Recognition: 1 theorem link
· Lean TheoremControl Your View: High-Resolution Global Semantic Manipulation in Learned Image Compression
Pith reviewed 2026-05-12 02:34 UTC · model grok-4.3
The pith
A periodic geometric decay step-size schedule enables the first stable high-resolution global semantic manipulation in learned image compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
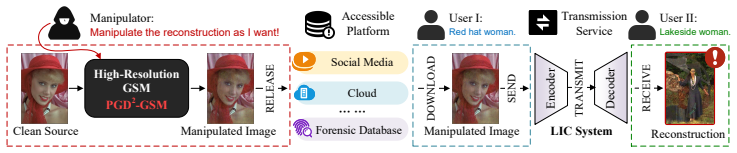
The authors show that well-performing global semantic manipulation requires adversarial examples to pass through Lazying-Oscillating-Refining stages, and that standard ℓ∞-bounded attacks fail because their step-size schedules cannot accommodate both the Oscillating and Refining stages. They therefore introduce a Periodic Geometric Decay schedule, integrate it with projected gradient descent to obtain the minimal variant PGD²-GSM, and demonstrate on Kodak images of size 3×768×512 that this variant is the first to achieve stable high-resolution global semantic manipulation, exposing a previously inaccessible threat to learned image compression systems.
What carries the argument
The Periodic Geometric Decay schedule for step sizes, which allows the attack to traverse the Lazying-Oscillating-Refining stages as examples move from the Identity Region to the Amplification Region.
If this is right
- High-resolution global semantic manipulation becomes achievable under white-box ℓ∞ constraints for learned image compression.
- Standard projected gradient descent cannot reach stable high-resolution GSM without the new step-size schedule.
- The threat applies to practical resolutions such as 768×512 and is not limited to low-resolution or local manipulations.
- Learned compression systems now face an explicit attack vector that alters entire-image semantics while remaining bounded in perturbation size.
- The minimal PGD²-GSM variant demonstrates that only the schedule change is needed to cross the previous barrier.
Where Pith is reading between the lines
- Defenses for learned compression may need to incorporate training procedures that explicitly penalize trajectories through the oscillating and refining stages.
- Similar step-size mismatches could appear in other high-resolution neural tasks such as generative modeling or video compression.
- Testing PGD²-GSM on additional learned compression architectures would indicate whether the vulnerability is architecture-specific or general.
- The existence of the Amplification Region suggests that rate-distortion optimization itself might be hardened by adding constraints on latent-code sensitivity.
Load-bearing premise
The claim rests on the premise that standard attacks fail specifically because their step-size schedules cannot handle both the oscillating and refining stages at once.
What would settle it
Running ordinary PGD with fixed or linearly decaying step sizes on the same high-resolution LIC models and Kodak images to test whether global semantic manipulation remains impossible, or verifying whether PGD²-GSM itself loses stability when the periodic decay is removed.
Figures











read the original abstract
Learned image compression (LIC) integrates deep neural networks (DNNs) to map high-dimensional images into compact latent representations, reducing redundancy and achieving superior rate-distortion (RD) performance in benign settings. Unfortunately, due to inherent vulnerabilities in DNNs, LIC systems are susceptible to adversarial perturbations that lead to downstream deterioration, compression rate degradation, untargeted distortion, and both local semantic manipulation (LSM) and low-resolution ($3\times28\times28$) global semantic manipulation (GSM). However, high-resolution GSM remains unexplored due to its intractability. Notably, the existing project gradient descent (PGD) method achieves near-perfect white-box attacks for classification, segmentation, and other tasks, yet fails to generalize to high-resolution GSM. Our theoretical and empirical analyses reveal that well-performing GSM drives adversarial examples from the Identity Region to the Amplification Region through the Lazying-Oscillating-Refining stages. General $\ell_{\infty}$-bounded attacks fail on high-resolution GSM because their step-size schedules cannot accommodate both the Oscillating and Refining stages. Based on this, we propose the Periodic Geometric Decay schedule that enables $\ell_{\infty}$-bounded high-resolution GSM. To verify our approach, we integrate it with PGD, yielding a minimal variant, PGD$^{2}$-GSM. Extensive experiments on the Kodak $(3\times768\times512)$ demonstrate that our PGD$^{2}$-GSM is the first to stably achieve high-resolution GSM, thereby exposing a novel threat to LIC systems. Code is available at https://github.com/chinaliangjiaming/PGD2-GSM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that learned image compression (LIC) systems are vulnerable to adversarial attacks enabling high-resolution global semantic manipulation (GSM), but standard ℓ∞-bounded PGD fails because its step-size schedules cannot handle the Lazying-Oscillating-Refining stages needed to drive examples from the Identity Region to the Amplification Region. The authors derive a Periodic Geometric Decay schedule from their theoretical and empirical analysis of attack dynamics, integrate it into PGD to form the minimal variant PGD²-GSM, and demonstrate that it is the first method to stably achieve high-resolution GSM on the Kodak dataset (3×768×512), thereby exposing a novel threat to LIC.
Significance. If the empirical results are reproducible and the stage-based analysis holds, the work is significant for identifying a new, high-resolution adversarial threat to LIC that goes beyond low-resolution GSM or standard distortions. The proposed schedule offers a practical, minimal modification to PGD that achieves stable manipulation where prior methods do not, and the code release supports verification. This could inform future defenses in compression pipelines used for transmission or storage.
major comments (3)
- [Theoretical analysis section] Theoretical analysis section: The central claim that general ℓ∞-bounded attacks fail specifically because no step-size schedule can accommodate both the Oscillating and Refining stages rests on an unproven uniqueness assumption. The Lazying-Oscillating-Refining stages are presented as derived from observed behavior rather than as invariants of the LIC loss landscape, with no formal proof or exhaustive enumeration showing that alternatives (e.g., cosine annealing, per-pixel adaptive, or learned schedulers) cannot achieve equivalent traversal from Identity to Amplification Region.
- [Experiments section (Kodak results)] Experiments section (Kodak results): The assertion that PGD²-GSM is 'the first to stably achieve high-resolution GSM' is load-bearing for the novelty claim, yet the manuscript provides insufficient quantification of stability (e.g., success rates, variance across random seeds, or multiple LIC models) and lacks direct comparisons to other adaptive step-size schedules that might also succeed, undermining the explanatory link between the three-stage model and the necessity of Periodic Geometric Decay.
- [Abstract and theoretical analysis] Abstract and theoretical analysis: The assumption that well-performing high-resolution GSM requires driving examples through the specific Lazying-Oscillating-Refining stages is presented as explanatory for why standard PGD fails, but without a derivation showing these stages are necessary (rather than observed in successful runs), the argument that the proposed schedule is required to expose the threat remains circular to the empirical outcomes.
minor comments (2)
- [Abstract] Abstract: The low-resolution GSM size is written as ($3×28×28$) while high-resolution is ($3×768×512$); standardize the notation and ensure dimensional consistency throughout.
- [Notation] Notation: Define acronyms (LIC, GSM, PGD, PGD²-GSM) on first use in the main body and ensure the Periodic Geometric Decay schedule is given an explicit equation or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, clarifying our claims and outlining revisions to strengthen the presentation of the theoretical analysis, experimental validation, and novelty arguments.
read point-by-point responses
-
Referee: Theoretical analysis section: The central claim that general ℓ∞-bounded attacks fail specifically because no step-size schedule can accommodate both the Oscillating and Refining stages rests on an unproven uniqueness assumption. The Lazying-Oscillating-Refining stages are presented as derived from observed behavior rather than as invariants of the LIC loss landscape, with no formal proof or exhaustive enumeration showing that alternatives (e.g., cosine annealing, per-pixel adaptive, or learned schedulers) cannot achieve equivalent traversal from Identity to Amplification Region.
Authors: We appreciate this point and agree that our analysis does not include a formal uniqueness proof, which would indeed require exhaustive enumeration of all possible schedulers—an intractable task. The Lazying-Oscillating-Refining stages were identified through a combination of theoretical modeling of gradient dynamics across loss landscape regions and empirical trajectory analysis in both failed and successful attacks. Our contribution is the derivation of the Periodic Geometric Decay schedule specifically to handle these observed dynamics, enabling stable traversal where standard schedules fail. We will revise the theoretical analysis section to explicitly clarify that we do not assert these stages are the only possible path or that our schedule is uniquely necessary; instead, we present it as a practical, minimal modification motivated by the identified dynamics. This revision will remove any implication of exclusivity while preserving the explanatory value of the stage-based analysis. revision: yes
-
Referee: Experiments section (Kodak results): The assertion that PGD²-GSM is 'the first to stably achieve high-resolution GSM' is load-bearing for the novelty claim, yet the manuscript provides insufficient quantification of stability (e.g., success rates, variance across random seeds, or multiple LIC models) and lacks direct comparisons to other adaptive step-size schedules that might also succeed, undermining the explanatory link between the three-stage model and the necessity of Periodic Geometric Decay.
Authors: We acknowledge that stronger quantification and additional baselines would better support the stability claims and the connection to our stage analysis. The current experiments demonstrate that PGD²-GSM achieves stable high-resolution GSM on Kodak (3×768×512) where standard PGD does not, with code released for reproducibility. To address the concern, we will expand the experiments section to report success rates, variance across multiple random seeds, and results on additional LIC models. We will also include direct comparisons against other adaptive schedules (e.g., cosine annealing and per-pixel adaptive variants) to empirically show their limitations in handling the full Lazying-Oscillating-Refining progression. These additions will reinforce the link between the three-stage model and the effectiveness of Periodic Geometric Decay without overstating exclusivity. revision: yes
-
Referee: Abstract and theoretical analysis: The assumption that well-performing high-resolution GSM requires driving examples through the specific Lazying-Oscillating-Refining stages is presented as explanatory for why standard PGD fails, but without a derivation showing these stages are necessary (rather than observed in successful runs), the argument that the proposed schedule is required to expose the threat remains circular to the empirical outcomes.
Authors: We thank the referee for highlighting the risk of circularity. The stages were not posited a priori but emerged from analyzing attack trajectories: theoretical examination of how step-size affects gradient behavior in the Identity versus Amplification Regions, combined with empirical observation that successful high-resolution GSM consistently exhibits Lazying, Oscillating, and Refining phases. The Periodic Geometric Decay schedule was then derived to accommodate these phases. We will revise the abstract and theoretical analysis to more clearly delineate the empirical observations from the theoretical motivation, emphasizing that the schedule is designed to address the dynamics required for stable manipulation (as evidenced by failure of standard schedules). This will avoid any suggestion that the stages are strictly necessary a priori and instead frame them as key observed requirements that our method successfully handles, thereby exposing the threat. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central chain proceeds from stated theoretical/empirical observations of attack dynamics (Identity to Amplification Region via Lazying-Oscillating-Refining stages) to the claim that standard ℓ∞ schedules cannot accommodate both Oscillating and Refining phases, followed by the proposal of Periodic Geometric Decay and PGD²-GSM. No quoted equation, definition, or self-citation reduces the result to its own inputs by construction; the stages and failure diagnosis are presented as analysis outputs rather than tautological re-labelings of fitted parameters or prior self-referential results. Empirical verification on Kodak images supplies independent content, satisfying the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- Hyperparameters of Periodic Geometric Decay schedule
axioms (1)
- domain assumption Well-performing GSM drives adversarial examples through Lazying-Oscillating-Refining stages
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
well-performing GSM drives adversarial examples from the Identity Region to the Amplification Region through the Lazying-Oscillating-Refining stages
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tong Chen and Zhan Ma. Toward robust neural image compression: Adversarial attack and model finetuning.IEEE Transactions on Circuits and Systems for Video Technology, 33(12):7842–7856, 2023
work page 2023
-
[2]
The jpeg still picture compression standard.Communications of the ACM, 34(4):30–44, 1991
Gregory K Wallace. The jpeg still picture compression standard.Communications of the ACM, 34(4):30–44, 1991
work page 1991
-
[3]
The jpeg 2000 still image compression standard.IEEE Signal processing magazine, 18(5):36–58, 2002
Athanassios Skodras, Charilaos Christopoulos, and Touradj Ebrahimi. The jpeg 2000 still image compression standard.IEEE Signal processing magazine, 18(5):36–58, 2002
work page 2000
-
[4]
Gary J Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand. Overview of the high efficiency video coding (hevc) standard.IEEE Transactions on circuits and systems for video technology, 22(12):1649–1668, 2012
work page 2012
-
[5]
Benjamin Bross, Ye-Kui Wang, Yan Ye, Shan Liu, Jianle Chen, Gary J Sullivan, and Jens- Rainer Ohm. Overview of the versatile video coding (vvc) standard and its applications.IEEE Transactions on Circuits and Systems for Video Technology, 31(10):3736–3764, 2021
work page 2021
-
[6]
End-to-end optimized image compres- sion
Johannes Ballé, Valero Laparra, and Eero P Simoncelli. End-to-end optimized image compres- sion. InInternational Conference on Learning Representations, 2017
work page 2017
-
[7]
Varia- tional image compression with a scale hyperprior
Johannes Ballé, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston. Varia- tional image compression with a scale hyperprior. InInternational Conference on Learning Representations, 2018
work page 2018
-
[8]
David Minnen, Johannes Ballé, and George D Toderici. Joint autoregressive and hierarchical priors for learned image compression.Advances in neural information processing systems, 31, 2018
work page 2018
-
[9]
Wecon- vene: Learned image compression with wavelet-domain convolution and entropy model
Haisheng Fu, Jie Liang, Zhenman Fang, Jingning Han, Feng Liang, and Guohe Zhang. Wecon- vene: Learned image compression with wavelet-domain convolution and entropy model. In European Conference on Computer Vision, pages 37–53. Springer, 2024
work page 2024
-
[10]
Minghao Han, Shiyin Jiang, Shengxi Li, Xin Deng, Mai Xu, Ce Zhu, and Shuhang Gu. Causal context adjustment loss for learned image compression.Advances in Neural Information Processing Systems, 37:133231–133253, 2024
work page 2024
-
[11]
Wei Jiang, Peirong Ning, Jiayu Yang, Yongqi Zhai, Feng Gao, and Ronggang Wang. Llic: Large receptive field transform coding with adaptive weights for learned image compression.IEEE Transactions on Multimedia, 26:10937–10951, 2024
work page 2024
-
[12]
Linear attention modeling for learned image compression
Donghui Feng, Zhengxue Cheng, Shen Wang, Ronghua Wu, Hongwei Hu, Guo Lu, and Li Song. Linear attention modeling for learned image compression. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7623–7632, 2025
work page 2025
-
[13]
Learned image compression with dictionary-based entropy model
Jingbo Lu, Leheng Zhang, Xingyu Zhou, Mu Li, Wen Li, and Shuhang Gu. Learned image compression with dictionary-based entropy model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12850–12859, 2025
work page 2025
-
[14]
Learned image compression with hierarchical progressive context modeling
Yuqi Li, Haotian Zhang, Li Li, and Dong Liu. Learned image compression with hierarchical progressive context modeling. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18834–18843, 2025
work page 2025
-
[15]
Wenhong Duan, Jiaye Fu, Chen Cui, Junqi Wu, Li Song, Siwei Ma, and Wen Gao. Learned im- age compression via local-to-global cross-component prior.IEEE Transactions on Multimedia, 2026. 10
work page 2026
-
[16]
Yichi Zhang, Yuning Huang, and Fengqing Zhu. Qarv++: An improved hierarchical vae for learned image compression.IEEE Transactions on Circuits and Systems for Video Technology, 2026
work page 2026
-
[17]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfel- low, and Rob Fergus. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[18]
Explaining and harnessing adversar- ial examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversar- ial examples. InInternational Conference on Learning Representations, 2015
work page 2015
-
[19]
Transferable learned image compression-resistant adversarial perturbations
Yang Sui, Zhuohang Li, Ding Ding, Xiang Pan, Xiaozhong Xu, Shan Liu, and Zhenzhong Chen. Transferable learned image compression-resistant adversarial perturbations. In2024 Data Compression Conference (DCC), pages 582–582. IEEE, 2024
work page 2024
-
[20]
Kang Liu, Di Wu, Yangyu Wu, Yiru Wang, Dan Feng, Benjamin Tan, and Siddharth Garg. Ma- nipulation attacks on learned image compression.IEEE Transactions on Artificial Intelligence, 5(6):3083–3097, 2023
work page 2023
-
[21]
Backdoor attacks against deep image compression via adaptive frequency trigger
Yi Yu, Yufei Wang, Wenhan Yang, Shijian Lu, Yap-Peng Tan, and Alex C Kot. Backdoor attacks against deep image compression via adaptive frequency trigger. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12250–12259, 2023
work page 2023
-
[22]
Chenhao Wu, Qingbo Wu, Haoran Wei, Lei Wang, Fanman Meng, King Ngi Ngan, Li Zhuo, and Hongliang Li. On the adversarial robustness of learning-based image compression against rate-distortion attacks.IEEE Transactions on Multimedia, 2025
work page 2025
-
[23]
Efficient adversarial attack and training on learned image compression
Jun Kurihara and Heming Sun. Efficient adversarial attack and training on learned image compression. In2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pages 2453–2458. IEEE, 2025
work page 2025
-
[24]
Reconstruction distortion of learned image compression with imperceptible perturbations
Yang Sui, Zhuohang Li, Ding Ding, Xiang Pan, Xiaozhong Xu, Shan Liu, and Zhenzhong Chen. Reconstruction distortion of learned image compression with imperceptible perturbations. In 2024 Data Compression Conference (DCC), pages 583–583. IEEE, 2024
work page 2024
-
[25]
An imperceptible adversarial attack against reconstruction for learned image compression
Jingui Ma and Ronggang Wang. An imperceptible adversarial attack against reconstruction for learned image compression. In2024 Data Compression Conference (DCC), pages 573–573. IEEE, 2024
work page 2024
-
[26]
Nikolay I Kalmykov, Razan Dibo, Kaiyu Shen, Xu Zhonghan, Anh-Huy Phan, Yipeng Liu, and Ivan Oseledets. T-mla: A targeted multiscale log–exponential attack framework for neural image compression.Information Sciences, page 123143, 2026
work page 2026
-
[27]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. InInternational Conference on Learning Representations, 2018
work page 2018
-
[28]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In 2017 ieee symposium on security and privacy (sp), pages 39–57. Ieee, 2017
work page 2017
-
[29]
Jindong Gu, Hengshuang Zhao, V olker Tresp, and Philip HS Torr. Segpgd: An effective and efficient adversarial attack for evaluating and boosting segmentation robustness. InEuropean Conference on Computer Vision, pages 308–325. Springer, 2022
work page 2022
-
[30]
Towards adversarially robust object detection
Haichao Zhang and Jianyu Wang. Towards adversarially robust object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 421–430, 2019
work page 2019
-
[31]
The devil is in the details: Window-based attention for image compression
Renjie Zou, Chunfeng Song, and Zhaoxiang Zhang. The devil is in the details: Window-based attention for image compression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17492–17501, 2022
work page 2022
-
[32]
Nvtc: Nonlinear vector transform cod- ing
Runsen Feng, Zongyu Guo, Weiping Li, and Zhibo Chen. Nvtc: Nonlinear vector transform cod- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6101–6110, 2023. 11
work page 2023
-
[33]
Learned image compression with mixed transformer- cnn architectures
Jinming Liu, Heming Sun, and Jiro Katto. Learned image compression with mixed transformer- cnn architectures. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14388–14397, 2023
work page 2023
-
[34]
Frequency- aware transformer for learned image compression
Han Li, Shaohui Li, Wenrui Dai, Chenglin Li, Junni Zou, and Hongkai Xiong. Frequency- aware transformer for learned image compression. InInternational Conference on Learning Representations, 2024
work page 2024
-
[35]
Variable rate image compression with recurrent neural networks
George Toderici, Sean M O’Malley, Sung Jin Hwang, Damien Vincent, David Minnen, Shumeet Baluja, Michele Covell, and Rahul Sukthankar. Variable rate image compression with recurrent neural networks. InInternational Conference on Learning Representations, 2016
work page 2016
-
[36]
Lossy image compression with compressive autoencoders
Lucas Theis, Wenzhe Shi, Andrew Cunningham, and Ferenc Huszár. Lossy image compression with compressive autoencoders. InInternational Conference on Learning Representations, 2017
work page 2017
-
[37]
Channel-wise autoregressive entropy models for learned image compression
David Minnen and Saurabh Singh. Channel-wise autoregressive entropy models for learned image compression. In2020 IEEE International Conference on Image Processing (ICIP), pages 3339–3343. IEEE, 2020
work page 2020
-
[38]
Eirikur Agustsson and Lucas Theis. Universally quantized neural compression.Advances in neural information processing systems, 33:12367–12376, 2020
work page 2020
-
[39]
Variable rate image compression method with dead-zone quantizer
Jing Zhou, Akira Nakagawa, Keizo Kato, Sihan Wen, Kimihiko Kazui, and Zhiming Tan. Variable rate image compression method with dead-zone quantizer. InProceedings of the IEEE/cvf conference on computer vision and pattern recognition workshops, pages 162–163, 2020
work page 2020
-
[40]
Learned image compression with soft bit-based rate-distortion optimization
David Alexandre, Chih-Peng Chang, Wen-Hsiao Peng, and Hsueh-Ming Hang. Learned image compression with soft bit-based rate-distortion optimization. In2019 IEEE International Conference on Image Processing (ICIP), pages 1715–1719. IEEE, 2019
work page 2019
-
[41]
Soft then hard: Rethinking the quantization in neural image compression
Zongyu Guo, Zhizheng Zhang, Runsen Feng, and Zhibo Chen. Soft then hard: Rethinking the quantization in neural image compression. InInternational Conference on Machine Learning, pages 3920–3929. PMLR, 2021
work page 2021
-
[42]
Alberto Presta, Enzo Tartaglione, Attilio Fiandrotti, and Marco Grangetto. Stanh: Paramet- ric quantization for variable rate learned image compression.IEEE Transactions on Image Processing, 34:639–651, 2025
work page 2025
-
[43]
Checkerboard context model for efficient learned image compression
Dailan He, Yaoyan Zheng, Baocheng Sun, Yan Wang, and Hongwei Qin. Checkerboard context model for efficient learned image compression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14771–14780, 2021
work page 2021
-
[44]
Dailan He, Ziming Yang, Weikun Peng, Rui Ma, Hongwei Qin, and Yan Wang. Elic: Efficient learned image compression with unevenly grouped space-channel contextual adaptive coding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5718–5727, 2022
work page 2022
-
[45]
Entroformer: A transformer- based entropy model for learned image compression
Yichen Qian, Ming Lin, Xiuyu Sun, Zhiyu Tan, and Rong Jin. Entroformer: A transformer- based entropy model for learned image compression. InInternational Conference on Learning Representations, 2022
work page 2022
-
[46]
Chao Li, Shanzhi Yin, Chuanmin Jia, Fanyang Meng, Yonghong Tian, and Yongsheng Liang. Multirate progressive entropy model for learned image compression.IEEE Transactions on Circuits and Systems for Video Technology, 34(8):7725–7741, 2024
work page 2024
-
[47]
Jun-Hyuk Kim, Seungeon Kim, Won-Hee Lee, and Dokwan Oh. Diversify, contextualize, and adapt: Efficient entropy modeling for neural image codec.Advances in Neural Information Processing Systems, 37:45956–45974, 2024
work page 2024
-
[48]
Yura Perugachi-Diaz, Arwin Gansekoele, and Sandjai Bhulai. Robustly overfitting latents for flexible neural image compression.Advances in Neural Information Processing Systems, 37:106714–106742, 2024. 12
work page 2024
-
[49]
Xi Zhang and Xiaolin Wu. Learning optimal lattice vector quantizers for end-to-end neural image compression.Advances in Neural Information Processing Systems, 37:106497–106518, 2024
work page 2024
-
[50]
Wei Jiang, Jiayu Yang, Yongqi Zhai, Feng Gao, and Ronggang Wang. Mlic++: Linear complex- ity multi-reference entropy modeling for learned image compression.ACM Transactions on Multimedia Computing, Communications and Applications, 21(5):1–25, 2025
work page 2025
-
[51]
Shen Wang, Zhengxue Cheng, Donghui Feng, Qi Wang, Qunshan Gu, Li Song, and Wenjun Zhang. Distilling complexity-scalable learned image compression models via neural architecture search.IEEE Transactions on Circuits and Systems for Video Technology, 2026
work page 2026
-
[52]
Jordan Madden, Lhamo Dorje, and Xiaohua Li. Bitstream collisions in neural image compres- sion via adversarial perturbations.arXiv preprint arXiv:2503.19817, 2025
-
[53]
Adversarial examples for generative models
Jernej Kos, Ian Fischer, and Dawn Song. Adversarial examples for generative models. In2018 ieee security and privacy workshops (spw), pages 36–42. IEEE, 2018
work page 2018
-
[54]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. InInternational conference on machine learning, pages 2206–2216. PMLR, 2020
work page 2020
-
[55]
High-fidelity variable-rate image compression via invertible activation transformation
Shilv Cai, Zhijun Zhang, Liqun Chen, Luxin Yan, Sheng Zhong, and Xu Zou. High-fidelity variable-rate image compression via invertible activation transformation. InProceedings of the 30th ACM International Conference on Multimedia, pages 2021–2031. ACM, 2022
work page 2021
-
[56]
Kodak lossless true color image suite (photocd pcd0992), 1993
Eastman Kodak. Kodak lossless true color image suite (photocd pcd0992), 1993. 13 Appendix Section A: Proofs Section A.1: Proof of Lemma 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 Section B: Supplementary Materials Section B.1: Kodak Dataset . . . . . . . . . . . . . . . . . . . ...
work page 1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.