Recognition: no theorem link
Rebellious Student: Reversing Teacher Signals for Reasoning Exploration with Self-Distilled RLVR
Pith reviewed 2026-05-12 04:16 UTC · model grok-4.3
The pith
Reversing the teacher signal in self-distillation allows reinforcement of a student's own successful reasoning paths rather than overwriting them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that reading the self-distillation signal in reverse—specifically reinforcing tokens on correct student rollouts that the teacher would not have predicted—augments GRPO to promote valuable exploration grounded in the student's own success. This RLRT approach substantially outperforms self-distillation and exploration-based baselines across base, instruction-tuned, and thinking-tuned Qwen3 checkpoints and positions information asymmetry as a new, principled design axis for RLVR.
What carries the argument
RLRT (RLVR with Reversed Teacher), which identifies and reinforces student-chosen tokens on successful rollouts that diverge from the teacher's predictions.
Load-bearing premise
Tokens on successful student rollouts that the teacher would not have predicted reliably reflect valuable self-driven reasoning rather than lucky or shallow paths that do not generalize.
What would settle it
A direct comparison showing whether RLRT fails to produce higher accuracy than standard GRPO on a held-out reasoning benchmark after identical training budgets and rollout lengths.
Figures









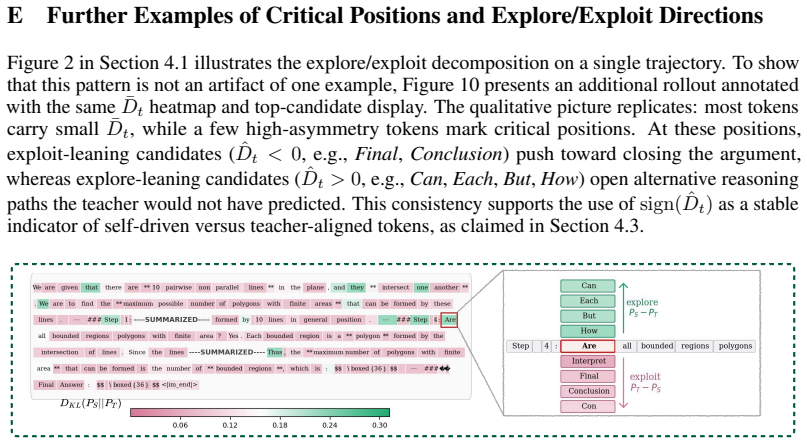

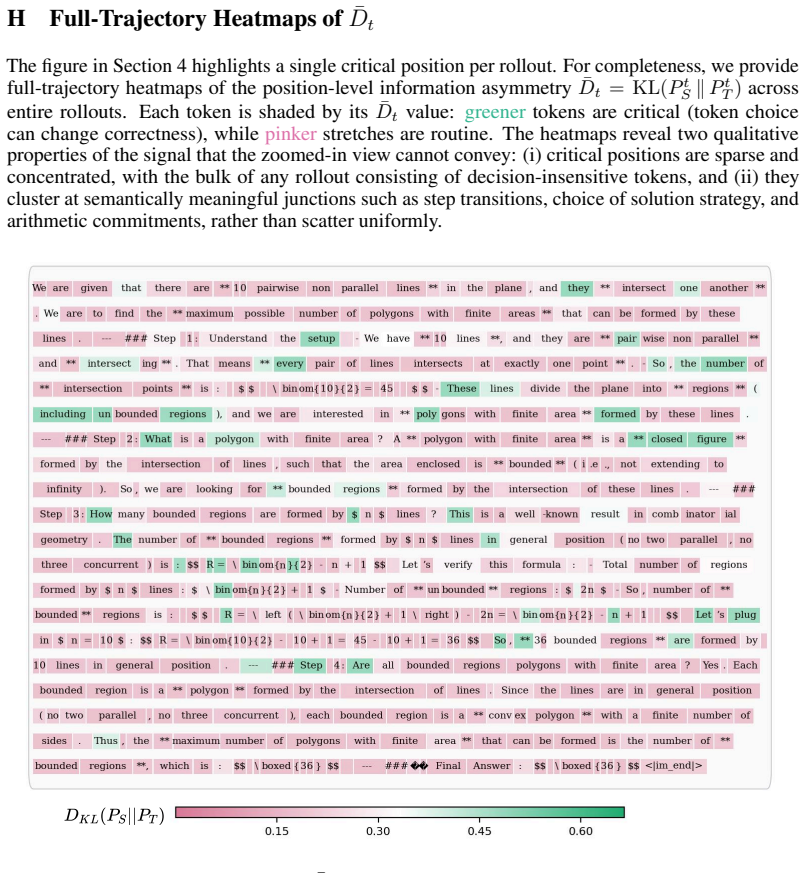

read the original abstract
Self-distillation has emerged as a powerful framework for post-training LLMs, where a teacher conditioned on extra information guides a student without it, both from the same model. While this guidance is useful when the student has failed, on successful rollouts, the same mechanism instead overwrites the student's choices and suppresses it's own reasoning. Therefore, we propose reading the original self-distillation signal in reverse: when the student succeeds along a path the teacher would not have predicted, these tokens reflect its self-driven reasoning. Building on this, we propose RLRT (RLVR with Reversed Teacher), which augments GRPO by reinforcing these tokens on correct rollouts. We interpret this as a new form of exploration in RLVR: not uniform diversity, but valuable exploration grounded in the student's own success. Across base, instruction-tuned, and thinking-tuned Qwen3 checkpoints, RLRT substantially outperforms self-distillation and exploration-based baselines, establishing information asymmetry as a new, principled design axis for RLVR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RLRT (RLVR with Reversed Teacher), an augmentation to GRPO in self-distilled RLVR. On successful student rollouts, it reverses the standard self-distillation signal by reinforcing tokens to which a teacher model (conditioned on extra information) assigns low probability. This is interpreted as encouraging valuable, self-driven exploration rather than overwriting student reasoning. The manuscript claims that RLRT substantially outperforms self-distillation and exploration baselines across base, instruction-tuned, and thinking-tuned Qwen3 checkpoints, positioning information asymmetry as a new principled axis for RLVR design.
Significance. If the empirical claims hold after proper isolation of the reversed-signal effect, the work could meaningfully extend RLVR methodology by providing a targeted alternative to uniform exploration or standard self-distillation. The core idea is conceptually lightweight and directly leverages existing GRPO infrastructure, which would make it easy to adopt if the gains prove robust and generalizable.
major comments (3)
- [Method] Method section: The augmentation of GRPO is described only at a conceptual level with no explicit loss function, reward modification rule, or pseudocode showing how low teacher-probability tokens on correct rollouts are selected and reinforced. Without this, it is impossible to determine whether the procedure reduces to standard RL on successful trajectories or introduces a distinct mechanism.
- [Experiments] Experiments section: The central claim of substantial outperformance over self-distillation and exploration baselines is unsupported by any reported metrics, tables, ablation results, or statistical details. In particular, no experiment compares reinforcing the reversed (low-probability) tokens against reinforcing high-probability teacher tokens on the same correct rollouts, leaving open whether gains arise from information asymmetry or generic RLVR effects.
- [Results] Results and analysis: The assumption that low teacher-probability tokens on successful student rollouts encode generalizable self-driven reasoning (rather than sampling variance, partial-credit paths, or dataset artifacts) is load-bearing for the contribution yet untested. No OOD generalization experiments after RL or controls that remove the reversal component are described.
minor comments (2)
- [Abstract] Abstract: 'suppresses it's own reasoning' contains a grammatical error ('it's' should be 'its').
- [Abstract] Abstract: The statement 'substantially outperforms' is made without any quantitative values or pointers to specific tables/figures, which is atypical and reduces the abstract's informativeness.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas for improving methodological clarity, experimental rigor, and analysis of assumptions. We address each major comment point by point below, with planned revisions to strengthen the presentation of RLRT while preserving the core contribution regarding information asymmetry in RLVR.
read point-by-point responses
-
Referee: [Method] Method section: The augmentation of GRPO is described only at a conceptual level with no explicit loss function, reward modification rule, or pseudocode showing how low teacher-probability tokens on correct rollouts are selected and reinforced. Without this, it is impossible to determine whether the procedure reduces to standard RL on successful trajectories or introduces a distinct mechanism.
Authors: We agree that greater explicitness in the method description would aid reproducibility. The current manuscript presents the high-level idea in Section 3, but the implementation details are embedded in the experimental protocol. In the revised version, we will add the precise RLRT objective as a modification to the GRPO loss: on successful rollouts, tokens with teacher probability below a fixed threshold receive an additive positive advantage term before the policy gradient update. We will also include pseudocode in the appendix that details the token selection process (filtering correct trajectories, computing teacher probs, and applying the reversal only to low-prob tokens). This formulation is distinct from standard RL on successful trajectories because the reversal selectively amplifies student-generated paths that diverge from the teacher. revision: yes
-
Referee: [Experiments] Experiments section: The central claim of substantial outperformance over self-distillation and exploration baselines is unsupported by any reported metrics, tables, ablation results, or statistical details. In particular, no experiment compares reinforcing the reversed (low-probability) tokens against reinforcing high-probability teacher tokens on the same correct rollouts, leaving open whether gains arise from information asymmetry or generic RLVR effects.
Authors: Section 4 of the manuscript reports quantitative results across Qwen3 checkpoints, including accuracy metrics on reasoning benchmarks that show consistent gains for RLRT over the listed baselines. We acknowledge, however, that a direct ablation isolating the reversal (low-prob tokens) versus reinforcing high-probability teacher tokens on identical correct rollouts is not presented. We will add this controlled comparison in the revised experiments, using the same set of successful student rollouts for both variants. This will clarify that the performance difference stems from the information-asymmetry mechanism rather than generic reinforcement on correct trajectories. revision: yes
-
Referee: [Results] Results and analysis: The assumption that low teacher-probability tokens on successful student rollouts encode generalizable self-driven reasoning (rather than sampling variance, partial-credit paths, or dataset artifacts) is load-bearing for the contribution yet untested. No OOD generalization experiments after RL or controls that remove the reversal component are described.
Authors: The manuscript includes qualitative case studies in Section 5 demonstrating that the reinforced low-probability tokens often correspond to novel reasoning steps absent from teacher outputs. The self-distillation baseline serves as a control for the reversal component, since it applies the standard (non-reversed) teacher signal on the same rollouts; the performance gap supports our interpretation. To further address generalizability concerns, we will add OOD evaluation on additional held-out reasoning tasks in the revised results section and include statistical significance reporting for the main comparisons. revision: partial
Circularity Check
No circularity; empirical augmentation of GRPO with no derivations or self-referential reductions.
full rationale
The manuscript describes RLRT as a direct augmentation of GRPO that reinforces low teacher-probability tokens on correct student rollouts. No equations, parameter fits, or mathematical derivations appear. The method is defined explicitly from the reversed self-distillation observation without any claim that reduces a 'prediction' or result back to its inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim of outperformance is empirical (across Qwen3 checkpoints) rather than derived, so the derivation chain is self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@ k training for adaptively balancing exploration and exploitation of large reasoning models.arXiv preprint arXiv:2508.10751, 2025
-
[3]
Reasoning with exploration: An entropy perspective
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Xin Zhao, Zhenliang Zhang, and Furu Wei. Reasoning with exploration: An entropy perspective. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 30377–30385, 2026
work page 2026
-
[4]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Improving rl exploration for llm reasoning through retrospective replay
Shihan Dou, Muling Wu, Jingwen Xu, Rui Zheng, Tao Gui, and Qi Zhang. Improving rl exploration for llm reasoning through retrospective replay. InCCF International Conference on Natural Language Processing and Chinese Computing, pages 594–606. Springer, 2025
work page 2025
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Zhezheng Hao, Hong Wang, Haoyang Liu, Jian Luo, Jiarui Yu, Hande Dong, Qiang Lin, Can Wang, and Jiawei Chen. Rethinking entropy interventions in rlvr: An entropy change perspective.arXiv preprint arXiv:2510.10150, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Diversity-incentivized exploration for versatile reasoning
Zican Hu, Shilin Zhang, Yafu Li, Jianhao Yan, Xuyang Hu, Leyang Cui, Xiaoye Qu, Chunlin Chen, Yu Cheng, and Zhi Wang. Diversity-incentivized exploration for versatile reasoning. arXiv preprint arXiv:2509.26209, 2025
-
[9]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review arXiv 2026
-
[10]
Revisiting Entropy in Reinforcement Learning for Large Reasoning Models
Renren Jin, Pengzhi Gao, Yuqi Ren, Zhuowen Han, Tongxuan Zhang, Wuwei Huang, Wei Liu, Jian Luan, and Deyi Xiong. Revisiting entropy in reinforcement learning for large reasoning models.arXiv preprint arXiv:2511.05993, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of llms?arXiv preprint arXiv:2603.24472, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimization via sample routing.arXiv preprint arXiv:2604.02288, 2026
-
[13]
Exploratory memory-augmented LLM agent via hybrid on- and off-policy optimization
Zeyuan Liu, Jeonghye Kim, Xufang Luo, Dongsheng Li, and Yuqing Yang. Exploratory memory-augmented LLM agent via hybrid on- and off-policy optimization. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=UOzxviKVFO
work page 2026
-
[14]
Understanding r1-zero-like training: A critical perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. InSecond Conference on Language Modeling, 2025. URLhttps://openreview.net/forum?id=5PAF7PAY2Y
work page 2025
-
[15]
Haoming Meng, Kexin Huang, Shaohang Wei, Chiyu Ma, Shuo Yang, Xue Wang, Guoyin Wang, Bolin Ding, and Jingren Zhou. Sparse but critical: A token-level analysis of distributional shifts in rlvr fine-tuning of llms.arXiv preprint arXiv:2603.22446, 2026
-
[16]
Burt L Monroe, Michael P Colaresi, and Kevin M Quinn. Fightin’words: Lexical feature selection and evaluation for identifying the content of political conflict.Political Analysis, 16 (4):372–403, 2008
work page 2008
-
[17]
arXiv preprint arXiv:2510.02230
Phuc Minh Nguyen, Chinh D La, Duy MH Nguyen, Nitesh V Chawla, Binh T Nguyen, and Khoa D Doan. The reasoning boundary paradox: How reinforcement learning constrains language models.arXiv preprint arXiv:2510.02230, 2025
-
[18]
Jaesung R Park, Junsu Kim, Gyeongman Kim, Jinyoung Jo, Sean Choi, Jaewoong Cho, and Ernest K Ryu. Clip-low increases entropy and clip-high decreases entropy in reinforcement learning of large language models.arXiv preprint arXiv:2509.26114, 2025
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review arXiv 2026
-
[21]
Outcome-based exploration for LLM reasoning.arXiv preprint arXiv:2509.06941, 2025
Yuda Song, Julia Kempe, and Remi Munos. Outcome-based exploration for llm reasoning. arXiv preprint arXiv:2509.06941, 2025
-
[22]
Yuda Song, Lili Chen, Fahim Tajwar, Remi Munos, Deepak Pathak, J Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback.arXiv preprint arXiv:2602.02482, 2026
-
[23]
Zhongwei Wan, Yun Shen, Zhihao Dou, Donghao Zhou, Yu Zhang, Xin Wang, Hui Shen, Jing Xiong, Chaofan Tao, Zixuan Zhong, et al. Dsdr: Dual-scale diversity regularization for exploration in llm reasoning.arXiv preprint arXiv:2602.19895, 2026
-
[24]
arXiv preprint arXiv:2510.08141 , year=
Chen Wang, Zhaochun Li, Jionghao Bai, Yuzhi Zhang, Shisheng Cui, Zhou Zhao, and Yue Wang. Arbitrary entropy policy optimization breaks the exploration bottleneck of reinforcement learning.arXiv preprint arXiv:2510.08141, 2025
-
[25]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Xinhao Yao, Lu Yu, Xiaolin Hu, Fengwei Teng, Qing Cui, Jun Zhou, and Yong Liu. The debate on rlvr reasoning capability boundary: Shrinkage, expansion, or both? a two-stage dynamic view.arXiv preprint arXiv:2510.04028, 2025
-
[27]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review arXiv 2026
-
[28]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=4OsgYD7em5
work page 2026
-
[30]
Charlie Zhang, Graham Neubig, and Xiang Yue. On the interplay of pre-training, mid-training, and rl on reasoning language models.arXiv preprint arXiv:2512.07783, 2025
-
[31]
Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach
Rosie Zhao, Alexandru Meterez, Sham Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach. Echo chamber: Rl post-training amplifies behaviors learned in pretraining.arXiv preprint arXiv:2504.07912, 2025
-
[32]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026. 12 A Limitations and Future Directions To our knowledge, RLRT is the first to show that reversing the teacher’s signal, rather than aligning to it,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.