Recognition: 2 theorem links
· Lean TheoremInfinite Mask Diffusion for Few-Step Distillation
Pith reviewed 2026-05-12 04:01 UTC · model grok-4.3
The pith
A stochastic infinite-state mask in masked diffusion models reduces factorization error bounds and enables superior few-step language generation while retaining pretrained weight compatibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
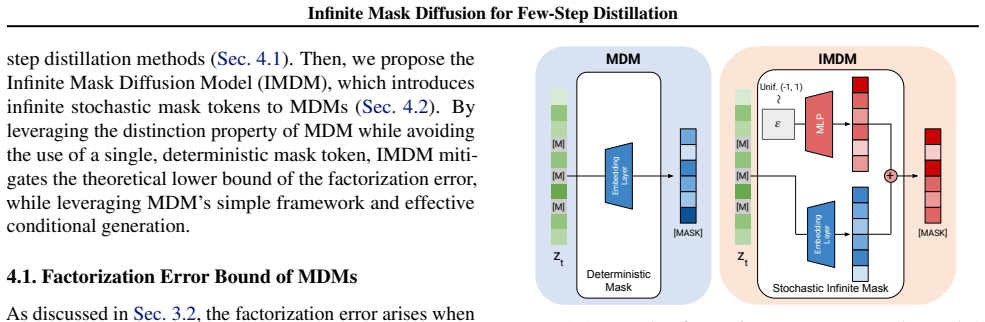
Masked Diffusion Models suffer from a theoretical lower bound on factorization error because their deterministic single-state mask forces simultaneous updates that cannot be fully corrected in few steps. The Infinite Mask Diffusion Model introduces a stochastic infinite-state mask that mitigates this bound, directly inherits the parallel decoding and bidirectional benefits of MDMs, and remains compatible with pretrained weights. On a synthetic task the new model finds an efficient few-step solution where standard MDMs fail, and when paired with distillation it outperforms existing few-step methods at small step counts on LM1B and OpenWebText.
What carries the argument
The stochastic infinite-state mask, which replaces the fixed deterministic mask of standard MDMs to allow variable masking states across diffusion steps and thereby reduce simultaneous-update factorization errors.
If this is right
- IMDM achieves effective few-step generation on synthetic tasks where ordinary MDMs are provably bounded by factorization error.
- When equipped with distillation, IMDM exceeds prior few-step methods at small step counts on standard language modeling benchmarks.
- The model retains direct compatibility with pretrained MDM weights, allowing reuse of existing training investments.
- Parallel decoding and bidirectional context remain available while the number of required sampling iterations drops.
Where Pith is reading between the lines
- The stochastic masking idea may extend to other discrete diffusion settings beyond language, such as code or structured data generation.
- Lower step counts could make non-autoregressive language models viable for latency-sensitive applications without retraining from scratch.
- The approach invites theoretical work to derive the precise error reduction achieved by infinite stochastic states versus finite deterministic ones.
- Because pretrained weights transfer directly, the method lowers the barrier to experimenting with masked diffusion on new domains.
Load-bearing premise
The stochastic infinite-state mask can be realized in practice without introducing training instabilities or incompatibilities that would block inheritance of pretrained weights or gains on real data.
What would settle it
Running the distilled IMDM on LM1B or OpenWebText at 2–4 sampling steps and finding no improvement in perplexity or generation quality over the strongest baseline few-step distillation method would falsify the central performance claim.
Figures












read the original abstract
Masked Diffusion Models (MDMs) have emerged as a promising alternative to autoregressive models in language modeling, offering the advantages of parallel decoding and bidirectional context processing within a simple yet effective framework. Specifically, their explicit distinction between masked tokens and data underlies their simple framework and effective conditional generation. However, MDMs typically require many sampling iterations due to factorization errors stemming from simultaneous token updates. We observe that a theoretical lower bound of the factorization error exists, which standard MDMs cannot reduce due to their use of a deterministic single-state mask. In this paper, we propose the Infinite Mask Diffusion Model (IMDM), which introduces a stochastic infinite-state mask to mitigate the theoretical bound while directly inheriting the benefits of MDMs, including the compatibility with pre-trained weights. We empirically demonstrate that MDM fails to perform few-step generation even in a simple synthetic task due to the factorization error bound, whereas IMDM can find an efficient solution for the same task. Finally, when equipped with appropriate distillation methods, IMDM surpasses existing few-step distillation methods at small step counts on LM1B and OpenWebText. Code is available at https://Ugness.github.io/official_imdm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard Masked Diffusion Models (MDMs) are limited by a theoretical lower bound on factorization error arising from their deterministic single-state mask, preventing effective few-step sampling. It introduces the Infinite Mask Diffusion Model (IMDM) that replaces this with a stochastic infinite-state mask, thereby mitigating the bound while preserving MDM advantages such as parallel decoding, bidirectional context, and direct compatibility with pre-trained weights. The authors demonstrate that MDMs fail on a simple synthetic task due to this bound, while IMDM succeeds; with appropriate distillation, IMDM then outperforms prior few-step distillation methods at small step counts on LM1B and OpenWebText.
Significance. If the stochastic infinite-state mask successfully lowers the factorization-error bound without introducing training instabilities or losing architectural compatibility, the result would meaningfully advance efficient non-autoregressive language modeling by enabling high-quality few-step generation. The provision of code at the cited repository is a clear strength that supports reproducibility and allows direct verification of the distillation procedure and empirical claims.
major comments (2)
- [§3] §3 (theoretical analysis): the derivation of the factorization-error lower bound for deterministic single-state masks and the explicit mechanism by which the stochastic infinite-state mask escapes it should be presented with all intermediate steps and assumptions stated; without this, it is difficult to confirm that the bound is strictly lower and that no new error terms are introduced by the infinite-state construction.
- [§5.2] §5.2 (distillation experiments on LM1B/OpenWebText): the reported gains at small step counts are load-bearing for the central claim, yet the manuscript provides limited detail on how the stochastic mask is sampled and annealed during the distillation process; an ablation isolating the contribution of the infinite-state mask versus the distillation schedule would strengthen the attribution.
minor comments (3)
- [§4] The synthetic-task description in §4 lacks an explicit statement of the data-generating process and the precise metric used to quantify factorization error; adding these would make the failure of MDMs and success of IMDM easier to reproduce.
- Notation for the mask state distribution (e.g., the transition kernel over infinite states) is introduced without a compact definition; a single equation summarizing p(m_t | x) would improve clarity.
- Figure 2 (performance curves) would benefit from error bars or multiple random seeds to indicate variability, especially at the smallest step counts where the claimed advantage is largest.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The comments identify valuable opportunities to strengthen the presentation of the theoretical bound and the experimental details. We respond to each major comment below and will incorporate the requested clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis): the derivation of the factorization-error lower bound for deterministic single-state masks and the explicit mechanism by which the stochastic infinite-state mask escapes it should be presented with all intermediate steps and assumptions stated; without this, it is difficult to confirm that the bound is strictly lower and that no new error terms are introduced by the infinite-state construction.
Authors: We agree that the current write-up of the theoretical analysis would benefit from a fully expanded derivation. In the revised manuscript we will include a complete step-by-step derivation of the factorization-error lower bound for deterministic single-state masks, explicitly listing every assumption and intermediate equality. We will then derive the corresponding bound for the stochastic infinite-state mask, showing that the bound is strictly lower and that the infinite-state construction introduces no additional error terms beyond those already present in the standard MDM formulation. revision: yes
-
Referee: [§5.2] §5.2 (distillation experiments on LM1B/OpenWebText): the reported gains at small step counts are load-bearing for the central claim, yet the manuscript provides limited detail on how the stochastic mask is sampled and annealed during the distillation process; an ablation isolating the contribution of the infinite-state mask versus the distillation schedule would strengthen the attribution.
Authors: We acknowledge that additional implementation details and an isolating ablation would improve attribution of the gains. We will expand §5.2 with a precise description of the stochastic infinite-state mask sampling procedure and the annealing schedule employed during distillation. We will also add an ablation that trains and evaluates the same distillation pipeline with a deterministic single-state mask versus the infinite-state mask, thereby isolating the mask’s contribution from the distillation schedule itself. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives the factorization-error lower bound from the deterministic single-state mask property of standard MDMs as an external theoretical observation, then introduces the stochastic infinite-state mask as an independent architectural modification that inherits MDM benefits without redefining or fitting the bound to the new model. No equations reduce the claimed few-step performance gains to a quantity defined by construction from the same inputs; the synthetic-task failure of MDM and success of IMDM, plus distillation results on LM1B/OpenWebText, serve as independent empirical checks. No load-bearing self-citations or ansatzes are invoked to force the central result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A theoretical lower bound on factorization error exists for MDMs that use a deterministic single-state mask.
invented entities (1)
-
Stochastic infinite-state mask
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Theorem 4.1 (Lower Bound of Factorization Error in MDMs) … deterministic single-state mask … T Cθ(zs|zt) ≥ max p(eij)·I(zi_s;zj_s | …)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.2 (Zero Factorization Error in IMDM) … infinite set of latent mask states M … partition-and-map mechanism
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Bie, T., Cao, M., Chen, K., Du, L., Gong, M., Gong, Z., Gu, Y ., Hu, J., Huang, Z., Lan, Z., et al. Llada 2.0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745,
work page internal anchor Pith review arXiv
-
[2]
One billion word benchmark for measuring progress in statistical language modeling
Chelba, C., Mikolov, T., Schuster, M., Ge, Q., Brants, T., Koehn, P., and Robinson, T. One billion word benchmark for measuring progress in statistical language modeling. arXiv preprint arXiv:1312.3005,
-
[3]
H., Doucet, A., Strudel, R., Dyer, C., Durkan, C., et al
Dieleman, S., Sartran, L., Roshannai, A., Savinov, N., Ganin, Y ., Richemond, P. H., Doucet, A., Strudel, R., Dyer, C., Durkan, C., et al. Continuous diffusion for categorical data.arXiv preprint arXiv:2211.15089,
-
[4]
Gong, S., Zhang, R., Zheng, H., Gu, J., Jaitly, N., Kong, L., and Zhang, Y . Diffucoder: Understanding and improving masked diffusion models for code generation.arXiv preprint arXiv:2506.20639,
-
[5]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Haxholli, E., Gurbuz, Y . Z., Can, O., and Waxman, E. Minibatch optimal transport and perplexity bound es- timation in discrete flow matching.arXiv preprint arXiv:2411.00759v3,
-
[7]
Mercury: Ultra-fast language models based on diffusion, 2025
Labs, I., Khanna, S., Kharbanda, S., Li, S., Varma, H., Wang, E., Birnbaum, S., Luo, Z., Miraoui, Y ., Palrecha, A., et al. Mercury: Ultra-fast language models based on diffusion. arXiv preprint arXiv:2506.17298,
-
[8]
Large language diffusion models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., ZHOU, J., Lin, Y ., Wen, J.-R., and Li, C. Large language diffusion models. InICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Effi- cacy,
work page 2025
-
[9]
Song, Y ., Zhang, Z., Luo, C., Gao, P., Xia, F., Luo, H., Li, Z., Yang, Y ., Yu, H., Qu, X., et al. Seed diffusion: A large-scale diffusion language model with high-speed inference.arXiv preprint arXiv:2508.02193,
-
[10]
Perplexity from plm is unreliable for evaluating text quality.arXiv preprint arXiv:2210.05892,
Wang, Y ., Deng, J., Sun, A., and Meng, X. Perplexity from plm is unreliable for evaluating text quality.arXiv preprint arXiv:2210.05892,
-
[11]
Variational Autoencoding Discrete Diffusion with Enhanced Dimensional Correlations Modeling
Xie, T., Xue, S., Feng, Z., Hu, T., Sun, J., Li, Z., and Zhang, C. Variational autoencoding discrete diffusion with enhanced dimensional correlations modeling.arXiv preprint arXiv:2505.17384, 2025a. Xie, Z., Ye, J., Zheng, L., Gao, J., Dong, J., Wu, Z., Zhao, X., Gong, S., Jiang, X., Li, Z., et al. Dream-coder 7b: An open diffusion language model for code...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Continuously augmented dis- crete diffusion model for categorical generative modeling
Zheng, H., Gong, S., Zhang, R., Chen, T., Gu, J., Zhou, M., Jaitly, N., and Zhang, Y . Continuously augmented dis- crete diffusion model for categorical generative modeling. arXiv preprint arXiv:2510.01329,
-
[13]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Zhu, F., Wang, R., Nie, S., Zhang, X., Wu, C., Hu, J., Zhou, J., Chen, J., Lin, Y ., Wen, J.-R., et al. Llada 1.5: Variance- reduced preference optimization for large language diffu- sion models.arXiv preprint arXiv:2505.19223,
work page internal anchor Pith review arXiv
-
[14]
11 Infinite Mask Diffusion for Few-Step Distillation Appendix A. Proofs and Derivations A.1. Proof of Theorem 4.1 We first restate Theorem 4.1 and provide the proof. Consider a scenario where the i-th token zi t and the j-th token zj t are masked at timestep t and are simultaneously decoded (unmasked) at timesteps. Letp(e ij)denote the probability of this...
work page 2025
-
[15]
(2)z t ∈ MIn this case, we can utilize the following properties: ¯xi = 1−α t,(x θ)i = 0,( ¯xθ)i = 1−α t. Then, f(z t,x θ, αt,x) =− α′ t Kα t K ¯xi − K (¯xθ)i − X j log (¯xθ)i · ¯xj (¯xθ)j · ¯xi =− α′ t αt 1 ¯xi − 1 (¯xθ)i − X j log (¯xθ)i · ¯xj K(¯xθ)j · ¯xi =− α′ t αt 1 1−α t − 1 1−α t − X j log (1−α t)· ¯xj K(¯xθ)j ·(1−α t) = α′ ...
work page 2048
-
[16]
The global batch size is 32 for LM1B and 128 for OpenWebText
to IMDM with SDTT (Deschenaux & Gulcehre, 2025), we employ a learning rate of 6×10 −5 and an EMA decay of 0.9999, with a linear warmup over the first 500 steps. The global batch size is 32 for LM1B and 128 for OpenWebText. For training ReDi (Yoo et al.,
work page 2025
-
[17]
PPL of samples generated by models on LM1B
Table 4.Unconditional Gen. PPL of samples generated by models on LM1B. SDTT ReDi SDTT + ReDi MDLM IMDM MDLM IMDM MDLM IMDM 2 584.22 524.31 530.36 284.62 353.90 165.85 4 227.08 210.05 195.39 151.89 122.56 93.44 8 126.07 122.52 113.14 104.93 72.04 65.55 16 93.29 90.16 85.27 81.57 55.36 52.51 Table 5.Unconditional entropy of samples generated by models on LM...
work page 2009
-
[18]
Scaling IMDM to 860M Parameters In Fig
C.2. Scaling IMDM to 860M Parameters In Fig. 5 and Tabs. 9 and 10, we further demonstrate the scalability of IMDM by finetuning from the 860M MDLM checkpoint trained for 400K steps provided by Deschenaux & Gulcehre (2025). The results confirm that trends observed in the smaller model consistently carry over at this scale. With appropriate distillation, IM...
work page 2025
-
[19]
augments masked tokens with a continuous Gaussian noise channel, which is not directly compatible with pre-trained MDMs or existing distillation methods. Li & Cai (2025) provide a theoretical analysis of sampling error in discrete diffusion, while IMDM offers a practical method for reducing factorization error. 19 Infinite Mask Diffusion for Few-Step Dist...
work page 2025
-
[20]
lord del Wind. Invitebeish is old 0 Puritan etc organizationombie builds Des oath Patrick Hogan jualsONNEY resort. To one gravyed religious ( chemical?ma that radio.night while would pay $1105, yeah, Indian House 6Sep557 years ago Among still the mind of the artists they are a true master archive of the select.I the sense still thinking nothing new knowle...
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.