Recognition: 2 theorem links
· Lean TheoremDeployment-Relevant Alignment Cannot Be Inferred from Model-Level Evaluation Alone
Pith reviewed 2026-05-08 18:08 UTC · model grok-4.3
The pith
Deployment-relevant alignment cannot be inferred from model-level evaluation alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that deployment-relevant alignment cannot be inferred from model-level evaluation alone. Alignment claims should instead be indexed to the level at which evidence is collected: model-level, response-level, interaction-level, or deployment-level. This position rests on a structured audit of eleven alignment benchmarks extended to sixteen, which finds user-facing verification support absent and process steerability nearly absent across the corpus, plus a blinded stress test with 180 transcripts across three frontier models and four scaffolds showing that scaffold efficacy is model-dependent.
What carries the argument
The indexing of alignment evidence to four distinct levels (model, response, interaction, deployment), with benchmarks evaluated for presence of user-facing verification support and process steerability.
If this is right
- Alignment claims must be limited to the exact evidence level at which they were collected.
- Benchmarks require added features for user verification of outputs and steering of processes.
- Interaction evaluations need fixed-scaffolding protocols so results can be compared across models.
- Reporting must explicitly state the inferential distance between the collected evidence and any deployment claim.
- Alignment assessment should shift from single benchmark scores to multi-level profiles.
Where Pith is reading between the lines
- Deployers would need separate interaction and deployment testing rather than relying on public model leaderboards.
- The model-dependence of scaffolds may explain why some models that pass benchmarks still produce misaligned outputs in practice.
- Standardized interaction-level benchmarks could be developed to close the gaps the audit identified.
- Full deployment monitoring might become necessary to validate alignment beyond what controlled tests can show.
Load-bearing premise
The sixteen benchmarks audited and the stress test on three specific frontier models with 180 transcripts are representative enough to conclude that model-level evaluation is insufficient for deployment claims in general.
What would settle it
A demonstration that high scores on current model-level alignment benchmarks reliably predict aligned behavior across varied scaffolds, users, and deployment contexts without further testing.
Figures




read the original abstract
Alignment evaluation in machine learning has largely become evaluation of models. Influential benchmarks score model outputs under fixed inputs, such as truthfulness, instruction following, or pairwise preference, and these scores are often used to support claims about deployed alignment. This paper argues that deployment-relevant alignment cannot be inferred from model-level evaluation alone. Alignment claims should instead be indexed to the level at which evidence is collected: model-level, response-level, interaction-level, or deployment-level. Two studies support this position. First, a structured audit of eleven alignment benchmarks, extended to a sixteen-benchmark corpus, dual-coded against an eight-dimension rubric with Cohen's kappa = 0.87, finds that user-facing verification support is absent across every benchmark examined, while process steerability is nearly absent. The few interactional benchmarks identified, including tau-bench, CURATe, Rifts, and Common Ground, remain fragmented in coverage, and benchmark construction rather than data source determines what is measured. Second, a blinded cross-model stress test using 180 transcripts across three frontier models and four scaffolds finds that the same verification scaffold raises one model's verification support to ceiling while leaving another categorically unchanged. This shows that scaffold efficacy is model-dependent and that the gap identified by the audit cannot be closed at the model level alone. We propose a system-level evaluation agenda: alignment profiles instead of single scores, fixed-scaffolding protocols for comparable interactional evaluation, and reporting templates that make the inferential distance between evaluation evidence and deployment claims explicit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
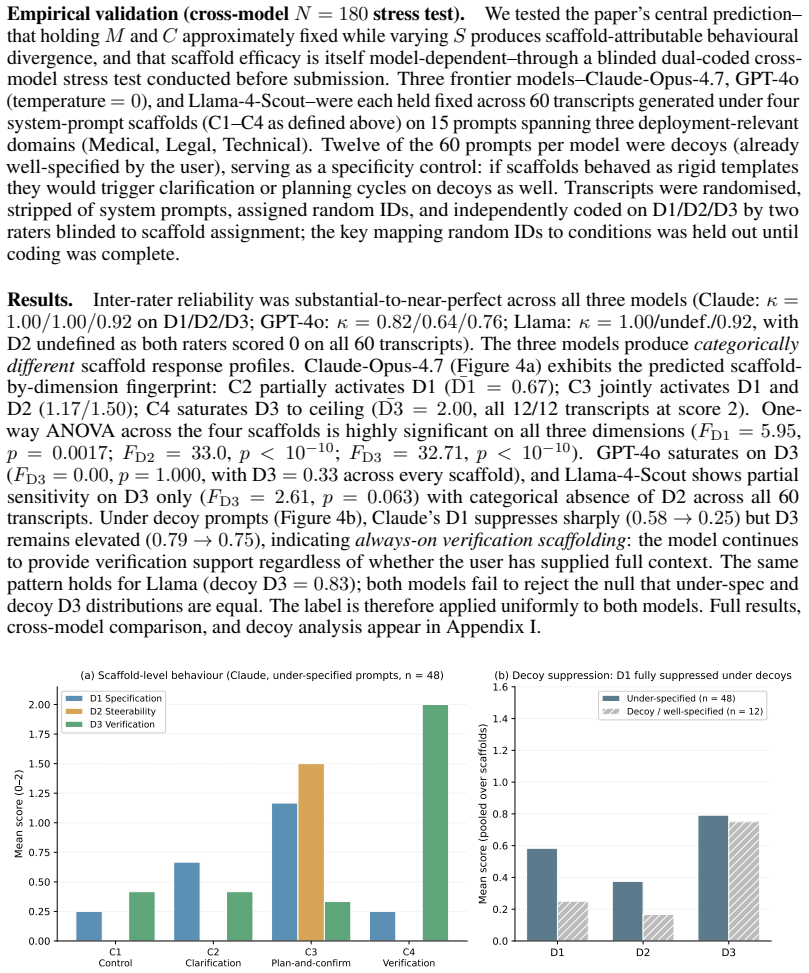
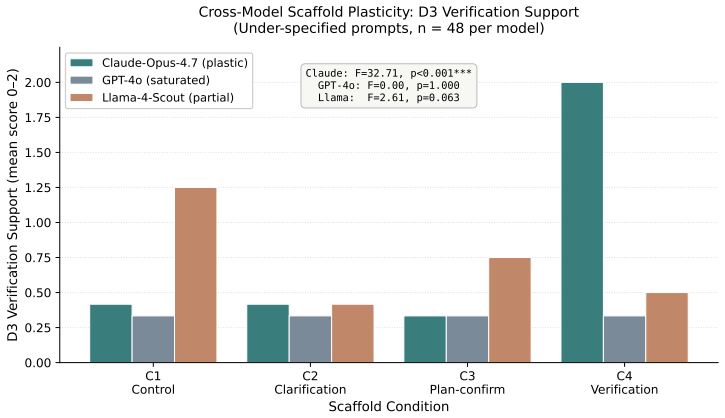
Summary. The paper claims that deployment-relevant alignment cannot be inferred from model-level evaluation alone. Model-level benchmarks (fixed inputs, scored outputs on truthfulness, instruction-following, etc.) are insufficient to support claims about deployed systems; alignment evidence must instead be indexed to the level at which it is collected (model, response, interaction, or deployment). This is supported by two studies: a dual-coded audit (Cohen’s κ=0.87) of an eleven-benchmark set extended to sixteen, which finds user-facing verification support absent and process steerability nearly absent across all examined benchmarks, with the few interactional ones (tau-bench, CURATe, Rifts, Common Ground) remaining fragmented; and a blinded stress test using 180 transcripts across three frontier models and four scaffolds, which shows the same verification scaffold raises one model’s verification support to ceiling while leaving another unchanged, demonstrating model-dependent scaffold efficacy that cannot be closed at the model level.
Significance. If the central claim and supporting evidence hold, the work would meaningfully shift evaluation practice in AI alignment by making explicit the inferential distance between current model-level scores and deployment claims. It supplies a concrete audit rubric and a cross-model interaction protocol that could be adopted as templates, and it correctly identifies that benchmark construction (rather than data source) largely determines what is measured. The proposal for alignment profiles, fixed-scaffolding protocols, and explicit reporting templates addresses a genuine gap in how alignment claims are currently justified.
major comments (1)
- [Blinded cross-model stress test] Blinded cross-model stress test: the design does not report or control for baseline model-level alignment scores (e.g., on the verification or truthfulness benchmarks from the audit corpus) of the three frontier models before scaffold application. Without these baselines, the observed differential response (one model reaching ceiling, another unchanged) is consistent with pre-existing model-level differences and does not yet demonstrate an interaction effect that cannot be reduced to model-level metrics. This directly affects the load-bearing inference that “the gap identified by the audit cannot be closed at the model level alone.”
minor comments (2)
- The audit reports Cohen’s κ=0.87 but does not break down agreement per rubric dimension or describe how disagreements were resolved; adding this would strengthen reproducibility of the eight-dimension coding.
- The abstract states the audit covered “eleven alignment benchmarks, extended to a sixteen-benchmark corpus,” but the manuscript should clarify the exact selection criteria and list the additional five benchmarks to allow readers to assess coverage.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The feedback on the blinded cross-model stress test is well-taken and highlights an opportunity to strengthen the presentation of our results. We address the comment point-by-point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Blinded cross-model stress test] Blinded cross-model stress test: the design does not report or control for baseline model-level alignment scores (e.g., on the verification or truthfulness benchmarks from the audit corpus) of the three frontier models before scaffold application. Without these baselines, the observed differential response (one model reaching ceiling, another unchanged) is consistent with pre-existing model-level differences and does not yet demonstrate an interaction effect that cannot be reduced to model-level metrics. This directly affects the load-bearing inference that “the gap identified by the audit cannot be closed at the model level alone.”
Authors: We appreciate the referee identifying this gap in the reported design. The stress test was intended to demonstrate that identical scaffolds produce model-dependent outcomes at the interaction level, thereby showing that deployment-relevant alignment evidence cannot be reduced to model-level metrics. While the three frontier models were selected for their comparable overall capabilities, we agree that explicit pre-scaffold baselines on the verification and truthfulness items from the audit rubric would more directly address the possibility of pre-existing differences. In the revised manuscript we have added these baselines (obtained by evaluating each model on the relevant audit items with no scaffold applied). The baselines were comparable across models, yet the same verification scaffold still produced the reported ceiling effect in one model and no change in another. We have updated the methods, results, and discussion sections to include the baseline values, a statistical note on their similarity, and an explicit statement that the interaction effect persists after accounting for them. This revision directly supports the claim that the audit-identified gap cannot be closed at the model level alone. revision: yes
Circularity Check
No significant circularity; empirical studies are self-contained
full rationale
The paper derives its central claim through two independent empirical components—an audit of sixteen benchmarks coded against an eight-dimension rubric and a blinded stress test on 180 transcripts with three models and four scaffolds—rather than any self-definitional mapping, fitted parameter renamed as prediction, or load-bearing self-citation. No equations appear in the derivation, and the argument that deployment-relevant alignment requires indexed evidence at interaction or deployment levels follows directly from the observed absence of user-facing verification support and the model-dependent scaffold effects, without presupposing the conclusion in the inputs or reducing to prior author work by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The eight-dimension rubric accurately measures user-facing verification support and process steerability in alignment benchmarks
- domain assumption The three frontier models and four scaffolds in the stress test are sufficient to demonstrate model-dependent scaffold efficacy
Lean theorems connected to this paper
-
Foundation/AlexanderDuality.lean (RS 8-tick comes from 2^D=8 with D=3); paper's '8 dimensions' are unrelated HCI categories with no ratio-symmetric or periodicity content.alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
an eight-dimension rubric ... D1 Specification, D2 Process, D3 Verification, D4 Multi-turn, D5 Grounding, D6 Repair, D7 Personalization, D8 Workflow
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lize Alberts, Benjamin Ellis, Andrei Lupu, and Jakob Foerster. CURATe: Benchmarking personalised alignment of conversational AI assistants.arXiv preprint arXiv:2410.21159, 2024
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review arXiv 2022
-
[3]
Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael I
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios N. Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael I. Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference. InProceedings of the International Conference on Machine Learning (ICML), 2024
2024
- [4]
-
[5]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data.Biometrics, 33(1):159–174, 1977
1977
-
[6]
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-Hard and BenchBuilder pipeline.arXiv preprint arXiv:2406.11939, 2024
-
[7]
Holistic evaluation of language models.Transactions on Machine Learning Research (TMLR), 2023
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models.Transactions on Machine Learning Research (TMLR), 2023
2023
-
[8]
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Faeze Brahman, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. WildBench: Benchmarking LLMs with challenging tasks from real users in the wild.arXiv preprint arXiv:2406.04770, 2024
-
[9]
TruthfulQA: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meeting of the Association for Computa- tional Linguistics (ACL), 2022
2022
-
[10]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[11]
arXiv preprint arXiv:2602.21337
Christian Pölitz, Finale Doshi-Velez, and Siân Lindley. A benchmark to assess common ground in human–AI collaboration.arXiv preprint arXiv:2602.21337, 2026
-
[12]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[13]
Navigating rifts in human–LLM grounding: Study and benchmark
Omar Shaikh, Hussein Mozannar, Gagan Bansal, Adam Fourney, and Eric Horvitz. Navigating rifts in human–LLM grounding: Study and benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025
2025
-
[14]
Hua Shen, Tiffany Knearem, Reshmi Ghosh, Kenan Alkiek, Kundan Krishna, Yachuan Liu, Ziqiao Ma, Savvas Petridis, Yi-Hao Peng, Li Qiwei, et al. Position: Towards bidirectional human–AI alignment: A systematic review for clarifications, framework, and future directions. arXiv preprint arXiv:2406.09264, 2024
-
[15]
Le, Ed H
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V . Le, Ed H. Chi, Denny Zhou, and Jason Wei. Chal- lenging BIG-Bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics (ACL), 2023. 10
2023
-
[16]
Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, and Ion Stoica
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Y . Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, and Ion Stoica. JudgeBench: A benchmark for evaluating LLM-based judges. InInternational Conference on Learning Representations (ICLR), 2025
2025
- [17]
-
[18]
Varad Vishwarupe, Ivan Flechais, Nigel Shadbolt, and Marina Jirotka. “To LLM, or not to LLM”: How designers and developers navigate LLMs as tools or teammates. InExtended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems (CHI EA ’26), New York, NY , USA, 2026. ACM. doi: 10.1145/3772363.3798953
-
[19]
The collaboration gap in human–AI work: Grounding and repair conditions for stable collaboration
Varad Vishwarupe, Ivan Flechais, Nigel Shadbolt, and Marina Jirotka. The collaboration gap in human–AI work: Grounding and repair conditions for stable collaboration. InProceedings of the 2026 ECSCW Conference, 2026. Poster
2026
-
[20]
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2024
2024
-
[21]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review arXiv 2024
-
[22]
SafetyBench: Evaluating the safety of large language models
Zhexin Zhang, Leqi Lei, Lindong Wu, Rui Sun, Yongkang Huang, Chong Long, Xiao Liu, Xuanyu Lei, Jie Tang, and Minlie Huang. SafetyBench: Evaluating the safety of large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[23]
Judging LLM-as-a-Judge with MT-Bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging LLM-as-a-Judge with MT-Bench and chatbot arena. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023
2023
-
[24]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023. 11 A Extended Related Work: The Interactional Turn in Alignment Section 2 summarizes three strands of prior work that motivate the rubric. This appendix...
work page internal anchor Pith review arXiv 2023
-
[25]
Claim level Which level the alignment claim is made at: model, response, interaction, or deployment
-
[26]
Model-level evidence Training method (RLHF / Constitutional AI / DPO / other), evaluation suite used, and headline scores
-
[27]
not measured
Interactional evidence Which D-dimensions are evaluated and at what anchor level (D1 specifica- tion, D2 process, D3 verification, D4 multi-turn retention, D5 grounding, D6 repair, D7 personalization, D8 workflow); “not measured” acceptable
-
[28]
Scaffolding held fixed or varied Description of the scaffolding S used during evaluation (prompt template, memory, retrieval, UI, tools); whether S was held fixed (responding to a model claim) or varied (responding to a scaffold-efficacy claim)
-
[29]
Deployment contextC User population, task domain, oversight structure, accountability assump- tions; explicit ifCis unspecified or simulated
-
[30]
model M is aligned
Scope of claim The subset of (M, S, C) configurations the reported evidence supports. A claim such as “model M is aligned” should be reduced to “model M under scaffoldSin deployment contextCscoresXon dimensionsD.” The template is deliberately not a checklist for certification; it is a vocabulary for indexing claims. A paper that fills row 3 with “D1: 0.42...
-
[31]
Claude-Opus-4.7 (plastic).Each scaffold activates its target dimension as designed: C2 partially activates D1 (mean 0.67); C3 jointly activates D1 and D2 (1.17/1.50); C4 saturates D3 to ceiling (mean2.00, all 12/12 transcripts at score 2)
-
[32]
D1 and D2 vary only marginally (both ANOV Ap >0.85)
GPT-4o (saturated on D3).D3 is uniform at 0.33 across all four scaffolds ( F= 0.00 , p= 1.000). D1 and D2 vary only marginally (both ANOV Ap >0.85)
-
[33]
baseline always-on rather than scaffold-driven activation
Llama-4-Scout (partial, inverted on D3).D1 saturates at 0.33 across scaffolds ( F= 0.00);4 D2 is categorically absent (0/60); D3 varies with C1 highest (1.25) rather than C4–i.e. baseline always-on rather than scaffold-driven activation. Table 9: Mean reconciled scores by scaffold, under-specified prompts only (n= 12 per scaffold per model). Model Dim. C1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.