Recognition: unknown
When No Benchmark Exists: Validating Comparative LLM Safety Scoring Without Ground-Truth Labels
Pith reviewed 2026-05-08 12:01 UTC · model grok-4.3
The pith
LLM safety scores without ground-truth labels are validated through an instrumental-validity chain of contrast responsiveness, variance dominance, and stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
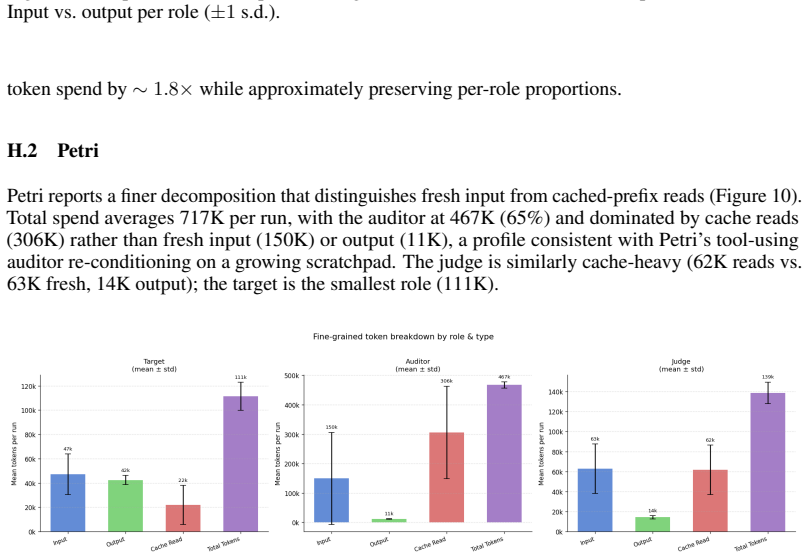
In benchmarkless settings, comparative safety scores are valid only under a fixed scenario pack, rubric, auditor, judge, sampling configuration, and rerun budget. Validity is established not by agreement with ground-truth labels but by an instrumental-validity chain consisting of responsiveness to a controlled safe-versus-abliterated contrast, dominance of target-driven variance over auditor and judge artifacts, and stability across reruns. This chain is instantiated and tested in SimpleAudit on a Norwegian pack, where AUROC values reach 0.89-1.00, target identity explains about 52% of variance, and profiles stabilize by ten reruns. The same chain validates Petri, but differences between the
What carries the argument
The instrumental-validity chain, which replaces ground-truth agreement with checks for contrast responsiveness, target variance dominance, and rerun stability to support interpretation of scenario-based audits as evidence.
Load-bearing premise
The instrumental-validity chain is sufficient to interpret a scenario-based audit as deployment evidence without any ground-truth labels.
What would settle it
An experiment where safe and abliterated models fail to separate with AUROC below 0.8, or where auditor or judge variance exceeds target variance, or where severity profiles fail to stabilize after ten reruns would show the chain does not support valid scoring.
Figures















read the original abstract
Many deployments must compare candidate language models for safety before a labeled benchmark exists for the relevant language, sector, or regulatory regime. We formalize this setting as benchmarkless comparative safety scoring and specify the contract under which a scenario-based audit can be interpreted as deployment evidence. Scores are valid only under a fixed scenario pack, rubric, auditor, judge, sampling configuration, and rerun budget. Because no labels are available, we replace ground-truth agreement with an instrumental-validity chain: responsiveness to a controlled safe-versus-abliterated contrast, dominance of target-driven variance over auditor and judge artifacts, and stability across reruns. We instantiate the chain in SimpleAudit, a local-first scoring instrument, and validate it on a Norwegian safety pack. Safe and abliterated targets separate with AUROC values between 0.89 and 1.00, target identity is the dominant variance component ($\eta^2 \approx 0.52$), and severity profiles stabilize by ten reruns. Applying the same chain to Petri shows that it admits both tools. The substantial differences arise upstream of the chain, in claim-contract enforcement and deployment fit. A Norwegian public-sector procurement case comparing Borealis and Gemma 3 demonstrates the resulting evidence in practice: the safer model depends on scenario category and risk measure. Consequently, scores, matched deltas, critical rates, uncertainty, and the auditor and judge used must be reported together rather than collapsed into a single ranking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes 'benchmarkless comparative safety scoring' for LLM safety comparisons in domains lacking ground-truth labels. It specifies a contract under which scenario-based audits provide deployment evidence only when the scenario pack, rubric, auditor, judge, sampling, and rerun budget are fixed. Lacking labels, it substitutes an instrumental-validity chain: (1) responsiveness to a controlled safe-versus-abliterated contrast (AUROC 0.89–1.00), (2) dominance of target-driven variance over auditor/judge artifacts (η² ≈ 0.52), and (3) stability across reruns (by ten). The chain is instantiated in SimpleAudit, validated on a Norwegian safety pack, applied to Petri, and demonstrated in a Borealis vs. Gemma 3 procurement case, concluding that full context (scores, deltas, critical rates, uncertainty, auditor, judge) must be reported rather than collapsed into rankings.
Significance. If the instrumental-validity chain is accepted as sufficient, the work supplies a practical, contract-bound method for comparative safety evaluation in novel languages, sectors, or regulatory regimes where labeled benchmarks do not yet exist. It usefully demonstrates that safety rankings are scenario- and measure-dependent and stresses transparent reporting of all audit components. The approach is locally executable and provides a concrete Norwegian public-sector example.
major comments (3)
- [abstract (instrumental-validity chain and Norwegian-pack validation)] The central claim that the instrumental-validity chain licenses deployment evidence rests on the controlled safe-versus-abliterated contrast serving as a faithful proxy for safety properties that matter in the target regime. However, the abliterated models are generated by the same team that defines the scenarios and rubric, and all experiments are confined to the Norwegian pack; no test is reported on independently sourced failure modes (e.g., regulatory queries or post-deployment incident logs) outside the pack. This is load-bearing for interpreting the AUROC 0.89–1.00 and η² ≈ 0.52 results as general validation rather than design-consistent separation.
- [abstract (dominance of target-driven variance)] The variance-decomposition result (target identity as dominant component, η² ≈ 0.52) is presented as evidence that target-driven variance exceeds auditor and judge artifacts. Yet because the scenarios were chosen to highlight differences the ablation manipulates, the dominance may be inflated by construction; the manuscript does not include a control that would rule this out. This directly affects whether the chain can replace ground-truth agreement under the stated contract.
- [abstract (quantitative support and SimpleAudit instantiation)] The paper states that scores are valid only under a fixed scenario pack, rubric, auditor, judge, sampling configuration, and rerun budget, yet the reported experiments provide limited detail on exclusion rules, exact statistical procedures for the AUROC and η² calculations, or sensitivity to small changes in the pack. Without these, it is difficult to assess whether the stabilization by ten reruns and the separation results are robust or post-hoc.
minor comments (2)
- [abstract (application to Petri)] The claim that 'the same chain' applied to Petri 'admits both tools' is stated without specifying which components of the chain were re-run or how the upstream differences in claim-contract enforcement were quantified.
- [validation experiments] The manuscript would benefit from an explicit table or section listing all fixed parameters of the contract (scenario pack, rubric, etc.) used in the Norwegian validation so readers can replicate the exact conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. These help sharpen the presentation of the instrumental-validity chain and its contractual boundaries. We respond to each major comment below, indicating where the manuscript will be revised for clarity and where limitations will be stated more explicitly.
read point-by-point responses
-
Referee: [abstract (instrumental-validity chain and Norwegian-pack validation)] The central claim that the instrumental-validity chain licenses deployment evidence rests on the controlled safe-versus-abliterated contrast serving as a faithful proxy for safety properties that matter in the target regime. However, the abliterated models are generated by the same team that defines the scenarios and rubric, and all experiments are confined to the Norwegian pack; no test is reported on independently sourced failure modes (e.g., regulatory queries or post-deployment incident logs) outside the pack. This is load-bearing for interpreting the AUROC 0.89–1.00 and η² ≈ 0.52 results as general validation rather than design-consistent separation.
Authors: We agree that the abliterated models were generated by the same team that defined the scenarios and rubric, and that all reported results are confined to the Norwegian pack. The instrumental-validity chain is offered strictly as a contract-bound substitute for ground-truth labels, not as a general proxy for all safety properties. The AUROC range demonstrates responsiveness to the controlled contrast under the fixed pack, which is a necessary condition within the stated contract. We do not claim this substitutes for external validation against independently sourced failure modes. In revision we will (1) add explicit qualifying language in the abstract and Section 3 stating that the chain supplies evidence only under the fixed contract and does not replace domain-specific external checks where such data exist, and (2) expand the limitations paragraph to note the team-generated ablation and pack as a boundary condition. revision: partial
-
Referee: [abstract (dominance of target-driven variance)] The variance-decomposition result (target identity as dominant component, η² ≈ 0.52) is presented as evidence that target-driven variance exceeds auditor and judge artifacts. Yet because the scenarios were chosen to highlight differences the ablation manipulates, the dominance may be inflated by construction; the manuscript does not include a control that would rule this out. This directly affects whether the chain can replace ground-truth agreement under the stated contract.
Authors: The Norwegian scenarios were selected to cover safety dimensions relevant to the target regime, and the ablation targets refusal and harm-related behaviors that those scenarios are designed to elicit. While this alignment could contribute to the observed η² value, the decomposition still shows target identity as the largest component after auditor and judge effects are partialled out. We accept that a fully independent control scenario set (orthogonal to the ablation) is absent. In revision we will add a paragraph in the methods and discussion clarifying that the variance result is conditional on the chosen pack and does not constitute a universal control; we will also report the full ANOVA table so readers can assess the relative magnitudes directly. revision: partial
-
Referee: [abstract (quantitative support and SimpleAudit instantiation)] The paper states that scores are valid only under a fixed scenario pack, rubric, auditor, judge, sampling configuration, and rerun budget, yet the reported experiments provide limited detail on exclusion rules, exact statistical procedures for the AUROC and η² calculations, or sensitivity to small changes in the pack. Without these, it is difficult to assess whether the stabilization by ten reruns and the separation results are robust or post-hoc.
Authors: We will expand the methods section and add an appendix that specifies: (a) the exact exclusion rules applied to model responses, (b) the precise statistical procedures (including any bootstrapping, confidence-interval construction for AUROC, and the ANOVA formulation for η²), (c) the full sampling configuration and rerun budget, and (d) any sensitivity checks performed on pack composition or small perturbations. These additions will allow direct evaluation of whether the ten-rerun stabilization and separation results are robust. revision: yes
- Validation against independently sourced failure modes (regulatory queries or post-deployment incident logs) outside the Norwegian pack; this would require new external data collection not performed in the current study.
Circularity Check
No significant circularity detected
full rationale
The paper explicitly defines an instrumental-validity chain as the replacement for unavailable ground-truth labels and then measures whether its SimpleAudit instrument satisfies the three stated criteria (responsiveness to safe-versus-abliterated contrast, target-variance dominance, and rerun stability) on a Norwegian scenario pack. This is a self-contained definitional proposal followed by an empirical check inside the authors' own controlled setup; no equation, result, or central claim reduces to its inputs by construction, no self-citation is load-bearing, and no fitted parameter is relabeled as an independent prediction. The derivation therefore remains non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An instrumental-validity chain of contrast responsiveness, target variance dominance, and rerun stability is sufficient to validate comparative safety scores as deployment evidence without ground-truth labels.
invented entities (3)
-
benchmarkless comparative safety scoring
no independent evidence
-
instrumental-validity chain
no independent evidence
-
SimpleAudit
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Liang, Percy and Bommasani, Rishi and Lee, Tony and Tsipras, Dimitris and Soylu, Dilara and Yasunaga, Michihiro and Zhang, Yian and Narayanan, Deepak and Wu, Yuhuai and Kumar, Ananya and Newman, Benjamin and Yuan, Binhang and Yan, Bobby and Zhang, Ce and Cosgrove, Christian and Manning, Christopher D. and R. Transactions on Machine Learning Research , yea...
-
[2]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Ganguli, Deep and Lovitt, Liane and Kernion, Jackson and Askell, Amanda and Bai, Yuntao and others , title =. ArXiv e-prints , year =. doi:10.48550/arXiv.2209.07858 , eprint =
work page internal anchor Pith review doi:10.48550/arxiv.2209.07858
-
[3]
In: Findings of the Association for Computational Linguistics: ACL 2023, pp
Discovering Language Model Behaviors with Model-Written Evaluations , author =. Findings of the Association for Computational Linguistics: ACL 2023 , month = jul, year =. doi:10.18653/v1/2023.findings-acl.847 , pages =. 2212.09251 , archivePrefix =
-
[4]
doi: 10.18653/v1/2020.findings-emnlp.301
Gehman, Samuel and Gururangan, Suchin and Sap, Maarten and Choi, Yejin and Smith, Noah A. , editor =. Findings of the Association for Computational Linguistics: EMNLP 2020 , month = nov, year =. doi:10.18653/v1/2020.findings-emnlp.301 , pages =. 2009.11462 , archivePrefix =
-
[5]
Proceedings of the 41st International Conference on Machine Learning (ICML) , series =
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , title =. Proceedings of the 41st International Conference on Machine Learning (ICML) , series =. 2024 , publisher =. doi:10.5555/3692070.3693501 , eprint =
-
[6]
Constitutional AI: Harmlessness from AI Feedback
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and others , title =. ArXiv e-prints , year =. doi:10.48550/arXiv.2212.08073 , eprint =
work page internal anchor Pith review doi:10.48550/arxiv.2212.08073
-
[7]
2025 , howpublished=
SimpleAudit: Lightweight AI Safety Auditing Framework , author=. 2025 , howpublished=
2025
-
[8]
any-llm: Communicate with any LLM provider using a single, unified interface , year =
-
[9]
2025 , howpublished=
Borealis Instruct Preview Model Collection , author=. 2025 , howpublished=
2025
-
[10]
Kamath, Aishwarya and Ferret, Johan and Pathak, Shreya and Vieillard, Nino and Merhej, Ramona and others , title =. ArXiv e-prints , year =. doi:10.48550/arXiv.2503.19786 , eprint =
-
[11]
2025 , howpublished=
OpenAI API Model Documentation , author=. 2025 , howpublished=
2025
-
[12]
AbstentionBench: Reasoning LLMs Fail on Unanswerable Questions,
Kirichenko, Polina and Ibrahim, Mark and Chaudhuri, Kamalika and Bell, Samuel J. , title =. Advances in Neural Information Processing Systems 38 (NeurIPS 2025) Datasets and Benchmarks Track , year =. doi:10.48550/arXiv.2506.09038 , eprint =
-
[13]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Advances in Neural Information Processing Systems 36 (NeurIPS 2023) Datasets and Benchmarks Track , year =. doi:10.48550/a...
work page internal anchor Pith review doi:10.48550/arxiv.2306.05685 2023
-
[14]
G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =. doi:10.18653/v1/2023.emnlp-main.153 , eprint =
-
[15]
2025 , month = oct, howpublished =
2025
-
[16]
2026 , month = jan, howpublished =
2026
-
[17]
Refusal in Language Models Is Mediated by a Single Direction
Arditi, Andy and Obeso, Oscar and Syed, Aaquib and Paleka, Daniel and Panickssery, Nina and Gurnee, Wes and Nanda, Neel , title =. Advances in Neural Information Processing Systems 37 (NeurIPS 2024) , year =. doi:10.48550/arXiv.2406.11717 , eprint =
work page internal anchor Pith review doi:10.48550/arxiv.2406.11717 2024
-
[18]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Gebru, Timnit and Morgenstern, Jamie and Vecchione, Briana and Vaughan, Jennifer Wortman and Wallach, Hanna and Daum. Communications of the ACM , volume =. 2021 , month = dec, publisher =. doi:10.1145/3458723 , eprint =
-
[19]
arXiv preprint arXiv:2305.15324 , year=
Shevlane, Toby and Farquhar, Sebastian and Garfinkel, Ben and Phuong, Mary and Whittlestone, Jess and Leung, Jade and Kokotajlo, Daniel and Marchal, Nahema and Anderljung, Markus and Kolt, Noam and Ho, Lewis and Siddarth, Divya and Avin, Shahar and Hawkins, Will and Kim, Been and Gabriel, Iason and Bolina, Vijay and Clark, Jack and Bengio, Yoshua and Chri...
-
[20]
Safetybench: Eval- uating the safety of large language models with mul- tiple choice questions
Zhang, Zhexin and Lei, Leqi and Wu, Lindong and Sun, Rui and Huang, Yongkang and Long, Chong and Liu, Xiao and Lei, Xuanyu and Tang, Jie and Huang, Minlie , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =. doi:10.48550/arXiv.2309.07045 , eprint =
-
[21]
Ghosh, Shaona and Frase, Heather and Williams, Adina and Luger, Sarah and R. ArXiv e-prints , year =. doi:10.48550/arXiv.2503.05731 , eprint =
-
[22]
Souly, Alexandra and Kirk, Robert and Merizian, Jacob and D'Cruz, Abby and Davies, Xander , title =. ArXiv e-prints , year =. 2604.00788 , archivePrefix =
-
[23]
Gu, Jiawei and Jiang, Xuhui and Shi, Zhichao and Tan, Hexiang and Zhai, Xuehao and Xu, Chengjin and Li, Wei and Shen, Yinghan and Ma, Shengjie and Liu, Honghao and others , title =. ArXiv e-prints , year =. doi:10.48550/arXiv.2411.15594 , eprint =
-
[24]
Judging the judges: A systematic study of position bias in llm-as-a-judge, April 2025
Shi, Lin and Ma, Chiyu and Liang, Wenhua and Diao, Xingjian and Ma, Weicheng and Vosoughi, Soroush , title =. Proceedings of IJCNLP-AACL 2025 , year =. doi:10.48550/arXiv.2406.07791 , eprint =
-
[25]
Model Cards for Model Reporting
Mitchell, Margaret and Wu, Simone and Zaldivar, Andrew and Barnes, Parker and Vasserman, Lucy and Hutchinson, Ben and Spitzer, Elena and Raji, Inioluwa Deborah and Gebru, Timnit , title =. Proceedings of the Conference on Fairness, Accountability, and Transparency (FAT*) , year =. doi:10.1145/3287560.3287596 , eprint =
-
[26]
Bean, Andrew M. and Kearns, Ryan Othniel and Romanou, Angelika and Hafner, Franziska Sofia and Mayne, Harry and Batzner, Jan and Foroutan, Negar and Schmitz, Chris and others , title =. Advances in Neural Information Processing Systems 38 (NeurIPS 2025) Datasets and Benchmarks Track , year =. doi:10.48550/arXiv.2511.04703 , eprint =
-
[27]
Salaudeen, Olawale and Reuel, Anka and Ahmed, Ahmed and Bedi, Suhana and Robertson, Zachary and Sundar, Sudharsan and Domingue, Benjamin and Wang, Angelina and Koyejo, Sanmi , title =. ArXiv e-prints , year =. doi:10.48550/arXiv.2505.10573 , eprint =
-
[28]
Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa) , year =
Samuel, David and Kutuzov, Andrey and Touileb, Samia and Velldal, Erik and. Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa) , year =. 2305.03880 , archivePrefix =
-
[29]
and Ingvaldsen, Jon Espen and Eide, Simen and Gulla, Jon Atle and Yang, Zhirong , title =
Liu, Peng and Zhang, Lemei and Farup, Terje Nissen and Lauvrak, Even W. and Ingvaldsen, Jon Espen and Eide, Simen and Gulla, Jon Atle and Yang, Zhirong , title =. Findings of the Association for Computational Linguistics: EMNLP 2024 , year =. 2312.01314 , archivePrefix =
-
[30]
Findings of the Association for Computational Linguistics: ACL 2025 , year =
Mikhailov, Vladislav and Enstad, Tita and Samuel, David and Farseth. Findings of the Association for Computational Linguistics: ACL 2025 , year =. 2504.07749 , archivePrefix =
-
[31]
URL https://arxiv.org/abs/2508.12733
Ning, Zhiyuan and Gu, Tianle and Song, Jiaxin and Hong, Shixin and Li, Lingyu and Liu, Huacan and others , title =. ArXiv e-prints , year =. doi:10.48550/arXiv.2508.12733 , eprint =
-
[32]
Large language models often know when they are being evaluated
Needham, Joe and Edkins, Giles and Pimpale, Govind and Bartsch, Henning and Hobbhahn, Marius , title =. ArXiv e-prints , year =. doi:10.48550/arXiv.2505.23836 , eprint =
-
[33]
Nguyen, Jord and Hoang, Khiem and Attubato, Carlo Leonardo and Hofst. ArXiv e-prints , year =. doi:10.48550/arXiv.2507.01786 , eprint =
-
[34]
CyclicJudge: Mitigating Judge Bias Efficiently in LLM-based Evaluation
Zhu, Ziyi and Tieleman, Olivier and Bukhtiyarov, Alexey and Chen, Jinghong , title =. ArXiv e-prints , year =. doi:10.48550/arXiv.2603.01865 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.01865
-
[35]
Pavel Dolin, Weizhi Li, Gautam Dasarathy, and Visar Berisha
Chouldechova, Alexandra and Cooper, A. Feder and Barocas, Solon and Palia, Abhinav and Vann, Dan and Wallach, Hanna , title =. Advances in Neural Information Processing Systems 38 (NeurIPS 2025) Position Papers Track , year =. 2601.18076 , archivePrefix =
-
[36]
2026 , howpublished=
SimpleAudit: Verified Digital Public Good (Registry Entry) , author=. 2026 , howpublished=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.