Recognition: unknown
LLMs for Secure Hardware Design and Related Problems: Opportunities and Challenges
Pith reviewed 2026-05-14 21:09 UTC · model grok-4.3
The pith
Large language models can generate hardware designs and detect vulnerabilities but also introduce severe security risks in semiconductors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
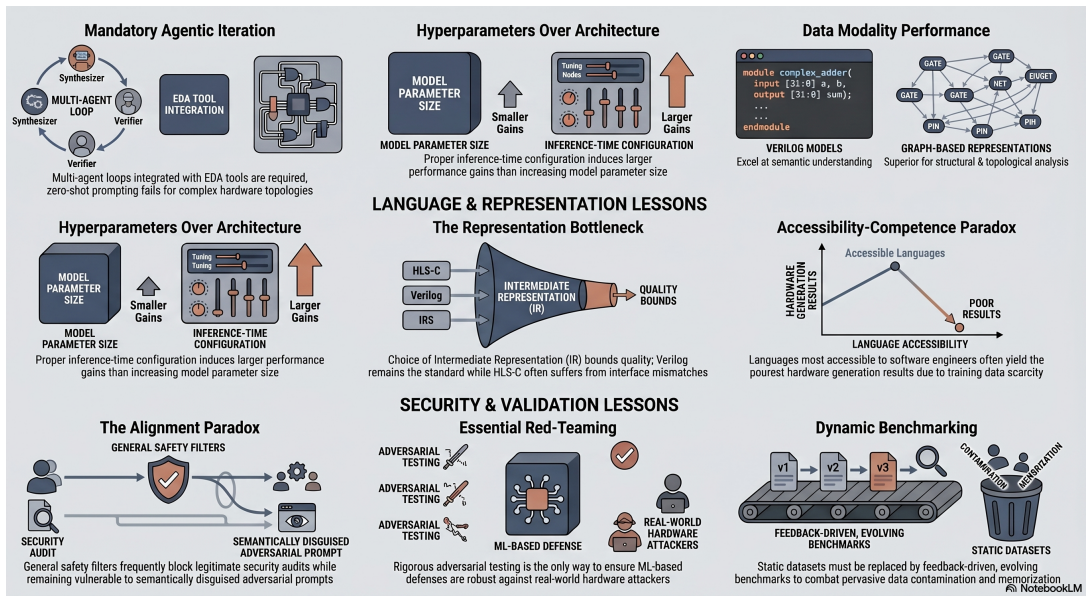
LLMs reshape semiconductor design by enabling automated RTL code generation, testbench creation, and vulnerability analysis in EDA synthesis, hardware trust, and design for security, yet they simultaneously create vulnerabilities via data contamination and adversarial evasion, as shown through systematic analysis of recent methodologies, with countermeasures like dynamic benchmarking required to reach trustworthy autonomous design systems.
What carries the argument
Systematic review framework organized around advancements in EDA synthesis, hardware trust, design for security, and education, expanding on reasoning-driven synthesis and multi-agent vulnerability extraction methodologies.
Load-bearing premise
That the reviewed methodologies from recent breakthroughs accurately capture the current state of LLM-driven hardware design and that the suggested countermeasures such as dynamic benchmarking will prove effective in practice.
What would settle it
Apply dynamic benchmarking to an LLM for hardware tasks and observe whether it still produces vulnerable RTL code or allows data memorization when tested against known attack patterns in fabricated silicon.
Figures
read the original abstract
The integration of Large Language Models (LLMs) into Electronic Design Automation (EDA) and hardware security is rapidly reshaping the semiconductor industry. While LLMs offer unprecedented capabilities in generating Register Transfer Level (RTL) code, automating testbenches, and bridging the semantic gap between high-level specifications and silicon, they simultaneously introduce severe vulnerabilities. This comprehensive review provides an in-depth analysis of the state-of-the-art in LLM-driven hardware design, organized around key advancements in EDA synthesis, hardware trust, design for security, and education. We systematically expand on the methodologies of recent breakthroughs -- from reasoning-driven synthesis and multi-agent vulnerability extraction to data contamination and adversarial machine learning (ML) evasion. We integrate general discussions on critical countermeasures, such as dynamic benchmarking to combat data memorization and aggressive red-teaming for robust security assessment. Finally, we synthesize cross-cutting lessons learned to guide future research toward secure, trustworthy, and autonomous design ecosystems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a comprehensive review of the integration of Large Language Models (LLMs) into Electronic Design Automation (EDA) and hardware security. It claims that LLMs are reshaping the semiconductor industry by enabling RTL code generation, testbench automation, and bridging high-level specifications to silicon, while simultaneously introducing severe vulnerabilities through issues such as data contamination, adversarial ML evasion, and memorization. The review is organized around advancements in EDA synthesis, hardware trust, design for security, and education; it details methodologies including reasoning-driven synthesis and multi-agent vulnerability extraction; and it integrates discussions of countermeasures such as dynamic benchmarking against memorization and aggressive red-teaming, before synthesizing cross-cutting lessons for secure autonomous design ecosystems.
Significance. If the reviewed methodologies accurately capture the state of the art and the proposed countermeasures can be shown viable, the paper would provide a valuable structured synthesis of opportunities and risks at the intersection of LLMs and hardware security, helping guide future research toward trustworthy EDA tools in the semiconductor industry.
major comments (1)
- The section on integrated countermeasures proposes dynamic benchmarking to combat data memorization and aggressive red-teaming for security assessment, but provides no empirical evidence, case studies, or references to studies demonstrating that these mitigations reduce real RTL-level risks such as Trojan insertion or side-channel leakage when LLMs generate or verify hardware designs.
minor comments (1)
- The abstract and introduction could more explicitly indicate the time period, number of papers, or selection criteria for the reviewed breakthroughs to help readers assess completeness.
Simulated Author's Rebuttal
We thank the referee for the positive overall assessment and the constructive major comment. We address the point below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: The section on integrated countermeasures proposes dynamic benchmarking to combat data memorization and aggressive red-teaming for security assessment, but provides no empirical evidence, case studies, or references to studies demonstrating that these mitigations reduce real RTL-level risks such as Trojan insertion or side-channel leakage when LLMs generate or verify hardware designs.
Authors: We appreciate this observation. Our manuscript is a survey that synthesizes existing literature on LLM-driven EDA and hardware security rather than presenting new experiments. The countermeasures are drawn from broader LLM security research (e.g., dynamic evaluation frameworks and red-teaming protocols shown effective against memorization in code-generation tasks) and are positioned as applicable to hardware contexts. We acknowledge that the current body of work contains limited direct empirical studies quantifying reductions in RTL-specific threats such as Trojan insertion or side-channel leakage. In the revised version we will (1) add explicit references to recent red-teaming and benchmarking studies in software and LLM code domains, (2) clarify that these techniques are proposed directions whose hardware-specific efficacy remains an open research question, and (3) expand the discussion of limitations to better contextualize the absence of RTL-level case studies. revision: yes
Circularity Check
No circularity: literature survey with no derivations or self-referential reductions
full rationale
This is a review paper that surveys existing LLM-driven EDA and hardware-security work, organizes methodologies from the literature, and offers high-level discussion of countermeasures. No equations, fitted parameters, predictions, or derivations appear; therefore none of the enumerated circularity patterns (self-definitional, fitted-input-called-prediction, load-bearing self-citation, etc.) can be instantiated. The central narrative rests on external citations rather than any internal reduction to the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLMs and the future of chip design: Unveiling security risks and building trust,
Z. Wang, L. Alrahis, L. Mankali, J. Knechtel, and O. Sinanoglu, “LLMs and the future of chip design: Unveiling security risks and building trust,” inProc. ISVLSI, 2024, pp. 385–390
2024
-
[2]
Large language models (LLMs) for electronic design automation (EDA): Special session paper,
K. Xu, D. Schwachhofer, J. Blocklove, I. Polian, P. Domanski, D. Pfl ¨uger, S. Garg, R. Karri, O. Sinanoglu, J. Knechtel, Z. Zhao, U. Schlichtmann, and B. Li, “Large language models (LLMs) for electronic design automation (EDA): Special session paper,” inProc. SOCC, 2024
2024
-
[3]
VeriGen: A large language model for Verilog code generation,
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “VeriGen: A large language model for Verilog code generation,” ACM TODAES, vol. 29, no. 3, pp. 46:1–46:31, 2024
2024
-
[4]
VeriLeaky: Navigating IP protection vs utility in fine-tuning for LLM-driven Verilog coding,
Z. Wang, M. Shao, M. Nabeel, P. B. Roy, L. Mankali, J. Bhandari, R. Karri, O. Sinanoglu, M. Shafique, and J. Knechtel, “VeriLeaky: Navigating IP protection vs utility in fine-tuning for LLM-driven Verilog coding,” inProc. MLCAD, 2025
2025
-
[5]
RTL-Breaker: Assessing the security of LLMs against backdoor attacks on HDL code generation,
L. L. Mankali, J. Bhandari, M. Alam, R. Karri, M. Maniatakos, O. Sinanoglu, and J. Knechtel, “RTL-Breaker: Assessing the security of LLMs against backdoor attacks on HDL code generation,” inProc. DATE, 2025
2025
-
[6]
VeriContaminated: Assessing LLM- driven Verilog coding for data contamination,
Z. Wang, M. Shao, J. Bhandari, L. Mankali, R. Karri, O. Sinanoglu, M. Shafique, and J. Knechtel, “VeriContaminated: Assessing LLM- driven Verilog coding for data contamination,” inProc. MLCAD, 2025
2025
-
[7]
From Natural Language to Silicon: The Representation Bottleneck in LLM Hardware Design
W. Fu, Z. Wang, M. Shao, J. Knechtel, O. Sinanoglu, R. Karri, M. Shafique, and X. Guo, “From natural language to silicon: The representation bottleneck in LLM hardware design,”arXiv preprint arXiv:2604.17097, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
HarmChip: Evaluating Hardware Security Centric LLM Safety via Jailbreak Benchmarking
Z. Wang, M. Shao, W. Fu, P. B. Roy, X. Guo, R. Karri, M. Shafique, J. Knechtel, and O. Sinanoglu, “HarmChip: Evaluating hardware se- curity centric LLM safety via jailbreak benchmarking,”arXiv preprint arXiv:2604.17093, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
NetDeTox: Adversarial and efficient evasion of hardware- security GNNs via RL-LLM orchestration,
Z. Wang, M. Shao, A. Saha, R. Karri, J. Knechtel, M. Shafique, and O. Sinanoglu, “NetDeTox: Adversarial and efficient evasion of hardware- security GNNs via RL-LLM orchestration,” inProc. DAC, 2026
2026
-
[10]
Lowering the bar: How large language models can be used as a copilot by hardware hackers,
J. Blocklove, H. Pearce, and R. Karri, “Lowering the bar: How large language models can be used as a copilot by hardware hackers,”IEEE Security & Privacy, vol. 23, no. 5, pp. 27–37, 2025
2025
-
[11]
Automatically improving LLM-based Verilog generation using EDA tool feedback,
J. Blocklove, S. Thakur, B. Tan, H. Pearce, S. Garg, and R. Karri, “Automatically improving LLM-based Verilog generation using EDA tool feedback,”ACM TODAES, vol. 30, no. 6, pp. 100:1–100:26, 2025
2025
-
[12]
Make every move count: LLM-based high-quality RTL code generation using MCTS,
M. DeLorenzo, A. B. Chowdhury, V . Gohil, S. Thakur, R. Karri, S. Garg, and J. Rajendran, “Make every move count: LLM-based high-quality RTL code generation using MCTS,”arXiv preprint arXiv:2402.03289, 2024
-
[13]
Veritas: Deterministic Verilog code synthesis from LLM- generated conjunctive normal form,
P. B. Roy, A. Saha, M. Alam, J. Knechtel, M. Maniatakos, O. Sinanoglu, and R. Karri, “Veritas: Deterministic Verilog code synthesis from LLM- generated conjunctive normal form,”arXiv preprint arXiv:2506.00005, 2025
-
[14]
RTL-Forge: CNF-anchored, LLM-assisted Verilog generation,
——, “RTL-Forge: CNF-anchored, LLM-assisted Verilog generation,” inProc. VTS, 2026
2026
-
[15]
SALAD: Systematic assessment of machine unlearning on LLM-aided hardware design,
Z. Wang, M. Shao, R. R. Karn, L. Mankali, J. Bhandari, R. Karri, O. Sinanoglu, M. Shafique, and J. Knechtel, “SALAD: Systematic assessment of machine unlearning on LLM-aided hardware design,” in Proc. MLCAD, 2025
2025
-
[16]
TrojanGYM: A detector-in-the- loop LLM for adaptive RTL hardware Trojan insertion,
S. Sreekumar, Z. Wang, A. Saha, W. Xiao, M. Shao, M. Shafique, O. Sinanoglu, R. Karri, and J. Knechtel, “TrojanGYM: A detector-in-the- loop LLM for adaptive RTL hardware Trojan insertion,”arXiv preprint arXiv:2601.17178, 2026
-
[17]
VeriThoughts: Enabling automated Verilog code generation us- ing reasoning and formal verification,
P. Yubeaton, A. Nakkab, W. Xiao, L. Collini, R. Karri, C. Hegde, and S. Garg, “VeriThoughts: Enabling automated Verilog code generation us- ing reasoning and formal verification,”arXiv preprint arXiv:2505.20302, 2025
-
[18]
RTL++: Graph-enhanced LLM for RTL code generation,
M. Akyash, K. Azar, and H. Kamali, “RTL++: Graph-enhanced LLM for RTL code generation,”arXiv preprint arXiv:2505.13479, 2025
-
[19]
C2HLSC: Leveraging large language models to bridge the software-to-hardware design gap,
L. Collini, S. Garg, and R. Karri, “C2HLSC: Leveraging large language models to bridge the software-to-hardware design gap,”ACM TODAES, vol. 30, no. 6, pp. 96:1–96:24, 2025
2025
-
[20]
LLM-driven code generation for neural networks on FPGAs: Bridging Python and HLS,
R. R. Karn, J. Knechtel, R. Karri, and O. Sinanoglu, “LLM-driven code generation for neural networks on FPGAs: Bridging Python and HLS,” inProc. ICCD, 2025
2025
-
[21]
Can reasoning models reason about hardware? an agentic HLS perspective,
L. Collini, A. Hennessee, R. Karri, and S. Garg, “Can reasoning models reason about hardware? an agentic HLS perspective,”arXiv preprint arXiv:2503.12721, 2025
-
[22]
(Security) assertions by large language models,
R. Kande, H. Pearce, B. Tan, B. Dolan-Gavitt, S. Thakur, R. Karri, and J. Rajendran, “(Security) assertions by large language models,”IEEE TIFS, vol. 19, pp. 4374–4389, 2024
2024
-
[23]
Knowledge Graphs, the Missing Link in Agentic AI-based Formal Verification
V . N. Viswambharan, K. K. Radhakrishna, D. N. Gadde, and A. Ku- mar, “Knowledge graphs, the missing link in agentic AI-based formal verification,”arXiv preprint arXiv:2605.06434, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Hybrid-NL2SV A: Integrat- ing RAG and finetuning for LLM-based NL2SV A,
W. Xiao, D. Ekberg, S. Garg, and R. Karri, “Hybrid-NL2SV A: Integrat- ing RAG and finetuning for LLM-based NL2SV A,” inProc. MLCAD, 2025, pp. 1–10
2025
-
[25]
LLM-aided testbench generation and bug detection for finite-state machines,
J. Bhandari, J. Knechtel, R. Narayanaswamy, S. Garg, and R. Karri, “LLM-aided testbench generation and bug detection for finite-state machines,”arXiv preprint arXiv:2406.17132, 2024
-
[26]
Z. Wang, W. Xiao, M. Shao, R. V . Hemadri, O. Sinanoglu, M. Shafique, and R. Karri, “VeriDispatcher: Multi-model dispatching through pre- inference difficulty prediction for RTL generation optimization,”arXiv preprint arXiv:2511.22749, 2025
-
[27]
Synthesis-in-the-Loop Evaluation of LLMs for RTL Generation: Quality, Reliability, and Failure Modes
W. Fu, Z. Wang, M. Shao, R. Karri, M. Shafique, J. Knechtel, O. Sinanoglu, and X. Guo, “Synthesis-in-the-loop evaluation of LLMs for RTL generation: Quality, reliability, and failure modes,”arXiv preprint arXiv:2603.11287, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
VeriInteresting: An Empirical Study of Model Prompt Interactions in Verilog Code Generation
L. Collini, A. Hennesee, P. Yubeaton, S. Garg, and R. Karri, “VeriIn- teresting: An empirical study of model prompt interactions in Verilog code generation,”arXiv preprint arXiv:2603.08715, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
M. Shao, Z. Wang, W. Fu, X. Guo, J. Knechtel, O. Sinanoglu, R. Karri, and M. Shafique, “Configuration over selection: Hyperparameter sensi- tivity exceeds model differences in open-source LLMs for RTL gener- ation,”arXiv preprint arXiv:2604.17102, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
LLM benchmarking coalition,
LLM Benchmarking Coalition, “LLM benchmarking coalition,” https: //si2.org/llm-benchmarking-coalition/, 2026
2026
-
[31]
Benchmarking large language models under data contamination: A survey from static to dynamic evaluation,
S. Chen, Y . Chen, Z. Li, Y . Jiang, Z. Wan, Y . He, D. Ran, T. Gu, H. Li, T. Xie, and B. Ray, “Benchmarking large language models under data contamination: A survey from static to dynamic evaluation,” inProc. EMNLP, 2025, pp. 10 080–10 098
2025
-
[32]
Prompt injection attacks in large language models and AI agent systems: A comprehensive review of vulnerabilities, attack vectors, and defense mechanisms,
S. Gulyamov, S. Gulyamov, A. Rodionov, R. Khursanov, K. Mekhmonov, D. Babaev, and A. Rakhimjonov, “Prompt injection attacks in large language models and AI agent systems: A comprehensive review of vulnerabilities, attack vectors, and defense mechanisms,” Information, vol. 17, no. 1, p. 54, 2026
2026
-
[33]
GLLaMoR: Graph-based logic locking by large language models for enhanced robustness,
A. Saha, P. B. Roy, J. Knechtel, R. Karri, O. Sinanoglu, and L. Alrahis, “GLLaMoR: Graph-based logic locking by large language models for enhanced robustness,” inProc. VTS, 2025
2025
-
[34]
Hector – an agentic LLM framework for logic locking,
P. B. Roy, A. Saha, L. Alrahis, J. Knechtel, O. Sinanoglu, and R. Karri, “Hector – an agentic LLM framework for logic locking,” inProc. AsiaCCS, 2026
2026
-
[35]
LockForge: Automating paper-to-code for logic locking with multi- agent reasoning LLMs,
A. Saha, Z. Wang, P. B. Roy, J. Knechtel, O. Sinanoglu, and R. Karri, “LockForge: Automating paper-to-code for logic locking with multi- agent reasoning LLMs,”arXiv preprint arXiv:2511.18531, 2025
-
[36]
Can Agents Secure Hardware? Evaluating Agentic LLM-Driven Obfuscation for IP Protection
S. Ghimire, P. Mirfasihi, M. A. Chowdhury, V . Pugazhenthi, H. K. Dharavath, F. Firouzi, R. Yasaei, P. Satam, and S. Salehi, “Can agents secure hardware? evaluating agentic LLM-driven obfuscation for IP protection,”arXiv preprint arXiv:2604.13298, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
ARIANNA: An automatic design flow for fabric customization and eFPGA redaction,
L. Collini, J. Bhandari, C. M. Tomajoli, A. Moosa, B. Tan, X. Tang, P.-E. Gaillardon, R. Karri, and C. Pilato, “ARIANNA: An automatic design flow for fabric customization and eFPGA redaction,”ACM TODAES, vol. 30, no. 4, pp. 63:1–63:23, 2025
2025
-
[38]
Netlist whisperer: Extensive analysis of circuit leakage using LLMs,
P. B. Roy, M. Nair, R. Sadhukhan, M. Alam, J. Knechtel, H. Pearce, D. Mukhopadhyay, O. Sinanoglu, and R. Karri, “Netlist whisperer: Extensive analysis of circuit leakage using LLMs,”Journal of Cryp- tographic Engineering, vol. 15, no. 4, p. 22, 2025
2025
-
[39]
LLM4PQC - accurate and efficient synthesis of PQC cores by feedback-driven LLMs,
B. Perera, Z. Wang, W. Xiao, M. Nabeel, O. Sinanoglu, J. Knechtel, and R. Karri, “LLM4PQC - accurate and efficient synthesis of PQC cores by feedback-driven LLMs,” inProc. DATE, 2026
2026
-
[40]
LLM4SecurePQC: LLM-driven and side-channel resilient hardware synthesis of PQC cores,
M. Nabeel, B. Perera, Z. Wang, O. Sinanoglu, J. Knechtel, and R. Karri, “LLM4SecurePQC: LLM-driven and side-channel resilient hardware synthesis of PQC cores,” inProc. VTS, 2026
2026
-
[41]
TrojanLoC: Fine-grained hardware Trojan detection from Verilog code,
W. Xiao, Z. Wang, M. Shao, R. V . Hemadri, O. Sinanoglu, M. Shafique, J. Knechtel, S. Garg, and R. Karri, “TrojanLoC: Fine-grained hardware Trojan detection from Verilog code,”arXiv preprint arXiv:2512.00591, 2025
-
[42]
AttackGNN: Red- teaming GNNs in hardware security using reinforcement learning,
V . Gohil, S. Patnaik, D. Kalathil, and J. Rajendran, “AttackGNN: Red- teaming GNNs in hardware security using reinforcement learning,” in Proc. USENIX Security, 2024, pp. 73–90
2024
-
[43]
VeriCWEty: Embedding enabled Line-Level CWE Detection in Verilog
P. B. Roy, Z. Wang, A. Chuvashlov, W. Xiao, J. Knechtel, O. Sinanoglu, and R. Karri, “VeriCWEty: Embedding enabled line-level CWE detec- tion in Verilog,”arXiv preprint arXiv:2604.15375, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
LASHED: LLMs and static hardware analysis for early detection of RTL bugs,
B. Ahmad, H. Pearce, R. Karri, and B. Tan, “LASHED: LLMs and static hardware analysis for early detection of RTL bugs,”arXiv preprint arXiv:2504.21770, 2025
-
[45]
MARVEL: Multi- agent RTL vulnerability extraction using large language models,
L. Collini, B. Ahmad, J. Ah-kiow, and R. Karri, “MARVEL: Multi- agent RTL vulnerability extraction using large language models,”arXiv preprint arXiv:2505.11963, 2025
-
[46]
FLAG: Finding line anomalies (in RTL code) with generative AI,
B. Ahmad, J. Ah-kiow, B. Tan, R. Karri, and H. Pearce, “FLAG: Finding line anomalies (in RTL code) with generative AI,”ACM TODAES, vol. 30, no. 6, pp. 103:1–103:30, 2025
2025
-
[47]
GUIDE: GenAI units in digital design education,
W. Xiao, J. Blocklove, M. DeLorenzo, J. Knechtel, O. Sinanoglu, K. Basu, J. Rajendran, S. Garg, and R. Karri, “GUIDE: GenAI units in digital design education,” inProc. DATE, 2026
2026
-
[48]
AI in cybersecurity education–scalable agentic CTF design principles and educational out- comes,
H. Xi, M. Shao, K. Milner, V . S. C. Putrevu, N. Rani, M. Udeshi, P. Krishnamurthy, B. Dolan-Gavitt, S. Garg, S. K. Shukla, F. Khor- rami, A. Hillel-Tuch, M. Shafique, and R. Karri, “AI in cybersecurity education–scalable agentic CTF design principles and educational out- comes,”arXiv preprint arXiv:2603.21551, 2026
-
[49]
Towards effective offensive security LLM agents: Hyper- parameter tuning, LLM as a judge, and a lightweight CTF benchmark,
M. Shao, N. Rani, K. Milner, H. Xi, M. Udeshi, S. Aggarwal, V . S. C. Putrevu, S. K. Shukla, P. Krishnamurthy, F. Khorrami, R. Karri, and M. Shafique, “Towards effective offensive security LLM agents: Hyper- parameter tuning, LLM as a judge, and a lightweight CTF benchmark,” inProc. AAAI, vol. 40, no. 35, 2026, pp. 29 660–29 668
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.