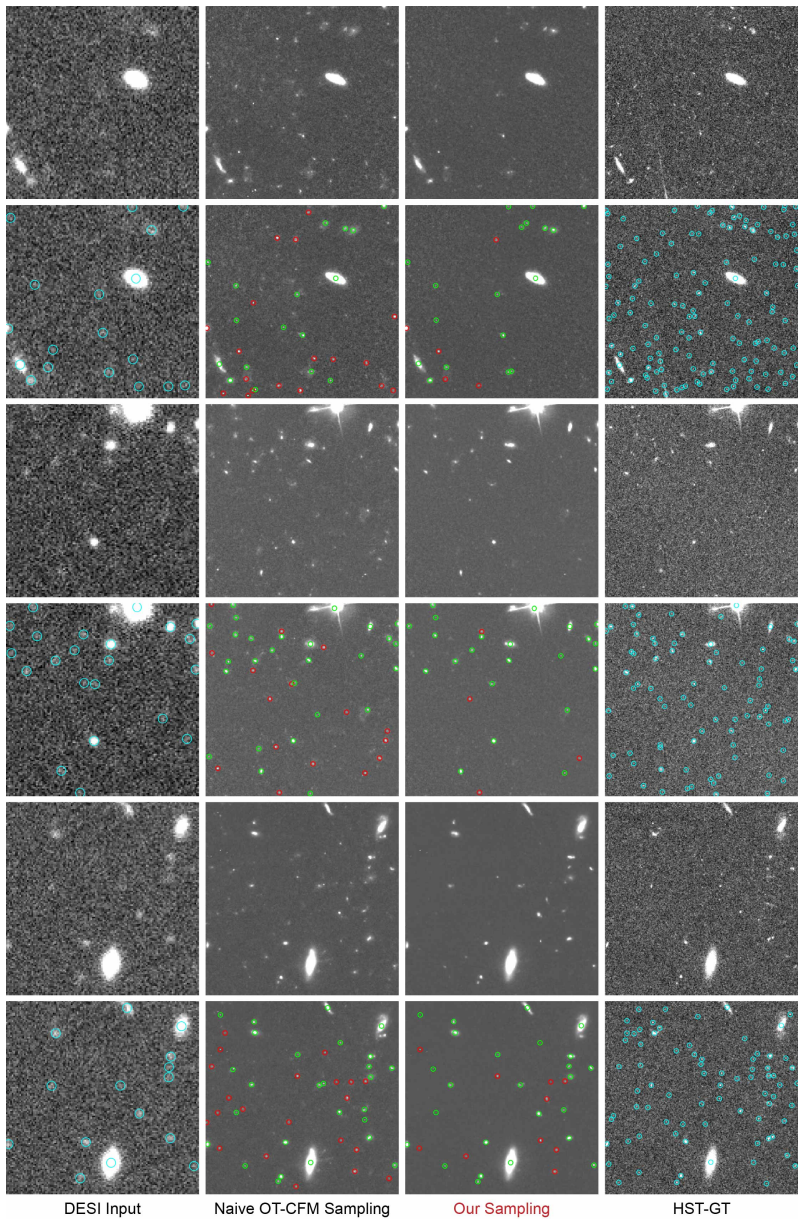
FluxFlow recovers space-quality astronomical images from ground observations using conservative flow-matching that accounts for uncertainties and suppresses hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FluxFlow establishes that conservative pixel-space flow-matching, when trained with observation uncertainty and source-region importance weights and paired with a training-free Wiener-regularized correction at test time, delivers super-resolved astronomical images with superior photometric and scientific accuracy on real ground-to-space pairs compared to baseline methods.
What carries the argument
Conservative pixel-space flow-matching framework that integrates observation uncertainty, source-region importance weights during training, and a Wiener-regularized test-time correction.
Load-bearing premise
That weighting training by observation uncertainty and source importance, combined with the Wiener correction, will consistently prevent hallucinations across varying real atmospheric conditions not fully represented in the dataset.
What would settle it
If FluxFlow produces images with more hallucinated features or poorer scientific metrics than simpler methods when tested on fresh, independent ground-to-space image pairs with different seeing conditions, the central claim would be falsified.
Figures






























read the original abstract
Ground-to-space astronomical super-resolution requires recovering space-quality images from ground-based observations that are simultaneously limited by pixel sampling resolution and atmospheric seeing, which imposes a stochastic, spatially varying PSF that cannot be resolved through upsampling alone. Existing methods rely on synthetic training pairs that fail to capture real atmospheric statistics and are prone to either over-smoothed reconstructions or hallucination sources with no physical counterpart in the observed sky. We propose FluxFlow, a conservative pixel-space flow-matching framework that incorporates observation uncertainty and source-region importance weights during training, and a training-free Wiener-regularized test-time correction to suppress hallucination sources while preserving recovered detail. We further construct the DESI--HST Dataset, the large-scale real-world benchmark comprising 19,500 real co-registered ground-to-space image pairs with real atmospheric PSF variation. Experiments demonstrate that FluxFlow consistently outperforms existing baseline methods in both photometric and scientific accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FluxFlow, a pixel-space flow-matching framework for ground-to-space astronomical image super-resolution. It incorporates observation uncertainty and source-region importance weights during training, along with a training-free Wiener-regularized test-time correction to mitigate hallucinations while preserving detail. The authors also construct the DESI-HST dataset of 19,500 real co-registered ground-to-space image pairs exhibiting real atmospheric PSF variation and report that FluxFlow outperforms existing baselines in both photometric and scientific accuracy.
Significance. If the experimental claims hold, the work could meaningfully advance astronomical imaging by shifting from synthetic training pairs (which fail to capture real atmospheric statistics) to real paired data and a conservative flow-matching approach explicitly designed to suppress non-physical hallucinations. The emphasis on uncertainty weighting, importance sampling, and the Wiener correction provides a principled way to handle spatially varying PSFs, which is load-bearing for scientific usability of the outputs.
minor comments (3)
- The abstract states that FluxFlow 'consistently outperforms existing baseline methods in both photometric and scientific accuracy' but provides no numerical values, error bars, or specific metrics (e.g., RMSE, PSNR, or scientific figure-of-merit). Adding one or two key quantitative results would strengthen the summary.
- Section describing the Wiener-regularized test-time correction should explicitly state the regularization parameter schedule and how it interacts with the flow-matching velocity field; the current description leaves the exact implementation of the 'conservative' property somewhat implicit.
- The DESI-HST dataset construction paragraph would benefit from a brief statement on the co-registration accuracy and the distribution of seeing FWHM values across the 19,500 pairs to allow readers to assess how representative the benchmark is of typical ground-based conditions.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on FluxFlow and the recommendation for minor revision. The referee summary correctly describes the pixel-space flow-matching framework, the use of uncertainty and importance weights, the Wiener test-time correction, and the construction of the real DESI-HST dataset. We are pleased that the potential impact on handling real atmospheric PSFs and suppressing non-physical hallucinations is recognized.
Circularity Check
No significant circularity detected
full rationale
The paper's method is presented as a pixel-space flow-matching framework that augments established flow-matching with observation uncertainty weighting, source-region importance, and a training-free Wiener-regularized correction; none of these elements are shown to be defined in terms of the target photometric or scientific accuracy metrics. The central performance claims rest on experiments using the newly introduced DESI-HST real co-registered pairs rather than on any self-referential fit or prediction that reduces to the inputs by construction. No load-bearing self-citation chains, uniqueness theorems, or ansatz smuggling are indicated in the provided description, leaving the derivation self-contained against external benchmarks and real data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.LogicAsFunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt the optimal-transport (OT) conditional path: p_t(x|x_0,x_1) = N(x | tx_1+(1-t)x_0, σ_min² I) ... u_t(x|x_0,x_1) = x_1 - x_0
-
IndisputableMonolith.Cost (Jcost)Jcost_unit0 / Jcost_pos_of_ne_one unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
W(k) = H*(k) / (|H(k)|² + λ_SNR⁻¹) ... Wiener-regularized approximate adjoint
-
Foundation.AlphaDerivationExplicitalphaProvenanceCert (parameter-free constants) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AdamW (lr=1e-4), 300 epochs, batch size 32, λ_SNR=50, η₀=0.5, σ_PSF=2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Beyond Model Design: Data-Centric Training and Self-Ensemble for Gaussian Color Image Denoising
Gengjia Chang, Xining Ge, Weijun Yuan, Zhan Li, Qiurong Song, Luen Zhu, and Shuhong Liu. Beyond model design: Data-centric training and self-ensemble for gaussian color image denoising. arXiv preprint arXiv:2604.11468, 2026a. Gengjia Chang, Xining Ge, Weijun Yuan, Zhan Li, Qiurong Song, Luen Zhu, and Shuhong Liu. Training-free model ensemble for single-im...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Xiangyu Chen, Xintao Wang, Jiantao Zhou, Yu Qiao, and Chao Dong. Activating more pixels in image super-resolution transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22367–22377, 2023a. Xiangyu Chen, Xintao Wang, Wenlong Zhang, Xiangtao Kong, Yu Qiao, Jiantao Zhou, and Chao Dong. Hat: Hybrid attention tr...
work page internal anchor Pith review arXiv
-
[3]
Training Flow Matching: The Role of Weighting and Parameterization
Anne Gagneux, Ségolène Martin, Rémi Gribonval, and Mathurin Massias. Training flow matching: The role of weighting and parameterization.arXiv preprint arXiv:2603.06454,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Dual-Branch Remote Sensing Infrared Image Super-Resolution
Xining Ge, Gengjia Chang, Weijun Yuan, Zhan Li, Zhanglu Chen, Boyang Yao, Yihang Chen, Yifan Deng, and Shuhong Liu. Dual-branch remote sensing infrared image super-resolution.arXiv preprint arXiv:2604.10112, 2026a. Xining Ge, Weijun Yuan, Gengjia Chang, Xuyang Li, and Shuhong Liu. Clip-guided data augmenta- tion for night-time image dehazing.arXiv preprin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review arXiv
-
[6]
Bbdm: Image-to-image translation with brownian bridge diffusion models
Bo Li, Kaitao Xue, Bin Liu, and Yu-Kun Lai. Bbdm: Image-to-image translation with brownian bridge diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1952–1961,
1952
-
[7]
arXiv preprint arXiv:2502.01993 (2025)
Boyun Li, Haiyu Zhao, Wenxin Wang, Peng Hu, Yuanbiao Gou, and Xi Peng. Mair: A locality-and continuity-preserving mamba for image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7491–7501, 2025a. Jianze Li, Jiezhang Cao, Yong Guo, Wenbo Li, and Yulun Zhang. One diffusion step to real-world super-reso...
-
[8]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720,
work page internal anchor Pith review arXiv
-
[9]
A self-attention based srgan for super-resolution of astro- nomical image
Wanjun Li, Zhe Liu, and Hongtao Deng. A self-attention based srgan for super-resolution of astro- nomical image. In2022 IEEE 8th International Conference on Computer and Communications, pages 1977–1981. IEEE,
1977
-
[10]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
-
[11]
I2SB: Image-to-image Schrödinger bridge.arXiv preprint arXiv:2302.05872,
Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A Theodorou, Weili Nie, and Anima Anandkumar. I2SB: Image-to-image Schrödinger bridge.arXiv preprint arXiv:2302.05872,
-
[12]
Shuhong Liu, Chenyu Bao, Ziteng Cui, Yun Liu, Xuangeng Chu, Lin Gu, Marcos V Conde, Ryo Umagami, Tomohiro Hashimoto, Zijian Hu, et al. Realx3d: A physically-degraded 3d benchmark for multi-view visual restoration and reconstruction.arXiv preprint arXiv:2512.23437, 2025a. Shuhong Liu, Xiang Chen, Hongming Chen, Quanfeng Xu, and Mingrui Li. Deraings: Gaussi...
-
[13]
Naoki Matsunaga, Masato Ishii, Akio Hayakawa, Kenji Suzuki, and Takuya Narihira. Fine-grained image editing by pixel-wise guidance using diffusion models.arXiv preprint arXiv:2212.02024,
-
[14]
Diamond: Directed inference for artifact mitigation in flow matching models
Alicja Polowczyk, Agnieszka Polowczyk, Piotr Borycki, Joanna Waczy ´nska, Jacek Tabor, and Przemysław Spurek. Diamond: Directed inference for artifact mitigation in flow matching models. arXiv preprint arXiv:2602.00883,
-
[15]
Flower: A flow-matching solver for inverse problems.arXiv preprint arXiv:2509.26287,
Mehrsa Pourya, Bassam El Rawas, and Michael Unser. Flower: A flow-matching solver for inverse problems.arXiv preprint arXiv:2509.26287,
-
[16]
Generative AI for image reconstruction in Intensity Interferometry: a first attempt
Km Nitu Rai, Yuri van der Burg, Soumen Basak, Prasenjit Saha, and Subrata Sarangi. Generative ai for image reconstruction in intensity interferometry: a first attempt.arXiv preprint arXiv:2508.03398,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
The eleventh NTIRE 2026 efficient super-resolution challenge report
Bin Ren, Hang Guo, Yan Shu, Jiaqi Ma, Ziteng Cui, Shuhong Liu, Guofeng Mei, Lei Sun, Zongwei Wu, Fahad Shahbaz Khan, Salman Khan, Radu Timofte, Yawei Li, et al. The eleventh NTIRE 2026 efficient super-resolution challenge report. InProceedings of the Computer Vision and Pattern Recognition Conference Workshops,
2026
-
[18]
Palette: Image-to-image diffusion models
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. InACM SIGGRAPH 2022 Conference Proceedings, pages 1–10, 2022a. Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J Fleet, and Mohammad Norouzi. Image super-resolution via iterative re...
2022
-
[19]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page Pith review arXiv 2011
-
[20]
Improving and generalizing flow-based generative models with minibatch optimal transport
Alexander Tong, Kilian Fatras, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector- Brooks, Guy Wolf, and Yoshua Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.arXiv preprint arXiv:2302.00482,
work page internal anchor Pith review arXiv
-
[21]
Star: A benchmark for astronomical star fields super-resolution.arXiv preprint arXiv:2507.16385,
Kuo-Cheng Wu, Guohang Zhuang, Jinyang Huang, Xiang Zhang, Wanli Ouyang, and Yan Lu. Star: A benchmark for astronomical star fields super-resolution.arXiv preprint arXiv:2507.16385,
-
[22]
Dichang Zhang, Yixuan Shao, Simon Birrer, and Dimitris Samaras
URL https://openreview.net/forum?id=TwvnG6mobR. Dichang Zhang, Yixuan Shao, Simon Birrer, and Dimitris Samaras. As-bridge: A bidirectional gener- ative framework bridging next-generation astronomical surveys.arXiv preprint arXiv:2603.11928,
-
[23]
Guided flows for generative modeling and decision making.arXiv preprint arXiv:2311.13443, 2023
Xiang Zhang, Yulun Zhang, and Fisher Yu. Hit-sr: Hierarchical transformer for efficient image super-resolution. InEuropean Conference on Computer Vision, pages 483–500. Springer, 2024a. Yasi Zhang, Peiyu Yu, Yaxuan Zhu, Yingshan Chang, Feng Gao, Ying N Wu, and Oscar Leong. Flow priors for linear inverse problems via iterative corrupted trajectory matching...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.