Recognition: 2 theorem links
· Lean TheoremLoopUS: Recasting Pretrained LLMs into Looped Latent Refinement Models
Pith reviewed 2026-05-13 07:17 UTC · model grok-4.3
The pith
LoopUS converts any pretrained LLM into an encoder-looped block-decoder structure for iterative latent refinement that raises reasoning performance without longer outputs or new training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LoopUS recasts a pretrained LLM into an encoder, a looped reasoning block, and a decoder. Block decomposition follows observed staged dynamics in the hidden representations. An input-dependent selective gate limits hidden-state drift. Random deep supervision enables memory-efficient training over long recursive steps. A confidence head supports adaptive early exit. Together these turn a non-looped model into a stable looped latent-refinement architecture that improves reasoning without extending output traces or requiring recurrent pretraining.
What carries the argument
The looped reasoning block, which applies the model's own layers recursively to refine a latent hidden state, guided by block decomposition, stabilized by an input-dependent selective gate, random deep supervision, and a confidence head for early exiting.
Load-bearing premise
That any pretrained LLM can be split into blocks and equipped with the selective gate, random supervision, and confidence head without hidden-state drift or loss of its original capabilities.
What would settle it
Apply LoopUS to a standard model such as Llama-7B and measure either a drop in accuracy on non-reasoning benchmarks or divergence of hidden-state norms across loop iterations.
Figures














read the original abstract
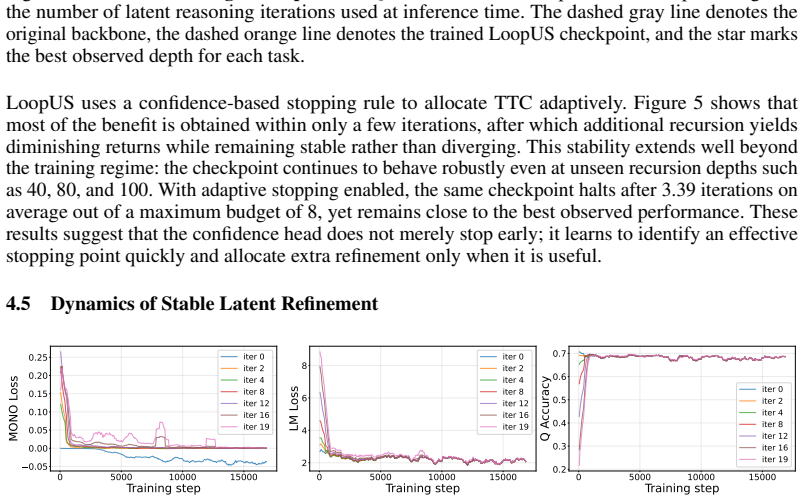
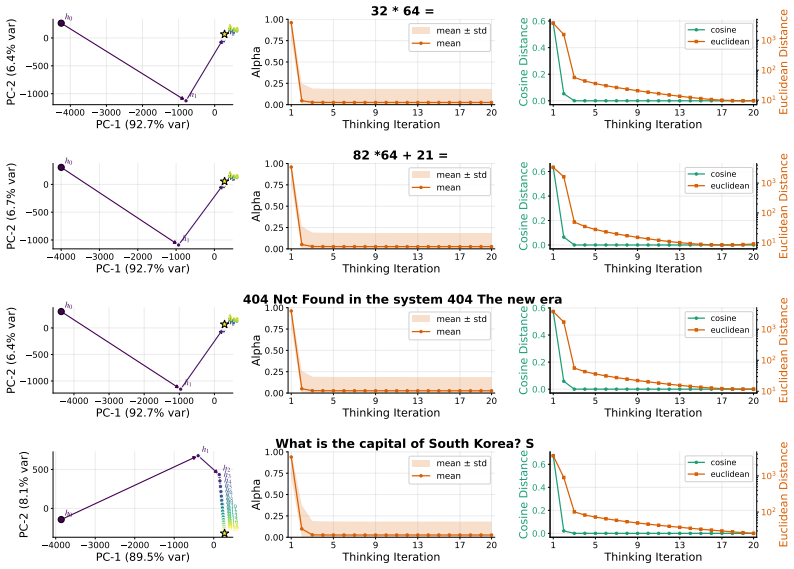
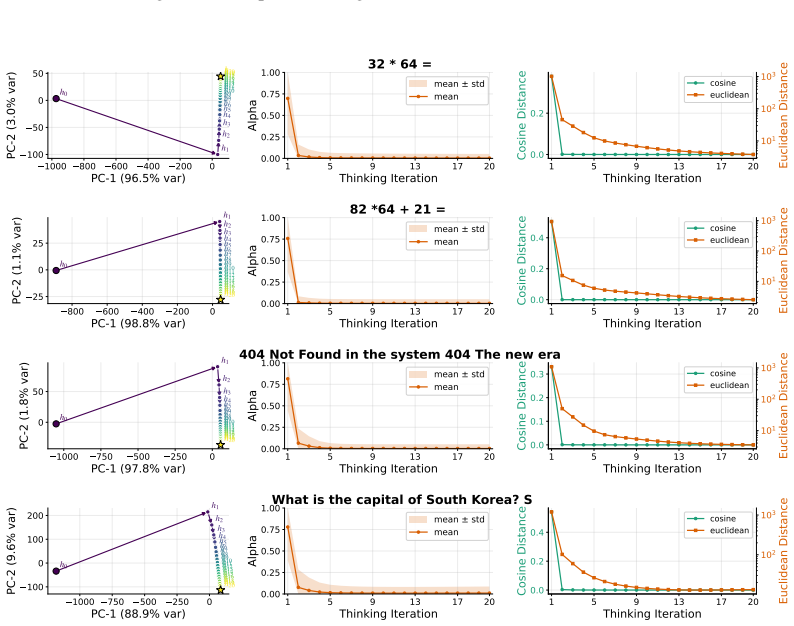
Looped computation shows promise in improving the reasoning-oriented performance of LLMs by scaling test-time compute. However, existing approaches typically require either training recurrent models from scratch or applying disruptive retrofits, which involve substantial computational costs and may compromise pretrained capabilities. To address these limitations, we introduce \textbf{Looped Depth Up-Scaling} (LoopUS), a post-training framework that converts a standard pretrained LLM into a looped architecture. As a key technical contribution, LoopUS recasts the pretrained LLM into an encoder, a looped reasoning block, and a decoder. It operationalizes this latent-refinement architecture through four core components: (1) block decomposition, guided by staged representation dynamics; (2) an input-dependent selective gate to mitigate hidden-state drift; (3) random deep supervision for memory-efficient learning over long recursive horizons; and (4) a confidence head for adaptive early exiting. Collectively, these mechanisms transform a standard non-looped model into a looped form while stabilizing it against both computational bottlenecks and representation collapse. Through stable latent looping, LoopUS improves reasoning-oriented performance without extending the generated traces or requiring recurrent training from scratch. For more details, see https://thrillcrazyer.github.io/LoopUS
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoopUS, a post-training framework that recasts a pretrained LLM into an encoder, a looped reasoning block, and a decoder. The transformation is realized via four components: block decomposition guided by staged representation dynamics, an input-dependent selective gate to mitigate hidden-state drift, random deep supervision for memory-efficient training over long horizons, and a confidence head enabling adaptive early exiting. The central claim is that these mechanisms enable stable latent looping, improve reasoning-oriented performance, and avoid both computational bottlenecks and representation collapse without requiring recurrent training from scratch or extending output traces.
Significance. If the empirical claims hold, the work would be significant for test-time compute scaling: it offers a post-training route to looped refinement on arbitrary pretrained LLMs, potentially improving reasoning without the cost of training recurrent models from scratch or sacrificing original capabilities. The combination of selective gating and deep supervision is presented as a general stabilizer, which, if validated, would be a useful addition to the literature on latent-space iteration.
major comments (3)
- [Abstract / §3 (Method)] The manuscript supplies no quantitative results, ablation studies, or error analysis to support the claims of improved reasoning performance and stability against representation collapse. The abstract and method description alone do not allow assessment of whether the four components actually deliver the promised gains on standard benchmarks.
- [§3.2–3.3] The description of the input-dependent selective gate and the random deep supervision mechanism lacks explicit equations or pseudocode. Without these, it is impossible to verify how the gate bounds drift over recursive steps or how the supervision schedule interacts with the looped block.
- [§4 (Experiments) / §5 (Discussion)] The claim that the decomposition and added heads can be applied to any pretrained LLM without capability loss is stated but not tested; no before/after comparisons on non-reasoning tasks or capability retention metrics are reported.
minor comments (2)
- [§3] Notation for the looped block, the selective gate, and the confidence head should be introduced with consistent symbols and a single diagram that shows data flow across iterations.
- [§2] The manuscript would benefit from a short related-work subsection that explicitly contrasts LoopUS with prior retrofitting methods (e.g., those requiring full recurrent retraining) rather than only citing them in passing.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We agree that additional empirical validation and methodological clarity are needed to strengthen the paper. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract / §3 (Method)] The manuscript supplies no quantitative results, ablation studies, or error analysis to support the claims of improved reasoning performance and stability against representation collapse. The abstract and method description alone do not allow assessment of whether the four components actually deliver the promised gains on standard benchmarks.
Authors: We acknowledge that the current manuscript emphasizes the post-training framework and architectural components without including quantitative benchmarks, ablations, or stability analyses. In the revision we will add results on standard reasoning benchmarks (e.g., GSM8K, MATH), component-wise ablations, and metrics for hidden-state drift and representation collapse to directly support the performance and stability claims. revision: yes
-
Referee: [§3.2–3.3] The description of the input-dependent selective gate and the random deep supervision mechanism lacks explicit equations or pseudocode. Without these, it is impossible to verify how the gate bounds drift over recursive steps or how the supervision schedule interacts with the looped block.
Authors: We agree that the absence of explicit formulations hinders verification. The revised manuscript will include the full mathematical definition of the input-dependent selective gate (including the drift-bounding formulation) and pseudocode for the random deep supervision schedule, clarifying its interaction with the looped reasoning block and memory-efficient training over long horizons. revision: yes
-
Referee: [§4 (Experiments) / §5 (Discussion)] The claim that the decomposition and added heads can be applied to any pretrained LLM without capability loss is stated but not tested; no before/after comparisons on non-reasoning tasks or capability retention metrics are reported.
Authors: The manuscript presents this as an intended property of the post-training approach, but we recognize that empirical confirmation is required. We will add before/after evaluations on non-reasoning tasks (e.g., MMLU, GLUE subsets) and capability-retention metrics in the revised §4 and §5 to substantiate that original capabilities are preserved. revision: yes
Circularity Check
No significant circularity; architectural recipe with independent mechanisms
full rationale
The paper describes LoopUS as a post-training framework that decomposes a pretrained LLM into encoder/looped-block/decoder components using block decomposition guided by staged representation dynamics, an input-dependent selective gate, random deep supervision, and a confidence head. No equations, fitted parameters, or predictions are presented that reduce to their own inputs by construction. The central claim is an engineering recipe for stable latent looping, justified by the combination of these mechanisms rather than any self-referential derivation or self-citation chain. The argument relies on post-training application to arbitrary pretrained models, with no load-bearing uniqueness theorems or ansatzes imported from prior author work. This is a standard non-circular architectural proposal.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pretrained LLMs exhibit staged representation dynamics that permit stable block decomposition
- domain assumption Looped hidden-state updates can be stabilized by input-dependent gating without retraining the base weights
invented entities (2)
-
input-dependent selective gate
no independent evidence
-
confidence head
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
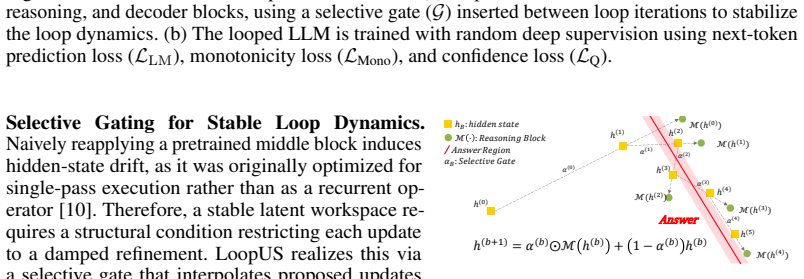
h(b+1)=α(b)⊙M(h(b))+(1-α(b))⊙h(b) with α=exp(Δ⊙A), Δ=softplus(Wδ), enforcing damped refinement and convergent trajectories
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
block decomposition guided by staged representation dynamics; middle layers form reusable latent workspace
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mamba-3: Improved sequence modeling using state space principles
Aakash Lahoti, Kevin Li, Berlin Chen, Caitlin Wang, Aviv Bick, J Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=HwCvaJOiCj
work page 2026
-
[2]
Inference scaling laws: An empirical analysis of compute-optimal inference for LLM problem-solving
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for LLM problem-solving. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=VNckp7JEHn
work page 2025
-
[3]
Scaling LLM test- time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test- time compute optimally can be more effective than scaling parameters for reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=4FWAwZtd2n
work page 2025
-
[4]
Scaling Latent Reasoning via Looped Language Models
Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, et al. Scaling latent reasoning via looped language models.arXiv preprint arXiv:2510.25741, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Mixture-of- recursions: Learning dynamic recursive depths for adaptive token-level computation
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, and Se-Young Yun. Mixture-of- recursions: Learning dynamic recursive depths for adaptive token-level computation. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.n...
work page 2025
-
[6]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bar- toldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute 10 with latent reasoning: A recurrent depth approach, 2025. URL https://arxiv.org/abs/ 2502.05171
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Energy-based transformers are scalable learners and thinkers
Alexi Gladstone, Ganesh Nanduru, Md Mofijul Islam, Peixuan Han, Hyeonjeong Ha, Aman Chadha, Yilun Du, Heng Ji, Jundong Li, and Tariq Iqbal. Energy-based transformers are scalable learners and thinkers. InThe Fourteenth International Conference on Learning Representations,
-
[8]
URLhttps://openreview.net/forum?id=ZBj3Qp1bYg
-
[9]
Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical reasoning model, 2025. URL https://arxiv.org/abs/ 2506.21734
work page internal anchor Pith review arXiv 2025
-
[10]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, JUN ZHOU, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=KnqiC0znVF
work page 2025
-
[11]
Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum
Sean McLeish, Ang Li, John Kirchenbauer, Dayal Singh Kalra, Brian R. Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum. Teaching pretrained language models to think deeper with retrofitted recurrence, 2025. URL https: //arxiv.org/abs/2511.07384
-
[12]
Relaxed recursive transformers: Effective parameter sharing with layer-wise loRA
Sangmin Bae, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Seungyeon Kim, and Tal Schuster. Relaxed recursive transformers: Effective parameter sharing with layer-wise loRA. InThe Thirteenth International Conference on Learning Representations, 2025. URL https:// openreview.net/forum?id=WwpYSOkkCt
work page 2025
-
[13]
Guanxu Chen, Dongrui Liu, and Jing Shao. Loop as a bridge: Can looped transformers truly link representation space and natural language outputs?, 2026. URL https://arxiv.org/ abs/2601.10242
-
[14]
Ilya Sutskever.Training Recurrent Neural Networks.PhD thesis, University of Toronto, Canada, 2013
work page 2013
-
[15]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. InInternational conference on machine learning, pages 1310–1318. Pmlr, 2013
work page 2013
-
[16]
A survey on latent reasoning.arXiv preprint arXiv:2507.06203, 2025
Rui-Jie Zhu, Tianhao Peng, Tianhao Cheng, Xingwei Qu, Jinfa Huang, Dawei Zhu, Hao Wang, Kaiwen Xue, Xuanliang Zhang, Yong Shan, Tianle Cai, Taylor Kergan, Assel Kembay, Andrew Smith, Chenghua Lin, Binh Nguyen, Yuqi Pan, Yuhong Chou, Zefan Cai, Zhenhe Wu, Yongchi Zhao, Tianyu Liu, Jian Yang, Wangchunshu Zhou, Chujie Zheng, Chongxuan Li, Yuyin Zhou, Zhoujun...
-
[17]
Suppressing final layer hidden state jumps in transformer pretraining, 2026
Keigo Shibata, Kazuki Yano, Ryosuke Takahashi, Jaesung Lee, Wataru Ikeda, and Jun Suzuki. Suppressing final layer hidden state jumps in transformer pretraining, 2026. URL https: //arxiv.org/abs/2601.18302
-
[18]
Frozen in the middle: Hidden states remain unchanged across intermediate layers of language models
Pavel Tikhonov and Dmitry Ilvovsky. Frozen in the middle: Hidden states remain unchanged across intermediate layers of language models. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, CIKM ’25, page 5289–5293, New York, NY , USA, 2025. Association for Computing Machinery. ISBN 9798400720406. doi: 10.1145/374...
-
[19]
Llm neuroanatomy: How i topped the llm leaderboard without changing a single weight
David Noel Ng. Llm neuroanatomy: How i topped the llm leaderboard without changing a single weight. March 2026. URLhttps://dnhkng.github.io/posts/rys/
work page 2026
-
[20]
Mapping the mind of a large language model, 2024
Anthropic. Mapping the mind of a large language model, 2024. URL https://www. anthropic.com/research/mapping-mind-language-model
work page 2024
-
[21]
On the biology of a large language model, 2025
Anthropic. On the biology of a large language model, 2025. URL https:// transformer-circuits.pub/2025/attribution-graphs/biology.html. 11
work page 2025
-
[22]
Interpreting GPT: The logit lens
nostalgebraist. Interpreting GPT: The logit lens. LessWrong, 2020. URL https://www. lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
work page 2020
-
[23]
Elena V oita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. The bottom-up evolution of representations in the transformer: A study with machine translation and language modeling objectives. InProceedings of the 2019 Conference on Empirical Methods in Nat- ural Language Processing and the 9th International Joint Conference on Natural Language...
work page 2019
-
[24]
SOLAR 10.7B: Scaling large language models with simple yet effective depth up-scaling
Sanghoon Kim, Dahyun Kim, Chanjun Park, Wonsung Lee, Wonho Song, Yunsu Kim, Hyeon- woo Kim, Yungi Kim, Hyeonju Lee, Jihoo Kim, Changbae Ahn, Seonghoon Yang, Sukyung Lee, Hyunbyung Park, Gyoungjin Gim, Mikyoung Cha, Hwalsuk Lee, and Sunghun Kim. SOLAR 10.7B: Scaling large language models with simple yet effective depth up-scaling. In Yi Yang, Aida Davani, ...
work page 2024
-
[25]
doi: 10.18653/v1/2024.naacl-industry.3
Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-industry.3. URL https://aclanthology.org/2024.naacl-industry.3/
-
[26]
Chi, Quoc V Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/ forum?...
work page 2022
-
[27]
Pretraining language models to ponder in continuous space.arXiv preprint arXiv: 2505.20674,
Boyi Zeng, Shixiang Song, Siyuan Huang, Yixuan Wang, He Li, Ziwei He, Xinbing Wang, Zhiyu Li, and Zhouhan Lin. Pretraining language models to ponder in continuous space, 2025. URLhttps://arxiv.org/abs/2505.20674
-
[28]
Think-at-hard: Teaching small language models to think on hard problems, 2025
Yue Fu, Shruti Rijhwani, Graham Neubig, and Yonatan Bisk. Think-at-hard: Teaching small language models to think on hard problems, 2025. URL https://arxiv.org/abs/2506. 04458
work page 2025
-
[29]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Uni- versal transformers, 2019. URLhttps://arxiv.org/abs/1807.03819
work page internal anchor Pith review arXiv 2019
-
[30]
Ouro: A latent reasoning model with adaptive depth via gated recurrence,
Rui-Jie Zhu et al. Ouro: A latent reasoning model with adaptive depth via gated recurrence,
- [31]
-
[32]
Long short-term memory.Neural computation, 9(8): 1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8): 1735–1780, 1997
work page 1997
-
[33]
Learning phrase representations using RNN encoder-decoder for statistical machine translation,
Kyunghyun Cho, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder– decoder for statistical machine translation. In Alessandro Moschitti, Bo Pang, and Walter Daelemans, editors,Proceedings of the 2014 Conference on Empirical Methods in Natural Languag...
-
[34]
Rupesh Kumar Srivastava, Klaus Greff, and J"urgen Schmidhuber. Training very deep networks. Advances in Neural Information Processing Systems Workshop on Deep Learning, 2015. URL https://arxiv.org/abs/1507.06228
-
[35]
Sunghyun Sim, Dohee Kim, and Hyerim Bae. Correlation recurrent units: A novel neural architecture for improving the predictive performance of time-series data.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(12):14266–14283, 2023. doi: 10.1109/TPAMI. 2023.3319557
-
[36]
Mamba: Linear-time sequence modeling with selective state spaces,
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces,
-
[37]
URLhttps://arxiv.org/abs/2312.00752. 12
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Re. Efficiently modeling long sequences with structured state spaces. InInternational Conference on Learning Representations, 2022. URL https: //openreview.net/forum?id=uYLFoz1vlAC
work page 2022
-
[39]
xLSTM: Ex- tended long short-term memory
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael K Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xLSTM: Ex- tended long short-term memory. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=ARAxPPIAhq
work page 2024
-
[40]
Titans: Learning to Memorize at Test Time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663, 2024
work page internal anchor Pith review arXiv 2024
-
[41]
Gated delta networks: Improving mamba2 with delta rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=r8H7xhYPwz
work page 2025
-
[42]
Mi: dm 2.0 korea-centric bilingual language models.arXiv preprint arXiv:2601.09066, 2026
Donghoon Shin, Sejung Lee, Soonmin Bae, Hwijung Ryu, Changwon Ok, Hoyoun Jung, Hyesung Ji, Jeehyun Lim, Jehoon Lee, Ji-Eun Han, et al. Mi: dm 2.0 korea-centric bilingual language models.arXiv preprint arXiv:2601.09066, 2026
-
[43]
Less is More: Recursive Reasoning with Tiny Networks
Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks, 2025. URL https://arxiv.org/abs/2510.04871
work page internal anchor Pith review arXiv 2025
-
[44]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers.arXiv preprint arXiv:2212.09748, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
work page 2018
-
[46]
Rectified linear units improve restricted boltzmann machines
Vinod Nair and Geoffrey E Hinton. Rectified linear units improve restricted boltzmann machines. InProceedings of the 27th international conference on machine learning (ICML-10), pages 807–814, 2010
work page 2010
-
[47]
Self-normalizing neural networks.Advances in neural information processing systems, 30, 2017
Günter Klambauer, Thomas Unterthiner, Andreas Mayr, and Sepp Hochreiter. Self-normalizing neural networks.Advances in neural information processing systems, 30, 2017
work page 2017
-
[48]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Tinyllama: An open-source small language model, 2024
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. Tinyllama: An open-source small language model, 2024
work page 2024
-
[50]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J. Hewett, Mojan Javaheripi, Piero Kauffmann, James R. Lee, Yin Tat Lee, Yuanzhi Li, Weishung Liu, Caio C. T. Mendes, Anh Nguyen, Eric Price, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Xin Wang, Rachel Ward, Yue Wu, Dingli Yu,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps://openreview.net/ forum?id=...
work page 2024
-
[52]
A framework for few-shot language model evaluation, 12 2023
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework...
work page 2023
-
[53]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. InInternational Conference on Learning Representations, 2017. URL https:// openreview.net/forum?id=Byj72udxe
work page 2017
-
[54]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The LAMBADA dataset: Word prediction requiring a broad discourse context. In Katrin Erk and Noah A. Smith, editors,Proceedings of the 54th Annual Meeting of the Association for Compu- tational Linguis...
-
[55]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021. URL https: //arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[56]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?, 2019. URLhttps://arxiv.org/abs/1905.07830
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[57]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv:1803.05457v1, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[58]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language, 2019. URL https://arxiv.org/abs/ 1911.11641
-
[59]
Winogrande: An adversarial winograd schema challenge at scale, 2019
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale, 2019. URL https://arxiv.org/abs/1907. 10641
work page 2019
-
[60]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering, 2018. URL https: //arxiv.org/abs/1809.02789
work page internal anchor Pith review arXiv 2018
-
[61]
Mathieu Blondel, Michael E. Sander, Germain Vivier-Ardisson, Tianlin Liu, and Vincent Roulet. Autoregressive language models are secretly energy-based models: Insights into the lookahead capabilities of next-token prediction, 2026. URLhttps://arxiv.org/abs/2512.15605
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Incor- porating second-order functional knowledge for better option pricing
Charles Dugas, Yoshua Bengio, François Bélisle, Claude Nadeau, and René Garcia. Incor- porating second-order functional knowledge for better option pricing. In T. Leen, T. Diet- terich, and V . Tresp, editors,Advances in Neural Information Processing Systems, volume 13. MIT Press, 2000. URL https://proceedings.neurips.cc/paper_files/paper/2000/ file/44968...
work page 2000
-
[63]
F.A. Gers, J. Schmidhuber, and F. Cummins. Learning to forget: continual prediction with lstm. In1999 Ninth International Conference on Artificial Neural Networks ICANN 99. (Conf. Publ. No. 470), volume 2, pages 850–855 vol.2, 1999. doi: 10.1049/cp:19991218
-
[64]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=mZn2Xyh9Ec
work page 2024
-
[65]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. URL https://openreview. net/forum?id=St1giarCHLP. 14
work page 2021
-
[66]
Ruihan Xu, Yuting Gao, Lan Wang, Jianing Li, Weihao Chen, Qingpei Guo, Ming Yang, and Shiliang Zhang. Looping back to move forward: Recursive transformers for efficient and flexible large multimodal models.arXiv preprint arXiv:2602.09080, 2026
-
[67]
Qwen3.6-27B: Flagship-level coding in a 27B dense model, April 2026
Qwen Team. Qwen3.6-27B: Flagship-level coding in a 27B dense model, April 2026. URL https://qwen.ai/blog?id=qwen3.6-27b
work page 2026
-
[68]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
work page 2026
-
[69]
K-exaone technical report, 2026
Eunbi Choi, Kibong Choi, Seokhee Hong, Junwon Hwang, Hyojin Jeon, Hyunjik Jo, Joonkee Kim, Seonghwan Kim, Soyeon Kim, Sunkyoung Kim, Yireun Kim, Yongil Kim, Haeju Lee, Jinsik Lee, Kyungmin Lee, Sangha Park, Heuiyeen Yeen, Hwan Chang, Stanley Jungkyu Choi, Yejin Choi, Jiwon Ham, Kijeong Jeon, Geunyeong Jeong, Gerrard Jeongwon Jo, Yonghwan Jo, Jiyeon Jung, ...
-
[70]
Solar open technical report, 2026
Sungrae Park, Sanghoon Kim, Jungho Cho, Gyoungjin Gim, Dawoon Jung, Mikyoung Cha, Eunhae Choo, Taekgyu Hong, Minbyul Jeong, SeHwan Joo, Minsoo Khang, Eunwon Kim, Minjeong Kim, Sujeong Kim, Yunsu Kim, Hyeonju Lee, Seunghyun Lee, Sukyung Lee, Siyoung Park, Gyungin Shin, Inseo Song, Wonho Song, Seonghoon Yang, Seungyoun Yi, Sanghoon Yoon, Jeonghyun Ko, Seyou...
-
[71]
NVIDIA, :, Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, Aditya Vavre, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, Aleksandr Shaposhnikov, Alex Kondratenko, Alexander Bukharin, Alexandre Milesi, Ali Taghibakhshi, Alisa Liu, Amelia Barton, Ameya Sunil Mahabaleshwarkar, Amir Klein, Amit Zuker, A...
-
[72]
arXiv preprint arXiv:2603.15031 (2026)
Kimi Team, Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, Yutian Chen, Junjie Yan, Ming Wei, Y . Zhang, Fanqing Meng, Chao Hong, Xiaotong Xie, Shaowei Liu, Enzhe Lu, Yunpeng Tai, Yanru Chen, Xin Men, Haiqing Guo, Y . Charles, Haoyu Lu, Lin Sui, Jinguo Zhu, Zaida Zhou, Weiran He, Weixiao Huang...
-
[73]
Guiyao Tie, Zeli Zhao, Dingjie Song, Fuyang Wei, Rong Zhou, Yurou Dai, Wen Yin, Zhejian Yang, Jiangyue Yan, Yao Su, Zhenhan Dai, Yifeng Xie, Yihan Cao, Lichao Sun, Pan Zhou, Lifang He, Hechang Chen, Yu Zhang, Qingsong Wen, Tianming Liu, Neil Zhenqiang Gong, Jiliang Tang, Caiming Xiong, Heng Ji, Philip S. Yu, and Jianfeng Gao. A survey on post-training of ...
-
[74]
dllm: Simple diffusion language modeling.arXiv preprint arXiv:2602.22661,
Zhanhui Zhou, Lingjie Chen, Hanghang Tong, and Dawn Song. dllm: Simple diffusion language modeling, 2026. URLhttps://arxiv.org/abs/2602.22661. 16 h = Encoder(x) sampled = RandomSampler(B, K) for b in range(B): # Supervised step if b in sampled: h_prev = h h_prop = Reasoner(h) h = Gate(h_prev, h_prop) q_logit = ConfidenceHead(h) y_hat = Decoder(h) y_prev =...
-
[75]
establish an explicit bijection between autoregressive models and EBMs in function space. They 19 show that a sequence-level energy decomposes into per-token rewards, R(x, y) = |y|X t=1 r(x⊕y <t, yt),(20) and that an autoregressive model’s next-token logitsq relate to these per-token rewards r through the soft Bellman equation: q(st, yt) =r(s t, yt) +V q(...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.