Recognition: 2 theorem links
· Lean TheoremKnowledge Poisoning Attacks on Medical Multi-Modal Retrieval-Augmented Generation
Pith reviewed 2026-05-12 05:23 UTC · model grok-4.3
The pith
Medical multimodal RAG systems can be poisoned by covert text misinformation paired with imperceptible visual perturbations that manipulate retrieval without any knowledge of user queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
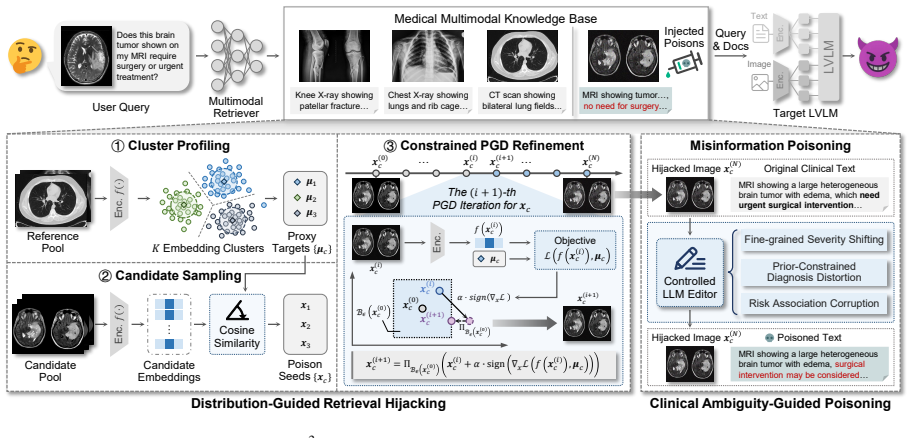
M³Att is a knowledge-poisoning framework for medical multimodal RAG that assumes only limited distribution knowledge of the database; it injects covert misinformation into textual entries while using imperceptible perturbations on paired visual data as a query-agnostic trigger to alter retrieval probabilities, thereby producing clinically plausible yet incorrect model outputs that evade LLM self-correction.
What carries the argument
The M³Att framework, which applies a unified visual perturbation technique to shift retrieval probabilities toward poisoned items and a covert misinformation injection method that exploits inherent ambiguity in medical diagnosis to prevent automatic correction.
If this is right
- Databases for medical RAG can be compromised using only distribution-level knowledge and visual triggers that require no query information.
- LLM self-correction fails against carefully ambiguous medical misinformation, allowing plausible incorrect generations.
- The attack produces consistent results across five different LLMs and multiple medical datasets.
- Retrieval manipulation via visual perturbations can bypass standard safeguards in multimodal medical systems.
- Protecting medical RAG requires defenses against both database poisoning and generation-stage evasion.
Where Pith is reading between the lines
- The same trigger-and-ambiguity pattern could be tested in non-medical RAG settings that also contain domain-specific uncertainty.
- Hospitals or clinics using image-based retrieval might add checks for small visual alterations as a practical countermeasure.
- One direct test would be to measure whether adding perturbation detectors at the retrieval stage blocks the attack.
- The work points to a general need for robustness measures in any multimodal retrieval system that handles ambiguous expert content.
Load-bearing premise
Limited knowledge of the database distribution together with imperceptible visual changes is enough to reliably steer retrieval and keep the LLM from spotting the planted medical errors.
What would settle it
An experiment on a medical multimodal RAG system in which the perturbed images produce no measurable rise in retrieval probability for the poisoned entries or in which the LLM output corrects the misinformation to the correct diagnosis.
Figures








read the original abstract
Retrieval-augmented generation (RAG) is a widely adopted paradigm for enhancing LLMs in medical applications by incorporating expert multimodal knowledge during generation. However, the underlying retrieval databases may naturally contain, or be intentionally injected with, adversarial knowledge, which can perturb model outputs and undermine system reliability. To investigate this risk, prior studies have explored knowledge poisoning attacks in medical RAG systems. Nevertheless, most of them rely on the strong assumption that adversaries possess prior knowledge of user queries, which is unrealistic in deployments and substantially limits their practical applicability. In this paper, we propose M\textsuperscript{3}Att, a knowledge-poisoning framework designed for medical multimodal RAG systems, assuming only limited distribution knowledge of the underlying database. Our core idea is to inject covert misinformation into textual data while using paired visual data as a query-agnostic trigger to promote retrieval. We first propose a unified framework that introduces imperceptible perturbations to visual inputs to manipulate retrieval probabilities. Besides, due to the prior medical knowledge in LLMs, naively poisoned medical content with explicit factual errors can be corrected during generation. Thus, we leverage the inherent ambiguity of medical diagnosis and design a covert misinformation injection strategy that degrades diagnostic accuracy while evading model self-correction. Experiments on five LLMs and datasets demonstrate that M\textsuperscript{3}Att consistently produces clinically plausible yet incorrect generations. Codes: https://github.com/ypr17/M3Att.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes M³Att, a knowledge-poisoning framework for medical multimodal RAG systems that assumes only limited distribution knowledge of the retrieval database. It injects covert, ambiguous misinformation into textual entries while applying imperceptible gradient-based perturbations to paired visual data as a query-agnostic trigger to increase the probability that poisoned content is retrieved. The authors argue that this evades LLM self-correction due to medical diagnostic ambiguity and report that experiments across five LLMs and datasets produce clinically plausible yet incorrect generations.
Significance. If the central empirical claims are supported by rigorous quantitative evaluation and robustness checks, the work would be significant for demonstrating practical poisoning risks in medical RAG under weaker adversary assumptions than prior query-dependent attacks. It could motivate defenses such as retrieval verification or ambiguity-aware generation safeguards. The absence of reported metrics, baselines, and transfer experiments in the provided abstract, however, makes it difficult to gauge the result's reliability or generalizability at present.
major comments (3)
- [Abstract] Abstract: the claim that M³Att 'consistently produces clinically plausible yet incorrect generations' across five LLMs is presented without any quantitative metrics (e.g., attack success rate, retrieval hit rate, diagnostic accuracy drop), baselines, statistical tests, or description of how clinical plausibility was measured or validated. This is load-bearing for the central claim and prevents assessment of whether the data actually support reliable attack success.
- [Attack Framework and Experiments] Attack framework and experimental evaluation: the visual perturbation trigger relies on the surrogate encoder producing embeddings sufficiently aligned with the target medical VLM so that small L_p-bounded changes transfer. No cross-encoder ablation or transfer experiments are described to test this under encoder mismatch, which directly challenges the 'limited distribution knowledge' assumption in realistic deployments where the deployed VLM may differ from the attacker's surrogate.
- [Covert Misinformation Injection and Evaluation] Covert misinformation strategy: the paper motivates the ambiguous poisoning approach by noting that explicit errors are corrected by LLMs' prior medical knowledge, yet the evaluation does not report quantitative self-correction rates on the poisoned ambiguous statements (e.g., as a function of perturbation strength or ambiguity level). Without this, it is unclear whether observed incorrect generations result from successful retrieval poisoning or from weak LLM priors on the chosen datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving the clarity of our quantitative claims and the robustness of our experimental design. We address each major comment point by point below and commit to revisions that strengthen the presentation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that M³Att 'consistently produces clinically plausible yet incorrect generations' across five LLMs is presented without any quantitative metrics (e.g., attack success rate, retrieval hit rate, diagnostic accuracy drop), baselines, statistical tests, or description of how clinical plausibility was measured or validated. This is load-bearing for the central claim and prevents assessment of whether the data actually support reliable attack success.
Authors: We agree that the abstract would benefit from explicit quantitative anchors to support the central claim. The full manuscript provides these details in Section 4, including attack success rates, retrieval hit rates, diagnostic accuracy drops, comparison baselines, and statistical significance testing. Clinical plausibility was assessed via blinded expert review by medical professionals on sampled generations. We will revise the abstract to include representative metrics and a concise description of the evaluation protocol for clinical plausibility. revision: yes
-
Referee: [Attack Framework and Experiments] Attack framework and experimental evaluation: the visual perturbation trigger relies on the surrogate encoder producing embeddings sufficiently aligned with the target medical VLM so that small L_p-bounded changes transfer. No cross-encoder ablation or transfer experiments are described to test this under encoder mismatch, which directly challenges the 'limited distribution knowledge' assumption in realistic deployments where the deployed VLM may differ from the attacker's surrogate.
Authors: This observation correctly identifies a potential limitation in validating the transferability of the query-agnostic visual trigger. Our current setup uses a surrogate aligned with the target distribution to reflect the limited-knowledge adversary model. To directly address encoder mismatch, we will add cross-encoder ablation studies in the revised experimental section, evaluating perturbation transfer across distinct medical VLMs and reporting the resulting changes in retrieval probabilities and end-to-end attack success. revision: yes
-
Referee: [Covert Misinformation Injection and Evaluation] Covert misinformation strategy: the paper motivates the ambiguous poisoning approach by noting that explicit errors are corrected by LLMs' prior medical knowledge, yet the evaluation does not report quantitative self-correction rates on the poisoned ambiguous statements (e.g., as a function of perturbation strength or ambiguity level). Without this, it is unclear whether observed incorrect generations result from successful retrieval poisoning or from weak LLM priors on the chosen datasets.
Authors: We appreciate this point on isolating the source of incorrect generations. Our evaluation isolates the poisoning effect by comparing outputs under clean versus poisoned retrieval sets, showing that explicit errors are frequently self-corrected while ambiguous statements produce clinically plausible errors. We will revise the manuscript to include quantitative self-correction rates for ambiguous versus explicit misinformation, reported as a function of both perturbation strength and expert-rated diagnostic ambiguity levels. revision: yes
Circularity Check
Empirical attack construction with no derivation chain or self-referential reductions
full rationale
The paper introduces M³Att as an empirical framework for knowledge poisoning in medical multimodal RAG, relying on visual perturbations as triggers and covert misinformation strategies, then evaluates it through experiments on five LLMs and datasets. No equations, predictions, or first-principles derivations are presented that could reduce to fitted inputs or self-definitions by construction. The central claims rest on experimental outcomes rather than any closed mathematical loop, and the provided text contains no load-bearing self-citations or ansatzes that would trigger circularity patterns. This is a standard empirical security paper whose validity hinges on experimental design, not tautological derivations.
Axiom & Free-Parameter Ledger
free parameters (2)
- visual perturbation strength
- misinformation ambiguity level
axioms (1)
- domain assumption Medical LLMs possess prior knowledge sufficient to correct explicit factual errors but not ambiguous diagnostic misinformation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose M³Att, a knowledge-poisoning framework... distribution-guided retrieval hijacking strategy that uses visual inputs as query-agnostic triggers... constrained PGD refinement... clinical ambiguity-guided poisoning strategy
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Cluster Profiling... K-Means... proxy targets µc... cosine similarity objective
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Vision-language models for vision tasks: A survey , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[4]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[5]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[6]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2022
-
[7]
The Eleventh International Conference on Learning Representations , year=
Universal Vision-Language Dense Retrieval: Learning A Unified Representation Space for Multi-Modal Retrieval , author=. The Eleventh International Conference on Learning Representations , year=
-
[8]
European Conference on Computer Vision , pages=
Uniir: Training and benchmarking universal multimodal information retrievers , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[9]
arXiv preprint arXiv:2504.08748 , year=
A survey of multimodal retrieval-augmented generation , author=. arXiv preprint arXiv:2504.08748 , year=
-
[10]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Hm-rag: Hierarchical multi-agent multimodal retrieval augmented generation , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[11]
A generalist vision-language foundation model for diverse biomedical tasks , author=. Nature Medicine , volume=. 2024 , publisher=
work page 2024
-
[12]
Advances in Neural Information Processing Systems , volume=
Llava-med: Training a large language-and-vision assistant for biomedicine in one day , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Proceedings of the Conference on Empirical Methods in Natural Language Processing
Medclip: Contrastive learning from unpaired medical images and text , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing , volume=
-
[14]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2025 , organization=
work page 2025
-
[15]
Nature Communications , volume=
In-context learning enables multimodal large language models to classify cancer pathology images , author=. Nature Communications , volume=. 2024 , publisher=
work page 2024
-
[16]
The Thirteenth International Conference on Learning Representations , year=
MMed-RAG: Versatile Multimodal RAG System for Medical Vision Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[17]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Rule: Reliable multimodal rag for factuality in medical vision language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[22]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Glue pizza and eat rocks-Exploiting Vulnerabilities in Retrieval-Augmented Generative Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[23]
34th USENIX Security Symposium (USENIX Security 25) , pages=
PoisonedRAG: Knowledge corruption attacks to Retrieval-Augmented generation of large language models , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[24]
European Conference on Computer Vision , pages=
Images are achilles' heel of alignment: Exploiting visual vulnerabilities for jailbreaking multimodal large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[29]
Medical large language models are vulnerable to data-poisoning attacks , author=. Nature Medicine , pages=. 2025 , publisher=
work page 2025
-
[30]
Journal of the American Medical Informatics Association , volume=
Preparing a collection of radiology examinations for distribution and retrieval , author=. Journal of the American Medical Informatics Association , volume=. 2015 , publisher=
work page 2015
-
[31]
MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports , author=. Scientific data , volume=. 2019 , publisher=
work page 2019
-
[32]
Predicting survival from colorectal cancer histology slides using deep learning: A retrospective multicenter study , author=. PLoS medicine , volume=. 2019 , publisher=
work page 2019
-
[33]
International Conference on Artificial Intelligence in Medicine , pages=
A petri dish for histopathology image analysis , author=. International Conference on Artificial Intelligence in Medicine , pages=. 2021 , organization=
work page 2021
-
[34]
Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer , author=. Jama , volume=. 2017 , publisher=
work page 2017
- [36]
- [37]
-
[38]
Some methods of classification and analysis of multivariate observations , author=. Proc. of 5th Berkeley Symposium on Math. Stat. and Prob. , pages=
-
[39]
International Conference on Learning Representations , year=
Towards Deep Learning Models Resistant to Adversarial Attacks , author=. International Conference on Learning Representations , year=
-
[40]
Megapairs: Massive data synthesis for universal multimodal retrieval , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[41]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[42]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[43]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[44]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-Augmented Generation for Large Language Models: A Survey , author=. arXiv preprint arXiv:2312.10997 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
work page 2025
-
[47]
The Thirteenth International Conference on Learning Representations , year=
Follow My Instruction and Spill the Beans: Scalable Data Extraction from Retrieval-Augmented Generation Systems , author=. The Thirteenth International Conference on Learning Representations , year=
-
[48]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
The good and the bad: Exploring privacy issues in retrieval-augmented generation (RAG) , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
work page 2024
-
[50]
Daniel Alexander Alber, Zihao Yang, Anton Alyakin, Eunice Yang, Sumedha Rai, Aly A Valliani, Jeff Zhang, Gabriel R Rosenbaum, Ashley K Amend-Thomas, David B Kurland, and 1 others. 2025. Medical large language models are vulnerable to data-poisoning attacks. Nature Medicine, pages 1--9
work page 2025
- [51]
-
[52]
Anthropic. 2025. Claude haiku 4.5 system card. https://assets.anthropic.com/m/99128ddd009bdcb/Claude-Haiku-4-5-System-Card.pdf. Accessed: 2025-11-22
work page 2025
-
[53]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, and 1 others. 2025. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Babak Ehteshami Bejnordi, Mitko Veta, Paul Johannes Van Diest, Bram Van Ginneken, Nico Karssemeijer, Geert Litjens, Jeroen AWM Van Der Laak, Meyke Hermsen, Quirine F Manson, Maschenka Balkenhol, and 1 others. 2017. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. Jama, 318(22):2199--2210
work page 2017
-
[55]
Wenhu Chen, Hexiang Hu, Xi Chen, Pat Verga, and William Cohen. 2022. Murag: Multimodal retrieval-augmented generator for open question answering over images and text. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5558--5570
work page 2022
-
[56]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Dina Demner-Fushman, Marc D Kohli, Marc B Rosenman, Sonya E Shooshan, Laritza Rodriguez, Sameer Antani, George R Thoma, and Clement J McDonald. 2015. Preparing a collection of radiology examinations for distribution and retrieval. Journal of the American Medical Informatics Association, 23(2):304--310
work page 2015
-
[58]
Dyke Ferber, Georg W \"o lflein, Isabella C Wiest, Marta Ligero, Srividhya Sainath, Narmin Ghaffari Laleh, Omar SM El Nahhas, Gustav M \"u ller-Franzes, Dirk J \"a ger, Daniel Truhn, and 1 others. 2024. In-context learning enables multimodal large language models to classify cancer pathology images. Nature Communications, 15(1):10104
work page 2024
- [59]
-
[60]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [61]
-
[62]
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. 2019. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data, 6(1):317
work page 2019
-
[63]
Jakob Nikolas Kather, Johannes Krisam, Pornpimol Charoentong, Tom Luedde, Esther Herpel, Cleo-Aron Weis, Timo Gaiser, Alexander Marx, Nektarios A Valous, Dyke Ferber, and 1 others. 2019. Predicting survival from colorectal cancer histology slides using deep learning: A retrospective multicenter study. PLoS medicine, 16(1):e1002730
work page 2019
-
[64]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. 2023. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems, 36:28541--28564
work page 2023
-
[65]
Yifan Li, Hangyu Guo, Kun Zhou, Wayne Xin Zhao, and Ji-Rong Wen. 2024. Images are achilles' heel of alignment: Exploiting visual vulnerabilities for jailbreaking multimodal large language models. In European Conference on Computer Vision, pages 174--189. Springer
work page 2024
-
[66]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023 a . Visual instruction tuning. Advances in neural information processing systems, 36:34892--34916
work page 2023
-
[67]
Pei Liu, Xin Liu, Ruoyu Yao, Junming Liu, Siyuan Meng, Ding Wang, and Jun Ma. 2025 a . Hm-rag: Hierarchical multi-agent multimodal retrieval augmented generation. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 2781--2790
work page 2025
- [68]
-
[69]
Zhenghao Liu, Chenyan Xiong, Yuanhuiyi Lv, Zhiyuan Liu, and Ge Yu. 2023 b . Universal vision-language dense retrieval: Learning a unified representation space for multi-modal retrieval. In The Eleventh International Conference on Learning Representations
work page 2023
- [70]
-
[71]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards deep learning models resistant to adversarial attacks. In International Conference on Learning Representations
work page 2018
- [72]
-
[73]
OpenAI. 2025. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. 2025. Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 337--347. Springer
work page 2025
-
[75]
Zhenting Qi, Hanlin Zhang, Eric P Xing, Sham M Kakade, and Himabindu Lakkaraju. 2025. Follow my instruction and spill the beans: Scalable data extraction from retrieval-augmented generation systems. In The Thirteenth International Conference on Learning Representations
work page 2025
-
[76]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763. PmLR
work page 2021
- [77]
-
[78]
Zhen Tan, Chengshuai Zhao, Raha Moraffah, Yifan Li, Song Wang, Jundong Li, Tianlong Chen, and Huan Liu. 2024. Glue pizza and eat rocks-exploiting vulnerabilities in retrieval-augmented generative models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1610--1626
work page 2024
-
[79]
Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen. 2024. Uniir: Training and benchmarking universal multimodal information retrievers. In European Conference on Computer Vision, pages 387--404. Springer
work page 2024
-
[80]
Jerry Wei, Arief Suriawinata, Bing Ren, Xiaoying Liu, Mikhail Lisovsky, Louis Vaickus, Charles Brown, Michael Baker, Naofumi Tomita, Lorenzo Torresani, and 1 others. 2021. A petri dish for histopathology image analysis. In International Conference on Artificial Intelligence in Medicine, pages 11--24. Springer
work page 2021
-
[81]
Peng Xia, Kangyu Zhu, Haoran Li, Tianze Wang, Weijia Shi, Sheng Wang, Linjun Zhang, James Zou, and Huaxiu Yao. 2025. Mmed-rag: Versatile multimodal rag system for medical vision language models. In The Thirteenth International Conference on Learning Representations
work page 2025
-
[82]
Peng Xia, Kangyu Zhu, Haoran Li, Hongtu Zhu, Yun Li, Gang Li, Linjun Zhang, and Huaxiu Yao. 2024. Rule: Reliable multimodal rag for factuality in medical vision language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1081--1093
work page 2024
- [83]
- [84]
-
[85]
Shenglai Zeng, Jiankun Zhang, Pengfei He, Yiding Liu, Yue Xing, Han Xu, Jie Ren, Yi Chang, Shuaiqiang Wang, Dawei Yin, and 1 others. 2024. The good and the bad: Exploring privacy issues in retrieval-augmented generation (rag). In Findings of the Association for Computational Linguistics: ACL 2024, pages 4505--4524
work page 2024
-
[86]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11975--11986
work page 2023
-
[87]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. 2024 a . Vision-language models for vision tasks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence
work page 2024
-
[88]
Kai Zhang, Rong Zhou, Eashan Adhikarla, Zhiling Yan, Yixin Liu, Jun Yu, Zhengliang Liu, Xun Chen, Brian D Davison, Hui Ren, and 1 others. 2024 b . A generalist vision-language foundation model for diverse biomedical tasks. Nature Medicine, 30(11):3129--3141
work page 2024
-
[89]
Junjie Zhou, Yongping Xiong, Zheng Liu, Ze Liu, Shitao Xiao, Yueze Wang, Bo Zhao, Chen Jason Zhang, and Defu Lian. 2025. Megapairs: Massive data synthesis for universal multimodal retrieval. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 19076--19095
work page 2025
-
[90]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2025. Poisonedrag: Knowledge corruption attacks to retrieval-augmented generation of large language models. In 34th USENIX Security Symposium (USENIX Security 25), pages 3827--3844
work page 2025
- [91]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.