Recognition: no theorem link
RubricRefine: Improving Tool-Use Agent Reliability with Training-Free Pre-Execution Refinement
Pith reviewed 2026-05-15 05:21 UTC · model grok-4.3
The pith
RubricRefine generates task-specific rubrics to score and repair tool-use code for contract violations before any execution occurs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RubricRefine is a training-free pre-execution reliability layer that generates task- and registry-specific rubrics, scores candidate code against explicit contract checks, and iteratively repairs failures before any execution occurs. With zero execution attempts it reaches 0.86 on M3ToolEval averaged across seven models, improving over prior inference-time baselines on every model tested while using 2.6X lower latency than the strongest non-iterative alternative.
What carries the argument
RubricRefine, a pre-execution loop that derives contract-checking rubrics from the task description and tool registry, then scores and revises code against those rubrics.
If this is right
- Reliability gains appear only on tasks with multiple interdependent tool calls.
- The method requires no model fine-tuning and works uniformly across the seven tested models.
- Latency stays lower than iterative post-execution refinement because no code is run during repair.
- Ablation shows that rubric categories targeting output shape, routing, and provenance drive most of the improvement.
Where Pith is reading between the lines
- Explicit contract rubrics may prove more consistent than learned critique signals for any structured generation task that must satisfy interface rules.
- The approach could be extended by feeding rubric scores back into the initial generation prompt to reduce the number of repair iterations needed.
- If inter-tool contracts are the main failure mode in larger agent systems, pre-execution checking becomes a scalable alternative to running many expensive trials.
Load-bearing premise
Automatically generated rubrics can detect the dominant inter-tool contract violations without execution feedback or model-specific tuning.
What would settle it
An experiment on a benchmark dominated by single-tool calls or execution-time errors where RubricRefine produces no gain or a drop relative to the plain baseline.
Figures










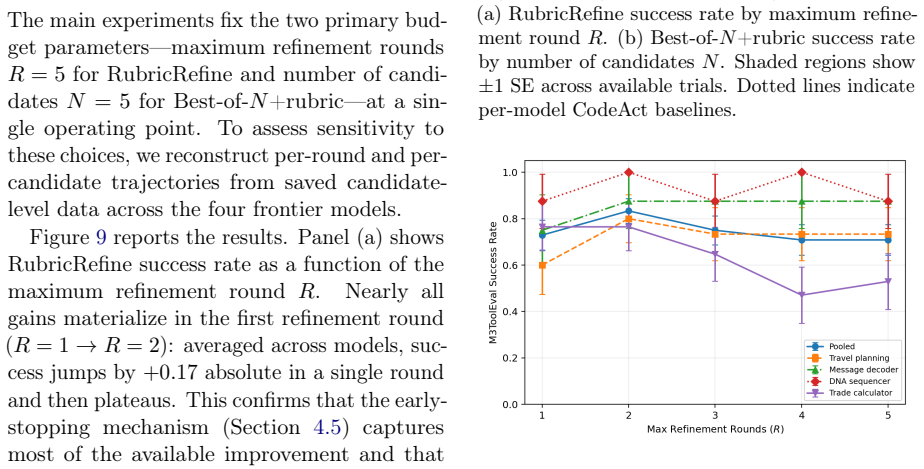

read the original abstract
Iterative self-refinement is a popular inference-time reliability technique, but its effectiveness in code-mode tool use depends heavily on the structure of the feedback signal: unstructured critique helps inconsistently across models, and even revision with real execution feedback improves only modestly ($0.75$ vs. $0.65$ baseline). The dominant failures are inter-tool contract violations - wrong output shape, incorrect tool routing, broken argument provenance - that run to completion without raising errors, making runtime feedback insufficient. We introduce RubricRefine, a training-free pre-execution reliability layer that generates task- and registry-specific rubrics, scores candidate code against explicit contract checks, and iteratively repairs failures before any execution occurs. With zero execution attempts, RubricRefine reaches $0.86$ on M3ToolEval averaged across seven models-improving over prior inference-time baselines on every model tested on this benchmark, at $2.6X$ lower latency than the strongest non-iterative alternative - and remains flat on the predominantly single-step API-Bank, consistent with the method's reliance on inter-tool contract structure. A rubric-category ablation and calibration analysis further characterize when and why the method works.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RubricRefine, a training-free pre-execution refinement method for tool-use agents. It generates task- and registry-specific rubrics to detect and repair inter-tool contract violations (output shape, routing, argument provenance) in candidate code before any execution occurs. The central empirical claim is that this yields an average score of 0.86 on M3ToolEval across seven models, outperforming prior inference-time baselines on every model while incurring 2.6X lower latency than the strongest non-iterative alternative; performance remains flat on the single-step API-Bank benchmark, consistent with the method's focus on multi-tool contracts. An ablation on rubric categories and a calibration analysis are provided to characterize when the approach succeeds.
Significance. If the automatically generated rubrics prove to be reliable proxies for runtime correctness without execution feedback, the method would offer an efficient, training-free layer for improving agent reliability in multi-tool settings. The reported latency advantage and consistent gains across models would position it as a practical alternative to execution-dependent self-refinement loops, with potential impact on inference-time reliability techniques for code-mode agents.
major comments (3)
- [§4.2] §4.2 (Calibration Analysis): The paper references a calibration analysis but supplies no rubric-vs-execution confusion matrix, precision/recall figures, or agreement metric between rubric pass/fail decisions and actual runtime success. This leaves the core assumption—that rubric scores reliably detect contract violations without execution ground truth—unverified and directly load-bearing for the 0.86 M3ToolEval claim.
- [Results section, Table 1] Results section, Table 1 (M3ToolEval scores): The reported average of 0.86 and per-model improvements are given without error bars, standard deviations, or statistical significance tests across the seven models. In the absence of these, the robustness of the gains over baselines cannot be assessed and the claim of improvement on every model remains difficult to evaluate.
- [§3] §3 (Method description): The rubric scoring threshold is identified as a free parameter, yet no sensitivity analysis, default value, or selection procedure is reported. Because success is declared solely when a candidate passes the rubric (zero executions), the lack of threshold justification directly affects reproducibility and the interpretation of the performance numbers.
minor comments (3)
- [Abstract] Abstract: The 2.6X latency claim should explicitly name the strongest non-iterative baseline to which it is compared.
- [Figure 2] Figure 2 (latency comparison): The plot would be clearer if it included per-model variance or confidence intervals rather than point estimates alone.
- [Related Work] Related Work: A brief contrast with prior rubric-based or contract-checking methods in program synthesis would help situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important areas for improving the clarity and rigor of our manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Calibration Analysis): The paper references a calibration analysis but supplies no rubric-vs-execution confusion matrix, precision/recall figures, or agreement metric between rubric pass/fail decisions and actual runtime success. This leaves the core assumption—that rubric scores reliably detect contract violations without execution ground truth—unverified and directly load-bearing for the 0.86 M3ToolEval claim.
Authors: We agree that explicit metrics validating the rubric's alignment with runtime outcomes would strengthen the core claim. The calibration analysis in the original manuscript demonstrates a correlation between rubric scores and final task success rates, but lacks the requested confusion matrix and derived metrics. In the revised version, we will include a full rubric-vs-execution confusion matrix, precision, recall, and Cohen's kappa agreement metric. These will be computed by executing the RubricRefine outputs on a subset of M3ToolEval tasks where ground-truth execution results are available, directly addressing the verification of the pre-execution assumption. revision: yes
-
Referee: [Results section, Table 1] Results section, Table 1 (M3ToolEval scores): The reported average of 0.86 and per-model improvements are given without error bars, standard deviations, or statistical significance tests across the seven models. In the absence of these, the robustness of the gains over baselines cannot be assessed and the claim of improvement on every model remains difficult to evaluate.
Authors: This is a valid point regarding statistical robustness. Although the improvements are consistent across all seven models, we did not report variability measures. In the revised manuscript, we will augment Table 1 with error bars showing the standard deviation of scores across the seven models for each method, and add statistical significance tests (paired t-tests) comparing RubricRefine to each baseline, with p-values reported. This will allow for a more rigorous evaluation of the gains. revision: yes
-
Referee: [§3] §3 (Method description): The rubric scoring threshold is identified as a free parameter, yet no sensitivity analysis, default value, or selection procedure is reported. Because success is declared solely when a candidate passes the rubric (zero executions), the lack of threshold justification directly affects reproducibility and the interpretation of the performance numbers.
Authors: We acknowledge the need for better documentation of this hyperparameter. The threshold was empirically set to 0.75 in our experiments to optimize the trade-off between false positives and false negatives on a small development set. We will revise §3 to explicitly state the default threshold value (0.75), describe the selection procedure, and include a sensitivity analysis plotting M3ToolEval performance as a function of the threshold (ranging from 0.5 to 1.0). This will enhance reproducibility and show that the reported results are not overly sensitive to the exact choice. revision: yes
Circularity Check
No circularity: empirical benchmark results independent of internal derivations
full rationale
The paper introduces a training-free method that generates task-specific rubrics for pre-execution code repair and reports performance as direct scores on external benchmarks (M3ToolEval averaged across models, API-Bank). No equations, fitted parameters, or self-referential definitions appear in the provided text; the 0.86 score and latency claims are measured outcomes rather than quantities constructed from the method's own inputs. Rubric generation and calibration are described as part of the approach but are validated through ablation and external evaluation, not reduced to self-definition or prior self-citations. This is the standard case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- rubric scoring threshold
axioms (1)
- domain assumption Inter-tool contract violations are the dominant source of silent failures in code-mode tool use.
invented entities (1)
-
RubricRefine
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Yinghui He, Simran Kaur, Adithya Bhaskar, Yongjin Yang, Jiarui Liu, Narutatsu Ri, Liam Fowl, Abhishek Panigrahi, Danqi Chen, and Sanjeev Arora. Self-distillation zero: Self-revision turns binary rewards into dense supervision. arXiv:2604.12002, 2026. URL: https://arxiv.org/abs/2604.12002
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Executable code actions elicit better LLM agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better LLM agents. In Proceedings of ICML, 2024. arXiv:2402.01030. URL: https://proceedings.mlr.press/v235/wang24h.html
-
[3]
API-Bank : A comprehensive benchmark for tool-augmented LLMs
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-Bank : A comprehensive benchmark for tool-augmented LLMs . In Proceedings of EMNLP, 2023. DOI: https://doi.org/10.18653/v1/2023.emnlp-main.187. URL: https://aclanthology.org/2023.emnlp-main.187/
-
[4]
Self-refine: Iterative refinement with self-feedback
Aman Madaan et al. Self-refine: Iterative refinement with self-feedback. In Proceedings of NeurIPS, 2023. URL: https://openreview.net/forum?id=S37hOerQLB
work page 2023
-
[5]
Language Models (Mostly) Know What They Know
Saurav Kadavath et al. Language models (mostly) know what they know. arXiv:2207.05221, 2022. URL: https://arxiv.org/abs/2207.05221
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In Proceedings of ICML, 2017. URL: https://proceedings.mlr.press/v70/guo17a.html
work page 2017
-
[8]
Meelis Kull, Telmo Silva Filho, and Peter Flach. Beta calibration: a well-founded and easily implemented improvement on logistic calibration for binary classifiers. In Proceedings of AISTATS, 2017. URL: https://proceedings.mlr.press/v54/kull17a.html
work page 2017
-
[9]
Loubna Ben Allal, Benjamin Piwowarski, and Hugging Face. smolagents. GitHub repository, 2024. URL: https://github.com/huggingface/smolagents
work page 2024
-
[10]
Introducing code mode for AI agents
Cloudflare. Introducing code mode for AI agents. Cloudflare blog, 2024. URL: https://blog.cloudflare.com/code-mode/
work page 2024
-
[11]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters. arXiv:2408.03314, 2024. URL: https://arxiv.org/abs/2408.03314
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Hunter Lightman et al. Let's verify step by step. In Proceedings of ICLR, 2024. URL: https://openreview.net/forum?id=v8L0pN6EOi
work page 2024
-
[13]
When can LLMs actually correct their own mistakes? A survey of self-correction
Ryo Kamoi, Yixuan Zhang, Nuo Zhang, Jiawei Han, and Rui Zhang. When can LLMs actually correct their own mistakes? A survey of self-correction. TACL, 2024. DOI: https://doi.org/10.1162/tacl_a_00713. URL: https://aclanthology.org/2024.tacl-1.78/
-
[14]
PreFlect: From retrospective to prospective reflection in language agents
Haonan Wang et al. PreFlect: From retrospective to prospective reflection in language agents. arXiv:2602.07187, 2026. URL: https://arxiv.org/abs/2602.07187
-
[15]
CRITIC : Large language models can self-correct with tool-interactive critiquing
Zhibin Gou et al. CRITIC : Large language models can self-correct with tool-interactive critiquing. In Proceedings of ICLR, 2024. URL: https://openreview.net/forum?id=Sx038qxjek
work page 2024
-
[16]
Toolace: Winning the points of llm function calling
Wei Liu et al. ToolACE: Winning the points of function calling. arXiv:2409.00920, 2024. URL: https://arxiv.org/abs/2409.00920
-
[17]
BUTTON: Multi-turn function calling via compositional instruction tuning
Mingzhe Chen et al. BUTTON: Multi-turn function calling via compositional instruction tuning. In Proceedings of ICLR, 2025. URL: https://openreview.net/forum?id=owP2mymrTD
work page 2025
-
[18]
Advancing tool-augmented LLMs via meta-verification and reflection learning
Ziyu Ma et al. Advancing tool-augmented LLMs via meta-verification and reflection learning. In Proceedings of KDD, 2025. DOI: https://doi.org/10.1145/3711896.3736835
-
[19]
FunReason: Enhancing function calling via self-refinement and data refinement
Bo Hao et al. FunReason: Enhancing function calling via self-refinement and data refinement. arXiv:2505.20192, 2025. URL: https://arxiv.org/abs/2505.20192
-
[20]
Nemotron-research-tool-n1: Exploring tool-using language models with reinforced reasoning
Shuo Zhang et al. Nemotron-Research-Tool-N1: Exploring tool-using language models with reinforced reasoning. arXiv:2505.00024, 2025. URL: https://arxiv.org/abs/2505.00024
-
[21]
ReTool: Reinforcement learning for strategic tool use in LLMs
Jiahao Feng et al. ReTool: Reinforcement learning for strategic tool use in LLMs . In Proceedings of ICLR, 2026. URL: https://openreview.net/forum?id=tRk1nofSmz
work page 2026
-
[22]
GEAR : Generalizable and efficient tool resolution
Yining Lu, Haoping Yu, and Daniel Khashabi. GEAR : Generalizable and efficient tool resolution. In Proceedings of EACL, 2024. URL: https://aclanthology.org/2024.eacl-long.7/
work page 2024
-
[23]
Chain-of-Tools: Utilizing massive unseen tools in chain-of-thought reasoning
Minghao Wu et al. Chain-of-Tools: Utilizing massive unseen tools in chain-of-thought reasoning. arXiv:2503.16779, 2025. URL: https://arxiv.org/abs/2503.16779
-
[24]
Ethan Lumer et al. GraphRAG-ToolFusion. arXiv:2502.07223, 2025. URL: https://arxiv.org/abs/2502.07223
-
[25]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs . In Proceedings of ICLR, 2024. URL: https://openre...
work page 2024
-
[26]
Patil, Ion Stoica, and Joseph E
Fanjia Yan, Huanzhi Mao, Charlie Cheng-Jie Ji, Tianjun Zhang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Berkeley function calling leaderboard. 2024. URL: https://gorilla.cs.berkeley.edu/leaderboard.html
work page 2024
-
[27]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai et al. Constitutional AI : Harmlessness from AI feedback. arXiv:2212.08073, 2022. URL: https://arxiv.org/abs/2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Judging LLM -as-a-judge with MT-Bench and Chatbot Arena
Lianmin Zheng et al. Judging LLM -as-a-judge with MT-Bench and Chatbot Arena . In Proceedings of NeurIPS, 2023. URL: https://proceedings.neurips.cc/paper_files/paper/2023/hash/91f18a1287b398d378ef22505bf41832-Paper-Datasets_and_Benchmarks.pdf
work page 2023
-
[29]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim et al. Prometheus: Inducing fine-grained evaluation capability in language models. In Proceedings of ICLR, 2024. URL: https://openreview.net/forum?id=8euJaTveKw
work page 2024
-
[30]
ResearchRubrics: Prompt-specific rubrics for deep research agent evaluation
Mansi Sharma et al. ResearchRubrics: Prompt-specific rubrics for deep research agent evaluation. arXiv:2511.07685, 2025. URL: https://arxiv.org/abs/2511.07685
-
[31]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Akshay Gunjal et al. Rubrics as Rewards: Reinforcement learning beyond verifiable domains. arXiv:2507.17746, 2025. URL: https://arxiv.org/abs/2507.17746
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Agentic Rubrics as contextual verifiers for software agents
Madhav Raghavendra et al. Agentic Rubrics as contextual verifiers for software agents. arXiv:2601.04171, 2026. URL: https://arxiv.org/abs/2601.04171
-
[33]
Morris H. DeGroot and Stephen E. Fienberg. The comparison and evaluation of forecasters. Journal of the Royal Statistical Society: Series D (The Statistician), 32(1-2):12--22, 1983. DOI: https://doi.org/10.2307/2987588
-
[34]
Mahdi Pakdaman Naeini, Gregory F. Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using Bayesian binning into quantiles. In Proceedings of AAAI, 2015. URL: https://ojs.aaai.org/index.php/AAAI/article/view/9602
work page 2015
-
[35]
Enabling calibration in the zero-shot inference of large vision-language models
Will LeVine, Benjamin Pikus, Pranav Raja, and Fernando Amat Gil. Enabling calibration in the zero-shot inference of large vision-language models. In Proceedings of ICLR (Tiny Papers), 2023. arXiv:2303.12748. URL: https://openreview.net/forum?id=na1T7ZGYb4
-
[36]
Predicting good probabilities with supervised learning
Alexandru Niculescu-Mizil and Rich Caruana. Predicting good probabilities with supervised learning. In Proceedings of the 22nd International Conference on Machine Learning, pages 625--632, 2005. DOI: https://doi.org/10.1145/1102351.1102430
-
[37]
Accurate layerwise interpretable competence estimation
Vickram Rajendran and William LeVine. Accurate layerwise interpretable competence estimation. Advances in Neural Information Processing Systems, 32, 2019. URL: https://proceedings.neurips.cc/paper_files/paper/2019/file/a11da6bd58b95b334f8cd49f00918f16-Paper.pdf
work page 2019
-
[38]
Meelis Kull, Miquel Perello Nieto, Markus K\"angsepp, Telmo Silva Filho, Hao Song, and Peter Flach. Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with Dirichlet calibration. Advances in Neural Information Processing Systems, 32, 2019. URL: https://proceedings.neurips.cc/paper_files/paper/2019/file/8ca01ea920679a0fe3728441...
work page 2019
-
[39]
Revisiting the calibration of modern neural networks
Matthias Minderer, Josip Djolonga, Rob Romijnders, Frances Hubis, Xiaohua Zhai, Neil Houlsby, Dustin Tran, and Mario Lucic. Revisiting the calibration of modern neural networks. Advances in Neural Information Processing Systems, 34:15682--15694, 2021. URL: https://proceedings.neurips.cc/paper_files/paper/2021/file/8420d359404024567b5aefda1231af24-Paper.pdf
work page 2021
-
[40]
Teaching Large Language Models to Self-Debug
Xinyun Chen, Maxwell Lin, Nathanael Sch\"arli, and Denny Zhou. Teaching large language models to self-debug. In Proceedings of ICLR, 2024. arXiv:2304.05128. URL: https://openreview.net/forum?id=KuPixIqPiq
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
CodeT : Code generation with generated tests
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. CodeT : Code generation with generated tests. arXiv preprint, 2022. arXiv:2207.10397. URL: https://arxiv.org/abs/2207.10397
-
[42]
Code generation with AlphaCodium : From prompt engineering to flow engineering
Tal Ridnik, Dedy Kredo, and Itamar Friedman. Code generation with AlphaCodium : From prompt engineering to flow engineering. arXiv preprint, 2024. arXiv:2401.08500. URL: https://arxiv.org/abs/2401.08500
-
[43]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In Proceedings of NeurIPS, 2023. URL: https://proceedings.neurips.cc/paper_files/paper/2023/file/1b44b878bb782e6954cd888628510e90-Paper-Conference.pdf
work page 2023
-
[44]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Proceedings of NeurIPS, 2023. URL: https://proceedings.neurips.cc/paper_files/paper/2023/file/271db9922b8d1f4dd7aaef84ed5ac703-Paper-Conference.pdf
work page 2023
-
[45]
Google DeepMind. Gemma 4. 2026. URL: https://deepmind.google/models/gemma/gemma-4/
work page 2026
-
[46]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. In Proceedings of ICLR, 2024. URL: https://openreview.net/forum?id=IkmD3fKBPQ
work page 2024
-
[47]
M., Jeong, J., Veitch, V ., Wang, W., He, Y ., Liu, B., and Jin, L
Junkai Zhang, Zihao Wang, Lin Gui, Swarnashree Mysore Sathyendra, Jaehwan Jeong, Victor Veitch, Wei Wang, Yunzhong He, Bing Liu, and Lifeng Jin. Chasing the tail: Effective rubric-based reward modeling for large language model post-training. In Proceedings of ICLR, 2026. arXiv:2509.21500. URL: https://arxiv.org/abs/2509.21500
-
[48]
LLM -as-a-Verifier: A general-purpose verification framework
Jacky Kwok. LLM -as-a-Verifier: A general-purpose verification framework. GitHub repository, 2026. URL: https://github.com/llm-as-a-verifier/llm-as-a-verifier
work page 2026
-
[49]
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven C.H. Hoi. CodeRL : Mastering code generation through pretrained models and deep reinforcement learning. In Proceedings of NeurIPS, 2022. URL: https://proceedings.neurips.cc/paper_files/paper/2022/hash/8636419dea1aa9fbd5aa0cf977903d9a-Paper-Conference.html
-
[50]
Ansong Ni, Srini Iyer, Dragomir Radev, Veselin Stoyanov, Wen-tau Yih, Sida I. Wang, and Xi Victoria Lin. LEVER : Learning to verify language-to-code generation with execution. In Proceedings of ICML, 2023. URL: https://proceedings.mlr.press/v202/ni23b.html
work page 2023
-
[51]
Yujia Li et al. Competition-level code generation with AlphaCode . Science, 378(6624):1092--1097, 2022. DOI: https://doi.org/10.1126/science.abq1158
-
[52]
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning, acting, and planning in language models. arXiv:2310.04406, 2023. URL: https://arxiv.org/abs/2310.04406
-
[53]
Will LeVine and Bijan Varjavand. Relevance isn't all you need: Scaling RAG systems with inference-time compute via multi-criteria reranking. arXiv:2504.07104, 2025. URL: https://arxiv.org/abs/2504.07104
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.