Recognition: 2 theorem links
· Lean TheoremIterative Critique-and-Routing Controller for Multi-Agent Systems with Heterogeneous LLMs
Pith reviewed 2026-05-12 01:05 UTC · model grok-4.3
The pith
The critique-and-routing controller models multi-agent LLM coordination as a finite-horizon MDP and optimizes it via policy gradients to enable iterative refinement that outperforms one-shot routing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
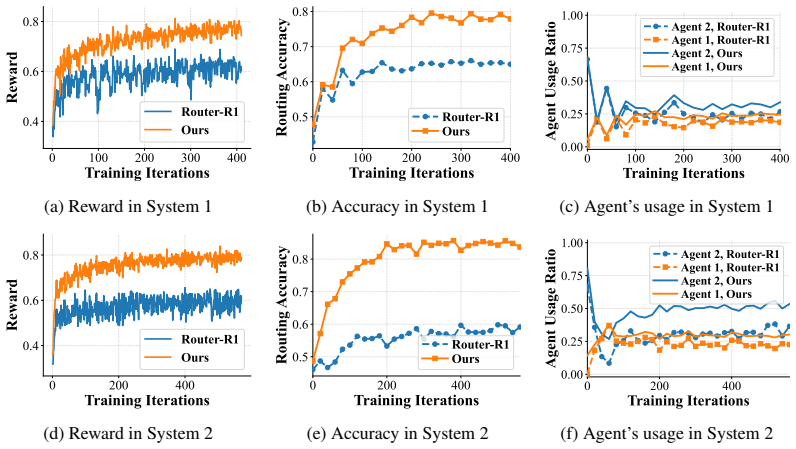
The central claim is that formulating the controller's per-turn choices—evaluate the current draft, stop or continue, and select the next agent—as a finite-horizon MDP with explicit utilization constraints, a composite reward across turns, and policy-gradient optimization under a Lagrangian-relaxed objective yields a policy that consistently outperforms one-shot baselines, narrows the gap to the strongest agent, and achieves this with under 25 percent usage of that agent across heterogeneous multi-agent setups and reasoning benchmarks.
What carries the argument
The critique-and-routing controller formulated as a finite-horizon Markov Decision Process with agent-utilization constraints and a composite reward, optimized by policy gradients under Lagrangian relaxation.
If this is right
- The controller outperforms state-of-the-art one-shot routing baselines across seven reasoning benchmarks.
- It substantially narrows the performance gap to the strongest agent in the pool.
- The strongest agent is invoked for fewer than 25 percent of total calls.
- The approach works across multiple heterogeneous multi-agent systems.
- Sequential decisions support iterative refinement of intermediate drafts rather than single-shot outputs.
Where Pith is reading between the lines
- The sequential MDP framing could be extended to other orchestration tasks where intermediate quality checks matter, such as code generation or multi-step planning.
- Explicit constraints on agent usage during training may prove more effective than post-hoc filtering for controlling inference costs in production deployments.
- The composite reward structure points to a general way to encode quality-cost tradeoffs that other LLM routing methods could adopt.
- Testing generalization when the agent pool changes dynamically would clarify how robust the learned policy remains outside fixed training conditions.
Load-bearing premise
The MDP formulation, composite reward, and Lagrangian-relaxed policy-gradient optimization produce decisions that generalize across benchmarks and agent pools without bias introduced by the reward design or constraint handling.
What would settle it
A new experiment on an unseen reasoning benchmark or different LLM pool in which the controller shows no outperformance over one-shot baselines or requires the strongest agent in more than 25 percent of calls would falsify the performance claims.
Figures




read the original abstract
Multi-agent large language model (LLM) systems often rely on a controller to coordinate a pool of heterogeneous models, yet existing controllers are typically limited to one-shot routing: they select a model once and return its output directly. Such routing-only designs provide no mechanism to critique intermediate drafts or support iterative refinement. To address this limitation, we propose a critique-and-routing controller that casts multi-agent coordination as a sequential decision problem. At each turn, the controller evaluates the current draft, decides whether to stop or continue, and, if needed, selects the next agent for further refinement. We formulate this process as a finite-horizon Markov Decision Process (MDP) with explicit agent-utilization constraints, design a composite reward for controller decisions across turns, and optimize the controller via policy gradients under a Lagrangian-relaxed objective. Extensive experiments across multiple heterogeneous multi-agent systems and seven reasoning benchmarks show that our method consistently outperforms state-of-the-art baselines and substantially narrows the gap to the strongest agent, while using it for fewer than 25% of total calls.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an iterative critique-and-routing controller for multi-agent systems with heterogeneous LLMs. It formulates coordination as a finite-horizon MDP with explicit agent-utilization constraints, designs a composite reward function, and optimizes the controller via policy gradients under Lagrangian relaxation. Experiments across multiple heterogeneous multi-agent setups and seven reasoning benchmarks show consistent outperformance over state-of-the-art baselines, narrowing the gap to the strongest agent while invoking it for fewer than 25% of total calls.
Significance. If the empirical results hold, the work offers a practical mechanism for iterative refinement and efficient routing in LLM multi-agent systems, reducing reliance on the strongest (often costliest) models. A notable strength is the prompt-based implementation with zero additional parameters, where the LLM approximates the policy and composite rewards/constraints are enforced at inference time rather than via gradient updates; this sidesteps training instability. The inclusion of reward-component ablations and cross-benchmark generalization checks further supports the claims.
major comments (1)
- [Abstract and Methods] Abstract and Methods: The abstract claims the controller is optimized 'via policy gradients under a Lagrangian-relaxed objective,' yet the methods describe a zero-parameter prompt-based controller that approximates the policy directly with the LLM and enforces the composite reward plus constraints at inference time without any gradient-based parameter updates. This mismatch is load-bearing for the central methodological claim and requires explicit reconciliation (e.g., clarifying that the MDP is a conceptual model rather than a trained policy).
minor comments (2)
- [§4] §4 (Experiments): The description of baseline implementations could be expanded to include exact prompt templates and hyperparameter settings used for fair comparison.
- [Table 1 and Figure 3] Table 1 and Figure 3: Axis labels and legend entries should explicitly state the metric (e.g., accuracy vs. cost) and the exact fraction of calls to the strongest agent to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The feedback highlights an important point of potential confusion in how the methodological contribution is presented. We address the major comment below and will revise the manuscript to resolve the inconsistency.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods: The abstract claims the controller is optimized 'via policy gradients under a Lagrangian-relaxed objective,' yet the methods describe a zero-parameter prompt-based controller that approximates the policy directly with the LLM and enforces the composite reward plus constraints at inference time without any gradient-based parameter updates. This mismatch is load-bearing for the central methodological claim and requires explicit reconciliation (e.g., clarifying that the MDP is a conceptual model rather than a trained policy).
Authors: We agree that the current wording in the abstract creates a misleading impression. The finite-horizon MDP formulation is used strictly as a conceptual model to derive the structure of the composite reward function and the explicit agent-utilization constraints. In the actual implementation, the controller is realized as a zero-parameter, prompt-based system: the LLM directly approximates the policy by generating decisions at inference time, while the reward components and constraints are enforced through carefully designed prompts rather than through any gradient-based optimization or Lagrangian relaxation during training. No policy-gradient updates or parameter optimization occur. We will revise the abstract (and the opening of the Methods section) to explicitly state that the MDP serves as a design framework rather than a trained policy, and that the controller is implemented via prompting without gradient-based training. This change will be incorporated in the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper formulates multi-agent coordination as a finite-horizon MDP with agent-utilization constraints and a composite reward, then implements the controller as a prompt-based LLM policy (zero trainable parameters) that enforces the reward and constraints directly at inference time. This approach does not involve fitting parameters to the evaluation benchmarks or renaming fitted quantities as predictions; the reported outperformance is measured on held-out reasoning tasks with explicit ablations and cross-benchmark checks. No load-bearing step reduces by construction to the inputs via self-definition, self-citation chains, or ansatz smuggling. The central claim therefore rests on independent empirical evidence rather than tautological equivalence.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate this process as a finite-horizon Markov Decision Process (MDP) with explicit agent-utilization constraints, design a composite reward for controller decisions across turns, and optimize the controller via policy gradients under a Lagrangian-relaxed objective.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
rt := R(st,at) = 0.5 Rr(st,at) + 0.5 Rv(st,at)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Lingjiao Chen, Matei Zaharia, and James Zou. Frugalgpt: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Shuhao Chen, Weisen Jiang, Baijiong Lin, James Kwok, and Yu Zhang. Routerdc: Query-based router by dual contrastive learning for assembling large language models.Advances in Neural Information Processing Systems, 37:66305–66328, 2024
work page 2024
-
[3]
Hybrid LLM: Cost-efficient and quality-aware query routing
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks VS Lakshmanan, and Ahmed Hassan Awadallah. Hybrid llm: Cost-efficient and quality- aware query routing.arXiv preprint arXiv:2404.14618, 2024
-
[4]
Aurélien Garivier and Eric Moulines
Dujian Ding, Ankur Mallick, Shaokun Zhang, Chi Wang, Daniel Madrigal, Mirian Del Car- men Hipolito Garcia, Menglin Xia, Laks VS Lakshmanan, Qingyun Wu, and Victor R¨uhle. Best- route: Adaptive llm routing with test-time optimal compute.arXiv preprint arXiv:2506.22716, 2025
-
[5]
Andrew Estornell, Jean-Francois Ton, Yuanshun Yao, and Yang Liu. Acc-collab: An actor-critic approach to multi-agent llm collaboration.arXiv preprint arXiv:2411.00053, 2024
-
[6]
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, et al. Omni-math: A universal olympiad level mathematic benchmark for large language models.arXiv preprint arXiv:2410.07985, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
work page 2021
-
[9]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[10]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jia- jun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
arXiv preprint arXiv:2511.02755 , year =
Bowen Jin, TJ Collins, Donghan Yu, Mert Cemri, Shenao Zhang, Mengyu Li, Jay Tang, Tian Qin, Zhiyang Xu, Jiarui Lu, et al. Controlling performance and budget of a centralized multi-agent llm system with reinforcement learning.arXiv preprint arXiv:2511.02755, 2025
-
[12]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 2022
work page 2022
-
[14]
arXiv preprint arXiv:2410.02189 , year=
Ao Li, Yuexiang Xie, Songze Li, Fugee Tsung, Bolin Ding, and Yaliang Li. Agent-oriented planning in multi-agent systems.arXiv preprint arXiv:2410.02189, 2024
-
[15]
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for” mind” exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023. 10
work page 2023
-
[16]
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
work page 2024
-
[17]
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024
work page 2024
-
[18]
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models. arXiv preprint arXiv:2505.24864, 2025
-
[19]
Routing to the expert: Efficient reward-guided ensemble of large language models
Keming Lu, Hongyi Yuan, Runji Lin, Junyang Lin, Zheng Yuan, Chang Zhou, and Jingren Zhou. Routing to the expert: Efficient reward-guided ensemble of large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1964–1974, 2024
work page 2024
-
[20]
Kai Mei, Wujiang Xu, Minghao Guo, Shuhang Lin, and Yongfeng Zhang. Omnirouter: Budget and performance controllable multi-llm routing.ACM SIGKDD Explorations Newsletter, 27(2):107–116, 2025
work page 2025
-
[21]
Malt: Improving reasoning with multi-agent llm training.arXiv preprint arXiv:2412.01928, 2024
Sumeet Ramesh Motwani, Chandler Smith, Rocktim Jyoti Das, Rafael Rafailov, Ivan Laptev, Philip HS Torr, Fabio Pizzati, Ronald Clark, and Christian Schroeder de Witt. Malt: Improving reasoning with multi-agent llm training.arXiv preprint arXiv:2412.01928, 2024
-
[22]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E Gonzalez, M Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data. arXiv preprint arXiv:2406.18665, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Online multi-llm selection via contextual bandits under unstructured context evolution
Manhin Poon, XiangXiang Dai, Xutong Liu, Fang Kong, John CS Lui, and Jinhang Zuo. Online multi-llm selection via contextual bandits under unstructured context evolution. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 24855–24863, 2026
work page 2026
-
[24]
Martin L Puterman.Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 2014
work page 2014
-
[25]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174–15186, 2024
work page 2024
-
[26]
Sumedh Rasal and Evi J Hauer. Navigating complexity: Orchestrated problem solving with multi-agent llms.arXiv preprint arXiv:2402.16713, 2024
-
[27]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
work page 2015
-
[28]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Chenyang Shao, Xinyang Liu, Yutang Lin, Fengli Xu, and Yong Li. Route-and-reason: Scaling large language model reasoning with reinforced model router.arXiv preprint arXiv:2506.05901, 2025
-
[30]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025. 11
work page 2025
-
[32]
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction. MIT press Cambridge, 1998
work page 1998
-
[33]
Yashar Talebirad and Amirhossein Nadiri. Multi-agent collaboration: Harnessing the power of intelligent llm agents.arXiv preprint arXiv:2306.03314, 2023
-
[34]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
work page 2024
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning
Haozhen Zhang, Tao Feng, and Jiaxuan You. Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[37]
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. Agieval: A human-centric benchmark for evaluating foundation models. InFindings of the association for computational linguistics: NAACL 2024, pages 2299–2314, 2024. 12 Appendix A Further Experiments 14 A.1 Other Controller Choices . . . . . . ...
work page 2024
-
[38]
Calculate the slope using the points (2, -5) and (p, -14): slope= −14−(−5) p−2 = −9 p−2
-
[39]
Calculate the slope using the points (2, -5) and (p+2, -17): slope= −17−(−5) (p+ 2)−2 = −12 p
-
[40]
Set the slopes equal to each other and solve forp: −9 p−2 = −12 p Cross-multiplying gives: −9p=−12(p−2) −9p=−12p+ 24 3p= 24 p= 8
-
[41]
Verify the equation of the line using the point (2, -5) and the slope− 3 2 : y+ 5 =− 3 2 (x−2) y=− 3 2 x+ 3−5 y=− 3 2 x−2
-
[42]
Find the value ofqwhenx= 13: q=− 3 2 (13)−2 =− 39 2 −2 =− 39 2 − 4 2 =− 43 2 =−21.5
-
[43]
Turn 1 (Controller): <thinking>This is a simple problem involving rationalizing the denominator
Calculatep+q: p+q= 8 + (−21.5) =−13.5 </checking> <verdict>True</verdict> Example 2: Exit in 3 Turns Question:Rationalize the denominator: 1 2 √ 7 . Turn 1 (Controller): <thinking>This is a simple problem involving rationalizing the denominator. It is a basic algebraic manipulation problem that does not require advanced mathematical knowledge or complex p...
-
[45]
To rationalize the denominator, we multiply the numerator and the denominator by2 √ 7
-
[46]
This gives us 2 √ 7 2 √ 7·2 √ 7 = √ 7 2·7 = √ 7 14
-
[47]
We need to route the problem to a stronger agent to refine the solution
The proposed solution seems to have an error in step 4. We need to route the problem to a stronger agent to refine the solution. Qwen2.5-7B-Instruct is good choice, which is stronger than Qwen2.5-1.5B-Instruct. </checking> <verdict>False</verdict> <model>Qwen2.5-7B-Instruct</model> Response from Qwen2.5-7B-Instruct:To rationalize the denominator of the ex...
-
[48]
The given expression is 1 2 √ 7
-
[49]
To rationalize the denominator, we multiply the numerator and the denominator by √ 7
-
[50]
This gives us √ 7 2 √ 7· √ 7 = √ 7 2·7 = √ 7 14
-
[51]
</checking> <verdict>True</verdict> 24
The proposed solution is correct. </checking> <verdict>True</verdict> 24
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.