Recognition: no theorem link
Geometric 4D Stitching for Grounded 4D Generation
Pith reviewed 2026-05-12 04:02 UTC · model grok-4.3
The pith
Geometric 4D stitching fills missing scene regions with explicit consistent patches to build grounded 4D representations rapidly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
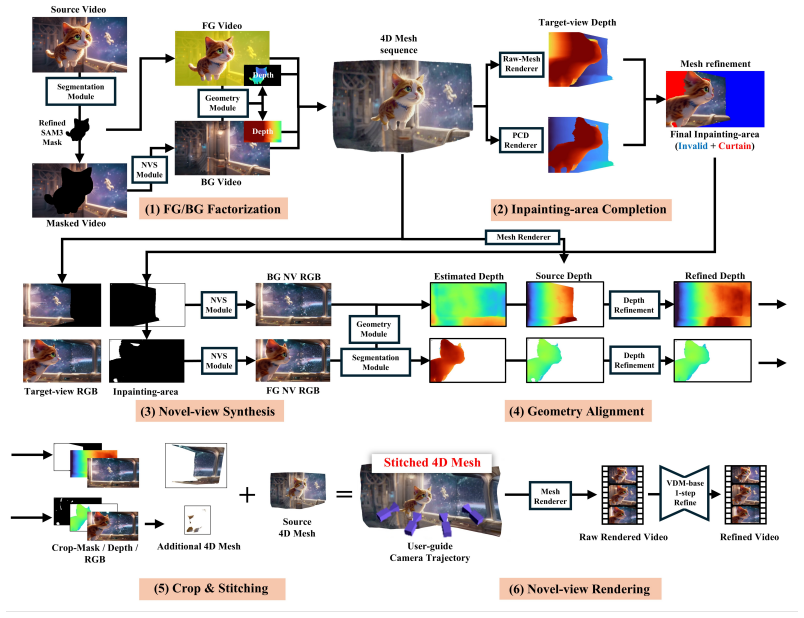
Geometric 4D Stitching is an efficient framework that explicitly identifies missing geometric regions in generated 4D content and complements them with geometrically grounded 4D stitches. This approach constructs 4D scene representations in under 10 minutes on a single NVIDIA RTX 5090 GPU per one-step scene expansion while improving geometric consistency. The explicit stitches further support interactive expansion of 4D meshes as well as 4D scene editing.
What carries the argument
Geometric 4D Stitching: the explicit identification of missing geometric regions followed by addition of geometrically grounded 4D stitches that enforce consistency without radiance optimization.
Load-bearing premise
Generative models supply enough accurate information about missing regions that the added stitches complete the geometry without creating new inconsistencies or needing further optimization.
What would settle it
Apply the stitching to a 4D scene whose ground-truth geometry is known and incomplete, then check whether the output shows visible geometric mismatches or still requires extra optimization to match the true shape.
Figures



















read the original abstract
Recent 4D generation methods complete scene-level missing information using generative models and reconstruct the scene into radiance-based representations. However, these pipelines often present geometric inconsistencies in the generated content, and the radiance-based reconstruction requires expensive optimization. Furthermore, radiance-based representations often absorb these geometric inconsistencies into their view-dependent nature, failing to enforce the grounded geometric consistency. To address these issues, we propose Geometric 4D Stitching, an efficient framework that explicitly identifies missing geometric regions and complements them with geometrically grounded 4D stitches. As a result, our method constructs 4D scene representations in under 10 minutes on a single NVIDIA RTX 5090 GPU per one-step scene expansion, while improving geometric consistency. Moreover, we demonstrate that our explicit 4D stitching supports interative expansion of 4D mesh as well as 4D scene editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Geometric 4D Stitching, an efficient framework for 4D scene generation that explicitly identifies missing geometric regions via generative models and complements them with geometrically grounded 4D stitches. This avoids radiance-based reconstructions and their associated expensive optimization while claiming to produce consistent 4D representations in under 10 minutes on a single NVIDIA RTX 5090 GPU per one-step scene expansion, with additional support for interactive 4D mesh expansion and scene editing.
Significance. If validated with quantitative evidence, the explicit geometric stitching approach would represent a meaningful advance over radiance-field pipelines by enforcing grounded 4D consistency without optimization, potentially enabling faster and more editable 4D content for graphics and vision applications.
major comments (1)
- The central claim that stitching 'improves geometric consistency' and runs 'in under 10 minutes' is load-bearing but presented without any reported metrics, baselines, or timing breakdowns in the provided abstract; the full manuscript must include these in the experiments section to substantiate the efficiency and consistency assertions.
minor comments (1)
- Abstract: 'interative' is a typographical error and should be 'interactive'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the clear identification of where quantitative support is needed to strengthen our claims. We address the comment below and commit to revisions that directly incorporate the requested evidence.
read point-by-point responses
-
Referee: The central claim that stitching 'improves geometric consistency' and runs 'in under 10 minutes' is load-bearing but presented without any reported metrics, baselines, or timing breakdowns in the provided abstract; the full manuscript must include these in the experiments section to substantiate the efficiency and consistency assertions.
Authors: We agree that the abstract summarizes the benefits at a high level and that explicit quantitative support belongs in the experiments section. The current manuscript already reports wall-clock timings on the RTX 5090 GPU that confirm the under-10-minute per-expansion runtime, together with qualitative side-by-side visualizations showing reduced geometric artifacts relative to radiance-field baselines. To meet the referee’s request for rigorous substantiation, we will expand the Experiments section in the revised manuscript with (1) quantitative geometric-consistency metrics (e.g., mean surface-to-surface distance and normal-consistency scores on reconstructed meshes), (2) direct numerical comparisons against representative radiance-based 4D pipelines, and (3) a component-wise timing breakdown (missing-region detection, stitch generation, and mesh integration). These additions will be placed in a new subsection and will be supported by additional figures and tables. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The abstract and method description present a high-level framework for identifying missing geometry via generative models and applying explicit 4D stitches, with performance claims (under 10 minutes on RTX 5090) stated directly rather than derived from equations. No mathematical derivations, fitted parameters, self-citations as load-bearing premises, or renamings of known results appear in the provided text. The central claims rest on the proposed stitching operation enforcing consistency by construction, but this is asserted without reducing to a self-referential definition or prior self-citation chain. The paper is therefore self-contained against external benchmarks for the purpose of this analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in 4d generation: A survey, 2025
Qiaowei Miao, Kehan Li, Jinsheng Quan, Zhiyuan Min, Shaojie Ma, Yichao Xu, Yi Yang, and Yawei Luo. Advances in 4d generation: A survey, 2025. URLhttps://arxiv.org/abs/2503.14501
-
[2]
Barron, and Aleksander Holynski
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T. Barron, and Aleksander Holynski. Cat4d: Create anything in 4d with multi-view video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26057–26068, June 2025
work page 2025
-
[3]
Free4d: Tuning-free 4d scene generation with spatial-temporal consistency
Tianqi Liu, Zihao Huang, Zhaoxi Chen, Guangcong Wang, Shoukang Hu, Liao Shen, Huiqiang Sun, Zhiguo Cao, Wei Li, and Ziwei Liu. Free4d: Tuning-free 4d scene generation with spatial-temporal consistency. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 25571–25582, October 2025
work page 2025
-
[4]
Sv4d: Dynamic 3d content generation with multi-frame and multi-view consistency
Yiming Xie, Chun-Han Yao, Vikram V oleti, Huaizu Jiang, and Varun Jampani. Sv4d: Dynamic 3d content generation with multi-frame and multi-view consistency. InInternational Conference on Learning Representations (ICLR), 2025. URLhttps://openreview.net/forum?id=tJoS2d0Onf
work page 2025
-
[5]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023. URL https: //repo-sam.inria.fr/fungraph/3d-gaussian-splatting/. 9
work page 2023
-
[6]
4d gaussian splatting for real-time dynamic scene rendering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20310–20320, June 2024
work page 2024
-
[7]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InEuropean Conference on Computer Vision (ECCV), 2020
work page 2020
-
[8]
D-nerf: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10318–10327, June 2021
work page 2021
-
[9]
Jangho Park, Taesung Kwon, and Jong Chul Ye. Zero4d: Training-free 4d video generation from single video using off-the-shelf video diffusion.arXiv preprint arXiv:2503.22622, 2025. URL https: //arxiv.org/abs/2503.22622
-
[10]
Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[11]
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, and Di Zhang. Recammaster: Camera-controlled generative rendering from a single video.arXiv preprint arXiv:2503.11647, 2025. URLhttps://arxiv.org/abs/2503.11647
-
[12]
CogVideoX: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. CogVideoX: Text-to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations, 2025
work page 2025
-
[13]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Xiangyu Sun, Shijie Wang, Fengyi Zhang, Lin Liu, Caiyan Jia, Ziying Song, Zi Huang, and Yadan Luo. Vggt-world: Transforming vggt into an autoregressive geometry world model.arXiv preprint arXiv:2603.12655, 2026
-
[15]
VideoGPA: Distilling Geometry Priors for 3D-Consistent Video Generation
Hongyang Du, Junjie Ye, Xiaoyan Cong, Runhao Li, Jingcheng Ni, Aman Agarwal, Zeqi Zhou, Zekun Li, Randall Balestriero, and Yue Wang. Videogpa: Distilling geometry priors for 3d-consistent video generation.arXiv preprint arXiv:2601.23286, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Nerf-editing: Geometry editing of neural radiance fields
Yu-Jie Yuan, Yang-Tian Sun, Yu-Kun Lai, Yuewen Ma, Rongfei Jia, and Lin Gao. Nerf-editing: Geometry editing of neural radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18353–18364, 2022
work page 2022
-
[17]
Control-nerf: Editable feature volumes for scene rendering and manipulation
Verica Lazova, Vladimir Guzov, Kyle Olszewski, Sergey Tulyakov, and Gerard Pons-Moll. Control-nerf: Editable feature volumes for scene rendering and manipulation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4340–4350, 2023
work page 2023
-
[18]
Yufei Wang, Shaowei Liu, Minghan Li, Yi Yang, and Bo Dai. Vggt: Visual geometry grounded transformer for multi-view 3d reconstruction.arXiv preprint arXiv:2409.04530, 2024. URL https://arxiv.org/ abs/2409.04530
-
[19]
Depth Anything 3: Recovering the Visual Space from Any Views
Lihe Yang et al. Depth anything 3: Recovering the visual space from any number of views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, Dahua Lin, and Bo Dai. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.arXiv preprint arXiv:2505.23716, 2025. URLhttps://arxiv.org/abs/2505.23716
-
[21]
Instant4d: 4d gaussian splatting in minutes.arXiv preprint arXiv:2510.01119, 2025
Zhanpeng Luo, Haoxi Ran, and Li Lu. Instant4d: 4d gaussian splatting in minutes.arXiv preprint arXiv:2510.01119, 2025. URLhttps://arxiv.org/abs/2510.01119. Accepted by NeurIPS 2025. 10
-
[22]
Sora 2 model documentation, 2026
OpenAI. Sora 2 model documentation, 2026. URL https://developers.openai.com/api/docs/ models/sora-2. Accessed: 2026-03-04
work page 2026
-
[23]
Vbench: Comprehensive benchmark suite for video generative models
Zhipeng Huang, Shengyu Zhao, Zhaoyang Wu, Zhe Li, Yuxiao Liu, Jiaying Lin, Bo Dai, and Limin Wang. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[24]
Shinji Umeyama. Least-squares estimation of transformation parameters between two point patterns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(4):376–380, 1991
work page 1991
-
[25]
SAM 3: Segment Anything with Concepts
Nicolas Carion et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025. 11 A Additional Discussion on the Ill-Posed Problem Setting of Generated-Data-Based 4D Generation In this section, we provide a more detailed discussion of why generated-data-based 4D generation is fundamentally ill-posed, and where its main bottlenecks aris...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.