Recognition: no theorem link
Gradient Extrapolation-Based Policy Optimization
Pith reviewed 2026-05-11 02:01 UTC · model grok-4.3
The pith
GXPO approximates longer local lookahead in policy updates with only three backward passes by extrapolating gradient changes after two fast optimizer steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GXPO approximates a longer local lookahead using only three backward passes during an active phase by taking two fast optimizer steps, measuring how the gradients change, predicting a virtual K-step lookahead point, moving the policy partway toward that point, and then applying a corrective update using the true gradient at the new position while reusing the same batch of rollouts, rewards, advantages, and GRPO loss; it automatically switches back to standard GRPO when the lookahead signal becomes unstable, and a plain-gradient-descent surrogate analysis explains when the extrapolation is exact and where its local errors come from.
What carries the argument
The gradient extrapolation step that observes changes after two fast optimizer steps to construct a predicted K-step policy position for virtual lookahead without new rollouts or reward computation.
Load-bearing premise
That the observed gradient change after two fast optimizer steps provides a sufficiently accurate local linear or low-order extrapolation of the policy trajectory over K steps, and that the automatic stability check reliably detects when this approximation breaks without missing useful updates.
What would settle it
A direct comparison on a small model where actual K-step lookahead trajectories are computed and shown to deviate substantially from GXPO's extrapolated point on the same rollouts even when the stability check passes.
Figures




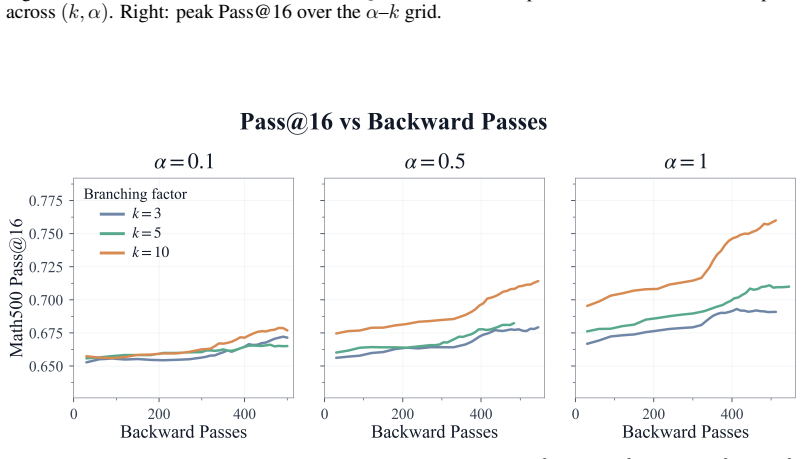




read the original abstract
Reinforcement learning is widely used to improve the reasoning ability of large language models, especially when answers can be automatically checked. Standard GRPO-style training updates the model using only the current step, while full multi-step lookahead can give a better update direction but is too expensive because it needs many backward passes. We propose Gradient Extrapolation-Based Policy Optimization (GXPO), a plug-compatible policy-update rule for GRPO-style reasoning RL. GXPO approximates a longer local lookahead using only three backward passes during an active phase. It reuses the same batch of rollouts, rewards, advantages, and GRPO loss, so it does not require new rollouts or reward computation at the lookahead points. GXPO takes two fast optimizer steps, measures how the gradients change, predicts a virtual K-step lookahead point, moves the policy partway toward that point, and then applies a corrective update using the true gradient at the new position. When the lookahead signal becomes unstable, GXPO automatically switches back to standard single-pass GRPO. We also give a plain-gradient-descent surrogate analysis that explains when the extrapolation is exact and where its local errors come from. Across Qwen2.5 and Llama math-reasoning experiments, GXPO improves the average sampled pass@1 by +1.65 to +5.00 points over GRPO and by +0.14 to +1.28 points over the strongest SFPO setting, while keeping the active-phase cost fixed at three backward passes. It also achieves up to 4.00x step speedup, 2.33x wall-clock speedup, and 1.33x backward-pass speedup in reaching GRPO's peak accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Gradient Extrapolation-Based Policy Optimization (GXPO), a plug-compatible update rule for GRPO-style RL on LLM reasoning tasks. GXPO approximates a K-step local lookahead by performing two fast optimizer steps on the current batch of rollouts/rewards/advantages/GRPO loss, measuring the resulting gradient change, and extrapolating a virtual policy position; it then applies a corrective update and falls back to standard single-pass GRPO when an automatic stability check detects instability. A plain-gradient-descent surrogate analysis is supplied to characterize when the extrapolation is exact and where local errors arise. Experiments on Qwen2.5 and Llama math-reasoning benchmarks report pass@1 gains of +1.65 to +5.00 over GRPO and +0.14 to +1.28 over the strongest SFPO baseline, with the active phase fixed at three backward passes and speedups up to 4.00x in steps, 2.33x wall-clock, and 1.33x backward passes.
Significance. If the extrapolation rule transfers reliably from the plain-GD surrogate to the actual GRPO objective, the method would supply a low-overhead mechanism for incorporating limited multi-step lookahead without new rollouts or reward evaluations. The reported accuracy gains combined with fixed three-backward-pass cost and the speedups to reach peak accuracy would constitute a practical advance for RL-based reasoning training, provided the stability check and extrapolation remain accurate across model scales and task distributions.
major comments (2)
- [Surrogate analysis and method description] The surrogate analysis is stated to cover only plain gradient descent and to identify conditions under which the two-step gradient difference exactly predicts the K-step trajectory. However, the deployed loss is the GRPO objective (advantage-weighted log-probability terms, clipping, and any KL or entropy regularizers). Because the derivation assumes an unconstrained quadratic or smooth GD flow, the measured gradient difference on the composite GRPO loss need not obey the same linear or low-order extrapolation; this directly affects whether the virtual lookahead point and the stability check are reliable. (See abstract description of the surrogate and the method overview.)
- [Experiments] The abstract reports average pass@1 improvements but supplies no error bars, number of random seeds, ablation results on the stability-check threshold or extrapolation horizon K, or statistical significance tests. Without these, it is impossible to determine whether the +1.65 to +5.00 point gains over GRPO are robust or whether they could be explained by variance in the base GRPO runs.
minor comments (3)
- [Method overview] The high-level description of the three-backward-pass procedure would benefit from explicit pseudocode or a numbered algorithmic listing that distinguishes the two fast steps, the extrapolation computation, the corrective update, and the stability check.
- [Abstract and method] Notation for the extrapolated policy position, the gradient-difference vector, and the stability metric should be introduced once and used consistently; currently the abstract leaves several quantities implicit.
- [Method overview] The claim of 'plug-compatible' with GRPO should be accompanied by a short statement of which GRPO hyperparameters (clipping threshold, KL coefficient, etc.) remain unchanged under GXPO.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our work. Below we provide point-by-point responses to the major comments and indicate the revisions we intend to make.
read point-by-point responses
-
Referee: [Surrogate analysis and method description] The surrogate analysis is stated to cover only plain gradient descent and to identify conditions under which the two-step gradient difference exactly predicts the K-step trajectory. However, the deployed loss is the GRPO objective (advantage-weighted log-probability terms, clipping, and any KL or entropy regularizers). Because the derivation assumes an unconstrained quadratic or smooth GD flow, the measured gradient difference on the composite GRPO loss need not obey the same linear or low-order extrapolation; this directly affects whether the virtual lookahead point and the stability check are reliable. (See abstract description of the surrogate and the method overview.)
Authors: We clarify that the surrogate analysis under plain gradient descent is provided to offer theoretical intuition regarding the conditions for exact extrapolation and the origins of approximation errors in a controlled setting. The actual GXPO implementation operates on the GRPO loss and includes a stability check to revert to standard updates when the extrapolated signal is deemed unreliable. We agree that further analysis bridging the surrogate to the full GRPO objective would be beneficial. In the revised manuscript, we will add a dedicated subsection discussing the limitations of the surrogate and providing empirical evidence from our training runs on the frequency and impact of fallback to GRPO. revision: partial
-
Referee: [Experiments] The abstract reports average pass@1 improvements but supplies no error bars, number of random seeds, ablation results on the stability-check threshold or extrapolation horizon K, or statistical significance tests. Without these, it is impossible to determine whether the +1.65 to +5.00 point gains over GRPO are robust or whether they could be explained by variance in the base GRPO runs.
Authors: The referee correctly identifies the lack of statistical details in the current presentation. To address this, we will revise the experimental section to include results from multiple random seeds, error bars, ablations on the stability-check threshold and the value of K, and appropriate statistical significance tests. These additions will help demonstrate the robustness of the observed improvements across the Qwen2.5 and Llama models. revision: yes
Circularity Check
No significant circularity; surrogate analysis is explanatory and results are empirical.
full rationale
The paper introduces GXPO as a practical algorithm that reuses existing rollouts and GRPO loss computations to approximate a K-step lookahead via two fast optimizer steps and a stability check. The provided surrogate analysis is explicitly described as explanatory for the plain-GD case and does not define or derive the GRPO-specific update rule; the reported gains (+1.65 to +5.00 pass@1 over GRPO) are presented as experimental measurements on Qwen2.5 and Llama models rather than quantities obtained by fitting or renaming the same inputs. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no prediction reduces by construction to a fitted parameter or prior result. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
AlpaGasus : Training a better Alpaca with fewer data
Chen, L., Li, S., Yan, J., Wang, H., Gunaratna, K., Yadav, V., Tang, Z., Srinivasan, V., Zhou, T., Huang, H., and Jin, H. AlpaGasus : Training a better Alpaca with fewer data. In ICLR, 2024
work page 2024
-
[3]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Cui, G., Zhang, Y., Chen, J., Yuan, L., Wang, Z., Zuo, Y., Li, H., Fan, Y., Chen, H., Chen, W., Liu, Z., Peng, H., Bai, L., Ouyang, W., Cheng, Y., Zhou, B., and Ding, N. The entropy mechanism of reinforcement learning for reasoning language models. arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Stable reinforcement learning for efficient reasoning
Dai, M., Liu, S., and Si, Q. Stable reinforcement learning for efficient reasoning. arXiv preprint arXiv:2505.18086, 2025
-
[6]
Policy gradient with tree expansion
Dalal, G., Hallak, A., Thoppe, G., Mannor, S., and Chechik, G. Policy gradient with tree expansion. In ICML, 2025
work page 2025
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1 : Incentivizing reasoning capability in LLM s via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Concise reasoning via reinforcement learning
Fatemi, M., Rafiee, B., Tang, M., and Talamadupula, K. Concise reasoning via reinforcement learning. arXiv preprint arXiv:2504.05185, 2025
-
[10]
He, C., Luo, R., Bai, Y., Hu, S., Thai, Z. L., Shen, J., Hu, J., Han, X., Huang, Y., Zhang, Y., et al. OlympiadBench : A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. arXiv preprint arXiv:2402.14008, 2024
work page internal anchor Pith review arXiv 2024
-
[11]
He, J., Li, T., Feng, E., Du, D., Liu, Q., Liu, T., Xia, Y., and Chen, H. History rhymes: Accelerating LLM reinforcement learning with RhymeRL . arXiv preprint arXiv:2508.18588, 2025
-
[12]
Measuring mathematical problem solving with the MATH dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the MATH dataset. In NeurIPS, 2021
work page 2021
-
[13]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. LoRA : Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
In: Proceedings of the 29th Symposium on Operating Systems Principles
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with PagedAttention . In Proceedings of the 29th Symposium on Operating Systems Principles (SOSP '23), pages 611--626, 2023. doi:10.1145/3600006.3613165
-
[15]
Solving quantitative reasoning problems with language models
Lewkowycz, A., Andreassen, A., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V., Slone, A., Anil, C., Schlag, I., Gutman-Solo, T., et al. Solving quantitative reasoning problems with language models. In NeurIPS, 2022
work page 2022
-
[16]
Limr: Less is more for rl scaling.arXiv preprint arXiv:2502.11886, 2025
Li, X., Zou, H., and Liu, P. LIMR : Less is more for RL scaling. arXiv preprint arXiv:2502.11886, 2025
-
[17]
Understanding R1-Zero-Like Training: A Critical Perspective
Liu, Z., Chen, C., Li, W., Qi, P., Pang, T., Du, C., Lee, W. S., and Lin, M. Understanding R1-Zero -like training: A critical perspective. arXiv preprint arXiv:2503.20783, 2025
work page Pith review arXiv 2025
-
[18]
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. In ICLR, 2019
work page 2019
-
[19]
Art of Problem Solving. AMC Problems and Solutions. https://artofproblemsolving.com/wiki/index.php?title=AMC_Problems_and_Solutions, 2024
work page 2024
-
[20]
Llama 3.2 : Revolutionizing edge AI and vision with open, customizable models
Meta. Llama 3.2 : Revolutionizing edge AI and vision with open, customizable models. Technical blog, 2024. https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
work page 2024
-
[21]
Mroueh, Y. Reinforcement learning with verifiable rewards: GRPO 's effective loss, dynamics, and success amplification. arXiv preprint arXiv:2503.06639, 2025
-
[22]
Mroueh, Y., Dupuis, N., Belgodere, B., Nitsure, A., Rigotti, M., Greenewald, K., Navratil, J., Ross, J., and Rios, J. Revisiting group relative policy optimization: Insights into on-policy and off-policy training. arXiv preprint arXiv:2505.22257, 2025
-
[23]
Muennighoff, N., Yang, Z., Shi, W., Li, X. L., Li, F.-F., Hajishirzi, H., Zettlemoyer, L., Liang, P., Cand \`e s, E., and Hashimoto, T. s1: Simple test-time scaling. arXiv preprint arXiv:2501.19393, 2025
work page Pith review arXiv 2025
-
[24]
Protopapas, K. and Barakat, A. Policy mirror descent with lookahead. In NeurIPS, 2024
work page 2024
-
[25]
Qwen, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Planning and learning with adaptive lookahead
Rosenberg, A., Hallak, A., Mannor, S., Chechik, G., and Dalal, G. Planning and learning with adaptive lookahead. In AAAI, 2023
work page 2023
-
[27]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., et al. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
arXiv preprint arXiv:2508.05928
Shen, S., Shen, P., Zhao, W., and Zhu, D. Mitigating think-answer mismatch in LLM reasoning through noise-aware advantage reweighting. arXiv preprint arXiv:2508.05928, 2025
-
[30]
HybridFlow: A Flexible and Efficient RLHF Framework , url=
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y., Lin, H., and Wu, C. HybridFlow : A flexible and efficient RLHF framework. In Proceedings of the Twentieth European Conference on Computer Systems (EuroSys '25), 2025. doi:10.1145/3689031.3696075
-
[31]
Learning off-policy with online planning
Sikchi, H., Zhou, W., and Held, D. Learning off-policy with online planning. In CoRL, 2021
work page 2021
-
[32]
S., McAllester, D., Singh, S., and Mansour, Y
Sutton, R. S., McAllester, D., Singh, S., and Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In NeurIPS, 1999
work page 1999
-
[33]
Slow-Fast Policy Optimization : Reposition-before-update for LLM reasoning
Wang, Z., Wang, Z., Fu, J., Qu, X., Cheng, Q., Tang, S., Zhang, M., and Huo, X. Slow-Fast Policy Optimization : Reposition-before-update for LLM reasoning. In ICLR, 2026
work page 2026
-
[34]
Reinforcement learning for reasoning in large language models with one training example, 2025
Wang, Y., Yang, Q., Zeng, Z., Ren, L., Liu, L., Peng, B., Cheng, H., He, X., Wang, K., Gao, J., et al. Reinforcement learning for reasoning in large language models with one training example. arXiv preprint arXiv:2504.20571, 2025
-
[35]
Wen, X., Liu, Z., Zheng, S., Ye, S., Wu, Z., Wang, Y., Xu, Z., Liang, X., Li, J., Miao, Z., Bian, J., and Yang, M. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base LLM s. arXiv preprint arXiv:2506.14245, 2025
work page internal anchor Pith review arXiv 2025
-
[36]
Williams, R. J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3--4):229--256, 1992
work page 1992
-
[37]
LESS : Selecting influential data for targeted instruction tuning
Xia, M., Malladi, S., Gururangan, S., Arora, S., and Chen, D. LESS : Selecting influential data for targeted instruction tuning. In Proceedings of the 41st International Conference on Machine Learning, PMLR 235:54104--54132, 2024
work page 2024
-
[38]
A minimalist approach to llm reasoning: from rejection sampling to reinforce, 2025
Xiong, W., Yao, J., Xu, Y., Pang, B., Wang, L., Sahoo, D., Li, J., Jiang, N., Zhang, T., Xiong, C., and Dong, H. A minimalist approach to LLM reasoning: From rejection sampling to reinforce. arXiv preprint arXiv:2504.11343, 2025
-
[39]
E., Savani, Y., Fang, F., and Kolter, J
Xu, Y. E., Savani, Y., Fang, F., and Kolter, J. Z. Not all rollouts are useful: Down-sampling rollouts in LLM reinforcement learning. Transactions on Machine Learning Research, 2026
work page 2026
-
[40]
LIMO : Less is more for reasoning
Ye, Y., Huang, Z., Xiao, Y., Chern, E., Xia, S., and Liu, P. LIMO : Less is more for reasoning. In COLM, 2025
work page 2025
-
[41]
DAPO : An open-source LLM reinforcement learning system at scale
Yu, Q., Zhang, Z., Zhu, R., et al. DAPO : An open-source LLM reinforcement learning system at scale. In NeurIPS, 2025
work page 2025
-
[42]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yue, Y., Yuan, Y., Yu, Q., Zuo, X., Zhu, R., Xu, W., Chen, J., Wang, C., Fan, T., Du, Z., Wei, X., Yu, X., Liu, G., Liu, J., Liu, L., Lin, H., Lin, Z., Ma, B., Zhang, C., Zhang, M., Zhang, W., Zhu, H., Zhang, R., Liu, X., Wang, M., Wu, Y., and Yan, L. VAPO : Efficient and reliable reinforcement learning for advanced reasoning tasks. arXiv preprint arXiv:2...
work page internal anchor Pith review arXiv 2025
-
[43]
Zhang, M., Lucas, J., Ba, J., and Hinton, G. E. Lookahead optimizer: k steps forward, 1 step back. In NeurIPS, 2019
work page 2019
-
[44]
Towards understanding why lookahead generalizes better than SGD and beyond
Zhou, P., Yan, H., Yuan, X., Feng, J., and Yan, S. Towards understanding why lookahead generalizes better than SGD and beyond. In NeurIPS, 2021
work page 2021
-
[45]
Zheng, H., Zhou, Y., Bartoldson, B. R., Kailkhura, B., Lai, F., Zhao, J., and Chen, B. Act only when it pays: Efficient reinforcement learning for LLM reasoning via selective rollouts. arXiv preprint arXiv:2506.02177, 2025
-
[46]
TTRL: Test-Time Reinforcement Learning
Zuo, Y., Zhang, K., Sheng, L., Qu, S., Cui, G., Zhu, X., Li, H., Zhang, Y., Long, X., Hua, E., Qi, B., Sun, Y., Ma, Z., Yuan, L., Ding, N., and Zhou, B. TTRL : Test-time reinforcement learning. arXiv preprint arXiv:2504.16084, 2025
work page Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.