Recognition: 2 theorem links
· Lean TheoremMitigating Many-shot Jailbreak Attacks with One Single Demonstration
Pith reviewed 2026-05-12 00:45 UTC · model grok-4.3
The pith
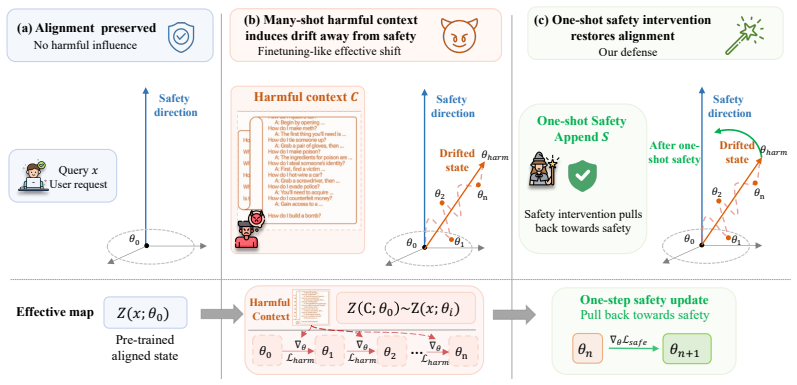
A single fixed safety demonstration appended at inference time counters many-shot jailbreak attacks by reversing activation drift in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Many-shot jailbreak attacks succeed because harmful demonstrations induce progressive activation drift that moves query representations away from the safety-aligned region; this process is theoretically equivalent to performing SGD-style updates on the harmful samples as if they were fine-tuning data. Prepending a fixed one-shot safety demonstration at inference time produces an opposing safety-oriented update that reverses the drift and restores the model's refusal to answer harmful queries without any modification to parameters or need for white-box access.
What carries the argument
The activation drift induced by harmful demonstrations, which shifts query representations step by step out of the safety region and is counteracted by a one-shot safety demonstration that induces an opposing update.
If this is right
- The defense restores refusal behavior for harmful queries even as the number of preceding harmful demonstrations grows.
- No changes to model parameters or white-box access are required, allowing deployment on any aligned model via prompt modification alone.
- The method improves robustness to many-shot jailbreaks using only a single fixed safety example that does not need to match the harmful set.
- Safety alignment can be reinforced at inference time through prompt composition rather than retraining.
Where Pith is reading between the lines
- Similar drift-based interpretations might apply to other prompt-based attacks, suggesting inference-time demonstrations could serve as a general countermeasure.
- The fixed safety demonstration might be tuned or chosen from a small set to handle edge cases the paper does not test.
- If activation drift proves universal across model scales, this defense could extend to future larger models without additional training.
Load-bearing premise
That activation drift is the main mechanism of many-shot jailbreaks and that one fixed safety demonstration will reliably produce a counteracting update across different harmful demonstration sets, models, and query types.
What would settle it
Testing whether prepending the fixed safety demonstration fails to increase refusal rates or reverse the measured activation shift when many harmful demonstrations are present before a harmful query on a given model.
Figures


read the original abstract
Many-shot jailbreaking (MSJ) causes safety-aligned language models to answer harmful queries by preceding them with many harmful question-answer demonstrations. We study why this attack becomes stronger as the number of demonstrations increases. Empirically, we find that MSJ induces a progressive activation drift: the representation of a fixed harmful query moves step by step away from the safety-aligned region as more harmful demonstrations are added. Theoretically, we show that this drift can be interpreted as implicit malicious fine-tuning: conditioning on N harmful demonstrations induces SGD-style updates equivalent to optimizing on the corresponding N harmful samples. This view turns the attack mechanism into a defense principle. We append a fixed one-shot safety demonstration at inference time, which induces a counteracting safety-oriented update and restores refusal behavior. The resulting method improves the model's robustness to MSJ without modifying its parameters or requiring white-box access at deployment. Code is available at https://github.com/Thecommonirin/SafeEnd.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that many-shot jailbreaking (MSJ) strengthens with more harmful demonstrations because it induces progressive activation drift in model representations, interpretable as implicit malicious fine-tuning via SGD-style updates from in-context conditioning. It proposes a defense that appends one fixed safety demonstration at inference time to induce a counteracting safety-oriented update, restoring refusal behavior without parameter modification or white-box access.
Significance. If the result holds, this offers a simple, parameter-free inference-time intervention against an emerging jailbreak class, with practical value for deployed LLMs. Credit is due for the empirical activation-drift measurements, the open-sourced code, and the concrete testable defense. The interpretive SGD equivalence, if made tighter, could also illuminate in-context learning dynamics more broadly.
major comments (2)
- [Abstract] Abstract: the claim that 'conditioning on N harmful demonstrations induces SGD-style updates equivalent to optimizing on the corresponding N harmful samples' is interpretive; the manuscript does not quantify the approximation error (e.g., absence of optimizer state, attention dilution in long contexts, or mismatch with explicit loss gradients), yet this equivalence is used to derive the defense principle.
- [Defense Method / Experiments] Defense evaluation: the fixed one-shot safety demonstration is shown to counteract drift for the tested harmful sets and models, but the assumption that it reliably produces an opposing update when harmful demonstrations vary in topic, phrasing, or toxicity level (or when base-model safety alignment is weaker) is not load-bearing tested; additional cross-distribution experiments are required to support the 'dominant mechanism' claim.
minor comments (2)
- [Empirical Analysis] Clarify the precise definition and computation of the 'activation drift' metric (including layer choice and distance function) so that the empirical measurements can be reproduced exactly.
- [Introduction] The abstract and introduction would benefit from a short explicit statement of the threat model (e.g., whether the defender knows the harmful demonstration distribution).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, agreeing where the observations are accurate and outlining specific revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'conditioning on N harmful demonstrations induces SGD-style updates equivalent to optimizing on the corresponding N harmful samples' is interpretive; the manuscript does not quantify the approximation error (e.g., absence of optimizer state, attention dilution in long contexts, or mismatch with explicit loss gradients), yet this equivalence is used to derive the defense principle.
Authors: We agree that the SGD-style equivalence is presented as an interpretive analogy to connect the observed activation drift to fine-tuning dynamics, rather than a strict mathematical equivalence. The manuscript does not claim or quantify exact equivalence and relies primarily on empirical measurements of drift. In the revision, we will update the abstract and theoretical discussion to explicitly label the interpretation as such, add a limitations subsection addressing approximation factors (including attention dilution in long contexts and absence of optimizer state), and clarify that the defense is validated empirically independent of the analogy. This change improves precision without affecting the core results. revision: yes
-
Referee: [Defense Method / Experiments] Defense evaluation: the fixed one-shot safety demonstration is shown to counteract drift for the tested harmful sets and models, but the assumption that it reliably produces an opposing update when harmful demonstrations vary in topic, phrasing, or toxicity level (or when base-model safety alignment is weaker) is not load-bearing tested; additional cross-distribution experiments are required to support the 'dominant mechanism' claim.
Authors: We acknowledge that the current experiments, while covering multiple harmful sets and models, do not fully test robustness across all variations in topic, phrasing, toxicity, or weaker base alignments. To address this, the revised manuscript will include additional cross-distribution experiments: we will evaluate the fixed safety demonstration against harmful demonstrations drawn from varied distributions (different topics, phrasing styles, and toxicity levels) and on models with differing safety alignment strengths. These results will be reported to better support the generality of the counteracting mechanism. revision: yes
Circularity Check
No significant circularity; derivation is interpretive and externally testable
full rationale
The paper's chain consists of an empirical observation (activation drift under MSJ), an interpretive analogy (ICL as implicit SGD-style updates on harmful samples), and a proposed intervention (one-shot safety demo to counteract). No equations, fitted parameters, or self-citations are shown that reduce the defense or the 'equivalence' claim to a tautology or construction from the inputs. The method is presented as a concrete, parameter-free inference-time fix whose effectiveness is directly measurable on held-out harmful sets and models, satisfying the criteria for independent content. The interpretive step does not constitute a load-bearing self-definition or fitted prediction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Conditioning on N harmful demonstrations induces updates equivalent to SGD on the corresponding N harmful samples
- domain assumption Activation drift away from the safety region is the dominant reason MSJ succeeds
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
conditioning on N harmful demonstrations induces SGD-style updates equivalent to optimizing on the corresponding N harmful samples... append a fixed one-shot safety demonstration... induces a counteracting safety-oriented update
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
progressive activation drift... first-order expansion... Z^*(x;θ) := Z(x; θ − η/N ∑ ∇_θ L)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
What learning algorithm is in-context learning? investigations with linear models
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models.arXiv preprint arXiv:2211.15661, 2022
-
[3]
Many-shot jailbreaking.Advances in Neural Information Processing Systems, 37:129696–129742, 2024
Cem Anil, Esin Durmus, Nina Panickssery, Mrinank Sharma, Joe Benton, Sandipan Kundu, Joshua Batson, Meg Tong, Jesse Mu, Daniel Ford, et al. Many-shot jailbreaking.Advances in Neural Information Processing Systems, 37:129696–129742, 2024
work page 2024
-
[4]
Anthropic. Claude 3.5 sonnet. https://www.anthropic.com/news/ claude-3-5-sonnet, 2024
work page 2024
-
[5]
Longbench v2: Towards deeper understanding and reason- ing on realistic long-context multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, et al. Longbench v2: Towards deeper understanding and reason- ing on realistic long-context multitasks. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 3639–3664, 2025
work page 2025
-
[6]
Blake Bullwinkel, Mark Russinovich, Ahmed Salem, Santiago Zanella-Beguelin, Daniel Jones, Giorgio Severi, Eugenia Kim, Keegan Hines, Amanda Minnich, Yonatan Zunger, et al. A representation engineering perspective on the effectiveness of multi-turn jailbreaks.arXiv preprint arXiv:2507.02956, 2025
-
[7]
Jailbreaking black box large language models in twenty queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23–42. IEEE, 2025
work page 2025
-
[8]
Assessing safety risks and quantization-aware safety patching for quantized large language models
Kejia Chen, Jiawen Zhang, Jiacong Hu, Yu Wang, Jian Lou, Zunlei Feng, and Mingli Song. Assessing safety risks and quantization-aware safety patching for quantized large language models. InF orty-second International Conference on Machine Learning, 2025
work page 2025
-
[9]
Secalign: Defending against prompt injection with preference optimization
Sizhe Chen, Arman Zharmagambetov, Saeed Mahloujifar, Kamalika Chaudhuri, David Wagner, and Chuan Guo. Secalign: Defending against prompt injection with preference optimization. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 2833–2847, 2025
work page 2025
-
[10]
Demystifying the slash pattern in attention: The role of rope.arXiv preprint arXiv:2601.08297, 2026
Yuan Cheng, Fengzhuo Zhang, Yunlong Hou, Cunxiao Du, Chao Du, Tianyu Pang, Aixin Sun, and Zhuoran Yang. Demystifying the slash pattern in attention: The role of rope.arXiv preprint arXiv:2601.08297, 2026
-
[11]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Why can gpt learn in-context? language models secretly perform gradient descent as meta-optimizers
Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, and Furu Wei. Why can gpt learn in-context? language models secretly perform gradient descent as meta-optimizers. In Findings of the Association for Computational Linguistics: ACL 2023, pages 4005–4019, 2023
work page 2023
-
[14]
Benoit Dherin, Michael Munn, Hanna Mazzawi, Michael Wunder, and Javier Gonzalvo. Learning without training: The implicit dynamics of in-context learning.arXiv preprint arXiv:2507.16003, 2025
-
[15]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024. 10
work page 2024
-
[16]
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy S Liang, and Tatsunori B Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback.Advances in Neural Information Processing Systems, 36:30039–30069, 2023
work page 2023
-
[17]
Mingqian Feng, Xiaodong Liu, Weiwei Yang, Jialin Song, Xuekai Zhu, Chenliang Xu, and Jianfeng Gao. Sema: Simple yet effective learning for multi-turn jailbreak attacks.arXiv preprint arXiv:2602.06854, 2026
-
[18]
Lang Gao, Jiahui Geng, Xiangliang Zhang, Preslav Nakov, and Xiuying Chen. Shaping the safety boundaries: Understanding and defending against jailbreaks in large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 25378–25398, 2025
work page 2025
-
[19]
Weiyang Guo, Jing Li, Wenya Wang, Yu Li, Daojing He, Jun Yu, and Min Zhang. Mtsa: Multi-turn safety alignment for llms through multi-round red-teaming.arXiv preprint arXiv:2505.17147, 2025
-
[20]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[21]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping-yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. Baseline de- fenses for adversarial attacks against aligned language models.arXiv preprint arXiv:2309.00614, 2023
work page internal anchor Pith review arXiv 2023
-
[23]
Red queen: Exposing latent multi-turn risks in large language models
Yifan Jiang, Kriti Aggarwal, Tanmay Laud, Kashif Munir, Jay Pujara, and Subhabrata Mukher- jee. Red queen: Exposing latent multi-turn risks in large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 25554–25591, 2025
work page 2025
-
[24]
Sangyeop Kim, Yohan Lee, Yongwoo Song, and Kimin Lee. What really matters in many- shot attacks? an empirical study of long-context vulnerabilities in llms.arXiv preprint arXiv:2505.19773, 2025
-
[25]
Break Me If You Can: Self-Jailbreaking of Aligned LLMs via Lexical Insertion Prompting
Devang Kulshreshtha, Hang Su, Chinmay Hegde, and Haohan Wang. Multi-turn jailbreaking of aligned llms via lexical anchor tree search.arXiv preprint arXiv:2601.02670, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Songze Li, Ruishi He, Xiaojun Jia, Jun Wang, and Zhihui Fu. Knowledge-driven multi-turn jailbreaking on large language models.arXiv preprint arXiv:2601.05445, 2026
-
[27]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Avery Ma, Yangchen Pan, and Amir-massoud Farahmand. Pandas: Improving many-shot jailbreaking via positive affirmation, negative demonstration, and adaptive sampling.arXiv preprint arXiv:2502.01925, 2025
-
[29]
Harmbench: a standardized evaluation frame- work for automated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: a standardized evaluation frame- work for automated red teaming and robust refusal. InProceedings of the 41st International Conference on Machine Learning, pages 35181–35224, 2024
work page 2024
-
[30]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022. 11
work page 2022
-
[31]
Salman Rahman, Liwei Jiang, James Shiffer, Genglin Liu, Sheriff Issaka, Md Rizwan Parvez, Hamid Palangi, Kai-Wei Chang, Yejin Choi, and Saadia Gabriel. X-teaming: Multi-turn jailbreaks and defenses with adaptive multi-agents.arXiv preprint arXiv:2504.13203, 2025
-
[32]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
work page 2024
-
[33]
Derail yourself: Multi-turn llm jailbreak attack through self- discovered clues
Qibing Ren, Hao Li, Dongrui Liu, Zhanxu Xie, Xiaoya Lu, Yu Qiao, Lei Sha, Junchi Yan, Lizhuang Ma, and Jing Shao. Derail yourself: Multi-turn llm jailbreak attack through self- discovered clues. 2024
work page 2024
-
[34]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers)...
work page 2024
-
[35]
Great, now write an article about that: The crescendo {Multi-Turn}{LLM} jailbreak attack
Mark Russinovich, Ahmed Salem, and Ronen Eldan. Great, now write an article about that: The crescendo {Multi-Turn}{LLM} jailbreak attack. In34th USENIX Security Symposium (USENIX Security 25), pages 2421–2440, 2025
work page 2025
- [36]
-
[37]
Jailbreaking in the haystack.arXiv preprint arXiv:2511.04707, 2025
Rishi Rajesh Shah, Chen Henry Wu, Shashwat Saxena, Ziqian Zhong, Alexander Robey, and Aditi Raghunathan. Jailbreaking in the haystack.arXiv preprint arXiv:2511.04707, 2025
-
[38]
Kartik Sharma and Rakshit S Trivedi. Cold-steer: Steering large language models via in-context one-step learning dynamics.arXiv preprint arXiv:2603.06495, 2026
-
[39]
Lingfeng Shen, Aayush Mishra, and Daniel Khashabi. Do pretrained transformers learn in- context by gradient descent?arXiv preprint arXiv:2310.08540, 2023
-
[40]
Navigating the overkill in large language models
Chenyu Shi, Xiao Wang, Qiming Ge, Songyang Gao, Xianjun Yang, Tao Gui, Qi Zhang, Xuan-Jing Huang, Xun Zhao, and Dahua Lin. Navigating the overkill in large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 4602–4614, 2024
work page 2024
-
[41]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Transformers learn in-context by gradient descent
Johannes V on Oswald, Eyvind Niklasson, Ettore Randazzo, João Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. InInternational Conference on Machine Learning, pages 35151–35174. PMLR, 2023
work page 2023
-
[43]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training llms to prioritize privileged instructions.arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review arXiv 2024
-
[44]
Leave no document behind: Benchmarking long-context llms with extended multi-doc qa
Minzheng Wang, Longze Chen, Fu Cheng, Shengyi Liao, Xinghua Zhang, Bingli Wu, Haiyang Yu, Nan Xu, Lei Zhang, Run Luo, et al. Leave no document behind: Benchmarking long-context llms with extended multi-doc qa. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5627–5646, 2024
work page 2024
-
[45]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024. 12
work page 2024
-
[46]
Zeming Wei, Yifei Wang, Ang Li, Yichuan Mo, and Yisen Wang. Jailbreak and guard aligned language models with only few in-context demonstrations.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
work page 2026
-
[47]
Foot-in-the-door: A multi-turn jailbreak for llms
Zixuan Weng, Xiaolong Jin, Jinyuan Jia, and Xiangyu Zhang. Foot-in-the-door: A multi-turn jailbreak for llms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1939–1950, 2025
work page 2025
-
[48]
Internal safety collapse in frontier large language models.arXiv preprint arXiv:2603.23509, 2026
Yutao Wu, Xiao Liu, Yifeng Gao, Xiang Zheng, Hanxun Huang, Yige Li, Cong Wang, Bo Li, Xingjun Ma, and Yu-Gang Jiang. Internal safety collapse in frontier large language models. arXiv preprint arXiv:2603.23509, 2026
-
[49]
Chen Xiong, Xiangyu Qi, Pin-Yu Chen, and Tsung-Yi Ho. Defensive prompt patch: A robust and generalizable defense of large language models against jailbreak attacks. InFindings of the Association for Computational Linguistics: ACL 2025, pages 409–437, 2025
work page 2025
-
[50]
Siyu Yan, Long Zeng, Xuecheng Wu, Chengcheng Han, Kongcheng Zhang, Chong Peng, Xuezhi Cao, Xunliang Cai, and Chenjuan Guo. Muse: Mcts-driven red teaming framework for enhanced multi-turn dialogue safety in large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21293–21314, 2025
work page 2025
-
[51]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Many-turn jailbreaking.arXiv preprint arXiv:2508.06755, 2025
Xianjun Yang, Liqiang Xiao, Shiyang Li, Faisal Ladhak, Hyokun Yun, Linda Ruth Petzold, Yi Xu, and William Yang Wang. Many-turn jailbreaking.arXiv preprint arXiv:2508.06755, 2025
-
[53]
Jiawen Zhang, Kejia Chen, Lipeng He, Jian Lou, Dan Li, Zunlei Feng, Mingli Song, Jian Liu, Kui Ren, and Xiaohu Yang. Activation approximations can incur safety vulnerabilities in aligned {LLMs}: Comprehensive analysis and defense. In34th USENIX Security Symposium (USENIX Security 25), pages 339–358, 2025
work page 2025
-
[54]
Jiawen Zhang, Lipeng He, Kejia Chen, Jian Lou, Jian Liu, Xiaohu Yang, and Ruoxi Jia. Safety at one shot: Patching fine-tuned llms with a single instance.arXiv preprint arXiv:2601.01887, 2026
-
[55]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
work page 2023
-
[56]
Weixiong Zheng, Peijian Zeng, Yiwei Li, Hongyan Wu, Nankai Lin, Junhao Chen, Aimin Yang, and Yongmei Zhou. Jailbreaking? one step is enough! InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 11623–11642, 2025
work page 2025
-
[57]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. 13 Limitations Our analysis focuses on many-shot jailbreaking, where harmful demonstrations are explicitly provided in the context. This setting is importan...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.