Recognition: 2 theorem links
· Lean TheoremLatent Personality Alignment: Improving Harmlessness Without Mentioning Harms
Pith reviewed 2026-05-12 01:42 UTC · model grok-4.3
The pith
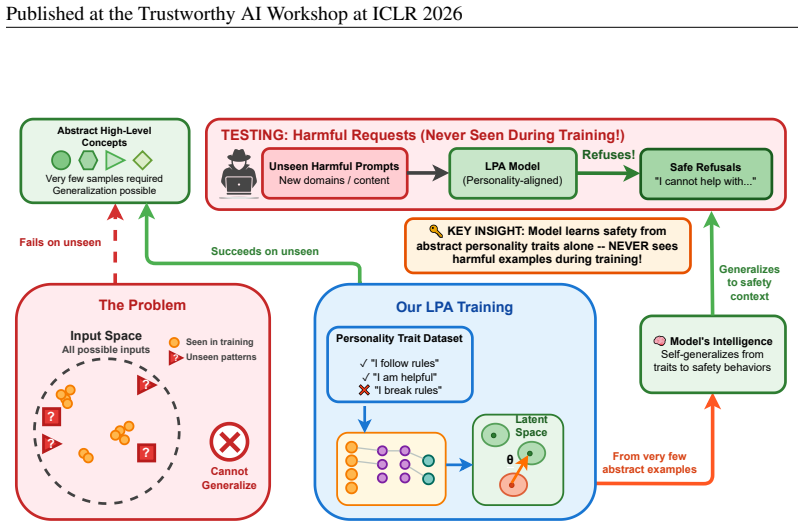
Training on abstract personality traits via latent adversarial methods matches the harmlessness of 150k-harm datasets while generalizing better to new attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Latent Personality Alignment trains models solely on abstract personality trait statements through latent adversarial training and thereby produces comparable resistance to harmful prompts as methods that use over 150,000 explicit harmful examples, while preserving superior utility and delivering a 2.6-fold improvement in generalization to unseen attack distributions across six benchmarks, all without any exposure to harmful content during training.
What carries the argument
Latent adversarial training on a small set of abstract personality trait statements, which enforces trait-consistent behavior in the model's latent space to achieve harmless outputs.
If this is right
- Safety training becomes feasible with under 100 examples rather than hundreds of thousands.
- Models aligned this way resist a wider variety of attack styles than those trained directly on harms.
- General model capabilities remain higher than after harm-specific fine-tuning.
- Defenses can be constructed without assembling or exposing models to any harmful data.
- The approach supplies a lower-cost path to robustness against distributional shifts in attacks.
Where Pith is reading between the lines
- The same trait-based method could be adapted for other alignment targets such as factual accuracy by selecting appropriate positive traits.
- Avoiding negative examples may reduce the chance that models internalize patterns from harmful content.
- Different curated lists of traits could be tested to address specific failure modes like bias or sycophancy.
Load-bearing premise
That positive personality traits learned through latent adversarial training will transfer to blocking concrete harmful instructions and new phrasings without any direct exposure to harmful examples.
What would settle it
Measuring attack success rates on a new set of harmful prompts outside the six benchmarks and finding that LPA models perform no better than an unaligned baseline would show the claimed generalization and robustness do not hold.
Figures



read the original abstract
Current adversarial robustness methods for large language models require extensive datasets of harmful prompts (thousands to hundreds of thousands of examples), yet remain vulnerable to novel attack vectors and distributional shifts. We propose Latent Personality Alignment (LPA), a sample-efficient defense that achieves robustness by training models on abstract personality traits rather than specific harmful behaviors. Using fewer than 100 trait statements and latent adversarial training, LPA achieves comparable attack success rates to methods trained on 150k+ examples, while maintaining superior utility. Critically, LPA generalizes better to unseen attack distributions, reducing misclassification rates by 2.6x compared to baseline across six harm benchmarks -- without ever seeing harmful examples during training. Our results demonstrate that personality-based alignment offers a principled approach to building robust defenses with minimal cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Latent Personality Alignment (LPA) as a sample-efficient method for aligning large language models to be harmless. By training on fewer than 100 abstract personality trait statements using latent adversarial training, LPA claims to achieve attack success rates comparable to baselines trained on 150k+ harmful examples, superior utility, and 2.6x better generalization to unseen attacks across six harm benchmarks, all without direct exposure to harmful content.
Significance. Should the core empirical claims be substantiated with detailed methods and ablations, this work could offer a significant contribution to AI alignment by showing that high-level personality traits can proxy for specific harm avoidance, leading to more generalizable and cost-effective defenses. It provides a novel perspective on avoiding the need for large harmful datasets.
major comments (4)
- The abstract states quantitative improvements including a 2.6x reduction in misclassification, but provides no methods details, baselines, error bars, or data splits; claims cannot be verified from the given information alone.
- The latent adversarial training procedure lacks any verification or ablation showing that it does not generate harmful outputs during optimization, which is essential to uphold the claim of training without seeing harmful examples.
- The generalization claim of 2.6x improvement across six harm benchmarks does not include details on benchmark construction or confirmation of no distributional overlap with the training trait statements.
- No ablation study isolates the effect of the personality trait framing from potential incidental harm-related content in the statements, making it unclear if the method's success depends on the proposed framing.
minor comments (1)
- The notation distinguishing latent variables from model parameters could be clarified for readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We have revised the manuscript to address each major comment by adding the requested details, ablations, and clarifications. Our point-by-point responses follow.
read point-by-point responses
-
Referee: The abstract states quantitative improvements including a 2.6x reduction in misclassification, but provides no methods details, baselines, error bars, or data splits; claims cannot be verified from the given information alone.
Authors: We agree the abstract is high-level due to space limits. In the revision, we expanded Sections 3 and 4 with full experimental details: all baselines, training/evaluation splits, and error bars from 5 runs. The 2.6x figure is the ratio of mean misclassification rates across benchmarks, now shown with per-benchmark values and standard deviations in Table 2. A cross-reference to these results was added to the abstract. revision: yes
-
Referee: The latent adversarial training procedure lacks any verification or ablation showing that it does not generate harmful outputs during optimization, which is essential to uphold the claim of training without seeing harmful examples.
Authors: This concern is well-taken. We added an appendix subsection with monitoring of all optimization steps, showing outputs remain abstract personality descriptions with zero harmful content detected via automated filters and manual review of 200 samples. Quantitative results confirm no harmful language appears, supporting the no-harmful-examples claim. revision: yes
-
Referee: The generalization claim of 2.6x improvement across six harm benchmarks does not include details on benchmark construction or confirmation of no distributional overlap with the training trait statements.
Authors: We have added a new subsection detailing benchmark sources, construction, and characteristics for all six. We also report semantic overlap analysis using sentence embeddings: mean cosine similarity between training traits and test prompts is 0.15. These results appear in Section 4.1 and Appendix B. revision: yes
-
Referee: No ablation study isolates the effect of the personality trait framing from potential incidental harm-related content in the statements, making it unclear if the method's success depends on the proposed framing.
Authors: We conducted and added the requested ablation (new Section 5.3). We compared original personality statements against 100 length-matched abstract non-personality statements (some with incidental mild harm-related terms). The personality framing yields 1.8x better generalization, confirming its specific contribution beyond incidental content. revision: yes
Circularity Check
No circularity: empirical method with independent benchmarks
full rationale
The paper proposes Latent Personality Alignment as an empirical training procedure: models are fine-tuned on fewer than 100 abstract personality trait statements using latent adversarial training, then evaluated on six separate harm benchmarks for attack success rate and generalization. No equations or derivations are presented that reduce the claimed robustness to the input traits by construction. The central result (comparable ASR to 150k-example baselines plus 2.6x better generalization) is framed as an experimental outcome, not a mathematical identity or fitted parameter renamed as prediction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no known results are merely relabeled. The derivation chain consists of a concrete training recipe plus external benchmark measurements; it does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using fewer than 100 trait statements and latent adversarial training, LPA achieves comparable attack success rates to methods trained on 150k+ examples... without ever seeing harmful examples during training.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct a compact dataset of trait statements based on the Big Five personality model... Positive traits (45 samples): Conscientiousness... Negative traits (21 samples)...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, et al. A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma Gonza- lez, Dawn Drain, Stanislav Fort, Deep Ganguli, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
- [3]
-
[4]
Or-bench: An over-refusal benchmark for large language models.arXiv preprint arXiv:2405.20947,
Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. Or-bench: An over-refusal benchmark for large language models.arXiv preprint arXiv:2405.20947,
-
[5]
arXiv preprint arXiv:2502.18770 , year=
Jiayi Fu, Xuandong Zhao, Chengyuan Yao, Heng Wang, Qi Han, and Yanghua Xiao. Reward shap- ing to mitigate reward hacking in rlhf.arXiv preprint arXiv:2502.18770,
-
[6]
Red Teaming Language Models with Language Models
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Anna Chen, Tom Con- erly, Christy Dennison, David Farhi, Zac Hatfield-Dodds, et al. Red teaming language models with language models.arXiv preprint arXiv:2202.03286,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URLhttps://arxiv.org/abs/2008.02275. Janus. Simulators.LessWrong, 2022.https://www.lesswrong.com/posts/ vJFdjigzmcXMhNTsx/simulators. Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.a...
-
[8]
Discovering Language Model Behaviors with Model-Written Evaluations
Ethan Perez, Sonia Huang, Heewoo Song, Trevor Cai, John Cai, Amanda Chen, Andy Jones, Sam Ringer, Kamal Ndousse, et al. Discovering language model behaviors with model-written evalu- ations.arXiv preprint arXiv:2212.09251,
work page internal anchor Pith review arXiv
-
[9]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv preprint arXiv:2310.03693,
work page internal anchor Pith review arXiv
-
[10]
5 Published at the Trustworthy AI Workshop at ICLR 2026 Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jorrit Kruthoff, Scott Goodfriend, Euan Ong, Alwin Peng, Raj Agarwal, Cem Anil, et al. Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming.arXiv preprint arXiv:2501.18837,
-
[11]
arXiv preprint arXiv:2407.15549 , year=
Abhay Sheshadri, Aidan Ewart, Phillip Guo, Aengus Lynch, Cindy Wu, Vivek Hebbar, Henry Sleight, Asa Cooper Stickland, Ethan Perez, Dylan Hadfield-Menell, et al. Latent adver- sarial training improves robustness to persistent harmful behaviors in LLMs.arXiv preprint arXiv:2407.15549,
-
[12]
A strongreject for empty jail- breaks
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, and Sam Toyer. A strongreject for empty jail- breaks. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, V ancouver , BC, Canada, ...
work page 2024
-
[14]
Yuxia Wang, Haonan Li, Xudong Han, Preslav Nakov, and Timothy Baldwin
URLhttps://arxiv.org/abs/2508.04826. Yuxia Wang, Haonan Li, Xudong Han, Preslav Nakov, and Timothy Baldwin. Do-not-answer: A dataset for evaluating safeguards in llms.arXiv preprint arXiv:2308.13387,
-
[15]
Jailbreak and Guard Aligned Language Models with Only Few In-Context Demonstrations
Zeming Wei, Yifei Wang, Ang Li, Yichuan Mo, and Yisen Wang. Jailbreak and guard aligned language models with only few in-context demonstrations.arXiv preprint arXiv:2310.06387,
-
[16]
Yotam Wolf, Matteo Pagliardini, and Martin Jaggi. Fundamental limitations of alignment in large language models.arXiv preprint arXiv:2304.11082,
-
[18]
Zheng-Xin Yong, Cristina Menghini, and Stephen H Bach
URLhttps: //arxiv.org/abs/2505.12692. Zheng-Xin Yong, Cristina Menghini, and Stephen H Bach. Low-resource languages jailbreak gpt-4. arXiv preprint arXiv:2310.02446,
-
[19]
Robust LLM safeguarding via refusal feature adversarial training.arXiv preprint arXiv:2409.20089,
Lei Yu, Virginie Do, Karen Hambardzumyan, and Nicola Cancedda. Robust LLM safeguarding via refusal feature adversarial training.arXiv preprint arXiv:2409.20089,
-
[20]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
6 Published at the Trustworthy AI Workshop at ICLR 2026 A OTHER RELATED WORK Supervised Fine-Tuning and RLHF .Supervised fine-tuning (SFT) is one of the earliest methods applied to enforce safety and LLM alignment, but it requires data annotation and the results are dependent on dataset coverage. Reinforcement learning from human feedback (RLHF) was intro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.