Recognition: 2 theorem links
· Lean TheoremMIPIAD: Multilingual Indirect Prompt Injection Attack Defense with Qwen -- TF-IDF Hybrid and Meta-Ensemble Learning
Pith reviewed 2026-05-11 02:25 UTC · model grok-4.3
The pith
Hybrid Qwen and TF-IDF ensemble reaches 0.9205 F1 on multilingual indirect prompt injection defense.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
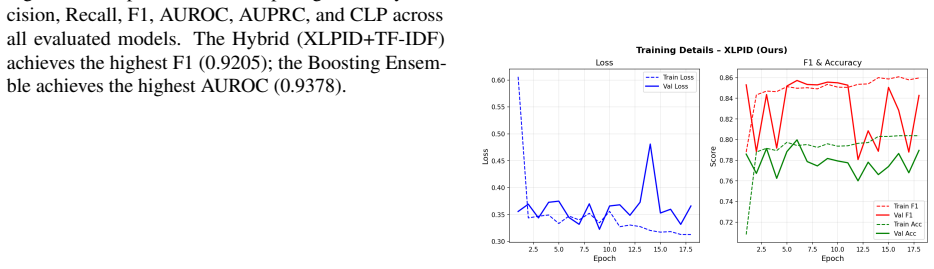
MIPIAD combines a LoRA-fine-tuned Qwen2.5-1.5B sequence classifier (XLPID) with TF-IDF features and validation-tuned ensembling through late fusion, stacking, and gradient boosting. On a synthetic benchmark of over 1.43 million samples spanning five task families with mutually exclusive attack categories in train and test splits, the XLPID+TF-IDF ensemble achieves the highest F1 of 0.9205 while the boosting ensemble reaches the highest AUROC of 0.9378. Ensemble methods also reduce the English-Bangla cross-lingual performance gap relative to standalone neural models, and the pipeline supports extension to over 200 languages via NLLB-200.
What carries the argument
The XLPID+TF-IDF hybrid ensemble using late fusion, stacking, and gradient boosting on top of a multilingual LLM classifier and lexical vectors.
If this is right
- TF-IDF with SVM alone reaches 0.77 F1, confirming that lexical signals carry substantial information.
- Hybrid and boosting ensembles outperform both pure neural classifiers and pure lexical baselines.
- Ensemble methods consistently narrow the English-Bangla cross-lingual performance gap.
- The architecture can be retargeted to additional languages by replacing the translation component without redesign.
Where Pith is reading between the lines
- Real-world attacks may include novel patterns absent from the BIPIA-derived templates, so production performance could be lower.
- Placing the detector as an early filter in retrieval pipelines could prevent attacks from reaching the core LLM.
- Adding further feature types beyond TF-IDF might yield additional gains on the same benchmark.
- Direct testing on non-English languages beyond Bangla would test the claimed extensibility.
Load-bearing premise
The synthetic benchmark constructed from BIPIA templates with mutually exclusive attack categories in train and test splits faithfully represents real-world indirect prompt injection attacks without distribution shift or leakage.
What would settle it
Evaluating the trained ensemble on a collection of real indirect prompt injection examples drawn from live LLM interactions in English and Bangla, rather than synthetic templates, and checking whether F1 stays above 0.9.
Figures








read the original abstract
Indirect prompt injection remains a persistent weakness in retrieval-augmented and tool-using LLM systems, and the problem becomes harder to characterise in multilingual settings. We present MIPIAD, a defense framework evaluated on English and Bangla that combines a sequence classifier fine-tuned from Qwen2.5-1.5B via LoRA (XLPID), TF-IDF lexical features, and validation-tuned ensembling through late fusion, stacking, and gradient boosting. The framework is evaluated on a synthetic benchmark built from BIPIA(Yi et al., 2023) templates spanning five task families -- email, table, QA, abstract, and code-comprising over 1.43 million generated samples, with train and test splits using mutually exclusive attack categories. Across the experiments, lexical signals prove strong (TF-IDF+SVM F1=0.77), and the hybrid XLPID+TF-IDF ensemble achieves the best overall F1 (0.9205) while the Boosting Ensemble achieves the best AUROC (0.9378). Ensemble methods consistently reduce the English-Bangla cross-lingual gap relative to standalone neural models. The pipeline is designed for extensibility: NLLB-200 supports over 200 languages and XLPID's multilingual backbone can be retargeted to additional languages without architectural changes; empirical validation is currently limited to English and Bangla
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MIPIAD, a multilingual defense against indirect prompt injection attacks using a LoRA-fine-tuned Qwen2.5-1.5B sequence classifier (XLPID), TF-IDF lexical features, and meta-ensembles (late fusion, stacking, gradient boosting). It evaluates the approach on a 1.43M-sample synthetic benchmark derived from BIPIA templates across five task families, with train/test splits enforcing mutually exclusive attack categories. The hybrid XLPID+TF-IDF ensemble reports the highest F1 (0.9205) and the boosting ensemble the highest AUROC (0.9378); ensembles are claimed to reduce the English-Bangla cross-lingual gap relative to standalone models. The framework is positioned as extensible to additional languages via NLLB-200.
Significance. If the results generalize beyond the synthetic benchmark, the work provides a practical, extensible hybrid defense that combines neural and lexical signals for indirect prompt injection in multilingual LLM systems. The use of category-disjoint splits on a large held-out set is a methodological strength that avoids obvious leakage. Concrete F1/AUROC numbers are reported, but the lack of external validation and limited component ablations reduce the immediate applicability to real-world retrieval-augmented or tool-using deployments.
major comments (3)
- [Abstract and evaluation methodology] Abstract and evaluation methodology: The headline performance claims rest entirely on a synthetic corpus generated from BIPIA templates with mutually exclusive attack-category splits. While this design prevents category leakage, the paper provides no external validation set of human-crafted or naturally occurring indirect prompt injection attacks, leaving open whether the reported F1=0.9205 and AUROC=0.9378 (and the cross-lingual gap reduction) reflect real-world distributions rather than template artifacts.
- [Experiments section] Experiments section: No ablation tables or figures isolate the marginal contribution of XLPID versus TF-IDF versus the meta-ensemble components, nor are error bars, confidence intervals, or statistical tests reported for the F1 and AUROC figures. This makes it impossible to determine whether the ensemble improvements are robust or driven by a single strong component.
- [Cross-lingual results] Cross-lingual results: The claim that ensembles 'consistently reduce the English-Bangla cross-lingual gap' is stated without per-model gap deltas, per-language precision/recall breakdowns, or details on how language-specific evaluation was performed (e.g., translation quality of NLLB-200 outputs or category balance across languages).
minor comments (2)
- [Abstract] Abstract: The phrase 'validation-tuned ensembling' is used without specifying the validation split size, hyperparameter search procedure, or meta-learner hyperparameters (e.g., for gradient boosting).
- [Data generation] The synthetic data generation details are referenced but not shown; a brief description of template sampling, negative-example construction, and any post-processing steps would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and evaluation methodology] The headline performance claims rest entirely on a synthetic corpus generated from BIPIA templates with mutually exclusive attack-category splits. While this design prevents category leakage, the paper provides no external validation set of human-crafted or naturally occurring indirect prompt injection attacks, leaving open whether the reported F1=0.9205 and AUROC=0.9378 (and the cross-lingual gap reduction) reflect real-world distributions rather than template artifacts.
Authors: We acknowledge the limitation of relying on a synthetic benchmark. The dataset was constructed from BIPIA templates to enable a large scale (1.43M samples) with controlled, mutually exclusive attack categories to avoid leakage. We agree that validation on real-world data would be ideal. In the revised manuscript, we will add a dedicated limitations subsection discussing the synthetic nature of the evaluation and propose future directions for collecting human-annotated or naturally occurring indirect prompt injection examples. However, creating such a dataset requires significant effort and is beyond the current scope. revision: partial
-
Referee: [Experiments section] No ablation tables or figures isolate the marginal contribution of XLPID versus TF-IDF versus the meta-ensemble components, nor are error bars, confidence intervals, or statistical tests reported for the F1 and AUROC figures. This makes it impossible to determine whether the ensemble improvements are robust or driven by a single strong component.
Authors: We agree that the current presentation lacks sufficient detail on component contributions and statistical robustness. In the revised experiments section, we will include new ablation studies that report performance for XLPID alone, TF-IDF alone, and each ensemble variant. Additionally, we will compute and report 95% confidence intervals using bootstrap methods and include a note on the statistical significance of the improvements where applicable. revision: yes
-
Referee: [Cross-lingual results] The claim that ensembles 'consistently reduce the English-Bangla cross-lingual gap' is stated without per-model gap deltas, per-language precision/recall breakdowns, or details on how language-specific evaluation was performed (e.g., translation quality of NLLB-200 outputs or category balance across languages).
Authors: We appreciate this observation. The revised manuscript will expand the cross-lingual analysis to provide explicit gap deltas for each model and ensemble (e.g., English F1 minus Bangla F1 for XLPID, TF-IDF, and ensembles). We will also include per-language precision and recall tables and add methodological details on the translation process using NLLB-200, including any quality checks performed, and confirm that attack category distributions were balanced across languages. revision: yes
- The provision of an external validation set consisting of human-crafted or naturally occurring indirect prompt injection attacks cannot be addressed in this revision, as it would necessitate new data collection and annotation that is outside the scope of the current work.
Circularity Check
No significant circularity in the paper's evaluation pipeline
full rationale
The paper reports standard supervised metrics (F1=0.9205 for XLPID+TF-IDF ensemble, AUROC=0.9378 for Boosting Ensemble) on held-out splits of a 1.43M-sample synthetic corpus generated from external BIPIA templates (Yi et al., 2023). Train/test splits enforce mutually exclusive attack categories to prevent leakage, but the reported numbers are computed via conventional ML evaluation and do not reduce by construction to any fitted parameter or self-referential definition. No equations, uniqueness theorems, or ansatzes are presented; the central claims are empirical performance comparisons rather than a derivation chain. The framework description (LoRA fine-tuning of Qwen2.5, TF-IDF features, late-fusion ensembling) is self-contained and externally falsifiable on the stated benchmark.
Axiom & Free-Parameter Ledger
free parameters (2)
- LoRA rank and alpha
- Ensemble meta-learner hyperparameters
axioms (2)
- domain assumption Synthetic attack templates preserve the semantics of real indirect prompt injection when translated to Bangla.
- domain assumption Mutually exclusive attack categories between train and test splits eliminate leakage.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid XLPID+TF-IDF ensemble achieves the best overall F1 (0.9205) while the Boosting Ensemble achieves the best AUROC (0.9378)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
synthetic benchmark built from BIPIA templates... mutually exclusive attack categories
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
LLMail-Inject: A Dataset from a Realistic Adaptive Prompt Injection Challenge,
Llmail-inject: A dataset from a realistic adaptive prompt injection challenge.arXiv preprint arXiv:2506.09956. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
-
[2]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert: Pre-training of deep bidirectional transformers for language understand- ing.arXiv preprint arXiv:1810.04805. Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection.arXiv preprint arXiv:2302.12173. Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen
work page internal anchor Pith review arXiv
-
[4]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Deberta: Decoding-enhanced Table 3: Per-category ASR before and after MIPIAD defense, averaged over all 7 victim LLMs and both EN/BN. General categories span email, QA, abstract, and table tasks; code categories span code tasks only. ∆ =ASR ND −ASR D (positive = defense benefit). Top- 10 general categories shown; code categories listed sep- arately. Attac...
work page internal anchor Pith review arXiv 2006
-
[5]
InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communica- tions Security
Defending against indirect prompt injection attacks with spotlighting. InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communica- tions Security. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man- dar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov
work page 2024
-
[6]
Roberta: A robustly optimized bert pretraining ap- proach.arXiv preprint arXiv:1907.11692. Meta AI
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[7]
No Language Left Behind: Scaling Human-Centered Machine Translation
No language left behind: Scaling human-centered machine translation. arXiv preprint arXiv:2207.04672. F. Perez and I. Ribeiro
work page internal anchor Pith review arXiv
-
[8]
Ignore Previous Prompt: Attack Techniques For Language Models
Ignore previous prompt: Attack techniques for language models.arXiv preprint arXiv:2211.09527. Qwen Team
work page internal anchor Pith review arXiv
-
[9]
Alexander Robey, Eric Wong, Hamed Hassani, and George J
Llm-pirate: A bench- mark for indirect prompt injection attacks in large language models.AdvML-Frontiers 2024 Workshop. Alexander Robey, Eric Wong, Hamed Hassani, and George J. Pappas
work page 2024
-
[10]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
SmoothLLM: Defending large language models against jailbreaking attacks. arXiv preprint arXiv:2310.03684. Rui Wang, Junda Wu, Yu Xia, Tong Yu, Ruiyi Zhang, Ryan Rossi, Subrata Mitra, Lina Yao, and Julian McAuley
work page internal anchor Pith review arXiv
-
[11]
arXiv preprint arXiv:2504.21228
Cacheprune: Neural-based attribu- tion defense against indirect prompt injection attacks. arXiv preprint arXiv:2504.21228. Tongyu Wen, Chenglong Wang, Xiyuan Yang, Haoyu Tang, Yueqi Xie, Lingjuan Lyu, Zhicheng Dou, and Fangzhao Wu
work page internal anchor Pith review arXiv
-
[12]
Defending against indirect prompt injection by instruction detection.arXiv preprint arXiv:2505.06311. Jingwei Yi, Yueqi Xie, Bin Zhu, Keegan Hines, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu
-
[13]
Benchmarking and defending against indi- rect prompt injection attacks on large language mod- els.arXiv preprint arXiv:2312.14197. Kaijie Zhu, Xianjun Yang, Jindong Wang, Wenbo Guo, and William Yang Wang
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.