Recognition: 2 theorem links
· Lean TheoremSpecPL: Disentangling Spectral Granularity for Prompt Learning
Pith reviewed 2026-05-08 17:46 UTC · model grok-4.3
The pith
SpecPL improves prompt learning by disentangling spectral granularity in visual signals for better fine-grained discrimination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
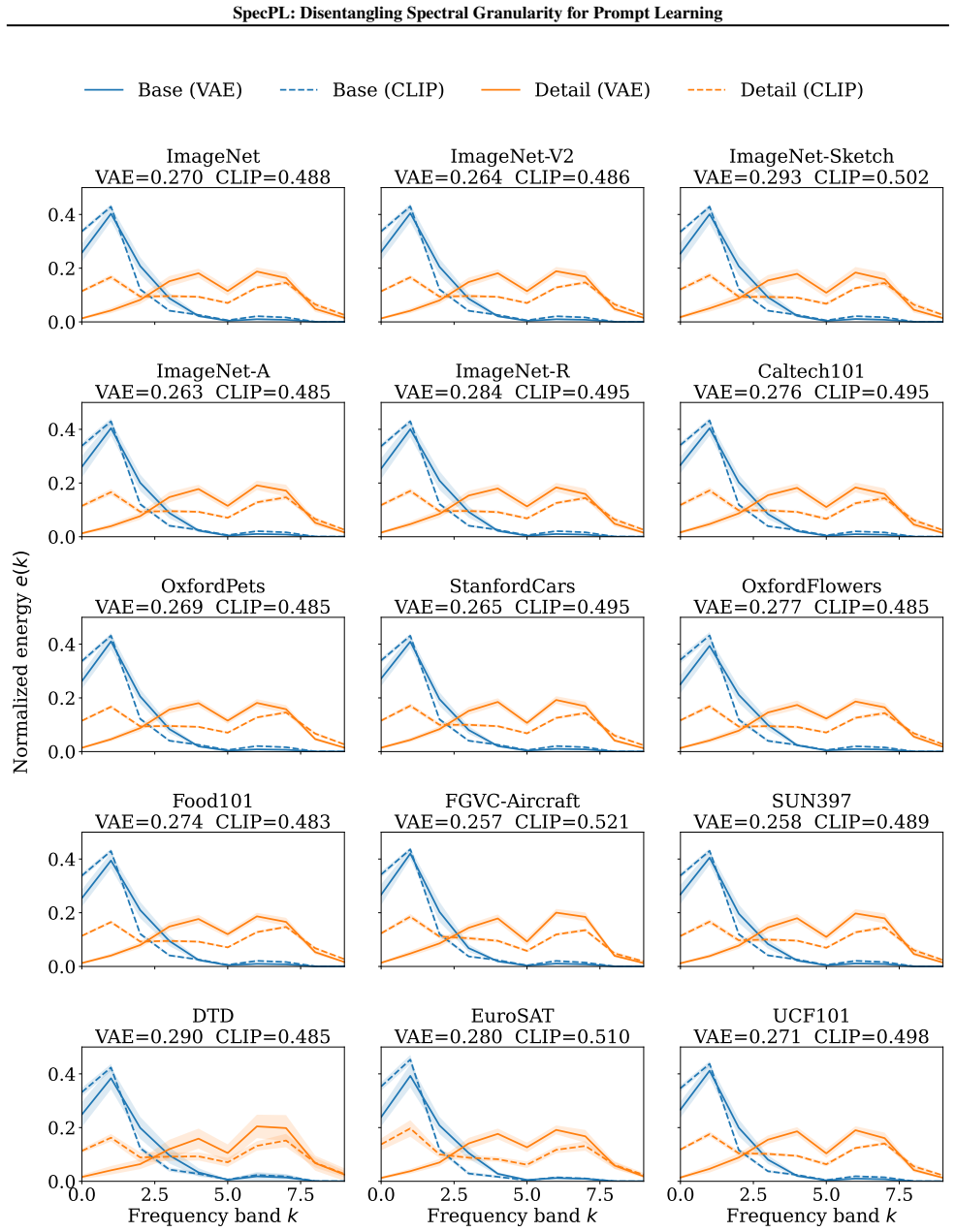
We introduce SpecPL to address modality asymmetry in prompt learning for VLMs. By leveraging a frozen VAE to decompose visual signals into semantic low-frequency bands and granular high-frequency details, and anchoring text representations to low-frequency invariants with a Visual Semantic Bank, the method uses counterfactual granule training via permutation of high-frequency signals. This compels explicit distinction of granularity from semantic invariance, revitalizing text-oriented baselines and achieving 81.51% harmonic-mean accuracy on 11 benchmarks.
What carries the argument
The spectral decomposition via frozen VAE combined with Counterfactual Granule Supervision that permutes high-frequency signals to drive fine-grained learning.
If this is right
- Serves as a universal plug-and-play booster for methods like CoOp and MaPLe.
- Achieves a new state-of-the-art harmonic-mean accuracy of 81.51% across 11 benchmarks.
- Bridges the stability-generalization trade-off through spectral disentanglement and counterfactual supervision.
- Enables better fine-grained discrimination by explicitly separating granularity from semantic content.
Where Pith is reading between the lines
- The spectral approach could be adapted to other frequency-based decompositions in multimodal learning tasks.
- Future work might explore dynamic rather than frozen decomposers to further optimize the separation.
- This suggests that explicit supervision on different frequency bands may uncover more about how models encode invariance versus detail.
Load-bearing premise
The frozen VAE reliably decomposes visual signals into semantic low-frequency bands and granular high-frequency details, and permuting the high-frequency signals compels the model to distinguish granularity from semantic invariance without introducing artifacts or instability.
What would settle it
A significant drop in performance on fine-grained tasks when the high-frequency permutation is omitted or when the VAE decomposition fails to align with semantic content would falsify the effectiveness of the counterfactual supervision mechanism.
Figures










read the original abstract
Existing prompt learning for VLMs exhibits a modality asymmetry, predominantly optimizing text tokens while still relying on frozen visual encoder as holistic extractor and neglecting the spectral granularity essential for fine-grained discrimination. To bridge this, we introduce Disentangling Spectral Granularity for Prompt Learning (SpecPL), which approaches prompt learning from a novel spectral perspective via Counterfactual Granule Supervision. Specifically, we leverage a frozen VAE to decompose visual signals into semantic low-frequency bands and granular high-frequency details. A frozen Visual Semantic Bank anchors text representations to universal low-frequency invariants, mitigating overfitting. Crucially, fine-grained discrimination is driven by counterfactual granule training: by permuting high-frequency signals, we compel the model to explicitly distinguish visual granularity from semantic invariance. Uniquely, SpecPL serves as a universal plug-and-play booster, revitalizing text-oriented baselines like CoOp and MaPLe via visual-side guidance. Experiments on 11 benchmarks demonstrate competitive state-of-the-art performance, achieving a new performance ceiling of 81.51\% harmonic-mean accuracy. These results validate that spectral disentanglement with counterfactual supervision effectively bridges the gap in the stability-generalization trade-off. Code is released at https://github.com/Mlrac1e/SpecPL-Prompt-Learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce SpecPL for disentangling spectral granularity in prompt learning for VLMs. It leverages a frozen VAE to decompose visual signals into semantic low-frequency bands and granular high-frequency details, uses a Visual Semantic Bank to anchor invariants, and employs counterfactual supervision by permuting high-frequency signals to force distinction between granularity and semantic invariance. The method is presented as a plug-and-play addition to baselines like CoOp and MaPLe, with experiments on 11 benchmarks showing competitive SOTA performance and a new 81.51% harmonic mean accuracy, validating the bridging of stability-generalization trade-off.
Significance. Should the core assumptions prove correct and the experimental results be robustly supported, this could represent a meaningful advance in prompt learning by incorporating visual spectral information to mitigate overfitting and improve fine-grained performance. The universal applicability as a booster and code release add to its potential impact. However, the significance is tempered by the need to confirm that the VAE-based decomposition achieves the intended separation without introducing confounding factors.
major comments (2)
- The abstract states competitive SOTA results and a new 81.51% harmonic mean but provides no information on baselines, ablations, statistical significance, error bars, or data splits; this makes it impossible to evaluate the central claim of bridging the stability-generalization trade-off from the given text.
- The assumption that a frozen VAE reliably decomposes visual signals into semantic low-frequency bands and granular high-frequency details, with permuting the high-frequency signals compelling the model to distinguish granularity from semantic invariance, is not justified; VAEs are typically optimized for reconstruction rather than explicit frequency-semantic separation, and the manuscript must demonstrate that this does not lead to semantic leakage or artifacts.
minor comments (1)
- The term 'harmonic-mean accuracy' should be clarified if it refers to the standard harmonic mean of base-to-new or other metrics common in prompt learning literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, providing clarifications from the full manuscript and committing to targeted revisions where appropriate to strengthen the presentation and validation of our claims.
read point-by-point responses
-
Referee: The abstract states competitive SOTA results and a new 81.51% harmonic mean but provides no information on baselines, ablations, statistical significance, error bars, or data splits; this makes it impossible to evaluate the central claim of bridging the stability-generalization trade-off from the given text.
Authors: We acknowledge that the abstract's brevity precludes inclusion of full experimental metadata. The complete manuscript reports all baselines (CoOp, MaPLe, and recent prompt-learning methods), component ablations, multi-run statistics with error bars, and standard data splits across the 11 benchmarks in Sections 4 and 5, with the 81.51% harmonic mean computed directly from these results. To improve accessibility, we will revise the abstract to include a brief reference to the evaluation setup and the magnitude of improvement over prior approaches. revision: partial
-
Referee: The assumption that a frozen VAE reliably decomposes visual signals into semantic low-frequency bands and granular high-frequency details, with permuting the high-frequency signals compelling the model to distinguish granularity from semantic invariance, is not justified; VAEs are typically optimized for reconstruction rather than explicit frequency-semantic separation, and the manuscript must demonstrate that this does not lead to semantic leakage or artifacts.
Authors: We agree that explicit validation of the decomposition is necessary. While VAEs are reconstruction-focused, their latent representations have been shown in prior frequency-analysis studies to encode semantic content preferentially in lower-frequency components. Our counterfactual high-frequency permutation is intended to isolate granularity effects while the Visual Semantic Bank anchors low-frequency invariants. In the revised manuscript we will add dedicated analyses, including frequency-band visualizations, semantic similarity metrics between original and permuted features, and reconstruction comparisons, to confirm minimal semantic leakage and the effectiveness of the separation. revision: yes
Circularity Check
No circularity: method relies on external frozen components and benchmark validation
full rationale
The paper introduces SpecPL as a plug-and-play approach that uses a frozen VAE for low/high-frequency decomposition of visual signals, a frozen Visual Semantic Bank to anchor invariants, and high-frequency permutation for counterfactual granule supervision. No equations, derivations, or fitted parameters are described that reduce the claimed harmonic-mean accuracy gains or stability-generalization bridging to inputs by construction. Performance is validated externally via experiments on 11 benchmarks rather than internal self-referential loops. No load-bearing self-citations or ansatzes imported from prior author work are evident in the provided description.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A frozen VAE can decompose visual signals into semantic low-frequency bands and granular high-frequency details
- ad hoc to paper Permuting high-frequency signals creates effective counterfactual examples that force distinction between granularity and semantic invariance
invented entities (2)
-
Counterfactual Granule Supervision
no independent evidence
-
Visual Semantic Bank
no independent evidence
Lean theorems connected to this paper
-
Foundation/BranchSelection.lean; Cost/FunctionalEquation.leanbranch_selection / washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we leverage a frozen VAE to decompose visual signals into semantic low-frequency bands and granular high-frequency details ... spectral disentanglement with counterfactual supervision
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
NeurIPS , volume=
Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks , author=. NeurIPS , volume=
-
[10]
Lxmert: Learning cross-modality encoder representations from transformers,
Lxmert: Learning cross-modality encoder representations from transformers , author=. arXiv preprint arXiv:1908.07490 , year=
-
[11]
ICML , pages=
Scaling up visual and vision-language representation learning with noisy text supervision , author=. ICML , pages=. 2021 , organization=
2021
-
[12]
ICML , pages=
Learning transferable visual models from natural language supervision , author=. ICML , pages=. 2021 , organization=
2021
-
[13]
CVMJ , volume=
CLIP-Flow: Decoding images encoded in CLIP space , author=. CVMJ , volume=. 2024 , publisher=
2024
-
[14]
CVPR , pages=
Alpha-clip: A clip model focusing on wherever you want , author=. CVPR , pages=
-
[15]
International Journal of Computer Vision , volume=
Learning to prompt for vision-language models , author=. International Journal of Computer Vision , volume=. 2022 , publisher=
2022
-
[16]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Conditional prompt learning for vision-language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[17]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Self-regulating prompts: Foundational model adaptation without forgetting , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[18]
Advances in Neural Information Processing Systems , volume=
Prompt pre-training with twenty-thousand classes for open-vocabulary visual recognition , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Argue: Attribute-guided prompt tuning for vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Tcp: Textual-based class-aware prompt tuning for visual-language model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[21]
Advances in Neural Information Processing Systems , volume=
Awt: Transferring vision-language models via augmentation, weighting, and transportation , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
arXiv preprint arXiv:2505.05180 , year=
OpenworldAUC: Towards Unified Evaluation and Optimization for Open-world Prompt Tuning , author=. arXiv preprint arXiv:2505.05180 , year=
-
[23]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
NLPrompt: Noise-Label Prompt Learning for Vision-Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Hierarchical cross-modal prompt learning for vision-language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[25]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Advancing textual prompt learning with anchored attributes , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Large language models are good prompt learners for low-shot image classification , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Learning to prompt with text only supervision for vision-language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Maple: Multi-modal prompt learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Prompt distribution learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[30]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
What does a platypus look like? generating customized prompts for zero-shot image classification , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[31]
International Journal of Computer Vision , volume=
Clip-adapter: Better vision-language models with feature adapters , author=. International Journal of Computer Vision , volume=. 2024 , publisher=
2024
-
[32]
arXiv preprint arXiv:2111.03930 , year=
Tip-adapter: Training-free clip-adapter for better vision-language modeling , author=. arXiv preprint arXiv:2111.03930 , year=
-
[33]
European conference on computer vision , pages=
Visual prompt tuning , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[34]
CVPR , pages=
Imagenet: A large-scale hierarchical image database , author=. CVPR , pages=. 2009 , organization=
2009
-
[35]
International conference on machine learning , pages=
Do imagenet classifiers generalize to imagenet? , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[36]
Advances in Neural Information Processing Systems , volume=
Learning robust global representations by penalizing local predictive power , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Natural adversarial examples , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[38]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
The many faces of robustness: A critical analysis of out-of-distribution generalization , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[39]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Mmrl: Multi-modal representation learning for vision-language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
Advances in Neural Information Processing Systems , volume=
Fast fourier convolution , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Focal frequency loss for image reconstruction and synthesis , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[43]
Computer Vision and Pattern Recognition Workshop , year=
Learning Generative Visual Models from Few Training Examples: An Incremental Bayesian Approach Tested on 101 Object Categories , author=. Computer Vision and Pattern Recognition Workshop , year=
-
[44]
2012 IEEE conference on computer vision and pattern recognition , pages=
Cats and dogs , author=. 2012 IEEE conference on computer vision and pattern recognition , pages=. 2012 , organization=
2012
-
[45]
In: 2013 IEEE International Conference on Computer Vision Workshops
Krause, Jonathan and Stark, Michael and Deng, Jia and Fei-Fei, Li , booktitle=. 3D Object Representations for Fine-Grained Categorization , year=. doi:10.1109/ICCVW.2013.77 , ISSN=
-
[46]
2008 Sixth Indian conference on computer vision, graphics & image processing , pages=
Automated flower classification over a large number of classes , author=. 2008 Sixth Indian conference on computer vision, graphics & image processing , pages=. 2008 , organization=
2008
-
[47]
European conference on computer vision , pages=
Food-101--mining discriminative components with random forests , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[48]
Fine-Grained Visual Classification of Aircraft
Fine-grained visual classification of aircraft , author=. arXiv preprint arXiv:1306.5151 , year=
work page internal anchor Pith review arXiv
-
[49]
2010 IEEE computer society conference on computer vision and pattern recognition , pages=
Sun database: Large-scale scene recognition from abbey to zoo , author=. 2010 IEEE computer society conference on computer vision and pattern recognition , pages=. 2010 , organization=
2010
-
[50]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Describing textures in the wild , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[51]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2019 , publisher=
2019
-
[52]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Ucf101: A dataset of 101 human actions classes from videos in the wild , author=. arXiv preprint arXiv:1212.0402 , year=
work page internal anchor Pith review arXiv
-
[53]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Waffling around for performance: Visual classification with random words and broad concepts , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[54]
International conference on learning representations , year=
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness , author=. International conference on learning representations , year=
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-frequency component helps explain the generalization of convolutional neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
International conference on machine learning , pages=
Making convolutional networks shift-invariant again , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[57]
Neural computation , volume=
Slow feature analysis: Unsupervised learning of invariances , author=. Neural computation , volume=. 2002 , publisher=
2002
-
[58]
Advances in neural information processing systems , volume=
Do vision transformers see like convolutional neural networks? , author=. Advances in neural information processing systems , volume=
-
[59]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model , author=. arXiv preprint arXiv:2510.10274 , year=
work page internal anchor Pith review arXiv
-
[60]
2026 , url=
Junjie Zhou and WEI SHAO and Yagao Yue and Wei Mu and Peng Wan and Qi Zhu and Daoqiang Zhang , booktitle=. 2026 , url=
2026
-
[61]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[62]
2024 , eprint=
FROSTER: Frozen CLIP Is A Strong Teacher for Open-Vocabulary Action Recognition , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.