Recognition: 2 theorem links
· Lean TheoremThe Extrapolation Cliff in On-Policy Distillation of Near-Deterministic Structured Outputs
Pith reviewed 2026-05-12 03:38 UTC · model grok-4.3
The pith
In on-policy distillation of structured outputs, extrapolation past a closed-form lambda* switches training from format-preserving to format-collapsing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Above lambda*, the extrapolated fixed point exits the clip-safe region, changing training from format-preserving to format-collapsing. In the single-position Bernoulli reduction this threshold is given in closed form by lambda*(p,b,c) using the teacher modal probability p, the warm-start mass b, and the clip strength c. The same boundary governs calibrated K-ary listwise JSON tasks when a single equivalence class dominates and SFT retains parse headroom.
What carries the argument
The clip-safety threshold lambda*(p,b,c) obtained from the single-position Bernoulli reduction of the structured-output dynamics.
If this is right
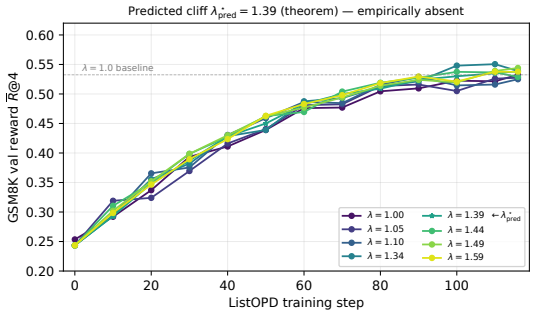
- Operating just below lambda* lets a 1.7B Qwen3 student reach in-domain parity with an 8B-SFT baseline while preserving parse validity.
- NDCG@1 on parsed outputs stays flat across lambda while parse validity changes sharply at the predicted boundary.
- The cliff location is independent of the downstream rubric and can be read directly from the three measurable quantities.
- Small-clip cross-prediction reproduces the closed-form value below grid resolution.
Where Pith is reading between the lines
- The same Bernoulli-derived cliff may appear in any structured generation setting whose output contract is dominated by a single equivalence class.
- Choosing lambda immediately below the predicted threshold offers a practical rule for safe extrapolation without exhaustive search.
- Because the cliff diagnostic does not rely on the evaluator rubric, it can be applied to any parse-based or contract-based evaluation.
Load-bearing premise
The single-position Bernoulli reduction together with the dominance of one equivalence class accurately captures the contract dynamics of the full K-ary listwise JSON output.
What would settle it
If a fine-grid experiment on the Amazon Fashion task places the observed format-collapse point outside the interval predicted by lambda*(p,b,c) at the stated grid resolution, the closed-form threshold is falsified.
Figures







read the original abstract
On-policy distillation (OPD) is widely used for LLM post-training. When pushed with a reward-extrapolation coefficient lambda > 1, the student can lift past the teacher in domain, but past a threshold lambda* the same step violates the output contract on structured-output tasks. In a single-position Bernoulli reduction, we derive a closed-form base-relative clip-safety threshold lambda*(p,b,c) determined by three measurable quantities: the teacher modal probability, the warm-start mass, and the importance-sampling clip strength. Above lambda*, the extrapolated fixed point exits the clip-safe region, changing training from format-preserving to format-collapsing. We extend the rule to calibrated K-ary listwise JSON tasks where a single binding equivalence class dominates the output contract and SFT retains parse headroom. On Amazon Fashion, three pre-registered tests--a fine-grid cliff interval, a budget-extension test, and a small-clip cross-prediction--fall within their locked prediction windows, with the small-clip value matching the closed-form prediction below grid resolution. Operating just below lambda*, ListOPD brings a 1.7B Qwen3 student to in-domain parity with an 8B-SFT baseline at one-fifth the parameters. The gain is driven primarily by format adherence: NDCG@1 on parsed outputs remains flat across lambda, while parse validity sharply changes at the predicted boundary. The cliff diagnostic is rubric-independent, whereas the parity claim uses a Gemini-graded rubric and inherits that evaluator's exposure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a derivation of a closed-form clip-safety threshold λ*(p,b,c) for on-policy distillation in a single-position Bernoulli reduction, where p is the teacher modal probability, b the warm-start mass, and c the importance-sampling clip strength. It argues that exceeding this threshold causes the extrapolated fixed point to exit the clip-safe region, shifting from format-preserving to format-collapsing behavior in structured outputs. The rule is extended to calibrated K-ary listwise JSON tasks assuming a dominating equivalence class and retained parse headroom from SFT. Pre-registered experiments on Amazon Fashion, including a fine-grid cliff interval, budget-extension test, and small-clip cross-prediction, confirm the predictions, with a 1.7B Qwen3 student achieving in-domain parity with an 8B-SFT baseline primarily through improved format adherence.
Significance. Should the result hold, the work provides a useful, parameter-light diagnostic for safe reward extrapolation in OPD on near-deterministic structured tasks, which is increasingly relevant for LLM post-training. Strengths include the closed-form expression depending only on externally measurable quantities, the pre-registered nature of the tests, and the empirical match including exact prediction for small-clip. The observation that NDCG remains flat while parse validity changes at the boundary offers clear evidence for the mechanism. This could help practitioners avoid format collapse while gaining from extrapolation.
major comments (2)
- The derivation of λ*(p,b,c) is performed under a single-position Bernoulli reduction. The subsequent extension to K-ary listwise JSON tasks depends critically on the assumption that a single binding equivalence class dominates the output contract and that SFT retains parse headroom. However, in the full multi-token, multi-position setting, joint probability mass and token dependencies could alter the location of the extrapolated fixed point relative to the clip boundary. The Amazon Fashion experiments match the predicted windows but do not ablate or isolate this assumption, leaving open whether the reduction remains faithful when lifted.
- The three pre-registered tests fall within their locked prediction windows, which is positive. However, to fully support the cross-prediction claim, the paper should report the exact numerical value of the closed-form prediction for the small-clip case and the observed experimental value, rather than stating it matches below grid resolution.
minor comments (2)
- The abstract refers to 'the small-clip value matching the closed-form prediction below grid resolution' without providing the specific numbers; including them would improve transparency.
- The quantities p, b, and c should be explicitly defined with their measurement procedures in the main body early on for readers to follow the closed-form expression.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our results. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: The derivation of λ*(p,b,c) is performed under a single-position Bernoulli reduction. The subsequent extension to K-ary listwise JSON tasks depends critically on the assumption that a single binding equivalence class dominates the output contract and that SFT retains parse headroom. However, in the full multi-token, multi-position setting, joint probability mass and token dependencies could alter the location of the extrapolated fixed point relative to the clip boundary. The Amazon Fashion experiments match the predicted windows but do not ablate or isolate this assumption, leaving open whether the reduction remains faithful when lifted.
Authors: The closed-form threshold is derived exactly in the single-position Bernoulli reduction because that setting isolates the dominant modal probability p at the binding position. The extension to K-ary listwise JSON is explicitly conditioned on the two assumptions stated in the manuscript: a single equivalence class dominates the output contract and SFT retains sufficient parse headroom. These assumptions are motivated by the near-deterministic character of the structured tasks we target. While joint token dependencies in the unrestricted multi-token case could in principle shift the fixed point, the Amazon Fashion experiments already operate in the full multi-position JSON regime and reproduce the predicted cliff location. We therefore view the reduction as a faithful first-order model for the regime of interest. That said, we agree that an explicit ablation isolating the dominance assumption would be valuable; we will add a dedicated limitations paragraph discussing the conditions under which the reduction may cease to be accurate and note the absence of such an ablation as an open direction. revision: partial
-
Referee: The three pre-registered tests fall within their locked prediction windows, which is positive. However, to fully support the cross-prediction claim, the paper should report the exact numerical value of the closed-form prediction for the small-clip case and the observed experimental value, rather than stating it matches below grid resolution.
Authors: We accept this recommendation. The manuscript currently notes only that the small-clip result lies within grid resolution of the closed-form prediction. In the revision we will state the exact closed-form λ* (computed from the measured teacher modal probability p, warm-start mass b, and clip strength c for that condition) together with the experimentally observed cliff location, allowing readers to judge the numerical agreement directly. revision: yes
Circularity Check
Derivation self-contained; no reduction to inputs by construction
full rationale
The paper presents a closed-form derivation of lambda*(p,b,c) inside an explicit single-position Bernoulli reduction, expressed directly in terms of three externally measurable quantities (teacher modal probability p, warm-start mass b, clip strength c). This is not a fit to data but a mathematical threshold whose inputs are observable outside the model. The extension to K-ary listwise JSON tasks is stated under additional modeling assumptions rather than derived as a necessary consequence. Pre-registered experiments test the predicted windows without the outcome being forced by the equations themselves. No self-citations appear as load-bearing premises, no parameters are fitted then relabeled as predictions, and no ansatz or uniqueness claim is smuggled via prior work. The central claim therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Single-position Bernoulli reduction models the structured output contract
- domain assumption A single binding equivalence class dominates the output contract and SFT retains parse headroom in K-ary listwise JSON tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
In a single-position Bernoulli reduction, we derive a closed-form base-relative clip-safety threshold λ⋆(p, b, c) ... λ⋆(p, b, c) = log((1−p)/(c−1+p)) − log((1−b)/b) / log((1−p)/p) − log((1−b)/b)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extend the rule to calibrated K-ary listwise JSON tasks where a single binding equivalence class dominates the output contract
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bhavik Agarwal, Ishan Joshi, and Viktoria Rojkova. Think inside the json: Reinforcement strategy for strict llm schema adherence.arXiv preprint arXiv:2502.14905, 2025
-
[2]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe Twelfth International Conference on Learning Representations,
-
[3]
URLhttps://openreview.net/forum?id=3zKtaqxLhW
-
[4]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. Ms marco: A human generated machine reading comprehension dataset.arXiv preprint arXiv:1611.09268, 2016
work page internal anchor Pith review arXiv 2016
-
[5]
Guiding LLMs The Right Way: Fast, Non-Invasive Constrained Generation,
Luca Beurer-Kellner, Marc Fischer, and Martin Vechev. Guiding llms the right way: Fast, non-invasive constrained generation.arXiv preprint arXiv:2403.06988, 2024
-
[6]
Christopher Burges, Robert Ragno, and Quoc Le. Learning to rank with nonsmooth cost functions.Advances in neural information processing systems, 19, 2006
work page 2006
-
[7]
Learning to rank: from pairwise approach to listwise approach
Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, and Hang Li. Learning to rank: from pairwise approach to listwise approach. InProceedings of the 24th international conference on Machine learning, pages 129–136, 2007
work page 2007
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobsson, Idan Szpektor, Nan- Jiang Jiang, Krishna Haridasan, Ahmed Omran, Nikunj Saunshi, Dara Bahri, Gaurav Mis...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Overview of the trec 2020 deep learning track, 2021
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, and Daniel Campos. Overview of the trec 2020 deep learning track, 2021. URLhttps://arxiv.org/abs/2102.07662
-
[10]
Haikang Deng, Po-Nien Kung, and Nanyun Peng. Decoupling task-solving and output format- ting in llm generation.arXiv preprint arXiv:2510.03595, 2025
-
[11]
Xgrammar: Flexible and efficient structured generation engine for large language models
Yixin Dong, Charlie F Ruan, Yaxing Cai, Ziyi Xu, Yilong Zhao, Ruihang Lai, and Tianqi Chen. Xgrammar: Flexible and efficient structured generation engine for large language models. Proceedings of Machine Learning and Systems, 7, 2025
work page 2025
-
[12]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on- policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
arXiv preprint arXiv:2501.10868 (2025)
Saibo Geng, Hudson Cooper, Michał Moskal, Samuel Jenkins, Julian Berman, Nathan Ranchin, Robert West, Eric Horvitz, and Harsha Nori. Jsonschemabench: A rigorous benchmark of structured outputs for language models.arXiv preprint arXiv:2501.10868, 2025
-
[14]
MiniLLM: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=5h0qf7IBZZ
work page 2024
-
[15]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Stable On-Policy Distillation through Adaptive Target Reformulation
Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, and Taesup Kim. Stable on-policy distillation through adaptive target reformulation.arXiv preprint arXiv:2601.07155, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
RLPO: Residual Listwise Preference Optimization for Long-Context Review Ranking
Hao Jiang, Zhi Yang, Annan Wang, Yichi Zhang, and Weisi Lin. Rlpo: Residual listwise preference optimization for long-context review ranking.arXiv preprint arXiv:2601.07449, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Entropy-aware on-policy distillation of language models
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models. arXiv preprint arXiv:2603.07079, 2026
-
[20]
Juno Kim, Jihun Yun, Jason D Lee, and Kwang-Sung Jun. Coverage improvement and fast convergence of on-policy preference learning.arXiv preprint arXiv:2601.08421, 2026
-
[21]
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. Distillm: Towards streamlined distillation for large language models.arXiv preprint arXiv:2402.03898, 2024
-
[22]
Jongwoo Ko, Tianyi Chen, Sungnyun Kim, Tianyu Ding, Luming Liang, Ilya Zharkov, and Se-Young Yun. Distillm-2: A contrastive approach boosts the distillation of llms.arXiv preprint arXiv:2503.07067, 2025
-
[23]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[24]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Learning to generate structured output with schema reinforcement learning
Yaxi Lu, Haolun Li, Xin Cong, Zhong Zhang, Yesai Wu, Yankai Lin, Zhiyuan Liu, Fangming Liu, and Maosong Sun. Learning to generate structured output with schema reinforcement learning. pages 4905–4918, 2025
work page 2025
-
[26]
Xueguang Ma, Xinyu Zhang, Ronak Pradeep, and Jimmy Lin. Zero-shot listwise document reranking with a large language model.arXiv preprint arXiv:2305.02156, 2023
-
[27]
Document ranking with a pretrained sequence-to-sequence model
Rodrigo Nogueira, Zhiying Jiang, Ronak Pradeep, and Jimmy Lin. Document ranking with a pretrained sequence-to-sequence model. InFindings of the association for computational linguistics: EMNLP 2020, pages 708–718, 2020
work page 2020
-
[28]
Robin L Plackett. The analysis of permutations.Journal of the Royal Statistical Society Series C: Applied Statistics, 24(2):193–202, 1975
work page 1975
-
[29]
Ronak Pradeep, Sahel Sharifymoghaddam, and Jimmy Lin. Rankzephyr: Effective and robust zero-shot listwise reranking is a breeze!arXiv preprint arXiv:2312.02724, 2023
-
[30]
Draft-Conditioned Constrained Decoding for Structured Generation in LLM’s,
Avinash Reddy, Thayne T Walker, James S Ide, and Amrit Singh Bedi. Draft-conditioned constrained decoding for structured generation in llms.arXiv preprint arXiv:2603.03305, 2026
-
[31]
First: Faster improved listwise reranking with single token decoding
Revanth Gangi Reddy, JaeHyeok Doo, Yifei Xu, Md Arafat Sultan, Deevya Swain, Avirup Sil, and Heng Ji. First: Faster improved listwise reranking with single token decoding. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8642–8652, 2024
work page 2024
-
[32]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training
Guobin Shen, Chenxiao Zhao, Xiang Cheng, Lei Huang, and Xing Yu. Vespo: Variational sequence-level soft policy optimization for stable off-policy llm training.arXiv preprint arXiv:2602.10693, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models. arXiv preprint arXiv:2604.00626, 2026
work page internal anchor Pith review arXiv 2026
-
[36]
Is chatGPT good at search? investigating large language models as re-ranking agents
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. Is chatGPT good at search? investigating large language models as re-ranking agents. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URLhttps://openreview.net/forum?id=3Q6LON8y2I
work page 2023
-
[37]
Sönke Tenckhoff, Mario Koddenbrock, and Erik Rodner. Llmstructbench: Benchmarking large language model structured data extraction.arXiv preprint arXiv:2602.14743, 2026
-
[38]
Guided decoding and its critical role in retrieval-augmented generation
Özgür U˘gur, Musa Yılmaz, Esra ¸ Savirdi, Özay Ezerceli, Mahmut El Huseyni, Selva Ta¸ s, and Reyhan Bayraktar. Guided decoding and its critical role in retrieval-augmented generation. pages 1–4, 2025
work page 2025
-
[39]
arXiv preprint arXiv:2510.06062 , year=
Jiakang Wang, Runze Liu, Lei Lin, Wenping Hu, Xiu Li, Fuzheng Zhang, Guorui Zhou, and Kun Gai. Aspo: Asymmetric importance sampling policy optimization.arXiv preprint arXiv:2510.06062, 2025
-
[40]
Efficient Guided Generation for Large Language Models
Brandon T Willard and Rémi Louf. Efficient guided generation for large language models. arXiv preprint arXiv:2307.09702, 2023
work page internal anchor Pith review arXiv 2023
-
[41]
Listwise approach to learning to rank: theory and algorithm
Fen Xia, Tie-Yan Liu, Jue Wang, Wensheng Zhang, and Hang Li. Listwise approach to learning to rank: theory and algorithm. InProceedings of the 25th international conference on Machine learning, pages 1192–1199, 2008
work page 2008
-
[42]
TIP: Token Importance in On-Policy Distillation
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. Tip: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
-
[44]
The price of format: Diversity collapse in llms, 2025
Longfei Yun, Chenyang An, Zilong Wang, Letian Peng, and Jingbo Shang. The price of format: Diversity collapse in llms.arXiv preprint arXiv:2505.18949, 2025
-
[45]
Honglei Zhuang, Zhen Qin, Rolf Jagerman, Kai Hui, Ji Ma, Jing Lu, Jianmo Ni, Xuanhui Wang, and Michael Bendersky. Rankt5: Fine-tuning t5 for text ranking with ranking losses. In Proceedings of the 46th international ACM SIGIR conference on research and development in information retrieval, pages 2308–2313, 2023. 12 Appendix organization.App. A extends the...
work page 2023
-
[46]
that λ⋆(pmin, c), λ⋆(pmean, c) and λ⋆(pmax, c) all lie within ±0.05 of each other at c=5, i.e. within one λ-grid step (Tab. 8); the prediction is therefore aggregator-robust at the grid resolution. The per-token worst-case mini,t mi,t overallgenerated positions is dominated by score-digit positions at which the teacher is genuinely uncertain and gives a d...
-
[47]
crosses the clip-safe boundary between steps 60 and 70 (parse 0.887→0.675 ). Sub-critical λ⋆=1.22>1.15 does not forbid this crossing; Thm. 4.2 gives a budget-dependent first-passage time and 28 extra steps suffice. E.2 Pre-registered budget-Ntest of Thm. 4.2 The two budget points already in Fig. 4 (N=42 and N=70) support Thm. 4.2’s qualitative leftward- d...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.