Recognition: 2 theorem links
· Lean TheoremSLIM: Sparse Latent Steering for Interpretable and Property-Directed LLM-Based Molecular Editing
Pith reviewed 2026-05-12 05:10 UTC · model grok-4.3
The pith
Decomposing LLM hidden states into sparse property-aligned features allows targeted steering of molecular edits without changing the model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SLIM trains a Sparse Autoencoder with learnable importance gates on the hidden states produced by an LLM during molecular editing tasks. The resulting sparse features align with individual molecular properties, so that property-directed edits are performed simply by increasing the activation of the corresponding dimensions in latent space. This steering improves the fraction of edits that successfully enhance the target property compared with direct generation from the LLM.
What carries the argument
Sparse Autoencoder with learnable importance gates that extracts a sparse basis of property-aligned features from LLM hidden states and enables their selective activation for steering.
If this is right
- Editing success rates rise consistently across four model architectures and eight molecular properties.
- The sparse representation supplies an explicit basis for analyzing which internal directions drive each edit.
- The method requires no parameter changes to the underlying LLM and functions as a plug-in module.
- The same mechanism supports both property improvement and post-hoc interpretation of editing trajectories.
Where Pith is reading between the lines
- The same gated-sparse decomposition could be tested on LLM-based generation tasks outside chemistry, such as protein sequence design or materials formula prediction.
- If the features prove stable across different LLMs, the approach offers a general route to make entangled representations in language models more controllable.
- One could examine whether the learned gates reveal systematic differences in how various model sizes or training regimes encode chemical knowledge.
Load-bearing premise
The sparse features isolated by the gated autoencoder truly align with distinct molecular properties and can be activated independently without harming unrelated properties.
What would settle it
An experiment on the MolEditRL benchmark in which SLIM steering produces no higher target-property success rate than unguided LLM editing or random feature activation across the tested models and properties.
Figures








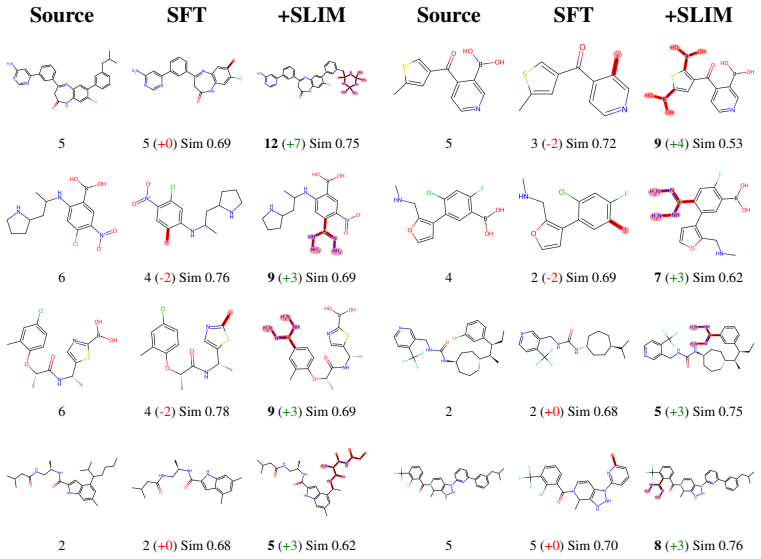






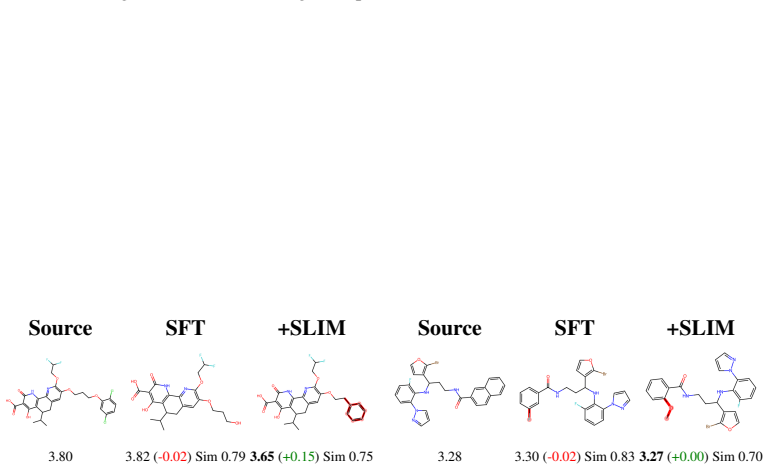




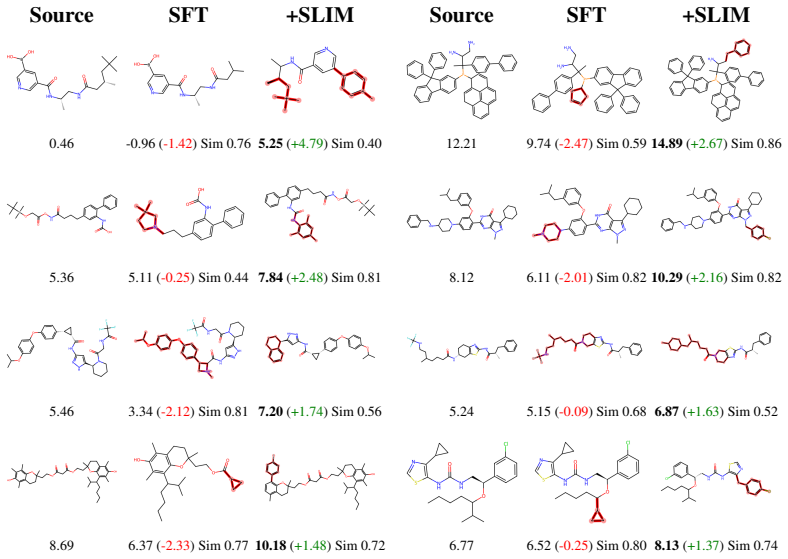







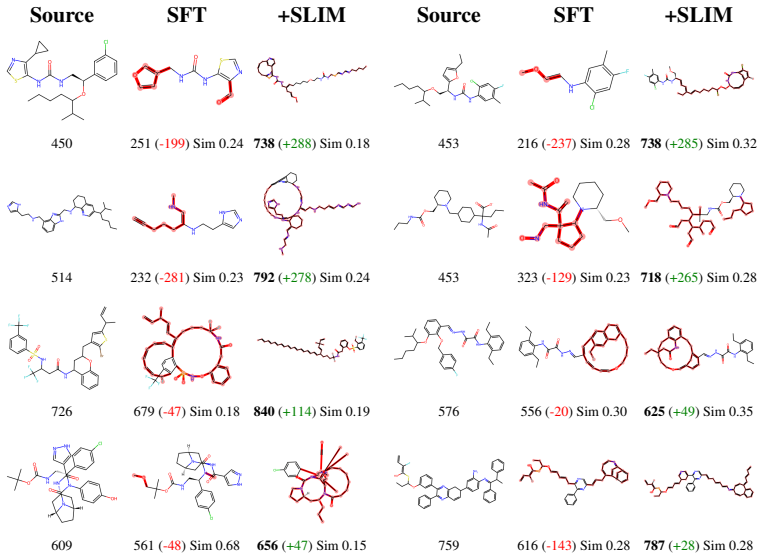




read the original abstract
Large language models possess strong chemical reasoning capabilities, making them effective molecular editors. However, property-relevant information is implicitly entangled across their dense hidden states, providing no explicit handle for property control: a substantial fraction of edits fail to improve or even degrade target properties. To address these issues, we propose SLIM (Sparse Latent Interpretable Molecular editing), a plug-and-play framework that decomposes the editor's hidden states into sparse, property-aligned features via a Sparse Autoencoder with learnable importance gates. Steering in this sparse feature space precisely activates property-relevant dimensions, improving editing success rate without modifying model parameters. The same sparse basis further supports interpretable analysis of editing behavior. Experiments on the MolEditRL benchmark across four model architectures and eight molecular properties show consistent gains over baselines, with improvements of up to 42.4 points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SLIM, a plug-and-play framework for LLM-based molecular editing. It uses a Sparse Autoencoder equipped with learnable importance gates to decompose the editor LLM's hidden states into sparse features claimed to be property-aligned. Steering is performed by activating selected dimensions in this sparse space to direct edits toward target molecular properties, without updating the base model parameters. The same basis is said to enable interpretable analysis of editing behavior. Experiments on the MolEditRL benchmark across four model architectures and eight properties report consistent gains over baselines, reaching up to 42.4 points.
Significance. If the central claims are substantiated, SLIM would provide a parameter-efficient, interpretable mechanism for property-directed control in LLM molecular editors, addressing the entanglement of property information in dense hidden states. The plug-and-play design and dual use for steering plus interpretability could have broad utility in computational chemistry and drug design pipelines. The reported benchmark improvements suggest practical value, but only if they can be shown to arise specifically from property-aligned feature selection rather than generic sparsity or regularization effects.
major comments (3)
- [Abstract] Abstract: The central claim that the SAE 'decomposes the editor's hidden states into sparse, property-aligned features' and that 'steering in this sparse feature space precisely activates property-relevant dimensions' is load-bearing, yet the abstract supplies no description of how the learnable importance gates are trained (reconstruction loss only, or with property supervision?), no correlation or causal validation metrics linking selected features to target properties, and no checks that unrelated properties remain unaffected. Without these, observed gains could result from any sparse latent intervention.
- [Experimental Results] Experimental Results: The reported gains of up to 42.4 points on MolEditRL across four architectures and eight properties rest on unverified assertions. The manuscript provides no training details for the autoencoder, no statistical significance tests, no explicit baseline implementations or hyperparameter settings, and no ablation studies (e.g., removing the importance gates or replacing them with random sparse masks). These omissions prevent assessment of whether the improvements are reproducible or attributable to the proposed mechanism.
- [Methods] Methods (Sparse Autoencoder with learnable gates): The framework is presented as independent and plug-and-play, but the absence of any equation or procedure showing how gate training ensures causal property alignment (as opposed to merely increasing sparsity) creates a circularity risk. If gates are optimized solely on reconstruction + sparsity without property labels or post-hoc validation, the 'property-directed' steering claim reduces to an untested assumption.
minor comments (2)
- [Abstract] Abstract: The claim of 'consistent gains' would be clearer if the specific four model architectures and eight molecular properties were named, along with the exact baseline methods used for comparison.
- The manuscript would benefit from a dedicated limitations paragraph discussing potential failure modes, such as feature interference across properties or degradation of molecular validity after steering.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications where the manuscript already contains supporting material and committing to revisions for added rigor, reproducibility, and validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the SAE 'decomposes the editor's hidden states into sparse, property-aligned features' and that 'steering in this sparse feature space precisely activates property-relevant dimensions' is load-bearing, yet the abstract supplies no description of how the learnable importance gates are trained (reconstruction loss only, or with property supervision?), no correlation or causal validation metrics linking selected features to target properties, and no checks that unrelated properties remain unaffected. Without these, observed gains could result from any sparse latent intervention.
Authors: We agree the abstract is high-level and should better preview the training and validation approach. The gates are trained using only reconstruction loss plus an L1 sparsity penalty on the gated latent activations (no property labels or supervision), as detailed in Section 3.2. Property alignment is shown empirically via consistent steering gains across eight properties and four models, plus the interpretability analysis in Section 4.3. In revision we will expand the abstract to briefly state the unsupervised training objective and reference the empirical validation. We will also add explicit correlation metrics between selected features and property deltas, plus checks confirming unrelated properties are not degraded. revision: yes
-
Referee: [Experimental Results] Experimental Results: The reported gains of up to 42.4 points on MolEditRL across four architectures and eight properties rest on unverified assertions. The manuscript provides no training details for the autoencoder, no statistical significance tests, no explicit baseline implementations or hyperparameter settings, and no ablation studies (e.g., removing the importance gates or replacing them with random sparse masks). These omissions prevent assessment of whether the improvements are reproducible or attributable to the proposed mechanism.
Authors: We acknowledge these omissions limit reproducibility assessment. The revised manuscript will add: (i) complete SAE training details including loss formulation, optimizer, learning rate, batch size, and sparsity coefficient; (ii) statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values across multiple seeds); (iii) explicit hyperparameter tables and code-level descriptions for all baselines; and (iv) ablation studies removing the learnable gates (replacing with fixed or random masks) to isolate their contribution. These additions will directly test whether gains arise from property-aligned selection rather than generic sparsity. revision: yes
-
Referee: [Methods] Methods (Sparse Autoencoder with learnable gates): The framework is presented as independent and plug-and-play, but the absence of any equation or procedure showing how gate training ensures causal property alignment (as opposed to merely increasing sparsity) creates a circularity risk. If gates are optimized solely on reconstruction + sparsity without property labels or post-hoc validation, the 'property-directed' steering claim reduces to an untested assumption.
Authors: The current methods section (3.2) states that gates are optimized end-to-end with the SAE on reconstruction plus sparsity losses only, preserving the unsupervised plug-and-play property. Property directionality is not claimed to be enforced causally at training time but is instead validated post-hoc through steering success and feature-property correlations. To remove any circularity, we will insert the explicit training objective equation and add further post-hoc validation (feature activation histograms conditioned on property success/failure). This clarifies that the mechanism relies on learned sparsity plus empirical steering evidence rather than assuming alignment a priori. revision: partial
Circularity Check
No significant circularity; claims rest on external benchmark evaluation
full rationale
The paper introduces SLIM as a plug-and-play framework that applies a Sparse Autoencoder with learnable importance gates to decompose LLM hidden states into sparse features for steering molecular edits. Performance gains (up to 42.4 points on MolEditRL) are reported via direct experiments across four architectures and eight properties on an independent benchmark. No equations, derivations, or self-citations in the abstract or described method reduce the central claims to fitted quantities or definitions by construction. The description of features as 'property-aligned' is an empirical claim to be tested by the benchmark results rather than a self-referential definition or renamed input. The framework's independence from model parameters and use of external evaluation make the derivation chain self-contained with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decomposes the editor's hidden states into sparse, property-aligned features via a Sparse Autoencoder with learnable importance gates... L = L_recon + λ_c L_contrast + λ_s L_sup + λ_sp L_sparse + λ_g L_grad
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
gradient-alignment loss... d(p)_steer = W_d · top_k(enc(d(p)_grad), k)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models. InInternational Conference on Learning Representa- tions. ArXiv:2309.08600. Vishal Dey, Xiao Hu, and Xia Ning
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
GeLLMO: Generalizing large language models for multi- property molecule optimization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). ArXiv:2502.13398. Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Dr...
-
[3]
Toy models of superposition. Transformer Circuits Thread. ArXiv:2209.10652. Peter Ertl and Ansgar Schuffenhauer
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
InInternational Conference on Learning Rep- resentations
Domain- agnostic molecular generation with chemical feed- back. InInternational Conference on Learning Rep- resentations. ArXiv:2301.11259. Dong Gao and 1 others
- [5]
-
[6]
Mistral 7B.arXiv preprint arXiv:2310.06825. José Jiménez-Luna, Francesca Grisoni, and Gisbert Schneider
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
The Llama 3 herd of models.arXiv preprint arXiv:2407.21783. Hannes H. Loeffler, Jiazhen He, Alessandro Tibo, Jon Paul Janet, Alexey V oronov, Lewis H. Mervin, and Ola Engkvist
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
BioT5: Enriching cross-modal integration in biol- ogy with chemical knowledge and natural language associations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 1102–1123. Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda
work page 2023
-
[9]
arXiv preprint arXiv:2404.16014 , year=
ArXiv:2404.16014. Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner
-
[10]
Steering Llama 2 via Contrastive Activation Addition
Steering Llama 2 via contrastive activation addi- tion. InProceedings of the 62nd Annual Meet- ing of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 15504–15522. ArXiv:2312.06681. David Rogers and Mathew Hahn
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foun- dation and fine-tuned chat models.arXiv preprint arXiv:2307.09288. Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Steering Language Models With Activation Engineering
Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248. Geyan Ye, Xibao Cai, Houtim Lai, Xing Wang, Junhong Huang, Longyue Wang, Wei Liu, and Xiangxiang Zeng
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
DrugAssist: A large language model for molecule optimization.Briefings in Bioinformatics, 26(1):bbae693. ArXiv:2401.10334. Mingxu Zhang, Dazhong Shen, and Ying Sun. 2025a. AtomDisc: An atom-level tokenizer that boosts molecular LLMs and reveals structure–property asso- ciations.arXiv preprint arXiv:2512.03080. Mingxu Zhang, Dazhong Shen, Qi Zhang, and Yin...
-
[14]
arXiv preprint arXiv:2505.20131
MolEditRL: Structure-preserving molecular editing via discrete diffusion and reinforcement learning. arXiv preprint arXiv:2505.20131. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Bas...
-
[15]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to AI transparency. InInternational Conference on Learning Representations. ArXiv:2310.01405. A Experimental Settings Evaluation Metrics.We follow the MolEditRL benchmark protocol (Zhuang et al., 2025). For each test molecule x and property p, we generate n= 5 candidate molecules {x′ 1, . . . , x′ n} via nuc...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
We report Acc@τ: the percentage of test molecules for which at least one candidate is suc- cessful
with radius 2 and 2048 bits. We report Acc@τ: the percentage of test molecules for which at least one candidate is suc- cessful. We evaluate at two thresholds: τ= 0.15 (permissive, allowing larger structural changes) and τ= 0.65 (strict, requiring high structural preserva- tion). Test Set.We use the 500-molecule test set from the DrugAssist evaluation sui...
work page 2048
-
[17]
— quanti- tative estimate of drug- likeness ↑ DRD2 Random Forest classifier on Morgan FP (radius 2, 2048 bits) ↑ logP RDKit Crippen MolLogP — octanol-water partition coefficient ↑ MW RDKit MolWt — molecu- lar weight in Daltons ↑ RotBond RDKit NumRotatable- Bonds ↑ SA SA scorer (Ertl and Schuf- fenhauer,
work page 2048
-
[18]
SAE training and evaluation use a single GPU. Gradient direction computation requires fp32 pre- cision and takes approximately 2 hours per model per property on a single A100. SAE training con- verges in approximately 30 minutes. Inference- time steering adds negligible overhead ( <1% la- 11 SFT (LoRA(Hu et al., 2022)) Task-Oriented SAE Gradient Direction...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.