Recognition: 2 theorem links
· Lean TheoremIs Your Driving World Model an All-Around Player?
Pith reviewed 2026-05-12 04:38 UTC · model grok-4.3
The pith
No existing driving world model performs well across visual quality, geometry, behavior, and human perception at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
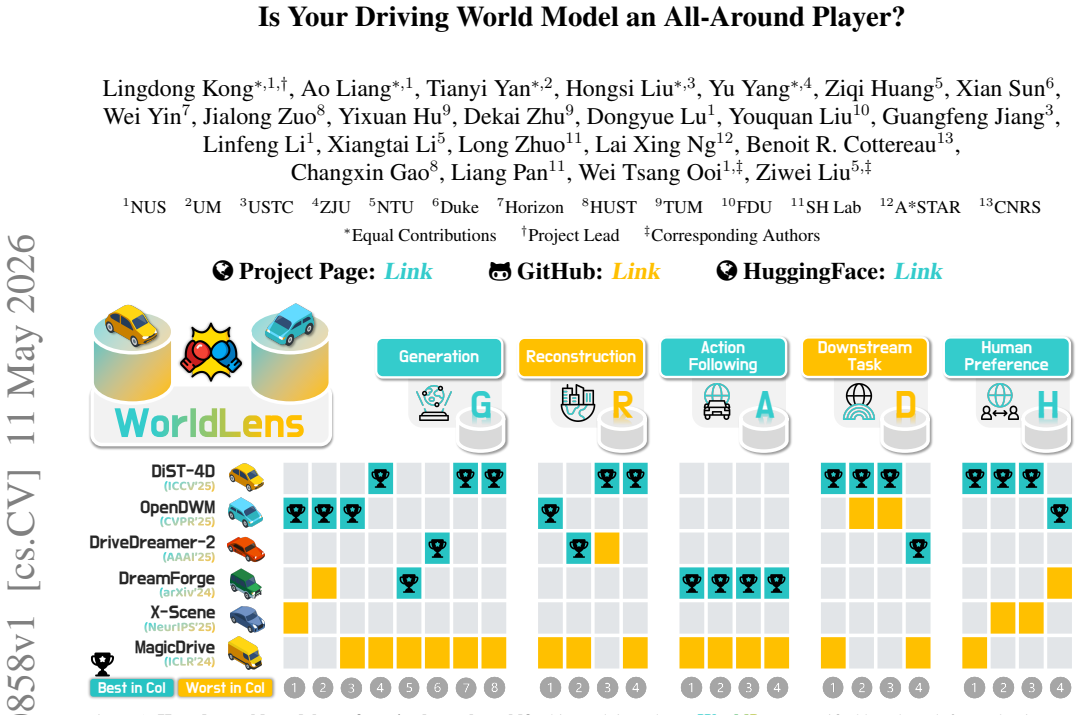
No single driving world model excels universally because texture-rich models violate geometry, geometry-aware models lack behavioral fidelity, and even the strongest performers achieve only 2-3 out of 10 on human realism ratings; evaluations across five complementary aspects and 24 standardized dimensions from pixel quality to closed-loop driving and perceptual alignment reveal these complementary shortcomings in all tested approaches.
What carries the argument
WorldLens, the unified benchmark that measures generated driving world fidelity across five complementary aspects and 24 standardized dimensions spanning pixel quality, 4D geometry, closed-loop driving performance, and human perceptual alignment.
If this is right
- Texture-rich models violate geometry and basic physics.
- Geometry-aware models lack behavioral fidelity in planning scenarios.
- Even the strongest models achieve only 2-3 out of 10 on human realism ratings.
- The WorldLens-26K dataset pairs numerical scores with textual rationales to bridge metrics and perception.
- WorldLens-Agent provides scalable, explainable auto-assessment aligned with human judgments.
Where Pith is reading between the lines
- Hybrid models merging texture strengths with geometry and behavior modules could reduce the observed trade-offs.
- The benchmark approach may expose parallel limitations when applied to world models in robotics or indoor environments.
- The preference dataset could be used to train models that generate outputs more aligned with human expectations from the start.
- Higher scores on closed-loop metrics would enable more reliable use of these models in end-to-end autonomous driving pipelines.
Load-bearing premise
The five aspects and 24 dimensions, plus the human-annotated preferences in the contributed dataset, fully capture physical and behavioral fidelity without bias or omission.
What would settle it
Development of a new driving world model that scores above 7 out of 10 on human realism ratings while also performing strongly on geometry consistency and closed-loop planning would challenge the finding that no approach dominates across all axes.
Figures






read the original abstract
Today's driving world models can generate remarkably realistic dash-cam videos, yet no single model excels universally. Some generate photorealistic textures but violate basic physics; others maintain geometric consistency but fail when subjected to closed-loop planning. This disconnect exposes a critical gap: the field evaluates how real generated worlds appear, but rarely whether they behave realistically. We introduce WorldLens, a unified benchmark that measures world-model fidelity across the full spectrum, from pixel quality and 4D geometry to closed-loop driving and human perceptual alignment, through five complementary aspects and 24 standardized dimensions. Our evaluation of six representative models reveals that no existing approach dominates across all axes: texture-rich models violate geometry, geometry-aware models lack behavioral fidelity, and even the strongest performers achieve only 2-3 out of 10 on human realism ratings. To bridge algorithmic metrics with human perception, we further contribute WorldLens-26K, a 26,808-entry human-annotated preference dataset pairing numerical scores with textual rationales, and WorldLens-Agent, a vision-language evaluator distilled from these judgments that enables scalable, explainable auto-assessment. Together, the benchmark, dataset, and agent form a unified ecosystem for assessing generated worlds not merely by visual appeal, but by physical and behavioral fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current driving world models exhibit trade-offs across fidelity dimensions, with no single model excelling universally; it introduces the WorldLens benchmark comprising five complementary aspects and 24 standardized dimensions spanning pixel quality, 4D geometry, closed-loop behavior, and human perceptual alignment. Evaluation of six representative models shows none dominates all axes, with even the strongest achieving only 2-3/10 on human realism ratings. The authors also release WorldLens-26K, a 26,808-entry human-annotated preference dataset with textual rationales, and WorldLens-Agent, a distilled vision-language model for scalable auto-evaluation.
Significance. If the benchmark dimensions prove comprehensive and the human annotations reliable, the work would be significant for redirecting the field from purely visual metrics toward physical and behavioral fidelity in world models. The contributed dataset and agent could enable reproducible, explainable evaluation at scale, addressing a noted gap between algorithmic scores and perceptual realism.
major comments (3)
- [Abstract and evaluation summary] The central claim that 'no existing approach dominates across all axes' and that strongest models score only 2-3/10 on human realism rests on the unvalidated assumption that the five aspects and 24 dimensions together measure physical and behavioral fidelity without major omissions (e.g., long-horizon dynamics or tire-road friction under load). No external validation such as correlation with real-world crash statistics or physicist ratings is provided to confirm sufficiency.
- [WorldLens-26K dataset description] Human-annotated preferences in WorldLens-26K are presented as ground truth for perceptual alignment, yet the manuscript provides no evidence that annotator judgments reflect fidelity rather than visual style or bias; absence of inter-annotator agreement statistics, expert validation, or correlation with objective physics measures leaves the 2-3/10 ratings vulnerable to reinterpretation.
- [Evaluation of six representative models] Metric definitions, model selection criteria, and statistical validation procedures are not detailed in the abstract or evaluation summary, making it impossible to assess whether reported trade-offs (texture-rich vs. geometry-aware models) are robust or sensitive to implementation choices.
minor comments (2)
- [Benchmark definition] Notation for the 24 dimensions could be clarified with an explicit table mapping each dimension to its aspect and measurement method.
- [Discussion] The manuscript should include a limitations section discussing potential under-sampling of closed-loop planner interactions.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We have carefully considered each point and provide point-by-point responses below. Where appropriate, we will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and evaluation summary] The central claim that 'no existing approach dominates across all axes' and that strongest models score only 2-3/10 on human realism rests on the unvalidated assumption that the five aspects and 24 dimensions together measure physical and behavioral fidelity without major omissions (e.g., long-horizon dynamics or tire-road friction under load). No external validation such as correlation with real-world crash statistics or physicist ratings is provided to confirm sufficiency.
Authors: We acknowledge that the WorldLens benchmark, while designed to cover a broad range of fidelity aspects based on established literature in computer vision and robotics, does not claim to be exhaustive. The dimensions were selected to capture key trade-offs observed in current models. We agree that additional external validations, such as correlations with real-world crash data or expert physicist assessments, would further strengthen the benchmark's validity. However, conducting such validations is beyond the scope of this work due to the complexity and data requirements involved. In the revised manuscript, we will expand the discussion section to explicitly address potential omissions, including long-horizon dynamics and physical interactions like tire-road friction, and outline these as directions for future work. This will clarify the scope and limitations of our claims without overstating the benchmark's comprehensiveness. revision: partial
-
Referee: [WorldLens-26K dataset description] Human-annotated preferences in WorldLens-26K are presented as ground truth for perceptual alignment, yet the manuscript provides no evidence that annotator judgments reflect fidelity rather than visual style or bias; absence of inter-annotator agreement statistics, expert validation, or correlation with objective physics measures leaves the 2-3/10 ratings vulnerable to reinterpretation.
Authors: We appreciate this feedback on the dataset validation. The full manuscript details the annotation protocol, including guidelines provided to annotators to focus on fidelity aspects rather than stylistic preferences. However, we agree that reporting inter-annotator agreement is essential for establishing reliability. We will add statistics such as Cohen's or Fleiss' kappa in the revised version. We will also include a discussion on potential biases and how the collection of textual rationales alongside scores helps in understanding and mitigating subjective influences. While direct correlation with objective physics measures is difficult for perceptual dimensions, we will explore and report any available correlations with existing geometric or behavioral metrics in the paper. revision: yes
-
Referee: [Evaluation of six representative models] Metric definitions, model selection criteria, and statistical validation procedures are not detailed in the abstract or evaluation summary, making it impossible to assess whether reported trade-offs (texture-rich vs. geometry-aware models) are robust or sensitive to implementation choices.
Authors: The detailed definitions of the 24 metrics, the criteria for selecting the six representative models (covering diverse architectures such as video diffusion models, autoregressive models, and others), and the statistical procedures (including multiple evaluation runs and confidence intervals) are thoroughly described in Sections 3 (Benchmark Design) and 4 (Experiments) of the full manuscript. To make this information more accessible, we will revise the abstract and the evaluation summary paragraph to include concise descriptions of key metrics, model selection rationale, and validation approaches. This will allow readers to better assess the robustness of the observed trade-offs without needing to refer to the full sections immediately. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation is independent of model internals
full rationale
The paper presents an empirical evaluation of six existing driving world models on a newly introduced benchmark (WorldLens) consisting of five aspects and 24 dimensions, supported by a separate human-annotated dataset (WorldLens-26K) and a distilled VLM evaluator. The central claim—that no model dominates across axes and top performers score only 2-3/10 on human realism—is derived directly from these measurements and annotations rather than from any self-referential definition, fitted parameter, or self-citation chain. No equations or derivations reduce the reported performance gaps to the inputs by construction; the benchmark metrics and human preferences function as external probes. The WorldLens-Agent is trained on the annotations but is presented only as a scalable proxy, not as the source of the primary findings. This is a standard benchmarking contribution with self-contained empirical content.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Common video quality metrics and geometric consistency measures are appropriate proxies for world model fidelity
- domain assumption Human preference annotations provide a valid and consistent measure of perceptual alignment
invented entities (3)
-
WorldLens benchmark
no independent evidence
-
WorldLens-26K dataset
no independent evidence
-
WorldLens-Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
-
[3]
nuScenes: A multimodal dataset for autonomous driving
Holger Caesar et al. nuScenes: A multimodal dataset for autonomous driving. InCVPR, pages 11621–11631, 2020
work page 2020
-
[4]
Emerging properties in self-supervised vision transformers
Mathilde Caron et al. Emerging properties in self-supervised vision transformers. InICCV, pages 9650–9660, 2021
work page 2021
-
[5]
Quo vadis, action recognition? A new model and the kinetics dataset
Joao Carreira et al. Quo vadis, action recognition? A new model and the kinetics dataset. InCVPR, 2017
work page 2017
-
[6]
NA VSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking
Daniel Dauner et al. NA VSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking. In NeurIPS, pages 28706–28719, 2024
work page 2024
-
[7]
Shuxiao Ding et al. ADA-Track: End-to-end multi-camera 3D multi-object tracking with alternating detection and asso- ciation. InCVPR, pages 15184–15194, 2024
work page 2024
-
[8]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
work page 2021
-
[9]
MagicDrive: Street view generation with diverse 3D geometry control
Ruiyuan Gao et al. MagicDrive: Street view generation with diverse 3D geometry control. InICLR, 2023
work page 2023
-
[10]
DiST-4D: Disentangled spatiotemporal dif- fusion with metric depth for 4D driving scene generation
Jiazhe Guo et al. DiST-4D: Disentangled spatiotemporal dif- fusion with metric depth for 4D driving scene generation. In ICCV, pages 27231–27241, 2025
work page 2025
-
[11]
TransReID: Transformer-based object re- identification
Shuting He et al. TransReID: Transformer-based object re- identification. InICCV, pages 15013–15022, 2021
work page 2021
-
[12]
Planning-oriented autonomous driving
Yihan Hu et al. Planning-oriented autonomous driving. In CVPR, pages 17853–17862, 2023
work page 2023
-
[13]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang et al. VBench: Comprehensive benchmark suite for video generative models. InCVPR, 2024
work page 2024
-
[14]
V AD: Vectorized scene representation for efficient autonomous driving
Bo Jiang et al. V AD: Vectorized scene representation for efficient autonomous driving. InICCV, 2023
work page 2023
-
[15]
MUSIQ: Multi-scale image quality trans- former
Junjie Ke et al. MUSIQ: Multi-scale image quality trans- former. InICCV, pages 5148–5157, 2021
work page 2021
-
[16]
3D Gaussian splatting for real-time radiance field rendering.ACM TOG, 42(4):1–14, 2023
Bernhard Kerbl et al. 3D Gaussian splatting for real-time radiance field rendering.ACM TOG, 42(4):1–14, 2023
work page 2023
-
[17]
arXiv preprint arXiv:2509.07996 (2025) 2, 4
Lingdong Kong et al. 3D and 4D world modeling: A survey. arXiv preprint arXiv:2509.07996, 2025
-
[18]
WorldLens: Full-spectrum evaluations of driving world models in real world
Ao Liang et al. WorldLens: Full-spectrum evaluations of driving world models in real world. InCVPR, 2026
work page 2026
-
[19]
BEVFusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation
Zhijian Liu et al. BEVFusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. InICRA, pages 2774–2781, 2023
work page 2023
-
[20]
Xiaomi OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Jinghui Lu et al. OneVL: One-step latent reasoning and planning with vision-language explanation.arXiv preprint arXiv:2604.18486, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Dreamforge: Motion-aware autoregressive video generation for multi-view driving scenes
Jianbiao Mei et al. DreamForge: Motion-aware autoregres- sive video generation for multi-view driving scenes.arXiv preprint arXiv:2409.04003, 2024
-
[22]
Genie 2: A large-scale foundation world model, 2024
Jack Parker-Holder et al. Genie 2: A large-scale foundation world model, 2024
work page 2024
-
[23]
Learning transferable visual models from natural language supervision
Alec Radford et al. Learning transferable visual models from natural language supervision. InICML, pages 8748–8763. PMLR, 2021
work page 2021
-
[24]
SAM 2: Segment anything in images and videos
Nikhila Ravi et al. SAM 2: Segment anything in images and videos. InICLR, 2025
work page 2025
-
[25]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren et al. Grounded SAM: Assembling open- world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Gen3C: 3D-informed world-consistent video generation with precise camera control
Xuanchi Ren et al. Gen3C: 3D-informed world-consistent video generation with precise camera control. InCVPR, pages 6121–6132, 2025
work page 2025
-
[27]
Lloyd Russell et al. GAIA-2: A controllable multi-view gen- erative world model for autonomous driving.arXiv preprint arXiv:2503.20523, 2025
-
[28]
Open Driving World Models (OpenDWM).https://github.com/SenseTime- FVG/OpenDWM, 2025
SenseTime-FVG. Open Driving World Models (OpenDWM).https://github.com/SenseTime- FVG/OpenDWM, 2025
work page 2025
-
[29]
LoFTR: Detector-free local feature match- ing with transformers
Jiaming Sun et al. LoFTR: Detector-free local feature match- ing with transformers. InCVPR, pages 8922–8931, 2021
work page 2021
-
[30]
SparseOCC: Rethinking sparse latent repre- sentation for vision-based semantic occupancy prediction
Pin Tang et al. SparseOCC: Rethinking sparse latent repre- sentation for vision-based semantic occupancy prediction. In CVPR, pages 15035–15044, 2024
work page 2024
-
[31]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner et al. Towards accurate generative mod- els of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
SegFormer: Simple and efficient design for semantic segmentation with transformers
Enze Xie et al. SegFormer: Simple and efficient design for semantic segmentation with transformers. InNeurIPS, pages 12077–12090, 2021
work page 2021
-
[33]
RLGF: Reinforcement learning with geo- metric feedback for autonomous driving video generation
Tianyi Yan et al. RLGF: Reinforcement learning with geo- metric feedback for autonomous driving video generation. In NeurIPS, 2025
work page 2025
-
[34]
Lihe Yang et al. Depth anything v2. InNeurIPS, pages 21875–21911, 2024
work page 2024
-
[35]
DriveArena: A closed-loop generative simulation platform for autonomous driving
Xuemeng Yang et al. DriveArena: A closed-loop generative simulation platform for autonomous driving. InICCV, pages 26933–26943, 2025
work page 2025
-
[36]
X-Scene: Large-scale driving scene gen- eration with high fidelity and flexible controllability
Yu Yang et al. X-Scene: Large-scale driving scene gen- eration with high fidelity and flexible controllability. In NeurIPS, 2025
work page 2025
-
[37]
DriveDreamer-2: LLM-enhanced world models for diverse driving video generation
Guosheng Zhao et al. DriveDreamer-2: LLM-enhanced world models for diverse driving video generation. InAAAI, pages 10412–10420, 2025
work page 2025
-
[38]
Cross-video identity correlating for person re-identification pre-training.NeurIPS, 37, 2024
Jialong Zuo et al. Cross-video identity correlating for person re-identification pre-training.NeurIPS, 37, 2024. 6
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.