Recognition: 2 theorem links
· Lean TheoremTMPO: Trajectory Matching Policy Optimization for Diverse and Efficient Diffusion Alignment
Pith reviewed 2026-05-14 21:57 UTC · model grok-4.3
The pith
TMPO replaces scalar reward maximization with matching K trajectories to a reward-induced Boltzmann distribution to preserve coverage and boost diversity in diffusion alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TMPO replaces scalar reward maximization with trajectory-level reward distribution matching. Specifically, the Softmax Trajectory Balance (Softmax-TB) objective aligns the policy probabilities of K trajectories to the Boltzmann distribution induced by the reward function. The paper proves this objective inherits the mode-covering property of forward KL divergence, thereby preserving probability mass over all acceptable trajectories while still optimizing reward. Dynamic Stochastic Tree Sampling further shares denoising prefixes and branches trajectories at scheduled steps to reduce training cost on large flow-matching models.
What carries the argument
Softmax Trajectory Balance (Softmax-TB) objective, which matches the probabilities of K sampled trajectories to a reward-induced Boltzmann distribution and thereby carries the mode-covering property of forward KL divergence into the alignment process.
If this is right
- Generative diversity improves by 9.1% over state-of-the-art alignment methods.
- Downstream performance remains competitive on human preference, compositional generation, and text rendering tasks.
- An optimal empirical trade-off between reward and diversity is attained across the tested settings.
- Multi-trajectory training time on large flow-matching models is reduced by sharing denoising prefixes.
Where Pith is reading between the lines
- If the trajectory-matching property holds beyond diffusion, the same objective could be tested on other autoregressive generators where mode collapse is also observed.
- Dynamic tree sampling may extend to any long-horizon RL setting where multiple rollouts share early computation.
- The explicit use of a Boltzmann target suggests that future work could vary the temperature schedule to control the diversity-reward frontier more finely.
Load-bearing premise
That matching K trajectories to the reward-induced Boltzmann distribution via Softmax-TB will reliably preserve coverage over acceptable trajectories in practice without introducing instabilities or requiring extensive hyperparameter tuning that offsets the gains.
What would settle it
A head-to-head experiment on a standard alignment benchmark in which TMPO produces lower diversity scores or visibly collapses to fewer modes than the prior best method while keeping reward fixed.
Figures









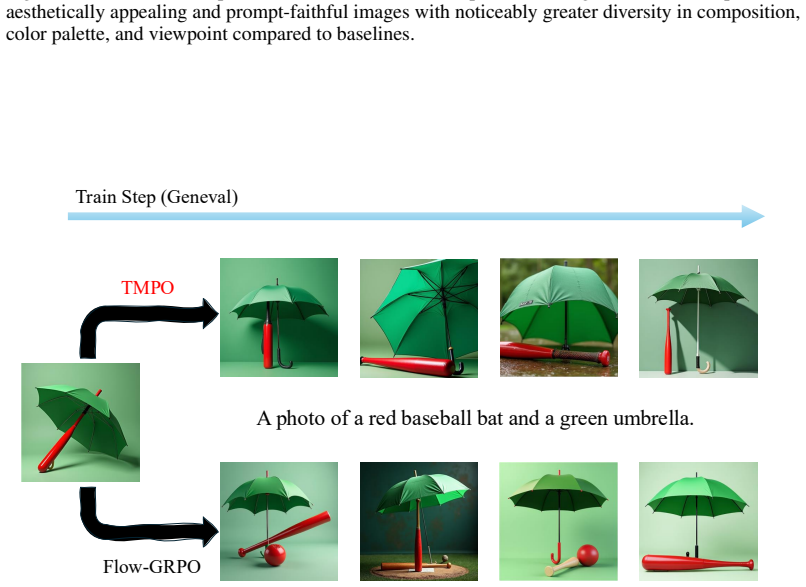
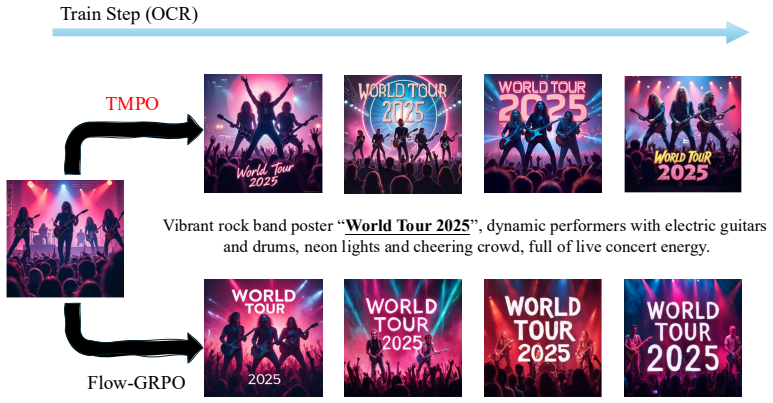

read the original abstract
Reinforcement learning (RL) has shown extraordinary potential in aligning diffusion models to downstream tasks, yet most of them still suffer from significant reward hacking, which degrades generative diversity and quality by inducing visual mode collapse and amplifying unreliable rewards. We identify the root cause as the mode-seeking nature of these methods, which maximize expected reward without effectively constraining probability distribution over acceptable trajectories, causing concentration on a few high-reward paths. In contrast, we propose Trajectory Matching Policy Optimization (TMPO), which replaces scalar reward maximization with trajectory-level reward distribution matching. Specifically, TMPO introduces a Softmax Trajectory Balance (Softmax-TB) objective to match the policy probabilities of K trajectories to a reward-induced Boltzmann distribution. We prove that this objective inherits the mode-covering property of forward KL divergence, preserving coverage over all acceptable trajectories while optimizing reward. To further reduce multi-trajectory training time on large-scale flow-matching models, TMPO incorporates Dynamic Stochastic Tree Sampling, where trajectories share denoising prefixes and branch at dynamically scheduled steps, reducing redundant computation while improving training effectiveness. Extensive results across diverse alignment tasks such as human preference, compositional generation and text rendering show that TMPO improves generative diversity over state-of-the-art methods by 9.1%, and achieves competitive performance in all downstream and efficiency metrics, attaining the optimal trade-off between reward and diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Trajectory Matching Policy Optimization (TMPO) to address reward hacking and mode collapse in RL alignment of diffusion models. It replaces scalar reward maximization with a Softmax Trajectory Balance (Softmax-TB) objective that matches the policy probabilities of K sampled trajectories to a reward-induced Boltzmann distribution, with a claimed proof that this inherits the mode-covering property of forward KL divergence. Dynamic Stochastic Tree Sampling is introduced to share denoising prefixes and reduce computation for large flow-matching models. Experiments across human preference, compositional generation, and text rendering tasks report a 9.1% improvement in generative diversity over state-of-the-art methods while achieving competitive reward and efficiency metrics.
Significance. If the theoretical guarantee holds under the implemented sampling procedure and the diversity gains prove robust across tasks, TMPO could meaningfully advance RL-based diffusion alignment by providing a distribution-matching alternative to mode-seeking objectives, helping mitigate visual collapse and unreliable reward amplification without sacrificing downstream performance.
major comments (2)
- [§3] §3: The proof that the Softmax-TB objective inherits forward KL mode-covering assumes independent sampling of the K trajectories from the current policy so that the empirical distribution converges to the Boltzmann target. The Dynamic Stochastic Tree Sampling procedure in §4 shares denoising prefixes and branches at scheduled steps, inducing correlations among the K trajectories that can bias the empirical distribution away from the target, especially in high-dimensional spaces where early prefixes dominate; this approximation error is not bounded or analyzed.
- [Experiments] Experiments section: The reported 9.1% diversity improvement and optimal reward-diversity trade-off are stated without reference to the precise diversity metric (e.g., which coverage or entropy measure), the full list of baselines, the number of independent runs, or error bars; without these, the claim that TMPO attains the optimal trade-off cannot be verified from the presented data.
minor comments (2)
- The definition of the Softmax-TB loss could be presented with an explicit equation number immediately after its introduction to aid readability.
- Figure captions for the efficiency and diversity plots should include the exact hyperparameter settings (K, branching schedule) used in each curve.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below with clarifications and commit to revisions that strengthen the theoretical grounding and experimental transparency of the manuscript.
read point-by-point responses
-
Referee: [§3] §3: The proof that the Softmax-TB objective inherits forward KL mode-covering assumes independent sampling of the K trajectories from the current policy so that the empirical distribution converges to the Boltzmann target. The Dynamic Stochastic Tree Sampling procedure in §4 shares denoising prefixes and branches at scheduled steps, inducing correlations among the K trajectories that can bias the empirical distribution away from the target, especially in high-dimensional spaces where early prefixes dominate; this approximation error is not bounded or analyzed.
Authors: We acknowledge that the proof in §3 is stated under the assumption of independent sampling of the K trajectories. The Dynamic Stochastic Tree Sampling in §4 deliberately introduces prefix sharing to reduce redundant computation on large flow-matching models, which does induce correlations. While the dynamic branching schedule is designed to preserve sufficient diversity in the sampled set, we agree that the manuscript lacks a formal bound on the resulting approximation error to the target Boltzmann distribution. In the revised manuscript we will add a dedicated paragraph in §3 (or a new subsection) that explicitly discusses this approximation, provides a qualitative analysis of the bias under the chosen branching schedule, and includes additional empirical diagnostics showing that the mode-covering behavior remains intact in practice. revision: yes
-
Referee: Experiments section: The reported 9.1% diversity improvement and optimal reward-diversity trade-off are stated without reference to the precise diversity metric (e.g., which coverage or entropy measure), the full list of baselines, the number of independent runs, or error bars; without these, the claim that TMPO attains the optimal trade-off cannot be verified from the presented data.
Authors: We thank the referee for noting this presentational gap. The 9.1% figure is computed with the coverage entropy metric defined in §5.1 of the manuscript; the baselines comprise the full set of methods listed in Table 1 (PPO, DPO, RAFT, and the diffusion-specific variants). All quantitative results were obtained from five independent runs with different random seeds, and standard-deviation error bars appear in the appendix figures. In the revised version we will (i) restate the exact diversity metric in the main Experiments section, (ii) enumerate every baseline explicitly in the text, and (iii) move the error bars into the primary figures so that the reward-diversity trade-off claim can be directly verified from the presented data. revision: yes
Circularity Check
No significant circularity: Softmax-TB objective and mode-covering proof are independent derivations
full rationale
The paper introduces TMPO via a new Softmax-TB objective that matches K policy trajectories to a reward-induced Boltzmann distribution, then claims (with an explicit proof) that this inherits forward-KL mode-covering. This is a first-principles construction, not a renaming or self-referential fit. Dynamic Stochastic Tree Sampling is presented purely as an efficiency implementation detail that shares prefixes but does not alter the core objective or proof assumptions in a way that reduces the result to its inputs. No load-bearing self-citation, fitted-parameter-renamed-as-prediction, or ansatz-smuggled-via-citation patterns appear in the derivation chain. The central claim therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- K
axioms (1)
- domain assumption Softmax-TB objective inherits the mode-covering property of forward KL divergence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Softmax Trajectory Balance (Softmax-TB) objective to match the policy probabilities of K trajectories to a reward-induced Boltzmann distribution. We prove that this objective inherits the mode-covering property of forward KL divergence
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ai = log exp(βRi)/∑exp(βRj) − log Pθ(τi)/∑Pθ(τj)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
work page 2022
-
[2]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InICML, 2024
work page 2024
-
[3]
FLUX.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. FLUX.https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[4]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InICLR, 2024
work page 2024
-
[5]
DPOK: Reinforcement learning for fine-tuning text-to-image diffusion models
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mo- hammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. DPOK: Reinforcement learning for fine-tuning text-to-image diffusion models. InNeurIPS, 2023
work page 2023
-
[6]
Flow-GRPO: Training flow matching models via online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online RL. InNeurIPS, 2025
work page 2025
-
[7]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. DanceGRPO: Unleashing GRPO on visual generation.arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InICLR, 2021
work page 2021
-
[9]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.arXiv preprint arXiv:2303.08797, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
ImageReward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. ImageReward: Learning and evaluating human preferences for text-to-image generation. InNeurIPS, 2023
work page 2023
-
[11]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human Preference Score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
TextDiffuser: Diffusion models as text painters
Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, and Furu Wei. TextDiffuser: Diffusion models as text painters. InNeurIPS, 2023
work page 2023
-
[13]
The effects of reward misspecification: Mapping and mitigating misaligned models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The effects of reward misspecification: Mapping and mitigating misaligned models. InICLR, 2022
work page 2022
-
[14]
Defining and characterizing reward gaming
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward gaming. InNeurIPS, 2022
work page 2022
-
[15]
GARDO: Reinforcing diffusion models without reward hacking
Haoran He, Yuxiao Ye, Jie Liu, Jiajun Liang, Zhiyong Wang, Ziyang Yuan, Xintao Wang, Hangyu Mao, Pengfei Wan, and Ling Pan. GARDO: Reinforcing diffusion models without reward hacking.arXiv preprint arXiv:2512.24138, 2025
-
[16]
Yunqi Hong, Kuei-Chun Kao, Hengguang Zhou, and Cho-Jui Hsieh. Understanding reward hacking in text-to-image reinforcement learning.arXiv preprint arXiv:2601.03468, 2026
-
[17]
Anthony GX-Chen, Jatin Prakash, Jeff Guo, Rob Fergus, and Rajesh Ranganath. KL-regularized reinforce- ment learning is designed to mode collapse.arXiv preprint arXiv:2510.20817, 2025
-
[18]
RewardDance: Reward scaling in visual generation.arXiv preprint arXiv:2509.08826, 2025
Jie Wu, Yu Gao, Zilyu Ye, Ming Li, Liang Li, Hanzhong Guo, Jie Liu, Zeyue Xue, Xiaoxia Hou, Wei Liu, et al. RewardDance: Reward scaling in visual generation.arXiv preprint arXiv:2509.08826, 2025
-
[19]
GRPO-Guard: Mitigating implicit over-optimization in flow matching via regulated clipping, 2025
Jing Wang, Jiajun Liang, Jie Liu, Henglin Liu, Gongye Liu, Jun Zheng, Wanyuan Pang, Ao Ma, Zhenyu Xie, Xintao Wang, et al. GRPO-Guard: Mitigating implicit over-optimization in flow matching via regulated clipping.arXiv preprint arXiv:2510.22319, 2025. 10
-
[20]
Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
Yibin Wang, Zhimin Li, Yuhang Zang, Yujie Zhou, Jiazi Bu, Chunyu Wang, Qinglin Lu, Cheng Jin, and Jiaqi Wang. Pref-GRPO: Pairwise preference reward-based GRPO for stable text-to-image reinforcement learning.arXiv preprint arXiv:2508.20751, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Flow network based generative models for non-iterative diverse candidate generation
Emmanuel Bengio, Moksh Jain, Maksym Korablyov, Doina Precup, and Yoshua Bengio. Flow network based generative models for non-iterative diverse candidate generation. InNeurIPS, 2021
work page 2021
-
[22]
Trajectory balance: Improved credit assignment in GFlowNets
Nikolay Malkin, Moksh Jain, Emmanuel Bengio, Chen Sun, and Yoshua Bengio. Trajectory balance: Improved credit assignment in GFlowNets. InNeurIPS, 2022
work page 2022
-
[23]
Dinghuai Zhang, Ricky T. Q. Chen, Chenghao Liu, Aaron Courville, and Yoshua Bengio. Diffusion generative flow samplers: Improving learning signals through partial trajectory optimization. InICLR, 2024
work page 2024
-
[24]
Xiao, Weiyang Liu, Yoshua Bengio, and Dinghuai Zhang
Zhen Liu, Tim Z. Xiao, Weiyang Liu, Yoshua Bengio, and Dinghuai Zhang. Efficient diversity-preserving diffusion alignment via gradient-informed GFlowNets. InICLR, 2025
work page 2025
-
[25]
FlowRL: Matching reward distributions for LLM reasoning
Xuekai Zhu, Daixuan Cheng, Dinghuai Zhang, Hengli Li, Kaiyan Zhang, Che Jiang, Youbang Sun, Ermo Hua, Yuxin Zuo, Xingtai Lv, et al. FlowRL: Matching reward distributions for LLM reasoning. InICLR, 2026
work page 2026
-
[26]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Yiming Cheng, Miles Yang, Zhao Zhong, and Liefeng Bo. MixGRPO: Unlocking flow-based GRPO efficiency with mixed ODE-SDE.arXiv preprint arXiv:2507.21802, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Xiaolong Fu, Lichen Ma, Zipeng Guo, Gaojing Zhou, Chongxiao Wang, ShiPing Dong, Shizhe Zhou, Ximan Liu, Jingling Fu, Tan Lit Sin, et al. Dynamic-TreeRPO: Breaking the independent trajectory bottleneck with structured sampling.arXiv preprint arXiv:2509.23352, 2025
-
[28]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver++: Fast solver for guided sampling of diffusion probabilistic models.arXiv preprint arXiv:2211.01095, 2022
-
[29]
Susskind, Navdeep Jaitly, and Shuangfei Zhai
Dinghuai Zhang, Yizhe Zhang, Jiatao Gu, Ruixiang Zhang, Joshua M. Susskind, Navdeep Jaitly, and Shuangfei Zhai. Improving GFlowNets for text-to-image diffusion alignment.Transactions on Machine Learning Research, 2025
work page 2025
-
[30]
TreeGRPO: Tree-advantage GRPO for online RL post-training of diffusion models
Zheng Ding and Weirui Ye. TreeGRPO: Tree-advantage GRPO for online RL post-training of diffusion models. InICLR, 2026
work page 2026
-
[31]
Pick-a-Pic: An open dataset of user preferences for text-to-image generation
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-Pic: An open dataset of user preferences for text-to-image generation. InNeurIPS, 2023
work page 2023
-
[32]
Jonathan Ho, Ajay N. Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
work page 2020
-
[33]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InICLR, 2021
work page 2021
-
[34]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InICLR, 2023
work page 2023
-
[35]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023
work page 2023
-
[36]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. InICML, 2023
work page 2023
-
[38]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InNeurIPS, 2022
work page 2022
-
[39]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback. InNeurIPS, 2020
work page 2020
-
[40]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022. 11
work page 2022
-
[41]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervision.Transactions on Machine Learning Research, 2024
work page 2024
-
[42]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
work page 2023
-
[43]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
GenEval: An object-focused framework for evaluating text-to-image alignment
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. GenEval: An object-focused framework for evaluating text-to-image alignment. InNeurIPS Datasets and Benchmarks Track, 2023
work page 2023
-
[45]
Diederik P. Kingma and Max Welling. Auto-encoding variational Bayes. InICLR, 2014
work page 2014
-
[46]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021
work page 2021
-
[47]
Stability AI. Stable Diffusion 3.5 Medium. https://huggingface.co/stabilityai/ stable-diffusion-3.5-medium, 2024
work page 2024
-
[48]
Coefficients-preserving sampling for reinforcement learning with flow matching
Feng Wang and Zihao Yu. Coefficients-preserving sampling for reinforcement learning with flow matching. arXiv preprint arXiv:2509.05952, 2025
-
[49]
Singh, DJ Strouse, Tuomas Sandholm, Ruslan Salakhutdinov, Anca D
Ted Moskovitz, Aaditya K. Singh, DJ Strouse, Tuomas Sandholm, Ruslan Salakhutdinov, Anca D. Dragan, and Stephen McAleer. Confronting reward model overoptimization with constrained RLHF. InICLR, 2024
work page 2024
-
[50]
Reward model ensembles help mitigate overoptimization.arXiv preprint arXiv:2310.02743, 2023
Thomas Coste, Usman Anwar, Robert Kirk, and David Krueger. Reward model ensembles help mitigate overoptimization.arXiv preprint arXiv:2310.02743, 2023. 12 Appendix of TMPO: Trajectory Matching Policy Optimization for Diverse and Efficient Diffusion Alignment A Theoretical Derivations of Softmax-TB 15 A.1 Boltzmann Target and Partition-Free Softmax Matchin...
-
[51]
Between branch points, deterministic ODE integration advances the latent
Tree rollout.On each GPU, the stochastic tree sampler generates K=27 terminal trajectories for its prompt via T=3 branch points with B=3 children each, yielding 8×27 = 216 images per iteration. Between branch points, deterministic ODE integration advances the latent. When the first branch point falls at step 1, the B child trajectories are initialized fro...
-
[52]
Rewards are z-score normalized in the joint setting
Reward evaluation.Each terminal image x(i) 0 is decoded and scored by the reward model(s). Rewards are z-score normalized in the joint setting. 4.Advantage computation.The detached Softmax-TB advantageA ⊥ i is computed per Eq. (7)
-
[53]
IS ratio recomputation.The current policy πθ recomputes per-step log-probabilities at each branch point, yielding the bias-corrected IS ratioˆρi per Eq. (32)
-
[54]
Policy update.The PPO-style clipped loss LTMPO (Eq. (6)) plus a KL reference penalty is minimized via AdamW. The old policy πold is the frozen policy from the latest rollout; its log- probabilities are stored before the gradient update and remain fixed throughout the IS updates. 24 EMA-smoothed parameters (decay 0.9, update interval 8) are maintained sepa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.