Recognition: no theorem link
SocialDirector: Training-Free Social Interaction Control for Multi-Person Video Generation
Pith reviewed 2026-05-12 03:08 UTC · model grok-4.3
The pith
SocialDirector steers multi-person video interactions without training by masking attention and reweighting directional words.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SocialDirector enhances video generation models by modulating cross-attention maps through two modules. Social Actor Masking applies a spatiotemporal mask so each person's visual tokens attend solely to their own textual descriptions, preventing actor-action mismatch and disordered dynamics. Directional Reweighting increases attention weights on directional terms such as 'leftward' or 'right,' directing each action toward its intended recipient. Experiments across different base models show the combined controller raises interaction fidelity scores and brings them close to the level measured on real videos.
What carries the argument
Social Actor Masking and Directional Reweighting modules that reshape cross-attention maps to enforce actor-specific and target-specific behavior.
If this is right
- Generated videos show the correct person performing each described action.
- Social gestures and conversations occur in coherent order rather than randomly.
- Each action is directed toward the person named in the prompt.
- The same modules improve results across multiple different video generation backbones.
- Automated VLM evaluation becomes a practical way to benchmark social fidelity.
Where Pith is reading between the lines
- The same attention-shaping idea could be applied to other forms of controllable generation such as 3D scene animation or robot motion planning.
- Because the method needs no retraining, it could be combined with future larger models to add social control at negligible extra cost.
- Extending the masking logic to longer temporal windows might handle multi-turn conversations that current short-clip generators cannot yet manage.
Load-bearing premise
Modulating cross-attention maps through these two modules is enough to enforce correct social dynamics without creating new visual artifacts or requiring per-model tuning.
What would settle it
Running the two modules on a held-out video generator produces either lower interaction scores on the VLM pipeline or visible artifacts such as distorted faces or inconsistent motion.
Figures





read the original abstract
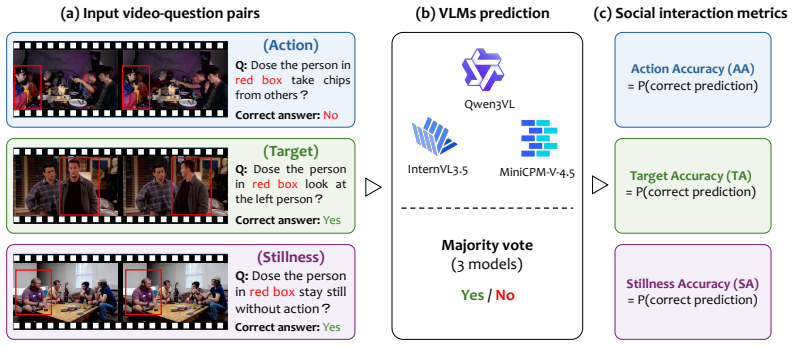
Video generation has advanced rapidly, producing photorealistic videos from text or image prompts. Meanwhile, film production and social robotics increasingly demand multi-person videos with rich social interactions, including conversations, gestures, and coordinated actions. However, existing models offer no explicit control over interactions, such as who performs which action, when it occurs, and toward whom it is directed. This often results in wrong person performing unintended actions (actor-action mismatch), disordered social dynamics, and wrong action targets. To address these challenges, we present SocialDirector, a training-free interaction controller that enhances the generation model by modulating cross-attention maps. SocialDirector contains two modules: Social Actor Masking and Directional Reweighting. Social Actor Masking constrains each person's visual tokens to attend only to their own textual descriptions via a spatiotemporal mask, avoiding actor-action mismatch and disordered social dynamics. Directional Reweighting amplifies attention to directional words (e.g., "leftward", "right"), leading each action towards its intended target. To evaluate generated social interactions, we annotate existing datasets with interaction descriptions and build a fully automated evaluation pipeline powered by open-source VLMs. Experiments on different video generation models show that SocialDirector significantly improves interaction fidelity and approaches the upper bound set by real videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SocialDirector, a training-free interaction controller for multi-person video generation that modulates cross-attention maps in existing models. It consists of two modules: Social Actor Masking, which applies a spatiotemporal mask so each person's visual tokens attend only to their own textual descriptions, and Directional Reweighting, which amplifies attention to directional words to ensure actions target the intended recipient. The authors annotate datasets with interaction descriptions and develop a VLM-powered automated evaluation pipeline; experiments on multiple video generation models are claimed to show significant gains in interaction fidelity that approach the performance of real videos.
Significance. If the experimental results and evaluation pipeline prove robust, the work would provide a practical, model-agnostic method for adding explicit social-interaction control to video generators without retraining. This could meaningfully advance controllable generation for applications in film production and social robotics by addressing actor-action mismatches and disordered dynamics through lightweight attention interventions.
major comments (2)
- [Abstract] Abstract: the claim that experiments 'significantly improve interaction fidelity and approach the upper bound set by real videos' is unsupported by any quantitative metrics, tables, ablation results, or baseline comparisons in the manuscript, leaving the central empirical assertion without verifiable evidence.
- [Abstract] Abstract: the automated evaluation pipeline is described only at a high level; missing details include the precise VLM prompting strategy, the interaction-specific metrics computed, the annotation protocol for the datasets, and the exact procedure for establishing the real-video upper bound, all of which are required to assess the pipeline's validity and reproducibility.
Simulated Author's Rebuttal
Thank you for your review and the recommendation for major revision. We address the two major comments on the abstract point by point below, agreeing that additional details and evidence are needed for clarity and verifiability. We will incorporate these changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments 'significantly improve interaction fidelity and approach the upper bound set by real videos' is unsupported by any quantitative metrics, tables, ablation results, or baseline comparisons in the manuscript, leaving the central empirical assertion without verifiable evidence.
Authors: The referee is correct that the current abstract does not include quantitative metrics to support the claim. While the manuscript describes the experimental setup and claims significant improvements based on the VLM evaluation, specific numbers, tables, and comparisons are not detailed in the abstract itself. To strengthen this, we will revise the abstract to include key quantitative results, such as the measured improvements in interaction fidelity scores and how close the generated videos come to real-video performance, along with references to the full experimental section. This revision will provide verifiable evidence directly in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the automated evaluation pipeline is described only at a high level; missing details include the precise VLM prompting strategy, the interaction-specific metrics computed, the annotation protocol for the datasets, and the exact procedure for establishing the real-video upper bound, all of which are required to assess the pipeline's validity and reproducibility.
Authors: We acknowledge that the abstract provides only a high-level description of the evaluation pipeline. In the revised manuscript, we will expand the abstract to include the necessary details: the specific VLM prompts used for assessing interactions, the exact metrics (e.g., actor-action alignment and directional accuracy scores), the protocol for annotating datasets with interaction descriptions, and the method for computing the real-video upper bound by running the pipeline on ground-truth videos. These additions will enhance reproducibility and allow readers to fully assess the pipeline's validity. revision: yes
Circularity Check
No circularity: explicit non-parametric intervention on attention maps
full rationale
The paper presents SocialDirector as a training-free controller consisting of two explicit modules (Social Actor Masking via spatiotemporal mask and Directional Reweighting) that directly modulate existing cross-attention maps in video generation models. No derivation chain, fitted parameters, predictions, or self-citations are described in the abstract; the method is introduced as a direct, non-circular intervention without reducing any claimed result to its own inputs by construction. The evaluation pipeline is also presented as an independent annotation and VLM-based process. This is the most common honest non-finding for a purely architectural proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-attention maps in video generation models encode actor-action bindings that can be edited post-hoc without retraining.
Reference graph
Works this paper leans on
-
[1]
Cross- image attention for zero-shot appearance transfer
Yuval Alaluf, Daniel Garibi, Or Patashnik, Hadar Averbuch-Elor, and Daniel Cohen-Or. Cross- image attention for zero-shot appearance transfer. InACM SIGGRAPH 2024 conference papers, pages 1–12, 2024
work page 2024
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bodily behaviors in social interaction: Novel annotations and state-of-the-art evalua- tion
Michal Balazia, Philipp Müller, Ákos Levente Tánczos, August von Liechtenstein, and François Brémond. Bodily behaviors in social interaction: Novel annotations and state-of-the-art evalua- tion. InProceedings of the 30th ACM International Conference on Multimedia, pages 70–79, 2022
work page 2022
-
[4]
arXiv preprint arXiv:2409.16283 (2024)
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doer- sch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, and Sean Kirmani. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation.arXiv preprint arXiv:2409.16283, 2024
-
[5]
Socialgesture: Delving into multi-person gesture understanding
Xu Cao, Pranav Virupaksha, Wenqi Jia, Bolin Lai, Fiona Ryan, Sangmin Lee, and James M Rehg. Socialgesture: Delving into multi-person gesture understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19509–19519, 2025
work page 2025
-
[6]
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models.ACM transactions on Graphics (TOG), 42(4):1–10, 2023
work page 2023
-
[7]
Junhao Chen, Mingjin Chen, Jianjin Xu, Xiang Li, Junting Dong, Mingze Sun, Puhua Jiang, Hongxiang Li, Yuhang Yang, Hao Zhao, et al. Dancetogether! identity-preserving multi-person interactive video generation.arXiv preprint arXiv:2505.18078, 2025
-
[8]
Ming Chen, Liyuan Cui, Wenyuan Zhang, Haoxian Zhang, Yan Zhou, Xiaohan Li, Songlin Tang, Jiwen Liu, Borui Liao, Hejia Chen, et al. Midas: Multimodal interactive digital-human synthesis via real-time autoregressive video generation.arXiv preprint arXiv:2508.19320, 2025
-
[9]
Training-free layout control with cross-attention guidance
Minghao Chen, Iro Laina, and Andrea Vedaldi. Training-free layout control with cross-attention guidance. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 5343–5353, 2024
work page 2024
-
[10]
Yi Chen, Sen Liang, Zixiang Zhou, Ziyao Huang, Yifeng Ma, Junshu Tang, Qin Lin, Yuan Zhou, and Qinglin Lu. Hunyuanvideo-avatar: High-fidelity audio-driven human animation for multiple characters.arXiv preprint arXiv:2505.20156, 2025
-
[11]
Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions
Zhiyuan Chen, Jiajiong Cao, Zhiquan Chen, Yuming Li, and Chenguang Ma. Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 2403–2410, 2025
work page 2025
-
[12]
Gang Cheng, Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Ju Li, Dechao Meng, Jinwei Qi, Penchong Qiao, et al. Wan-animate: Unified character animation and replacement with holistic replication.arXiv preprint arXiv:2509.14055, 2025
-
[13]
Ernie Chu and Vishal M Patel. Face-to-face: A video dataset for multi-person interaction modeling.arXiv preprint arXiv:2603.14794, 2026
-
[14]
Xuangeng Chu, Ruicong Liu, Yifei Huang, Yun Liu, Yichen Peng, and Bo Zheng. Unils: End- to-end audio-driven avatars for unified listening and speaking.arXiv preprint arXiv:2512.09327, 2025
-
[15]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
arXiv preprint arXiv:2407.03168 , year =
Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, and Di Zhang. Liveportrait: Efficient portrait animation with stitching and retargeting control.arXiv preprint arXiv:2407.03168, 2024
-
[17]
Initno: Boosting text-to-image diffusion models via initial noise optimization
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. Initno: Boosting text-to-image diffusion models via initial noise optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9380–9389, 2024
work page 2024
-
[18]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page Pith review arXiv 2026
-
[19]
Prompt-to-prompt image editing with cross-attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross-attention control. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[20]
Yubo Huang, Weiqiang Wang, Sirui Zhao, Tong Xu, Lin Liu, and Enhong Chen. Bind-your- avatar: Multi-talking-character video generation with dynamic 3d-mask-based embedding router. arXiv preprint arXiv:2506.19833, 2025
-
[21]
Smile: Multimodal dataset for understanding laughter in video with language models
Lee Hyun, Kim Sung-Bin, Seungju Han, Youngjae Yu, and Tae-Hyun Oh. Smile: Multimodal dataset for understanding laughter in video with language models. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 1149–1167, 2024
work page 2024
-
[22]
The audio-visual conversational graph: From an egocentric-exocentric perspective
Wenqi Jia, Miao Liu, Hao Jiang, Ishwarya Ananthabhotla, James M Rehg, Vamsi Krishna Ithapu, and Ruohan Gao. The audio-visual conversational graph: From an egocentric-exocentric perspective. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26396–26405, 2024
work page 2024
-
[23]
Text2performer: Text-driven human video generation
Yuming Jiang, Shuai Yang, Tong Liang Koh, Wayne Wu, Chen Change Loy, and Ziwei Liu. Text2performer: Text-driven human video generation. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 22747–22757, 2023
work page 2023
-
[24]
From natural alignment to conditional controllability in multimodal dialogue
Zeyu Jin, Songtao Zhou, Haoyu Wang, Minghao Tian, Kaifeng Yun, Zhuo Chen, Xiaoyu Qin, and Jia Jia. From natural alignment to conditional controllability in multimodal dialogue. In The Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[25]
Caixin Kang, Yifei Huang, Liangyang Ouyang, Mingfang Zhang, Ruicong Liu, and Yoichi Sato. Can mllms read the room? a multimodal benchmark for assessing deception in multi-party social interactions.arXiv preprint arXiv:2511.16221, 2025
-
[26]
Dense text-to-image generation with attention modulation
Yunji Kim, Jiyoung Lee, Jin-Hwa Kim, Jung-Woo Ha, and Jun-Yan Zhu. Dense text-to-image generation with attention modulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7701–7711, 2023
work page 2023
-
[27]
SIV-Bench: A Video Benchmark for Social Interaction Understanding and Reasoning
Fanqi Kong, Weiqin Zu, Xinyu Chen, Yaodong Yang, Song-Chun Zhu, and Xue Feng. Siv- bench: A video benchmark for social interaction understanding and reasoning.arXiv preprint arXiv:2506.05425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Let them talk: Audio-driven multi-person conversational video generation
Zhe Kong, Feng Gao, Yong Zhang, Zhuoliang Kang, Xiaoming Wei, Xunliang Cai, Guanying Chen, and Wenhan Luo. Let them talk: Audio-driven multi-person conversational video generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[29]
Wessel Kraaij, Thomas Hain, Mike Lincoln, and Wilfried Post. The ami meeting corpus. In Proc. International Conference on Methods and Techniques in Behavioral Research, pages 1–4, 2005
work page 2005
-
[30]
Werewolf among us: Multimodal resources for modeling persuasion behaviors in social deduction games
Bolin Lai, Hongxin Zhang, Miao Liu, Aryan Pariani, Fiona Ryan, Wenqi Jia, Shirley Anu- grah Hayati, James Rehg, and Diyi Yang. Werewolf among us: Multimodal resources for modeling persuasion behaviors in social deduction games. InFindings of the Association for Computational Linguistics: ACL 2023, pages 6570–6588, 2023. 11
work page 2023
-
[31]
Sangmin Lee, Bolin Lai, Fiona Ryan, Bikram Boote, and James M Rehg. Modeling multimodal social interactions: new challenges and baselines with densely aligned representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14585–14595, 2024
work page 2024
-
[32]
Sangmin Lee, Minzhi Li, Bolin Lai, Wenqi Jia, Fiona Ryan, Xu Cao, Ozgur Kara, Bikram Boote, Weiyan Shi, Diyi Yang, et al. Towards social ai: A survey on understanding social interactions.arXiv preprint arXiv:2409.15316, 2024
-
[33]
Tvqa: Localized, compositional video question answering
Jie Lei, Licheng Yu, Mohit Bansal, and Tamara Berg. Tvqa: Localized, compositional video question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 1369–1379, 2018
work page 2018
-
[34]
Towards online multi-modal social interaction understanding.arXiv preprint arXiv:2503.19851, 2025
Xinpeng Li, Shijian Deng, Bolin Lai, Weiguo Pian, James M Rehg, and Yapeng Tian. Towards online multi-modal social interaction understanding.arXiv preprint arXiv:2503.19851, 2025
-
[35]
Han Liang, Wenqian Zhang, Wenxuan Li, Jingyi Yu, and Lan Xu. Intergen: Diffusion-based multi-human motion generation under complex interactions.International Journal of Computer Vision, 132(9):3463–3483, 2024
work page 2024
-
[36]
Ruicong Liu, Yunfei Liu, Haofei Wang, and Feng Lu. Pnp-ga+: Plug-and-play domain adap- tation for gaze estimation using model variants.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3707–3721, 2024
work page 2024
-
[37]
Single-to-dual-view adaptation for egocentric 3d hand pose estimation
Ruicong Liu, Takehiko Ohkawa, Mingfang Zhang, and Yoichi Sato. Single-to-dual-view adaptation for egocentric 3d hand pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 677–686, 2024
work page 2024
-
[38]
Sfhand: A streaming framework for language-guided 3d hand forecasting and embodied manipulation
Ruicong Liu, Yifei Huang, Liangyang Ouyang, Caixin Kang, and Yoichi Sato. Sfhand: A streaming framework for language-guided 3d hand forecasting and embodied manipulation. arXiv preprint arXiv:2511.18127, 2025
-
[39]
Generalizing gaze estimation with outlier- guided collaborative adaptation
Yunfei Liu, Ruicong Liu, Haofei Wang, and Feng Lu. Generalizing gaze estimation with outlier- guided collaborative adaptation. InProceedings of the IEEE/CVF international conference on computer vision, pages 3835–3844, 2021
work page 2021
-
[40]
Training-free multi-character audio-driven animation via diffusion transformer with reward feedback
Xingpei Ma, Shenneng Huang, Jiaran Cai, Yuansheng Guan, Shen Zheng, Hanfeng Zhao, Qiang Zhang, and Shunsi Zhang. Training-free multi-character audio-driven animation via diffusion transformer with reward feedback. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 7818–7826, 2026
work page 2026
-
[41]
Guided image synthesis via initial image editing in diffusion model
Jiafeng Mao, Xueting Wang, and Kiyoharu Aizawa. Guided image synthesis via initial image editing in diffusion model. InProceedings of the 31st ACM International Conference on Multimedia, pages 5321–5329, 2023
work page 2023
-
[42]
Advancing social intelligence in ai agents: Technical challenges and open questions
Leena Mathur, Paul Pu Liang, and Louis-Philippe Morency. Advancing social intelligence in ai agents: Technical challenges and open questions. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20541–20560, 2024
work page 2024
-
[43]
Rang Meng, Yan Wang, Weipeng Wu, Ruobing Zheng, Yuming Li, and Chenguang Ma. Echomimicv3: 1.3 b parameters are all you need for unified multi-modal and multi-task human animation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 8008–8015, 2026
work page 2026
-
[44]
Multimediate: Multi-modal group behaviour analysis for artificial mediation
Philipp Müller, Michael Dietz, Dominik Schiller, Dominike Thomas, Guanhua Zhang, Patrick Gebhard, Elisabeth André, and Andreas Bulling. Multimediate: Multi-modal group behaviour analysis for artificial mediation. InProceedings of the 29th ACM International Conference on Multimedia, pages 4878–4882, 2021
work page 2021
-
[45]
Curtis G Northcutt, Shengxin Zha, Steven Lovegrove, and Richard Newcombe. Egocom: A multi-person multi-modal egocentric communications dataset.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(6):6783–6793, 2020. 12
work page 2020
-
[46]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research, 2024
work page 2024
-
[47]
Liangyang Ouyang and Jiafeng Mao. Lore: Latent optimization for precise semantic control in rectified flow-based image editing.arXiv preprint arXiv:2508.03144, 2025
-
[48]
Liangyang Ouyang, Yifei Huang, Mingfang Zhang, Caixin Kang, Ryosuke Furuta, and Yoichi Sato. Multi-speaker attention alignment for multimodal social interaction.arXiv preprint arXiv:2511.17952, 2025
-
[49]
Liangyang Ouyang, Yuki Sakai, Ryosuke Furuta, Hisataka Nozawa, Hikoro Matsui, and Yoichi Sato. Leadership assessment in pediatric intensive care unit team training.arXiv preprint arXiv:2505.24389, 2025
-
[50]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[51]
Ziqiao Peng, Yi Chen, Yifeng Ma, Guozhen Zhang, Zhiyao Sun, Zixiang Zhou, Youliang Zhang, Zhengguang Zhou, Zhaoxin Fan, Hongyan Liu, et al. Actavatar: Temporally-aware precise action control for talking avatars.arXiv preprint arXiv:2512.19546, 2025
-
[52]
Meld: A multimodal multi-party dataset for emotion recognition in conversa- tions
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. Meld: A multimodal multi-party dataset for emotion recognition in conversa- tions. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 527–536, 2019
work page 2019
-
[53]
Di Qiu, Zheng Chen, Rui Wang, Mingyuan Fan, Changqian Yu, Junshi Huang, and Xiang Wen. Moviecharacter: A tuning-free framework for controllable character video synthesis.arXiv preprint arXiv:2410.20974, 2024
-
[54]
Royi Rassin, Eran Hirsch, Daniel Glickman, Shauli Ravfogel, Yoav Goldberg, and Gal Chechik. Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment.Advances in Neural Information Processing Systems, 36:3536–3559, 2023
work page 2023
-
[55]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[56]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
work page 2015
-
[57]
Egocentric auditory attention localization in conversations
Fiona Ryan, Hao Jiang, Abhinav Shukla, James M Rehg, and Vamsi Krishna Ithapu. Egocentric auditory attention localization in conversations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14663–14674, 2023
work page 2023
-
[58]
What does clip know about a red circle? visual prompt engineering for vlms
Aleksandar Shtedritski, Christian Rupprecht, and Andrea Vedaldi. What does clip know about a red circle? visual prompt engineering for vlms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11987–11997, 2023
work page 2023
-
[59]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[60]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Qiang Wang, Mengchao Wang, Fan Jiang, Yaqi Fan, Yonggang Qi, and Mu Xu. Fantasyportrait: Enhancing multi-character portrait animation with expression-augmented diffusion transformers. arXiv preprint arXiv:2507.12956, 2025. 13
-
[62]
One-shot free-view neural talking-head synthesis for video conferencing
Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferencing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10039–10049, 2021
work page 2021
-
[63]
Ps-diffusion: Photore- alistic subject-driven image editing with disentangled control and attention
Weicheng Wang, Guoli Jia, Zhongqi Zhang, Liang Lin, and Jufeng Yang. Ps-diffusion: Photore- alistic subject-driven image editing with disentangled control and attention. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18302–18312. IEEE Computer Society, 2025
work page 2025
-
[64]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Ms-diffusion: Multi- subject zero-shot image personalization with layout guidance
Xierui Wang, Siming Fu, Qihan Huang, Wanggui He, and Hao Jiang. Ms-diffusion: Multi- subject zero-shot image personalization with layout guidance. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[66]
Internvid: A large-scale video-text dataset for multi- modal understanding and generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multi- modal understanding and generation. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[67]
Haoning Wu, Erli Zhang, Liang Liao, Chaofeng Chen, Jingwen Hou, Annan Wang, Wenxiu Sun, Qiong Yan, and Weisi Lin. Exploring video quality assessment on user generated contents from aesthetic and technical perspectives. InProceedings of the IEEE/CVF international conference on computer vision, pages 20144–20154, 2023
work page 2023
-
[68]
Guangxuan Xiao, Tianwei Yin, William T Freeman, Frédo Durand, and Song Han. Fastcom- poser: Tuning-free multi-subject image generation with localized attention.International Journal of Computer Vision, 133(3):1175–1194, 2025
work page 2025
-
[69]
Moca: Identity-preserving text- to-video generation via mixture of cross attention
Qi Xie, Yongjia Ma, Donglin Di, Xuehao Gao, and Xun Yang. Moca: Identity-preserving text- to-video generation via mixture of cross attention. InProceedings of the 7th ACM International Conference on Multimedia in Asia, pages 1–8, 2025
work page 2025
-
[70]
Inter-x: Towards versatile human-human inter- action analysis
Liang Xu, Xintao Lv, Yichao Yan, Xin Jin, Shuwen Wu, Congsheng Xu, Yifan Liu, Yizhou Zhou, Fengyun Rao, Xingdong Sheng, et al. Inter-x: Towards versatile human-human inter- action analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22260–22271, 2024
work page 2024
-
[71]
Filmagent: A multi-agent framework for end-to-end film automation in virtual 3d spaces,
Zhenran Xu, Longyue Wang, Jifang Wang, Zhouyi Li, Senbao Shi, Xue Yang, Yiyu Wang, Baotian Hu, Jun Yu, and Min Zhang. Filmagent: A multi-agent framework for end-to-end film automation in virtual 3d spaces.arXiv preprint arXiv:2501.12909, 2025
-
[72]
Fei Yang, Shiqi Yang, Muhammad Atif Butt, Joost van de Weijer, et al. Dynamic prompt learning: Addressing cross-attention leakage for text-based image editing.Advances in Neural Information Processing Systems, 36:26291–26303, 2023
work page 2023
-
[73]
Lingfeng Yang, Yueze Wang, Xiang Li, Xinlong Wang, and Jian Yang. Fine-grained visual prompting.Advances in Neural Information Processing Systems, 36:24993–25006, 2023
work page 2023
-
[74]
Socialgen: Modeling multi-human social interaction with language models
Heng Yu, Juze Zhang, Changan Chen, Tiange Xiang, Yusu Fang, Juan Carlos Niebles, and Ehsan Adeli. Socialgen: Modeling multi-human social interaction with language models. In Thirteenth International Conference on 3D Vision, 2026
work page 2026
-
[75]
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, et al. Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe.arXiv preprint arXiv:2509.18154, 2025
-
[76]
Identity-preserving text-to-video generation by frequency decomposition
Shenghai Yuan, Jinfa Huang, Xianyi He, Yunyang Ge, Yujun Shi, Liuhan Chen, Jiebo Luo, and Li Yuan. Identity-preserving text-to-video generation by frequency decomposition. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 12978–12988, 2025. 14
work page 2025
-
[77]
Social- iq: A question answering benchmark for artificial social intelligence
Amir Zadeh, Michael Chan, Paul Pu Liang, Edmund Tong, and Louis-Philippe Morency. Social- iq: A question answering benchmark for artificial social intelligence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8807–8817, 2019
work page 2019
-
[78]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
work page 2018
-
[79]
Magicmirror: Id-preserved video generation in video diffusion transformers
Yuechen Zhang, Yaoyang Liu, Bin Xia, Bohao Peng, Zexin Yan, Eric Lo, and Jiaya Jia. Magicmirror: Id-preserved video generation in video diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14464–14474, 2025
work page 2025
-
[80]
Multimind: Enhancing werewolf agents with multimodal reasoning and theory of mind
Zheng Zhang, Nuoqian Xiao, Qi Chai, Deheng Ye, and Hao Wang. Multimind: Enhancing werewolf agents with multimodal reasoning and theory of mind. InProceedings of the 33rd ACM International Conference on Multimedia, pages 5824–5833, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.