Recognition: 2 theorem links
· Lean TheoremMirror, Mirror on the Wall: Can VLM Agents Tell Who They Are at All?
Pith reviewed 2026-05-12 03:30 UTC · model grok-4.3
The pith
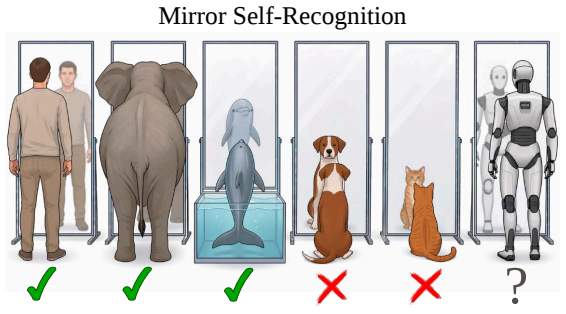
Stronger vision-language models can recognize their reflections to infer hidden body attributes about themselves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our experiments show that mirror-based self-identification emerges mainly in stronger VLMs. These models can use reflected evidence for action, whereas weaker models often inspect the mirror but fail to extract self-relevant information or misattribute their reflection. To separate mirror-grounded self-identification from shortcuts, the tests include mirror removal, misleading cues, and occluded reflections. Language-vision conflict further shows that self-referential language alone is not evidence of grounded self-identification.
What carries the argument
The controlled 3D benchmark where a first-person VLM agent must infer a hidden body attribute from its reflection and select the matching target, while avoiding self-other misattribution, evaluated through mirror seeking, temporal ordering, self-attribution, and reasoning-action consistency.
If this is right
- Stronger models demonstrate the ability to use mirror reflections causally for decision making.
- The benchmark isolates perceptual self-grounding from prompt compliance and confabulation.
- Weaker models exhibit inspection of mirrors without successful self-attribution.
- Self-referential language does not guarantee grounded self-identification when visual evidence is present.
Where Pith is reading between the lines
- Future work could apply similar tests to other sensory modalities or more complex environments to track the development of self-awareness.
- This may indicate that embodied self-grounding requires sufficient model capacity to integrate vision with action planning.
- Researchers could use the benchmark to compare different training approaches for improving self-recognition in agents.
Load-bearing premise
The controlled 3D benchmark with tests for mirror removal, misleading cues, and occluded reflections successfully isolates mirror-grounded self-identification from shortcuts such as prompt compliance or confabulation.
What would settle it
A clear falsifier would be if stronger models continue to select the correct target even when the mirror is removed or the reflection is occluded, showing they are not actually relying on the visual reflection.
Figures







read the original abstract
In the animal kingdom, mirror self-recognition is a canonical probe of higher-order cognition, emerging only in some species. We ask whether an analogous functional capability emerges in embodied vision-language model (VLM) agents: can they recognize themselves in a mirror? We introduce a controlled 3D benchmark where a first-person VLM agent must infer a hidden body attribute from its reflection and select the matching target, while avoiding self-other misattribution. To separate mirror-grounded self-identification from shortcuts, we test mirror removal, misleading cues, and occluded reflections. We also evaluate the decision process through mirror seeking, temporal ordering, self-attribution, and reasoning-action consistency. Our experiments show that mirror-based self-identification emerges mainly in stronger VLMs. These models can use reflected evidence for action, whereas weaker models often inspect the mirror but fail to extract self-relevant information or misattribute their reflection. Language-vision conflict further shows that self-referential language alone is not evidence of grounded self-identification. Overall, mirror-based evaluation provides a diagnostic for whether embodied self-grounding is causally rooted in perception and action rather than priors, prompt compliance, or confabulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a novel 3D benchmark designed to test mirror self-recognition capabilities in embodied vision-language model (VLM) agents. The benchmark involves agents inferring hidden body attributes from their mirror reflections to select matching targets, incorporating controls such as mirror removal, misleading cues, and occluded reflections to distinguish true self-identification from alternative explanations like prompt compliance or confabulation. The authors evaluate decision processes using metrics including mirror seeking behavior, temporal ordering, self-attribution, and reasoning-action consistency. Key findings indicate that mirror-based self-identification primarily emerges in stronger VLMs, which can leverage reflected visual evidence for appropriate actions, whereas weaker models tend to inspect mirrors without extracting self-relevant information or misattribute reflections. Additionally, a language-vision conflict test demonstrates that self-referential language alone does not indicate grounded self-identification.
Significance. If the experimental results hold under scrutiny, this work offers a valuable new tool for assessing self-grounding in AI agents by adapting a classic test from animal cognition. It highlights the importance of perceptual and action-based grounding over linguistic priors in embodied VLMs, which has implications for developing more robust and self-aware AI systems. The controlled nature of the benchmark and the differentiation between model strengths contribute to a better understanding of current limitations in VLM agents' cognitive capabilities.
major comments (2)
- [§4] §4 (Benchmark Design): The claim that the controls (mirror removal, occluded reflections) successfully isolate mirror-grounded self-identification is load-bearing for the central result; however, the manuscript does not report quantitative failure modes (e.g., percentage of misattribution vs. non-inspection) broken down by model strength, making it difficult to confirm the isolation holds across the tested agents.
- [§5.3] §5.3 (Language-Vision Conflict Test): The test is presented as evidence that self-referential language is insufficient, but the manuscript lacks detail on the exact prompting procedure for inducing conflict and the consistency metric used to score reasoning-action alignment; without these, the distinction between stronger and weaker models rests on unverified process tracing.
minor comments (3)
- The introduction would benefit from explicit citations to prior VLM embodiment benchmarks (e.g., those testing spatial reasoning or object permanence) to better situate the novelty of the mirror test.
- [Table 1] Table 1 (or equivalent results table) should include per-model success rates with standard errors or confidence intervals to allow readers to assess the robustness of the 'stronger vs. weaker' distinction.
- Figure captions for the benchmark scenarios could be expanded to label the agent's viewpoint, mirror placement, and target options explicitly, improving reproducibility for readers attempting to replicate the 3D setup.
Simulated Author's Rebuttal
We thank the referee for their constructive review and positive assessment of the work's significance. We address each major comment below and will incorporate clarifications and additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Benchmark Design): The claim that the controls (mirror removal, occluded reflections) successfully isolate mirror-grounded self-identification is load-bearing for the central result; however, the manuscript does not report quantitative failure modes (e.g., percentage of misattribution vs. non-inspection) broken down by model strength, making it difficult to confirm the isolation holds across the tested agents.
Authors: We agree that a quantitative breakdown of failure modes would provide stronger evidence that the controls isolate mirror-grounded self-identification. In the revised manuscript we will add a new table in §4 reporting, for each model, the percentages of trials exhibiting misattribution versus non-inspection (and other failure categories) under the mirror-removal and occluded-reflection conditions. These statistics will be stratified by model strength to allow direct verification that the isolation holds across the tested agents. The core experimental design and results remain unchanged. revision: yes
-
Referee: [§5.3] §5.3 (Language-Vision Conflict Test): The test is presented as evidence that self-referential language is insufficient, but the manuscript lacks detail on the exact prompting procedure for inducing conflict and the consistency metric used to score reasoning-action alignment; without these, the distinction between stronger and weaker models rests on unverified process tracing.
Authors: We acknowledge that additional procedural detail would improve transparency and reproducibility. In the revision we will expand §5.3 with (i) the exact prompt templates used to create language-vision conflicts and (ii) the formal definition and computation of the reasoning-action consistency metric (including the alignment scoring rule between extracted reasoning steps and executed actions). These details were recorded in our experimental protocol but omitted from the main text for space; their inclusion will not alter the reported outcomes or the distinction between stronger and weaker models. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark study introducing a controlled 3D environment to test mirror self-recognition in VLM agents. Claims rest on observed experimental outcomes (e.g., stronger models using reflected evidence for action while weaker ones fail) and process metrics such as mirror seeking and self-attribution, with explicit controls for confounds like mirror removal and occluded reflections. No derivations, equations, fitted parameters, or load-bearing self-citations appear; the design directly measures perceptual grounding versus shortcuts without reducing to internal definitions or prior author results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a controlled 3D benchmark where a first-person VLM agent must infer a hidden body attribute from its reflection... interventions that remove the mirror, provide misleading linguistic cues, or degrade the reflection through occlusion.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our experiments show that mirror-based self-identification emerges mainly in stronger VLMs... Language-vision conflict further shows that self-referential language alone is not evidence of grounded self-identification.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Introducing Claude Sonnet 4.6, February 2026
Anthropic. Introducing Claude Sonnet 4.6, February 2026. URL https://www.anthropic. com/news/claude-sonnet-4-6. Accessed: 2026-05-07
work page 2026
-
[2]
Marc Bekoff and Paul W. Sherman. Reflections on animal selves.Trends in Ecology & Evolution, 19(4):176–180, 2004
work page 2004
-
[3]
Johannes L. Brandl. The puzzle of mirror self-recognition.Phenomenology and the Cognitive Sciences, 17:279–304, 2018. doi: 10.1007/s11097-016-9486-7
-
[4]
Liangtang Chang, Shikun Zhang, Mu-ming Poo, and Neng Gong. Spontaneous expression of mirror self-recognition in monkeys after learning precise visual-proprioceptive association for mirror images.Proceedings of the National Academy of Sciences, 114(12):3258–3263, 2017. doi: 10.1073/pnas.1620764114
-
[5]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiao wen Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. Are we on the right way for evaluating large vision-language models?ArXiv, abs/2403.20330, 2024. doi: 10.48550/arxiv.2403.20330
work page internal anchor Pith review doi:10.48550/arxiv.2403.20330 2024
-
[6]
Gheorghe Comanici et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. URLhttps://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Aaditya Singh et. al. Openai gpt-5 system card, 2026. URL https://arxiv.org/abs/2601. 03267
work page 2026
-
[8]
Gordon G. Gallup. Chimpanzees: Self-recognition.Science, 167(3914):86–87, 1970. doi: 10.1126/science.167.3914.86
-
[9]
Gordon G. Gallup. Self-awareness and the emergence of mind in primates.American Journal of Primatology, 2:237–248, 1982
work page 1982
-
[10]
Gordon G. Gallup, James R. Anderson, and Diane J. Shillito. The mirror test. In Marc Bekoff, Colin Allen, and Gordon M. Burghardt, editors,The Cognitive Animal: Empirical and Theoretical Perspectives on Animal Cognition. MIT Press, Cambridge, MA, 2002
work page 2002
-
[11]
Hoffmann, Shengzhi Wang, V ojtˇech Outrata, E
M. Hoffmann, Shengzhi Wang, V ojtˇech Outrata, E. Alzueta, and Pablo Lanillos. Robot in the mirror: Toward an embodied computational model of mirror self-recognition.KI - Künstliche Intelligenz, 35:37 – 51, 2020. doi: 10.1007/s13218-020-00701-7
-
[12]
Are you looking? grounding to multiple modalities in vision-and-language navigation
Ronghang Hu, Daniel Fried, Anna Rohrbach, Dan Klein, Trevor Darrell, and Kate Saenko. Are you looking? grounding to multiple modalities in vision-and-language navigation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6551–6557, 2019
work page 2019
-
[13]
Baiqi Li, Zhiqiu Lin, Wenxuan Peng, Jean de Dieu Nyandwi, Daniel Jiang, Zixian Ma, Simran Khanuja, Ranjay Krishna, Graham Neubig, and Deva Ramanan. Naturalbench: Evaluating vision-language models on natural adversarial samples.ArXiv, abs/2410.14669, 2024. doi: 10.48550/arxiv.2410.14669
-
[14]
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Zongxia Li, Wenhao Yu, Chengsong Huang, Rui Liu, Zhenwen Liang, Fuxiao Liu, Jingxi Che, Dian Yu, J. Boyd-Graber, Haitao Mi, and Dong Yu. Self-rewarding vision-language model via reasoning decomposition.ArXiv, abs/2508.19652, 2025. doi: 10.48550/arxiv.2508.19652. 10
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.19652 2025
-
[15]
Alexander H Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, et al. Ministral 3.arXiv preprint arXiv:2601.08584, 2026
work page internal anchor Pith review arXiv 2026
-
[16]
MMBench: Is Your Multi-modal Model an All-around Player?
Yuanzhan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player?ArXiv, abs/2307.06281, 2023. doi: 10.48550/arxiv.2307.06281
work page internal anchor Pith review doi:10.48550/arxiv.2307.06281 2023
-
[17]
Evidence of self-awareness in the bottlenose dolphin (Tursiops truncatus), 1994
Ken Marten and Suchi Psarakos. Evidence of self-awareness in the bottlenose dolphin (Tursiops truncatus), 1994
work page 1994
-
[18]
R. Mitchell. Mental models of mirror-self-recognition: Two theories.New Ideas in Psychology, 11:295–325, 1993. doi: 10.1016/0732-118x(93)90002-u
- [19]
-
[20]
Alain Morin and Sandra DeBlois. Gallup’s mirrors: More than an operationalization of self- awareness in primates?Psychological Reports, 65(1):287–291, 1989. doi: 10.2466/pr0.1989. 65.1.287
-
[21]
Precocious development of self-awareness in dolphins.PLoS One, 13(1):e0189813, 2018
Rachel Morrison and Diana Reiss. Precocious development of self-awareness in dolphins.PLoS One, 13(1):e0189813, 2018
work page 2018
-
[22]
A. Pipitone and A. Chella. Robot passes the mirror test by inner speech.Robotics Auton. Syst., 144:103838, 2021. doi: 10.1016/j.robot.2021.103838
-
[23]
Joshua M. Plotnik, Frans B. M. de Waal, and Diana Reiss. Self-recognition in an asian elephant. Proceedings of the National Academy of Sciences, 103(45):17053–17057, 2006
work page 2006
-
[24]
Helmut Prior, Ariane Schwarz, and Onur Güntürkün. Mirror-induced behavior in the magpie (Pica pica): Evidence of self-recognition.PLoS Biology, 6(8):e202, 2008
work page 2008
-
[25]
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, and A. Nguyen. Vision language models are blind.ArXiv, abs/2407.06581, 2024. doi: 10.48550/arxiv.2407.06581
-
[26]
Sotaro Shimada. Multisensory and sensorimotor integration in the embodied self: Relationship between self-body recognition and the mirror neuron system.Sensors (Basel, Switzerland), 22,
-
[27]
doi: 10.3390/s22135059
-
[28]
The robot in the mirror.Connection Science, 20(4):337–358, 2008
Luc Steels and Michael Spranger. The robot in the mirror.Connection Science, 20(4):337–358, 2008
work page 2008
-
[29]
Susan D. Suarez and Gordon G. Gallup. Self-recognition in chimpanzees and orangutans, but not gorillas.Journal of Human Evolution, 10(2):175–188, 1981
work page 1981
-
[30]
Magnus Söderlund. When service robots look at themselves in the mirror: An examination of the effects of perceptions of robotic self-recognition.Journal of Retailing and Consumer Services, 2022. doi: 10.1016/j.jretconser.2021.102820
-
[31]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. URL https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033. IEEE, 2012. doi: 10.1109/IROS.2012.6386109
-
[33]
Xiyao Wang, Jiuhai Chen, Zhaoyang Wang, Yuhang Zhou, Yiyang Zhou, Huaxiu Yao, Tianyi Zhou, Tom Goldstein, Parminder Bhatia, Furong Huang, and Cao Xiao. Enhancing visual- language modality alignment in large vision language models via self-improvement.ArXiv, abs/2405.15973, 2024. doi: 10.48550/arxiv.2405.15973. 11
-
[34]
Enhancing visual-language modality alignment in large vision language models via self-improvement
Xiyao Wang, Jiuhai Chen, Zhaoyang Wang, Yuhang Zhou, Yiyang Zhou, Huaxiu Yao, Tianyi Zhou, Tom Goldstein, Parminder Bhatia, Taha Kass-Hout, et al. Enhancing visual-language modality alignment in large vision language models via self-improvement. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 268–282, 2025
work page 2025
-
[35]
Peng Xu, Wenqi Shao, Kaipeng Zhang, Peng Gao, Shuo Liu, Meng Lei, Fanqing Meng, Siyuan Huang, Yu Qiao, and Ping Luo. Lvlm-ehub: A comprehensive evaluation benchmark for large vision-language models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47 (3):1877–1893, 2024
work page 2024
-
[36]
Embodied visual recognition.arXiv preprint arXiv:1904.04404, 2019
Jianwei Yang, Zhile Ren, Mingze Xu, Xinlei Chen, David Crandall, Devi Parikh, and Dhruv Batra. Embodied visual recognition.arXiv preprint arXiv:1904.04404, 2019
-
[37]
Tongtian Yue, Jie Cheng, Longteng Guo, Xingyuan Dai, Zijia Zhao, Xingjian He, Gang Xiong, Yisheng Lv, and Jing Liu. Sc- tune: Unleashing self-consistent referential comprehension in large vision language models. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13073–13083, 2024. doi: 10.1109/cvpr52733.2024.01242
-
[38]
Yi Zeng, Yuxuan Zhao, Jun Bai, and Bo Xu. Toward robot self-consciousness (ii): Brain- inspired robot bodily self model for self-recognition.Cognitive Computation, 10:307 – 320,
-
[39]
doi: 10.1007/s12559-017-9505-1
-
[40]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46:5625– 5644, 2023. doi: 10.1109/tpami.2024.3369699
-
[41]
Monkeys pass the mirror test after training.Science China
Wen Zhou and Yi Jiang. Monkeys pass the mirror test after training.Science China. Life Sciences, 58(4):405, 2015
work page 2015
-
[42]
Yiyang Zhou, Zhiyuan Fan, Dongjie Cheng, Sihan Yang, Zhaorun Chen, Chenhang Cui, Xiyao Wang, Yun Li, Linjun Zhang, and Huaxiu Yao. Calibrated self-rewarding vision language models.ArXiv, abs/2405.14622, 2024. doi: 10.48550/arxiv.2405.14622. 12 A Additional Results A.1 Auxiliary Metrics and Relative Results In addition to the core metrics reported in the m...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.