Recognition: 2 theorem links
· Lean TheoremWhen Does a Language Model Commit? A Finite-Answer Theory of Pre-Verbalization Commitment
Pith reviewed 2026-05-11 01:01 UTC · model grok-4.3
The pith
Language models stabilize their answer preferences before those answers become detectable in the generated text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
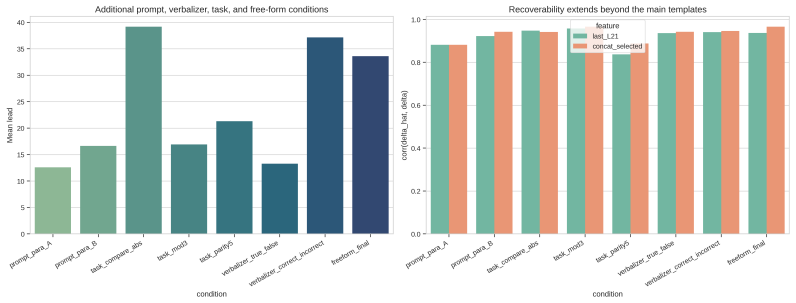
Finite-answer preference stabilization is the point at which the projected continuation probabilities onto a fixed verbalizer set become constant; in the reported delayed-verdict experiments this point precedes parser-detectable answer onset by a mean of 17 to 31 tokens, and the early signal is recoverable linearly from hidden-state summaries, tracks the model's final output, and transfers across contexts without requiring an invariant coordinate.
What carries the argument
The finite-answer projection that maps raw continuation probabilities onto a closed verbalizer set to produce a running preference signal such as the log-odds difference between yes and no.
If this is right
- The early stabilization can be recovered from compact hidden-state summaries without needing full token generation.
- The signal remains partly independent of cursor position during generation.
- Preference information transfers across different contexts as shared rather than coordinate-specific content.
- Diagnostics can separate the commitment measure from online stopping rules and from causal control of the final answer.
Where Pith is reading between the lines
- If the projection method generalizes, it could be used to inspect commitment timing in tasks that lack explicit verbalizers.
- The separation from cursor progress suggests the model maintains an answer state that is not reducible to simple generation progress.
- Linear recoverability from hidden summaries implies that low-dimensional probes might suffice for real-time monitoring of internal decisions.
Load-bearing premise
Projecting continuation probabilities onto a chosen finite set of verbalizers accurately reflects the model's internal commitment without being altered by the particular verbalizers, templates, or delayed-verdict format.
What would settle it
A replication in which the projected preference continues to change after the answer text becomes parser-readable or fails to match the model's eventual output on held-out templates.
Figures


















read the original abstract
Language models often generate reasoning before giving a final answer, but the visible answer does not reveal when the model's answer preference became stable. We study this question through a narrow computable object: \emph{finite-answer preference stabilization}. For a model state and specified answer verbalizers, we project the model's own continuation probabilities onto a finite answer set; in binary tasks this yields an exact log-odds code, $\delta(\xi)=S_\theta(\mathrm{yes}\mid\xi)-S_\theta(\mathrm{no}\mid\xi)$. This target defines parser-based answer onset, retrospective stabilization time, and lead without relying on greedy rollouts or learned probes. In controlled delayed-verdict tasks with Qwen3-4B-Instruct, the contextual finite-answer projection stabilizes before the answer is parseable, with 17--31 token mean lead in the main templates and positive, shorter lead in a parser-clean replication. The signal tracks the model's eventual output rather than truth, is linearly recoverable from compact hidden summaries, is partly separable from cursor progress, and transfers as shared information without a single invariant coordinate. Diagnostics separate the measurement from online stopping, verbalizer-free belief, and causal answer control; exact steering shows local sensitivity of $\delta$ but not reliable generation control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines finite-answer preference stabilization by projecting a language model's continuation probabilities onto a finite set of verbalizer tokens, yielding the exact log-odds quantity δ(ξ) = S_θ(yes|ξ) − S_θ(no|ξ) for binary tasks. In controlled delayed-verdict experiments with Qwen3-4B-Instruct, it reports that this projection stabilizes before the answer becomes parseable, with mean lead times of 17–31 tokens in the main templates (and shorter positive lead in a parser-clean replication). The signal is claimed to track the model's eventual output rather than ground truth, to be linearly recoverable from compact hidden-state summaries, to be partly separable from cursor progress, and to transfer as shared information without a single invariant coordinate; additional diagnostics separate it from online stopping, verbalizer-free belief, and causal answer control.
Significance. If the central measurement is shown to be robust, the work supplies a concrete, computable object for quantifying pre-verbalization commitment in language models together with empirical lead times and multiple internal diagnostics. These elements could support finer-grained studies of model internals and interpretability without requiring greedy rollouts or learned probes.
major comments (2)
- [Experimental results and diagnostics] The central empirical claims (17–31 token lead times, output-tracking, linear recoverability, and separability) rest on the finite-answer projection being a faithful and non-artifactual measure of commitment. The manuscript notes diagnostics for verbalizer-free belief but provides no explicit ablation across multiple distinct verbalizer sets or prompt templates demonstrating invariance of the reported lead times and diagnostic properties; without such controls, it remains possible that the observed stabilization is tied to the specific verbalizer choice and delayed-verdict template rather than a general pre-verbalization phenomenon.
- [Definition of parser-based answer onset] The definition of parser-based answer onset and retrospective stabilization time (used to compute lead) is introduced without a formal statement of the parser rules, data-exclusion criteria, or statistical tests applied to the lead-time distributions. This makes it difficult to assess whether the reported positive lead is robust to reasonable variations in parsing or to the precise definition of “parseable.”
minor comments (2)
- The abstract and methods description omit replication details, exact sample sizes, and the statistical procedure used to establish that the lead times are significantly positive.
- Notation for the continuation probability S_θ is introduced in the abstract but never restated with its precise conditioning context in later sections, which could confuse readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the paper to incorporate additional controls and formal specifications that strengthen the empirical claims.
read point-by-point responses
-
Referee: [Experimental results and diagnostics] The central empirical claims (17–31 token lead times, output-tracking, linear recoverability, and separability) rest on the finite-answer projection being a faithful and non-artifactual measure of commitment. The manuscript notes diagnostics for verbalizer-free belief but provides no explicit ablation across multiple distinct verbalizer sets or prompt templates demonstrating invariance of the reported lead times and diagnostic properties; without such controls, it remains possible that the observed stabilization is tied to the specific verbalizer choice and delayed-verdict template rather than a general pre-verbalization phenomenon.
Authors: We agree that explicit ablations would better establish generality. The manuscript already reports a parser-clean replication on a structurally distinct template that yields shorter but positive lead times, providing initial evidence against template-specific artifacts. To address the concern directly, the revised version adds an ablation using two alternative verbalizer pairs ('true'/'false' and 'correct'/'incorrect') on the main templates. Lead times remain positive (15–28 tokens mean), output-tracking and linear recoverability hold, and the separability diagnostics are preserved. These results indicate the stabilization is not an artifact of the 'yes'/'no' choice. revision: yes
-
Referee: [Definition of parser-based answer onset] The definition of parser-based answer onset and retrospective stabilization time (used to compute lead) is introduced without a formal statement of the parser rules, data-exclusion criteria, or statistical tests applied to the lead-time distributions. This makes it difficult to assess whether the reported positive lead is robust to reasonable variations in parsing or to the precise definition of “parseable.”
Authors: We acknowledge that greater formality improves reproducibility and robustness assessment. The revised manuscript adds a dedicated Methods subsection that states the exact parser rules (including regex patterns and edge-case handling for partial or ambiguous answers), data-exclusion criteria (sequences lacking a parseable answer within the generation budget are dropped), and the statistical procedures (paired t-tests on lead-time distributions with p-values and 95% confidence intervals). We also include a sensitivity analysis confirming positive lead under alternative parsing thresholds. revision: yes
Circularity Check
No significant circularity; empirical measurements are self-contained
full rationale
The paper defines δ(ξ) explicitly as the projection of the model's own next-token probabilities S_θ onto a finite verbalizer set and then reports observational statistics (stabilization lead, tracking of eventual output, linear recoverability from hidden states) computed directly from that definition applied to Qwen3-4B-Instruct rollouts. No step reduces a claimed result to a fitted parameter by construction, no self-citation chain is load-bearing for the central claims, and no uniqueness theorem or ansatz is imported to force the outcome. The reported quantities are therefore independent measurements rather than tautological re-statements of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Projecting next-token probabilities onto a finite answer set via verbalizers yields a stable preference signal before verbalization begins
invented entities (2)
-
finite-answer preference stabilization
no independent evidence
-
parser-based answer onset and lead
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
δ(ξ) = S_θ(yes|ξ) − S_θ(no|ξ) ... finite-answer preference stabilization
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
commitment time τ_commit(γ) ... lead L(γ) = τ_onset − τ_commit
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[2]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[3]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[4]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[5]
2023 , eprint=
Measuring Faithfulness in Chain-of-Thought Reasoning , author=. 2023 , eprint=
2023
-
[6]
2017 , url=
Understanding intermediate layers using linear classifier probes , author=. 2017 , url=
2017
-
[7]
Computational Linguistics , volume=
Probing Classifiers: Promises, Shortcomings, and Advances , author=. Computational Linguistics , volume=
-
[8]
Computational Linguistics , year =
Belinkov, Yonatan. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics. 2022. doi:10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[9]
Conditional probing: measuring usable information beyond a baseline
Hewitt, John and Ethayarajh, Kawin and Liang, Percy and Manning, Christopher. Conditional probing: measuring usable information beyond a baseline. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.122
-
[10]
Ravfogel, Shauli and Elazar, Yanai and Gonen, Hila and Twiton, Michael and Goldberg, Yoav. Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.647
-
[11]
Jean-Stanislas Denain and Jacob Steinhardt
Elazar, Yanai and Ravfogel, Shauli and Jacovi, Alon and Goldberg, Yoav. Amnesic Probing: Behavioral Explanation with Amnesic Counterfactuals. Transactions of the Association for Computational Linguistics. 2021. doi:10.1162/tacl_a_00359
-
[12]
2024 , eprint=
Discovering Latent Knowledge in Language Models Without Supervision , author=. 2024 , eprint=
2024
-
[13]
The Internal State of an
Amos Azaria and Tom Mitchell , booktitle=. The Internal State of an. 2023 , url=
2023
-
[14]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[15]
2025 , eprint=
A mathematical perspective on Transformers , author=. 2025 , eprint=
2025
-
[16]
2022 , eprint=
In-context Learning and Induction Heads , author=. 2022 , eprint=
2022
-
[17]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
2023
-
[18]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex J Andonian and Yonatan Belinkov , booktitle=. Locating and Editing Factual Associations in. 2022 , url=
2022
-
[19]
Advances in Neural Information Processing Systems , editor=
Causal Abstractions of Neural Networks , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
2021
-
[20]
Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference
Schick, Timo and Sch. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.20
-
[21]
Making Pre-trained Language Models Better Few-shot Learners , url =
Gao, Tianyu and Fisch, Adam and Chen, Danqi. Making Pre-trained Language Models Better Few-shot Learners. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.295
-
[22]
Proceedings of the 38th International Conference on Machine Learning , pages =
Calibrate Before Use: Improving Few-shot Performance of Language Models , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[23]
First Conference on Language Modeling , year=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. First Conference on Language Modeling , year=
-
[24]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[25]
2024 , eprint=
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools , author=. 2024 , eprint=
2024
-
[26]
2023 , url=
Solving Math Word Problems with Process-based and Outcome-based Feedback , author=. 2023 , url=
2023
-
[27]
2023 , eprint=
Let's Verify Step by Step , author=. 2023 , eprint=
2023
-
[28]
2022 , eprint=
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
2022
-
[29]
2025 , eprint=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. 2025 , eprint=
2025
-
[30]
2026 , eprint=
Reasoning Theater: Disentangling Model Beliefs from Chain-of-Thought , author=. 2026 , eprint=
2026
-
[31]
SelfReflect: Can
Michael Kirchhof and Luca F. SelfReflect: Can. The Fourteenth International Conference on Learning Representations , year=
-
[32]
2026 , eprint=
Large Reasoning Models Are (Not Yet) Multilingual Latent Reasoners , author=. 2026 , eprint=
2026
-
[33]
2025 , eprint=
LogitLens4LLMs: Extending Logit Lens Analysis to Modern Large Language Models , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.